Apache ZooKeeper vs. etcd3
If you are trying to select the right distributed coordination scheme for your future distributed computing implementations, you've come to the right place.
Join the DZone community and get the full member experience.
Join For FreeWhen it comes to implementing distributed coordination schemes, there are many outstanding systems, such as Apache ZooKeeper, etcd, consul, and Hazelcast. If you haven't heard of distributed coordination, refer my article on distributed coordination that gives an introductory idea of what distributed coordination is and why we need it.
Even though some of these are not directly distributed coordination systems, all of them can be used as distributed coordination schemes. However, there are two clear outstanding giants in distributed coordination: Apache ZooKeeper and etcd. ZooKeeper originated in the Hadoop ecosystem while etcd is the distributed coordination scheme backing Google’s Kubernetes.
This article compares these two implementations along with their pros and cons, which will be very useful for many developers when selecting the right distributed coordination scheme for their future distributed computing implementations.
Apache ZooKeeper
ZooKeeper originated as a subproject of Hadoop and evolved to be a top-level project of Apache Software Foundation. Right now, it is being used by most of the Apache projects, including Hadoop, Kafka, Solr, and much more. Due to its proven track record and stability, ZooKeeper has become one of the top distributed coordination systems in the world.

ZooKeeper uses ZAB (ZooKeeper Atomic Broadcast) as its consensus protocol. As mentioned earlier, one of the purposes of ZooKeeper is to provide a distributed data store. To achieve high availability, ZooKeeper operates in an ensemble — that is, a set of nodes running ZooKeeper works together to provide its distributed characteristics. This set of nodes is called the ZooKeeper Ensemble.
A ZooKeeper Ensemble should always include an odd number of nodes. When running, these nodes first communicate with each other and elect a leader, which is why ZooKeeper needs to operate in an odd-numbered ensemble. Onwards, the other nodes are called Followers, while the elected node is called the Leader. A client connecting to ZooKeeper now can connect to any of these nodes. Clients read requests can be served by any node, but write requests can only be served by the Leader. Therefore, adding more nodes to the ZooKeeper Ensemble will increase read speed but not write speed.
Out of the three properties of the CAP (Consistency, Availability, and Partition Tolerance) theorem, ZooKeeper provides consistency and partition tolerance. You can read more on ZooKeeper guarantees here.
ZNodes
 When storing data, ZooKeeper uses a tree structure where each node is called a
ZNode. ZNodes are named based on the path from the root node. Each ZNode has a name. When accessing a given ZNode, the absolute path from the root node is used.
When storing data, ZooKeeper uses a tree structure where each node is called a
ZNode. ZNodes are named based on the path from the root node. Each ZNode has a name. When accessing a given ZNode, the absolute path from the root node is used.
Shown above is an example of ZooKeeper’s ZNode structure. Each ZNode can store up to 1MB of data. Users can:
- Create ZNodes.
- Delete ZNodes.
- Store data in a particular ZNode.
- Read data in a particular ZNode.
Apart from that, ZooKeeper provides another very important feature: the Watcher API.
Zookeeper Watches
Users can put a watch on any given ZNode. When any change (i.e. create, delete, data change, addition/removal of child ZNode) occurs to that ZNode, the Watch API notifies the listening party. This is a very important functionality provided by ZooKeeper that can be used to detect changes for distributed command passing and for many critical requirements.
The only drawback of ZooKeeper watches is that a given watch is only triggered once. Once a watch is notified, in order to receive future events on the same ZNode, users have to place a new watch on that ZNode. However, extensions like Apache Curator internally handle these complexities and provide the user with a more convenient API.
Apache Curator
Apache Curator is an extended client library for ZooKeeper. It internally handles almost all the edge cases and complexities of ZooKeeper and provides users with a convenient API. You can read more on curator here. Curator has implemented many distributed ZooKeeper recipes, including shared reentrant lock, path cache, tree cache, and much more.
Pros
We've already discussed most of the pros, but here are more:
- Non-blocking full snapshots (to make eventually consistent).
- Efficient memory management.
- Reliable (has been around for a long time).
- A simplified API.
- Automatic ZooKeeper connection management with retries.
- Complete, well-tested implementations of ZooKeeper recipes.
- A framework that makes writing new ZooKeeper recipes much easier.
- Event support through ZooKeeper watches.
- In a network partition, both minority and majority partitions will start a leader election. Therefore, the minority partition will stop operations. You can read more about this here.
Cons
- Since ZooKeeper is written in Java, it inherits few drawbacks of Java (i.e. garbage collection pauses).
- When creating snapshots (where the data is written to disks), ZooKeeper read/write operations are halted temporarily. This only happens if we have enabled snapshots. If not, ZooKeeper operates as an in-memory distributed storage.
- ZooKeeper opens a new socket connection per each new watch request we make. This has made ZooKeepers like more complex since it has to manage a lot of open socket connections in real time.
etcd3

We will be talking about the latest release of etcd (etcd v3), which has major changes compared to its predecessor etcd v2. In contrast to Apache ZooKeeper, etcd is written in Go. Its prime objective is to resolve drawbacks in ZooKeeper. Even though it is not as old and renowned as ZooKeeper, it is a promising project with a great future. Well-known Google's container orchestration platform, Kubernetes uses etcd v2 as distributed storage to get distributed locks for its master components. This is an example of how powerful etcd is.
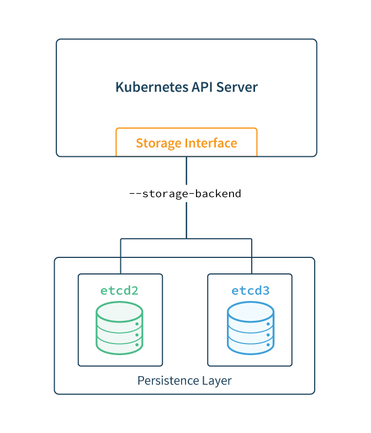
etcd uses the RAFT consensus algorithm for consensus, making it easier to implement than ZooKeeper with its ZAB protocol. Instead of a tree structure, etcd provides a distributed key-value store. It also provides the following guarantees, which are very similar to those provided by ZooKeeper:
- Atomicity.
- Consistency.
- Sequential consistency.
- Serializable isolation.
- Durability.
- Linearizability (except for watches).
API
etcd3 provides following operations to be performed on distributed storage. These operations are mostly similar to the operations provided by ZooKeeper instead of the differences imposed by the underlying data structure.
- Put: Puts a new key-value pair to storage.
- Get: Retrieves a value corresponding to a key.
- Range: Retrieves values corresponding to a key range (i.e. key1 to key10 will retrieve all the present values for keys key1, key2, …, key10).
- Transaction: Read, compare, modify, and write combinations.
- Watch: On a key or key range. Changes will be notified similarly to ZooKeeper.
More on these operations can be found here. Also, etcd has most of the distributed recipes implemented on to Apache Curator.
Pros
- Incremental snapshots avoid pauses when creating snapshots, which is a problem in ZooKeeper.
- No garbage collection pauses due to off-heap storage.
- Watchers are redesigned, replacing the older event model with one that streams and multiplexes events over key intervals. Therefore, there's no socket connection per watch. Instead, it multiplexes events on the same connection.
- Unlike ZooKeeper, etcd can continuously watch from the current revision. There's no need to place another watch once a watch is triggered.
- etcd3 holds a sliding window to keep old events so that disconnecting will not cause all events to be lost.
Cons
- Note that the client may be uncertain about the status of an operation if it times out or if there's a network disruption between the client and the etcd member. etcd may also abort operations when there is a leader election. etcd does not send abort responses to clients’ outstanding requests in this event.
- Serialized read requests will continue to be served in a network split where the minority partition is the leader at the time of the split.
Conclusion
We discussed the major features, pros, and cons of Apache ZooKeeper and etcd3. ZooKeeper is written in Java and is widely adopted by Apache Software Foundation projects, while etcd3 is backed by Google (Kubernetes). Even though Apache ZooKeeper is stable and is renowned for being a great distributed coordination system, etcd3 is new and promising.
Since etcd is written in Go, good client libraries are not available for Java. In contrast, since ZooKeeper has been around for some time, it has some good client libraries written in other languages, as well. However, whether you should go with ZooKeeper or etcd depends on your requirements and your preferred language.
Further Reading
Published at DZone with permission of Imesha Sudasingha. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments