API and Database Performance Optimization Strategies
Optimize API and database performance with caching, query optimization, indexing, data sharding, and performance testing for improved user experience.
Join the DZone community and get the full member experience.
Join For FreeIn today's fast-paced digital landscape, performance optimization plays a pivotal role in ensuring the success of applications that rely on the integration of APIs and databases. Efficient and responsive API and database integration is vital for achieving high-performing applications. Poorly optimized performance can lead to sluggish response times, scalability challenges, and even user dissatisfaction.
By focusing on performance optimization, developers can enhance the speed, scalability, and overall efficiency of their applications. This not only leads to improved user satisfaction but also lays the foundation for future growth and success. Investing time and effort in optimizing performance upfront can prevent performance bottlenecks, reduce maintenance costs, and provide a solid framework for handling increased user loads as the application scales.
In this guide, we will delve into various techniques for optimizing the performance of APIs and databases. Throughout the content, we will focus on key performance optimization techniques such as caching, query optimization, indexing, and data sharding. These techniques offer powerful solutions for enhancing response times, minimizing database load, and improving overall system performance.
Join us as we embark on this journey to uncover the secrets of API and database performance optimization. Let's explore how these techniques can revolutionize your application's performance and propel your development efforts to new heights.
API Caching
Caching is a powerful technique used in API and database integration to improve performance and reduce the load on both the API and the underlying database. At its core, caching involves storing frequently accessed data in temporary storage space, such as memory, to enable faster retrieval in subsequent requests.
The benefits of caching in API and database integration are manifold. Firstly, caching significantly reduces the need to query the database for the same data repeatedly. By storing commonly accessed data in memory or a fast storage medium, subsequent requests can be fulfilled directly from the cache, eliminating the need to traverse the entire data retrieval pipeline. This results in faster response times and a more seamless user experience.
Moreover, caching reduces the load on both the API and the database, as fewer requests need to be processed and served. This can lead to improved scalability, allowing the application to handle a larger number of concurrent users without sacrificing performance. By alleviating the strain on the database, caching can help prevent bottlenecks and ensure the system remains responsive even during peak usage periods.
Caching can be employed at various levels within the application architecture. It can be implemented at the API level, where responses to frequently requested data are stored and served directly from the API cache. Additionally, caching can be applied at the database level, where the database itself maintains a cache of frequently accessed data to expedite retrieval.
However, it's important to note that caching introduces a trade-off between data consistency and performance. As cached data might not always reflect the most up-to-date information in the underlying database, it's crucial to implement cache invalidation strategies to ensure data integrity. Techniques such as time-based expiration or cache invalidation based on specific events can be employed to manage cache consistency effectively.
Types of API Caching Mechanisms
When it comes to optimizing API and database performance, various caching mechanisms can be employed to meet specific requirements. Let's explore some of the commonly used types of caching mechanisms
- In-memory caching involves storing frequently accessed data in the memory of the application server or a dedicated caching server. By keeping the data in close proximity to the application, retrieval times are significantly reduced. In-memory caching is particularly effective for read-heavy workloads where data consistency can be managed through cache invalidation strategies.
- Content delivery networks (CDNs) are geographically distributed networks of servers that store cached copies of static and dynamic content. CDNs improve performance by serving content to users from the server closest to their location, reducing latency and network congestion. This type of caching is beneficial for large-scale applications with a global user base, as it accelerates the delivery of static assets and reduces the load on the API and database servers
- Database query result caching involves storing the results of frequently executed database queries in memory. By avoiding the need to recompute the same query results, subsequent requests can be served faster, resulting in improved response times. This type of caching is particularly useful for applications with complex and resource-intensive database queries.
- HTTP caching leverages the caching capabilities of the HTTP protocol to store and serve cached responses. This type of caching is based on the HTTP headers, such as "Cache-Control" and "Expires," which specify how long a response should be considered fresh and can be cached. HTTP caching is effective for caching static resources like images, CSS, and JavaScript files, reducing the need for repeated downloads.
- Full-page caching involves caching the entire rendered output of a web page. This technique is often used in content management systems and e-commerce platforms to serve static versions of frequently accessed pages. By bypassing the dynamic rendering process, full-page caching significantly improves response times and reduces server load.
Caching plays a vital role in improving response times and reducing the load on databases in API and database integration. By storing frequently accessed data in a cache, subsequent requests for the same data can be served directly from the cache, eliminating the need to retrieve it from the underlying database. This significantly reduces the response time, as accessing data from the cache is much faster compared to querying the database.
When a request is made, the system first checks if the data is available in the cache. If it is, the response can be generated quickly without any additional database operations. This not only saves time but also reduces the workload on the database server. As a result, the overall system performance improves, enabling it to handle a higher volume of requests without slowing down.
Additionally, caching can help alleviate database load by reducing the number of queries made to the database. As data is retrieved from the cache, the number of database queries decreases, which lightens the database's processing load. This is particularly beneficial when dealing with complex or resource-intensive queries that require significant computational resources. By caching the results of these queries, subsequent requests for the same data can be served directly from the cache, reducing the need for repetitive and costly database operations.
Best Practices for Implementing API Caching and Database Integration
Implementing caching in API and database integration requires careful consideration of best practices to ensure optimal results. One essential best practice is to identify caching opportunities within your system. Determine which parts of your API and database integration would benefit the most from caching, such as frequently accessed data, computationally expensive operations, or relatively static data.
Furthermore, some enterprise-class integration platforms will typically include a caching function to facilitate caching of dynamic or static data. One example is Martini. Below is a snippet showing how to use the Cache function in the API service designer of Martini:
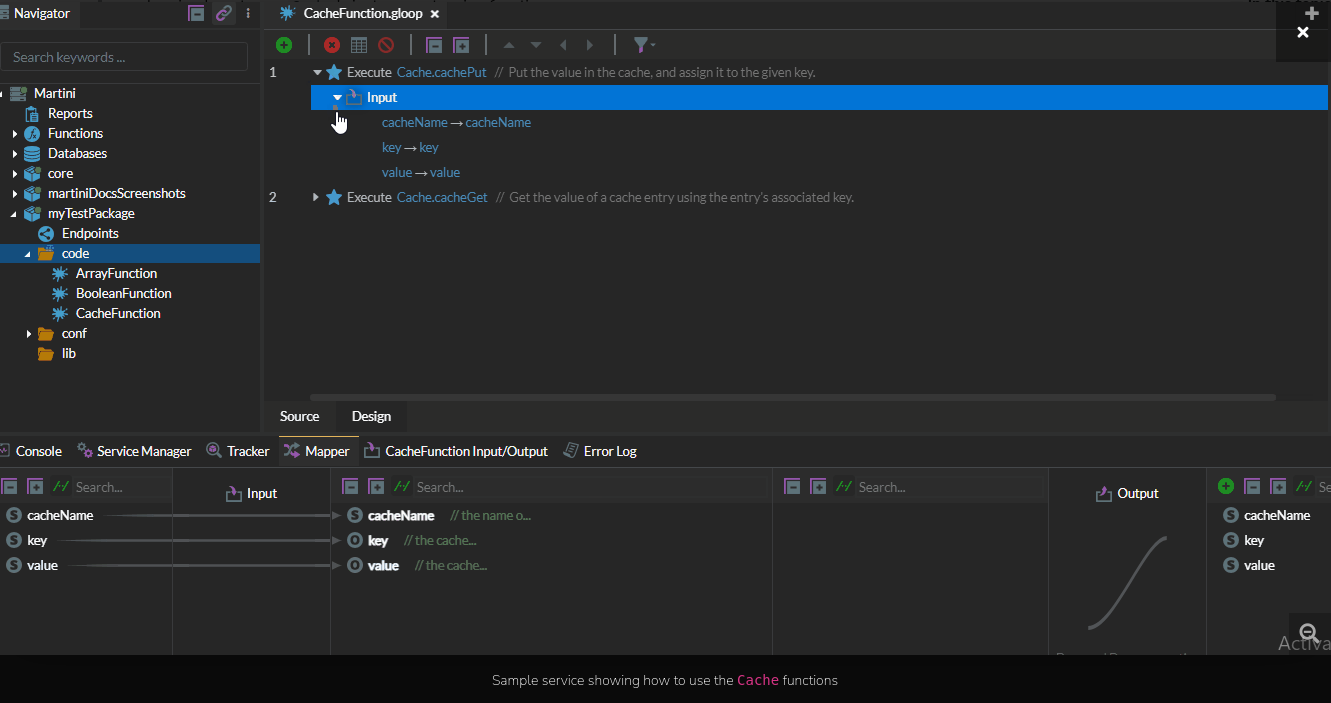
Additionally, it's crucial to determine the appropriate caching granularity. This involves deciding whether to cache entire API responses, individual database query results, or smaller components of data within a response. Finding the right balance between maximizing cache hits and minimizing cache invalidations is key.
Setting appropriate cache expiration policies is another important aspect. Define suitable expiration times for cached data based on its volatility. Consider the frequency of data updates and the acceptable staleness of cached information. Shorter expiration times ensure fresher data but may increase cache misses, while longer expiration times increase the likelihood of serving stale data.
Handling cache invalidation is a critical practice to maintain cache consistency with the latest data. Implement mechanisms to invalidate or update cached data when the underlying data changes. This can be done through manual invalidation triggered by data updates, time-based invalidation, or event-driven approaches.
Employing effective cache eviction strategies is also essential. Determine how the cache handles eviction when it reaches its capacity limit. Eviction strategies can include removing the least recently used items, the least frequently accessed items, or using a combination of different policies. Choosing the appropriate eviction strategy depends on the specific requirements and characteristics of your system.
Furthermore, it is important to monitor and analyze cache performance regularly. Utilize suitable tools and metrics to measure cache hit rates, cache utilization, response times, and other relevant performance indicators. This data will provide insights into the effectiveness of your caching implementation and help identify areas for improvement or optimization.
Finally, thoroughly test your caching implementation under various scenarios and traffic loads. Simulate realistic usage patterns and verify that the cache behaves as expected. Monitor performance metrics during testing and fine-tune caching configurations if needed. Following these best practices will ensure a successful caching implementation in your API and database integration, leading to improved performance and scalability of your system.
API Query Optimization
Query optimization plays a crucial role in enhancing the performance of API and database integration. When executing queries, databases use query optimization techniques to generate the most efficient execution plan. This process involves analyzing query structures, table statistics, and available indexes to determine the optimal way to retrieve data.
By optimizing queries, you can significantly improve the response times and reduce the overall workload on the database. Efficient query execution reduces the amount of time spent on processing requests, leading to faster response times for API consumers. It also helps minimize resource utilization, enabling the system to handle more concurrent requests without sacrificing performance.
The impact of query optimization extends beyond response times. Well-optimized queries reduce the load on the database server, improving its scalability and capacity to handle increasing workloads. By minimizing unnecessary database operations and leveraging indexes effectively, you can avoid resource bottlenecks and ensure a smooth and efficient operation of your system.
Query optimization techniques include various strategies such as choosing appropriate join algorithms, utilizing indexes effectively, and optimizing query predicates. Join algorithms determine how tables are combined to retrieve the required data, and selecting the most suitable algorithm based on the data distribution and query conditions can significantly improve performance. Indexes provide a way to locate data quickly, and creating and utilizing indexes based on query patterns can enhance query execution speed. Optimizing query predicates involves using appropriate operators and conditions to filter and retrieve the necessary data efficiently.
In addition to the technical aspects, it is essential to consider query optimization as an ongoing process. As your system evolves and data volumes increase, query performance can be impacted. Regularly reviewing and analyzing query performance metrics, identifying bottlenecks, and fine-tuning queries based on changing requirements and data characteristics are essential for maintaining optimal performance.
Techniques for Optimizing Database Queries
Optimizing database queries is a critical aspect of improving the performance and efficiency of your API and database integration. By implementing various techniques, you can enhance the execution speed and resource utilization of your queries. Here are some effective techniques for optimizing database queries:
- Query rewriting involves modifying the original query to generate an alternative query that delivers the same results but with improved performance. This technique aims to eliminate redundant operations, simplify complex expressions, or break down a complex query into smaller and more manageable parts. By rewriting queries, you can reduce the computational overhead and improve the overall query execution time.
- Query plan analysis involves examining the execution plans generated by the database optimizer. These plans outline the steps the database engine will take to execute a query. By analyzing the query plans, you can identify potential bottlenecks or inefficiencies in the query execution process. This knowledge allows you to make informed decisions about query modifications, such as restructuring or adding indexes, to optimize the query performance.
- Indexing is a fundamental technique for improving query performance. Indexes are data structures that provide quick access to specific data in a database table. By creating indexes on columns frequently used in query conditions or joins, you can significantly speed up the data retrieval process. However, it's important to strike a balance between the number of indexes and the overhead they introduce during data modifications, as excessive indexing can degrade performance.
- Database-specific optimizations, different database management systems offer various optimization techniques and features. These may include materialized views, query hints, or stored procedures. Materialized views store the results of frequently executed queries as physical tables, allowing for faster data retrieval without executing the underlying query again. Query hints provide instructions to the optimizer on how to process a query more efficiently. Stored procedures allow you to precompile and store frequently executed queries, reducing the overhead of query parsing and compilation.
- Data denormalization involves restructuring the database schema to reduce the number of joins required for complex queries. By duplicating data across multiple tables or adding redundant columns, you can simplify queries and improve their performance. However, denormalization should be used judiciously, considering the trade-off between query performance and data consistency.
Using Appropriate Indexing To Improve API Query Performance
Optimizing query performance is essential for ensuring efficient API and database integration. One powerful technique to achieve this is by using appropriate indexing. Indexing involves creating data structures that enable faster retrieval of information from the database. By strategically selecting the right columns to index, you can significantly enhance the speed and efficiency of your queries.
To start, identify the key columns that are frequently used in query conditions, such as columns involved in WHERE clauses or JOIN operations. These columns should possess high selectivity, meaning they have a wide range of distinct values. Choosing such columns for indexing allows the database engine to quickly narrow down the search space and retrieve the relevant data more efficiently.
When creating indexes, consider the index type that best suits your database capabilities and query requirements. Common index types include B-tree indexes, hash indexes, and bitmap indexes. Each type has its own advantages and is suitable for different scenarios. Additionally, for queries that involve multiple columns or joins, composite indexes can be used to cover multiple conditions and improve query performance.
Regularly updating statistics is crucial for maintaining optimal indexing performance. Statistics provide information about the data distribution in the indexed columns, allowing the query optimizer to make informed decisions about query execution plans. Outdated or inaccurate statistics can lead to suboptimal query performance, so it's important to schedule regular statistics updates.
While indexing can greatly improve query performance, it's important to avoid over-indexing. Having too many indexes can introduce maintenance overhead and slow down data modification operations. It's a best practice to carefully analyze the query patterns and usage scenarios to determine the most beneficial indexes while keeping the index count manageable.
Monitoring and analyzing the usage and performance of your indexes is essential. Utilize database monitoring tools and performance metrics to identify underutilized or unused indexes. Periodically review and adjust your indexes based on query performance statistics and user behavior to ensure they remain effective.
By implementing appropriate indexing techniques, you can significantly enhance query performance in your API and database integration. Well-designed indexes can reduce query response times, minimize resource utilization, and improve overall system efficiency, leading to a better user experience and higher scalability.
Best Practices for Writing Efficient and Optimized Queries
- Use appropriate data types: Choose the most suitable data types for your columns to ensure efficient storage and indexing. Using the correct data types not only saves storage space but also allows the database to perform operations more efficiently.
- Minimize data retrieval: Retrieve only the necessary columns and rows to minimize the amount of data transferred between the database and the application. Avoid using wildcard (*) in SELECT statements and specify the required columns explicitly. Additionally, use WHERE clauses to filter data at the database level, reducing the amount of data processed and improving query performance.
- Avoid unnecessary joins: Joining multiple tables can be resource-intensive and impact query performance. Only join the necessary tables and ensure that your join conditions are optimized. Analyze the relationships between tables and identify the minimum set of joins required to fetch the desired data.
- Optimize subqueries: Subqueries can be a powerful tool, but they can also impact performance if not used carefully. Make sure to optimize subqueries by using appropriate indexes, limiting the result set, or considering alternative query structures like joins or derived tables when possible.
- Create appropriate indexes: As mentioned earlier, indexing is crucial for query performance. Analyze the query patterns and identify the columns that are frequently used in search conditions. Create indexes on these columns to speed up data retrieval. However, be mindful of the trade-off between the benefits of indexing and the overhead of maintaining indexes during data modifications.
- Update statistics regularly: Keep the statistics of your database up to date to ensure accurate query optimization. Outdated statistics can lead to suboptimal query plans, resulting in poor performance. Schedule regular statistics updates or enable automatic statistics updates to maintain optimal query performance.
- Use query hints or directives: Query hints or directives are mechanisms provided by the database engine to guide query optimization. They can be used to enforce specific execution plans or to provide additional information to the query optimizer. Use them sparingly and only when necessary, as they can restrict the flexibility of the query optimizer.
- Test and benchmark queries: Before deploying queries into a production environment, thoroughly test and benchmark them under realistic conditions. Use sample data representative of your actual workload and measure query execution times. This will help identify any performance bottlenecks or areas for improvement.
Indexing
Indexing plays a crucial role in optimizing database performance. It involves creating data structures that facilitate fast data retrieval based on specific search criteria. By creating indexes on frequently queried columns, databases can quickly locate relevant data, resulting in improved query performance. In this section, we will explore the fundamentals of indexing and understand its significance in enhancing database performance.
Indexes are separate structures associated with tables that enable quick access to data rows based on the values in one or more columns. They act as a roadmap, allowing databases to find data efficiently. The primary benefit of indexing is its ability to speed up data retrieval by reducing disk I/O operations. Instead of scanning the entire table, the database engine can use the index to locate relevant rows, significantly reducing the scanning process.
To maximize indexing benefits, it's crucial to choose which columns to index carefully. Indexes are typically created on frequently used search conditions, such as WHERE clauses or JOIN operations. However, indexing involves a trade-off as it introduces overhead on data modification operations. Therefore, it's essential to strike a balance between read performance and the impact on write operations.
Different Types of Indexes
When it comes to indexing in databases, there are several types of indexes that offer unique characteristics and suitability for different scenarios. Understanding the various types of indexes can help you choose the most appropriate indexing strategy for your database. Here are some commonly used types of indexes:
- B-tree index is the most common and widely used index type. It organizes data in a balanced tree structure, allowing for efficient range queries and sorted data retrieval. B-tree indexes are well-suited for columns with a wide range of values and provide fast lookup times for equality and range-based queries.
- Hash indexes use a hashing function to map keys to index entries, providing fast access to specific values. They are efficient for equality-based queries but do not perform well with range queries. Hash indexes are often used in in-memory databases or for columns with a limited number of distinct values.
- Bitmap indexes represent data as bitmaps, with each bit indicating the presence or absence of a value. They are particularly useful for columns with a low number of distinct values and work well for boolean or categorical data. Bitmap indexes are efficient for complex queries involving multiple conditions and offer space-efficient storage.
- Clustered index determines the physical order of data rows in a table. It sorts and stores the data based on the indexed column, which can improve the performance of range queries and data retrieval. However, each table can have only one clustered index, and its creation can impact the performance of insert and update operations.
- Non-clustered indexes do not affect the physical order of data rows. They are separate structures that contain a copy of the indexed column and a reference to the corresponding data row. Non-clustered indexes are useful for improving query performance for specific columns and support multiple indexes per table.
- Full-text indexes are specialized indexes used for efficient searching of text data. They enable fast searching for keywords and phrases within textual content, providing powerful text-based search capabilities. Full-text indexes are commonly used in applications involving document management, content search, or text-heavy data.
Choosing the Right Columns to Index for Optimal Performance
Choosing the right columns to index for optimal performance is a crucial aspect of query optimization in a database. When deciding which columns to index, it's important to consider various factors. First, analyze the query patterns in your database to identify frequently used columns in the WHERE, JOIN, and ORDER BY clauses. These columns are good candidates for indexing as they are often involved in filtering, joining, or sorting data.
Next, consider the selectivity and cardinality of columns. Highly selective columns with many distinct values, such as primary keys, are ideal for indexing as they can effectively narrow down the search space and improve query performance. On the other hand, columns with low cardinality, like boolean or gender columns, may not benefit significantly from indexing.
Additionally, examine the data distribution across columns. If a column has an even distribution of values, indexing it can provide better performance gains. However, if the data distribution is skewed with a few values appearing frequently, indexing might not be as effective.
Consider the size of the indexed columns, as indexes require storage space. Indexing large columns can increase storage requirements and impact overall performance. In such cases, you may consider indexing a subset of the column or exploring other optimization techniques.
Furthermore, balance the read and write operations in your database. Keep in mind that indexes incur overhead during data modification operations. Indexing heavily updated columns may introduce additional maintenance overhead without significant performance benefits.
Regularly reviewing and adjusting indexes is essential. Query patterns and data characteristics may change over time, so it's important to remove unused or redundant indexes and create new ones based on updated query patterns or evolving business requirements.
Monitoring and Maintaining Indexes for Continued Performance Gains
Monitoring and maintaining indexes is crucial for continued performance gains in a database environment. Regular monitoring helps identify potential issues and ensures that indexes continue to provide optimal performance. Here are some key practices for monitoring and maintaining indexes:
- Index fragmentation analysis: Fragmentation occurs when index pages become disorganized over time, leading to decreased performance. Regularly analyzing index fragmentation helps identify fragmented indexes that need attention. Tools like index fragmentation reports or database management system utilities can assist in this analysis.
- Index statistics update: Index statistics provide valuable information about the distribution and cardinality of data in indexed columns. Outdated or inaccurate statistics can lead to suboptimal query execution plans. It is essential to update index statistics regularly to ensure the query optimizer makes informed decisions.
- Regular index maintenance: Perform regular index maintenance tasks, such as index reorganization or index rebuild operations. These operations can help improve index efficiency, reduce fragmentation, and optimize query performance. The choice between reorganization and rebuild depends on the severity of fragmentation and the database platform being used.
- Query performance monitoring: Monitor query performance and identify queries that experience performance issues. Analyze execution plans and check for index usage. Queries that don't utilize indexes effectively may benefit from index modifications, such as adding new indexes, modifying existing ones, or rewriting queries to optimize index usage.
- Index usage analysis: Track index usage statistics to determine the effectiveness of existing indexes. Identify indexes that are rarely or never used, as they may introduce unnecessary overhead without providing significant performance gains. Consider removing or modifying such indexes to streamline database operations.
- Regular database maintenance: Perform routine maintenance tasks such as database backups, integrity checks, and index rebuilds on critical tables. These tasks help ensure overall database health and support optimal index performance.
- Performance benchmarking: Benchmark the performance of queries and database operations periodically. Compare performance metrics before and after index modifications to measure the impact of index maintenance activities. This helps validate the effectiveness of index changes and identify areas for further optimization.
Data Sharding
Data sharding is a technique used in database systems to horizontally partition data across multiple servers or nodes. The purpose of data sharding is to distribute the database workload and improve performance by allowing concurrent processing of data across multiple shards. In data sharding, the dataset is divided into smaller, more manageable subsets called shards, and each shard is stored and processed independently on separate database instances.
The primary goal of data sharding is to achieve scalability and handle large datasets efficiently. By distributing data across multiple shards, database systems can handle increased data volumes and higher transaction rates. Sharding enables parallel processing and improves throughput by allowing multiple servers to handle queries simultaneously.
Data sharding is particularly useful in scenarios where a single database instance becomes a bottleneck due to high data volume or heavy workload. By partitioning the data and distributing it across multiple shards, the database system can achieve better load balancing and improved performance.
Additionally, data sharding can provide fault tolerance and high availability. Each shard can be replicated or backed up independently, reducing the risk of data loss and improving system resilience. In the event of a failure or downtime on one shard, the remaining shards can continue to serve data and maintain system availability.
Sharding is commonly used in distributed database systems, big data platforms, and cloud-based architectures where scalability and performance are critical. However, implementing data sharding requires careful planning and consideration of various factors, such as data distribution strategy, shard key selection, data consistency, and query routing mechanisms.
Strategies for Dividing and Distributing Data Across Multiple Database Instances
When implementing data sharding, it is crucial to carefully plan and design strategies for dividing and distributing data across multiple database instances. Here are some common strategies used for effective data sharding:
- Key-based sharding: In this strategy, a shard key is defined based on a specific attribute or column in the dataset. The data is partitioned and distributed across shards based on the value of the shard key. This ensures that related data is stored in the same shard, enabling efficient data retrieval and minimizing cross-shard queries.
- Range-based sharding: With range-based sharding, data is partitioned based on a specific range of values. For example, you can divide data based on a time range or alphabetical range. Each shard is responsible for storing data within a specific range, allowing for easy data management and query optimization.
- Hash-based sharding: Hash-based sharding involves applying a hash function to a unique identifier or key of the data. The hash function determines the shard where the data should be stored. This strategy evenly distributes data across shards and minimizes data hotspots. However, it can make range-based queries challenging since the data is distributed randomly.
- Composite sharding: In some cases, a combination of different sharding strategies may be used to achieve optimal data distribution. For example, you can combine key-based sharding with hash-based sharding to balance data distribution while ensuring efficient query routing.
Considerations and Challenges When Implementing Data Sharding
Data sharding offers significant benefits in terms of scalability and performance for database systems. By distributing data across multiple shards, data sharding allows for horizontal scalability, accommodating the growing dataset by adding additional shards. This results in improved performance and the ability to handle larger workloads.
Sharding also enables parallel processing of data across multiple shards, leading to increased throughput and reduced response times. With each shard handling a portion of the workload, data processing becomes more efficient, particularly in scenarios with high read or write demands.
Furthermore, data sharding facilitates better load balancing by dividing data into shards and distributing it across database instances. This ensures that the workload is evenly distributed, preventing performance bottlenecks and maintaining consistent system performance.
However, implementing data sharding comes with considerations and challenges that need to be addressed. One of the challenges is maintaining data consistency across shards, especially when updates or changes span multiple shards. Techniques such as distributed transactions or eventual consistency models need to be implemented to ensure data integrity.
Efficient query routing is another consideration. Implementing a query router or load balancer that intelligently routes queries based on the shard key or metadata helps optimize query performance and avoid unnecessary cross-shard queries.
Choosing the right shard key is critical for balanced data distribution and query performance. The shard key should evenly distribute data across shards and align with the application's access patterns to prevent data hotspots and uneven load distribution.
Additionally, managing and maintaining shards, including provisioning, data migration, and handling shard failures, can be complex. Proper monitoring and maintenance processes are necessary to ensure the overall health and performance of the sharded database system.
By carefully addressing these considerations and challenges, organizations can successfully implement data sharding, harness its scalability and performance benefits, and overcome any potential hurdles. A thorough analysis of application requirements and thoughtful planning are key to implementing an efficient and robust data-sharding strategy.
Performance Testing
Performance testing plays a crucial role in API and database integration, ensuring that the system meets the expected performance requirements and performs optimally under different workloads. It allows organizations to identify potential bottlenecks, uncover performance issues, and make informed decisions to improve overall system performance.
One of the primary reasons for conducting performance testing is to validate the scalability and responsiveness of the API and database integration. By simulating various user loads and stress scenarios, performance testing helps determine how the system performs under different levels of traffic and usage patterns. It provides insights into response times, throughput, resource utilization, and scalability limits, allowing organizations to identify performance degradation or bottlenecks that may arise with increased usage.
Performance testing also helps uncover inefficiencies in database queries, API calls, or data access patterns. By analyzing performance metrics, organizations can identify slow-performing queries, poorly optimized code, or resource-intensive operations. This information enables developers and administrators to optimize the system, fine-tune query execution plans, and improve overall response times.
Additionally, performance testing helps organizations assess the impact of concurrent user access, heavy workloads, or spikes in traffic on the system's performance. By subjecting the system to realistic and high-load scenarios, organizations can determine its stability, resilience, and capacity to handle peak loads. This information is crucial for capacity planning, ensuring that the infrastructure and resources are adequately provisioned to meet the expected demand.
Moreover, performance testing aids in identifying memory leaks, resource contention issues, or other system abnormalities that may negatively affect performance. By monitoring system resources during testing, organizations can pinpoint any excessive resource consumption, memory leaks, or bottlenecks that may degrade system performance over time. This allows for proactive measures to be taken, such as optimizing resource usage, tuning configuration settings, or addressing memory management issues.
Techniques for Performance Testing
Performance testing involves various techniques to evaluate the behavior and performance of an API and database integration. Some common techniques include:
- Load testing technique simulates realistic user loads by generating a high volume of concurrent requests to assess the system's performance under normal and peak usage scenarios. Load testing helps identify performance bottlenecks, measure response times, and determine if the system meets the expected throughput and scalability requirements.
- Stress testing pushes the system beyond its normal capacity to determine its breaking point or the maximum load it can handle. By applying extreme workloads or increasing the number of concurrent users, stress testing helps identify performance issues, uncover system weaknesses, and assess the system's ability to recover gracefully under heavy load conditions.
- Soak testing involves running the system under a sustained workload for an extended period. This technique helps identify performance degradation over time, memory leaks, resource exhaustion, or other issues that may arise during long-duration usage. Soak testing is particularly useful for assessing the system's stability, robustness, and ability to handle continuous operations.
- Spike testing evaluates the system's performance when there is a sudden and significant increase in user traffic or workload. By simulating abrupt spikes in user activity, spike testing helps identify how the system handles sudden surges in demand, measures response times, and ensures that the system remains stable under such conditions.
Monitoring Tools and Practices for Identifying Performance Bottlenecks
- Application performance monitoring (APM) tools: APM tools provide real-time insights into the performance of an API and database integration. These tools monitor various metrics such as response times, resource utilization, database query execution, and transaction rates. They help identify performance bottlenecks, track system behavior, and diagnose issues that impact performance.
- Logging and tracing: Logging and tracing mechanisms capture detailed information about the system's behavior, including request and response data, query execution details, and error messages. Analyzing logs and traces can help identify performance issues, pinpoint problematic code sections, and understand the flow of data within the system.
- System resource monitoring: Monitoring system resources such as CPU usage, memory utilization, disk I/O, and network traffic provides insights into resource bottlenecks and helps identify performance constraints. Resource monitoring tools help detect excessive resource consumption, identify resource contention, and ensure that the system has sufficient resources to handle the expected workload.
- Real User Monitoring (RUM): RUM tools capture data from actual user interactions with the system, allowing organizations to understand the end-user experience. RUM helps identify performance issues from the user's perspective, such as slow response times or errors encountered during API calls or database interactions.
Strategies for Analyzing and Optimizing System Performance Based on Monitoring Results
Analyzing monitoring data and optimizing system performance requires a systematic approach. One strategy is to identify performance hotspots by analyzing monitoring data. This involves pinpointing slow-performing queries, resource-intensive operations, or inefficient code sections that significantly impact response times or resource utilization.
Once performance hotspots are identified, organizations can prioritize and optimize them. This may involve optimizing database queries, refactoring code, or implementing caching mechanisms to improve response times and reduce resource usage. Techniques such as query rewriting, index optimization, or code profiling can be employed to identify specific areas for improvement.
If performance issues persist, scaling and load-balancing strategies can be implemented. Horizontal scaling, achieved by adding more servers or employing load balancers, helps distribute the workload across multiple instances, improving scalability and enabling efficient handling of increased traffic.
To ensure ongoing performance optimization, organizations should implement a continuous performance testing and monitoring strategy. Regularly testing and monitoring the system under various workloads helps identify performance regressions and allows for prompt resolution. This iterative approach ensures that the system maintains optimal performance over time.
By leveraging these strategies, along with the use of appropriate monitoring tools, organizations can effectively identify and address performance bottlenecks, optimize system performance, and achieve a high-performing API and database integration.
Case Studies: Real-World Examples of Optimized API and Database Performance
Netflix, a popular streaming platform, heavily relies on APIs and databases to deliver content to millions of users worldwide. To optimize their performance, Netflix implemented caching strategies at various levels, including content delivery networks (CDNs) and in-memory caching. By caching frequently accessed data and reducing the load on their databases, Netflix improved response times and provided a smooth streaming experience to their users.
Similarly, Airbnb, an online marketplace connecting travelers with accommodations, deals with a vast amount of data and requires efficient API and database integration. To optimize their performance, Airbnb adopted a data sharding approach, horizontally partitioning their data across multiple databases. This allowed them to scale their infrastructure and handle the growing number of users and listings, resulting in improved scalability and response times.
Twitter, a popular social media platform, faces the challenge of handling high volumes of real-time data and delivering it to millions of users. To optimize their API and database performance, Twitter implemented advanced caching techniques and utilized in-memory databases. By caching frequently accessed data and leveraging in-memory storage, Twitter improved response times, reduced the load on their databases, and provided a seamless user experience even during peak usage periods.
Similarly, Shopify, an e-commerce platform, relies on APIs and databases to support thousands of online stores. To optimize their performance, Shopify implemented query optimization techniques, including query rewriting and query plan analysis. By analyzing and optimizing their database queries, Shopify improved the efficiency of their operations, resulting in faster response times and better overall performance for their merchants and customers.
These case studies serve as inspiration and provide insights into successful strategies for optimizing API and database performance. By adopting similar techniques and best practices, organizations can enhance scalability, reduce response times, and deliver exceptional user experiences in their own systems.
Conclusion
In conclusion, this article has explored various techniques for optimizing API and database performance. We discussed the importance of caching, query optimization, indexing, data sharding, performance testing, and monitoring. These techniques play a crucial role in improving response times, scalability, and overall system performance.
It is essential to emphasize the importance of continuously monitoring and improving performance. Technology landscapes are constantly evolving, and user expectations continue to rise. By regularly monitoring performance metrics, identifying bottlenecks, and making necessary optimizations, organizations can ensure that their API and database integration remains performant and meets user demands.
We encourage organizations to implement these techniques and best practices to enhance their system performance. Whether it is implementing caching mechanisms, optimizing queries, leveraging appropriate indexing, adopting data sharding, conducting performance testing, or employing monitoring tools, each technique contributes to a more efficient and reliable system.
By optimizing API and database performance, organizations can provide better user experiences, handle increased workloads, and achieve scalability. Furthermore, improved system performance leads to enhanced customer satisfaction, increased productivity, and a competitive edge in today's digital landscape.
Opinions expressed by DZone contributors are their own.
Comments