What Are SpeedUp and ScaleUp in DBMS?
In this article, we will discuss SpeedUp and ScaleUp in DBMS, two fundamental concepts from Parallel Processing for Databases that are used for tweaking the databases.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will discuss all the SpeedUp and ScaleUp in DBMS, two of the fundamental concepts from Parallel Processing for Databases that are used for tweaking databases.
Speedup
Data warehouses carrying several hundred gigabytes of data are now relatively typical due to the steady increase in database sizes. Even several terabytes of data can be stored in some databases, referred to as Very Large Databases (VLDBs).
These data warehouses are subjected to sophisticated queries in order to acquire business intelligence and support decision-making. Such inquiries take a very long time to process. You can shorten the total time spent while still delivering the necessary CPU time by running these queries simultaneously.
The ratio of the runtime using one processor to the runtime utilizing several processors is known as speedup.
The following formula is used to compute it. It estimates the performance advantage obtained by employing more than one processor instead of one CPU:
Speedup is equal to Time1 / Timen
Time1 is the amount of time needed to complete a task with a single processor, whereas Timen is the amount of time needed to complete the same work with m processors.
Speedup Curve
In an ideal scenario, the speedup from parallel processing would correspond to the number of processors being used for each given operation.
Alternatively, a 45-degree line is an optimum shape for a speedup curve.
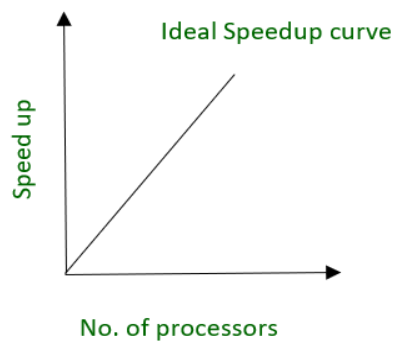
Because parallelism involves some overhead, the optimal speedup curve is rarely obtained. The degree of speedup you can obtain is significantly influenced by the application’s inherent parallelism.
The components of some tasks can be processed in parallel with ease. For instance, it is possible to do two huge tables join concurrently.
However, some tasks cannot be separated. One such instance is a nonpartitioned index scan. The amount of speedup will be minimal or nonexistent if an application has little or no inherent parallelism.
Efficiency is calculated as the speedup divided by the total number of processors. In our example, there are four processors, and the speedup is also four. Consequently, the efficiency is 100%, which represents an ideal case.
Example:
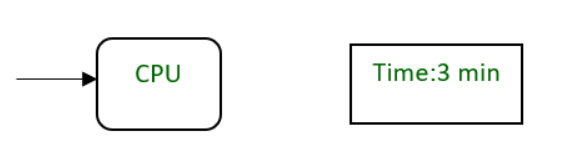
A CPU requires three mins to execute a process.
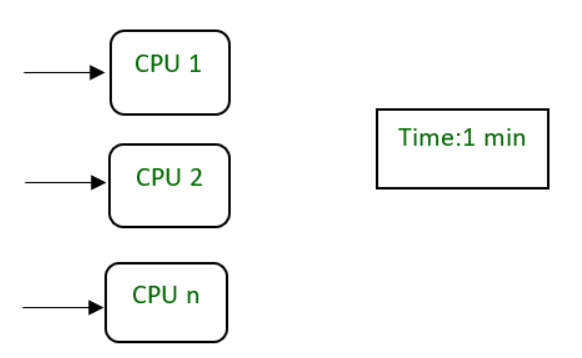
‘n’ CPU requires one min to execute a process by dividing it into smaller tasks.
Types of Speedup
- Linear Speedup
- Sub-Linear Speedup
Linear Speedup
If the speedup is N, then the speedup is linear. In other words, the tiny system’s elapsed time is N times greater than the large system’s elapsed time (N is the number of resources, say CPU).
For instance, if a single machine completes a task in 10 seconds, but ten single machines working in parallel complete the same task in 1 second, the speedup is (10/1)=10 (see the equation above), which is equal to N, the size of the larger system. The ten times more powerful mechanism is what allows for the speedup.
Sub-Linear Speedup
If the speedup is less than N, it is sub-linear (which is usual in most parallel systems).
More insightful discussions: If the Speedup is N, or linear, that means the performance is as anticipated.
Two scenarios are possible if the Speedup is less than N
Case 1: If Speedup exceeds N, the system performs better than intended. In this scenario, the Speedup value would be lower than 1.
Case 2: It is sub-linear if Speedup N. The denominator (huge system elapsed time) in this situation exceeds the elapsed time of a single machine.
In this situation, the value would range between 0 and 1, and we would need to set a threshold value such that any value below the threshold would prevent parallel processing from taking place.
Redistributing the workload among processors in such a system requires special caution.
Few Techniques to Speed Up Your Database
Now let us see some of the techniques to speed up the database
Indices
By preserving an effective search data structure, indices enable the database to locate pertinent rows more quickly (e.g., a B-Tree).
Each table must perform this. An index might be added seldom because it can be computationally intensive and requires the production system.
With SQL (MySQL, PostgreSQL), creating an index is simple:
CREATE INDEX random index name
ON your table name
(col1, col2);The database can be searched more quickly by adding an index; however, the UPDATE, INSERT and DELETE commands take longer to execute unless the WHERE clause takes a long time.
Query Enhancement
The database user does query optimization for each query. There are numerous ways to write queries, and some of them may be more effective than others.
The n+1 problem and using a loop to submit numerous requests rather than just one to obtain the data fall under a slightly distinct subcategory of the query optimization topic.
Changes in Business and Partitioning
You want to impress your customers as your firm expands. You attempt to include any minor new features that customers request. This can result in feature creep.
This was a problem quite a while ago, according to the UNIX philosophy:
Comparably, dividing your online services data into user groups might be acceptable. Maybe dividing them up into areas makes sense? That’s what I observed at Secure Code Warrior and AWS.
It could be possible to divide it into “Private clients,” “Small business clients,” and “Large Business clients.” Perhaps a portion of the application can function as its own service with a separate database.
Replication
If reads are your issue and a small amount of update time delay is not a major deal, replication is an easy solution. The database is continuously copied to another system during replication. It serves as a failover mechanism and accelerates reads.
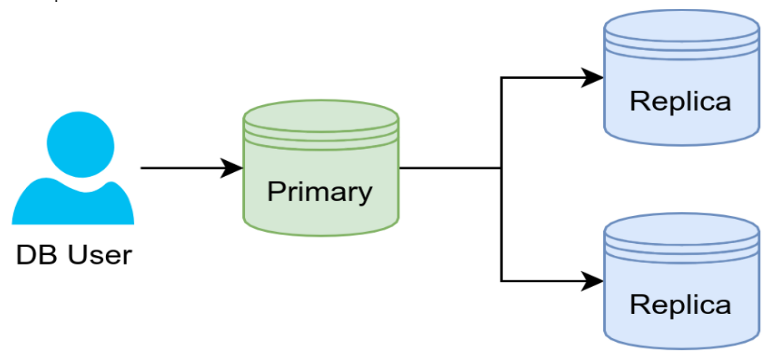
One primary server and numerous replication servers—which were earlier known by different names—are the intended configuration. Data updates are handled by the primary server, not the replication servers, which merely mirror the primary server. Other topologies exist, such as a ring or star configuration.
Horizontal Partitioning
If the table were really large, we could store some rows on one machine and others on another. Horizontal partitioning is the concept of dividing data into rows.
Vertical Dividing
The large database can be split up into smaller sections using columns rather than rows. You may feel worried about this because you were taught in school that normalizing a database is a good thing.
That we are discussing various stages of database architecture is crucial to keep in mind. The logical design is related to the numerous normal kinds of databases. The physical design is what we focus on right now.
Perhaps not all of a row’s columns are required by all application components. It may be acceptable to divide them up because of this. Row splitting is another name for vertical partitioning because of this.
One thing to keep in mind is that scaling vertically has nothing to do with vertical partitioning!
Vertical partitioning may be advantageous if privacy or legal concerns are not involved. Consider your payment card details.
Although it would make logical sense to combine that with other data, the majority of the application does not require it, even better, you could conceal it behind a private microservice and store it in a whole new database.
Sharding: The Next Step in Partitioning
You’ve seen that there are two distinct ways to group the data. To help the database process frequent queries more quickly, it might already make sense to divide the data on the same system.
However, it would be wise to use different machines if the database is using all of the CPU or RAM on the current one.
A single logical dataset is sharded and distributed across various devices.
This has a lot of problems, as you could expect, so you should only use it as a last resort. For instance, in October 2010, a sharding problem caused Foursquare to be unavailable for 11 hours.
The first obvious problem is that your application must be aware of which shard has the desired data. Consequently, your application logic could be impacted everywhere.
Clustering of Databases
Only after looking at Vitess did I come across this phrase. The concept appears to cover up the problems with sharding by employing replication as a cover technique.
Scaleup
By adding more processors and discs, scaleup is the ability of an application to maintain response time as the size of the workload or the volume of transactions grows. Scaleup is frequently discussed in terms of scalability.
Scaleup in database applications can be batch- or transaction-based. Larger batch jobs can be supported with batch scaleup without sacrificing response time. Greater quantities of transactions can be supported with transaction scaleup without sacrificing response time.
More processors are added in both scenarios to maintain response time. For instance, a four-processor system can deliver the same response time with 400 transactions per minute of burden as a single-processor system that supports 100 transactions per minute of duty.
Ideal Scaleup Curve
The figure shows an ideal as a curve or really a flat line. In truth, even if more processors are added, the reaction time eventually increases for increasing transaction volumes.
The ability to scale up is determined by how much more processing power can be added while still maintaining a constant response time. The formula below is used to determine scaleup:
Scaleup = Volumem/Volume1
Volume1 is the volume of transactions carried out in the same period of time using one processor, whereas Volumem is the volume of transactions carried out using m processors. For the prior instance:
Scaleup = 400/100.
Scaled-up = 4,
Using four processors, this scaleup of 4 is accomplished.
Types of Scaleup
- Liner Scaling up
- Sub-linear Scaleup
Linear Scaling Up
If resources grow proportionally to the magnitude of the problem, scale-up is linear (it is very rare). The preceding equation states that Scaleup = 1 and is linear if the time taken to solve a small system small problem equals the time taken to solve a large system large problem.
Sub-Linear Scaleup
The scaleup is sub-linear if the elapsed time for large systems with huge problems is longer than for small systems with minor problems.
Additional discussions that are pertinent include: The system performs flawlessly if scaleup is one or linear.
We must take extra caution when selecting our plan for parallel execution if the scaleup is sublinear and the value ranges between 0 and 1. For instance, if the time it takes to solve a small problem is 5 seconds, and a large system with a large problem takes 5 seconds to solve.
This exhibits linearity clearly. Therefore, 5/5 = 1. The system performs admirably for different denominator values, particularly low values (not conceivable beyond a limit).
However, the scale-up value drops below 1, which necessitates significant attention for better task redistribution for higher values of the denominator, such as 6, 7, 8, and so on.
Difference Between Speedup and Scaleup
Scaleup and speedup differ significantly in that speedup are computed by maintaining a fixed problem size, whereas scaleup is determined by increasing the problem size or transaction volume.
How much the transaction volume can be enhanced by adding additional processors while yet maintaining a constant response time is how scaleup is measured.
Conclusion
Hope this article on scaleup and speedup helped you learn the basics of the same. Thanks for reading!
Opinions expressed by DZone contributors are their own.
Comments