Building Your API Gateway From OpenAPI Specs: A Spec-Driven Approach
Generate API gateways directly from OpenAPI specs to eliminate configuration drift, simplify maintenance, and keep your API contract as the single source of truth.
Join the DZone community and get the full member experience.
Join For FreeGenerating an API Gateway From OpenAPI Specs
Five Key Takeaways
- When your OpenAPI specification becomes the single source of truth, the gap between your API contract and your gateway configuration simply stops existing.
- Generating the gateway from the spec scales far better than hand-maintaining per-endpoint configuration as your API surface grows into the hundreds.
- Generated, human-readable service code keeps day-to-day operations manageable — you can read it, reason about it, and trace failures like ordinary software.
- The genuinely hard part is not the generation; it's the regeneration workflow and the discipline around where custom logic is allowed to live.
- Adopt the model on new APIs first, prove it's boring and trustworthy, and only then migrate existing ones.
The Quiet Way Gateways Rot
Every public API gateway I've worked with started its life clean and, over a few years, quietly accumulated a second universe of hand-written configuration sitting alongside the services it fronts. None of it looked dangerous at the time. A path rewrite here. A parameter rename there. A response transform to make an internal field look the way customers expect it to. A content-type translation to bridge two teams that made different choices years apart. Each individual edit was sensible, small, and well-intentioned. The danger was never any single change — it was the accumulation, and more importantly, the separation.
That configuration described how the gateway should behave, but it lived in a different place from the thing it was describing: the API's actual contract. Two artifacts, two repositories, two owners, two review processes, two release cadences — all trying to stay in agreement about the same set of endpoints. Anyone who has run a system like this knows how that story ends. The two drift apart. A backend team renames a field and ships their service. The matching gateway mapping doesn't get updated because it's someone else's pull request in someone else's repo. Nothing fails loudly. A customer-facing response is simply, silently wrong. And the place you now have to go and debug is the gateway — the one component that every single request flows through, and therefore the one component nobody wants to touch under pressure.
This is the real tax of treating gateway configuration as a hand-maintained artifact. It isn't the effort of writing the config. It's the slow, compounding cost of keeping two sources of truth honest with each other, forever, across a growing number of teams who have no structural reason to remember that the other one exists.
A Different Premise: The Contract Is the Configuration
The shift that fixes this is conceptually simple, even if it takes real engineering to operationalize. Instead of describing the gateway's behavior in a separate configuration language, you let the API's own contract define it. If you already maintain an OpenAPI specification — and most teams serving public APIs do — then that document already contains nearly everything the gateway needs to know. It knows the routes. It knows the HTTP methods. It knows the path and query parameters, the request bodies, the response shapes, the status codes. It is, in effect, a complete and precise description of the public surface.
The premise of a specification-driven gateway is to stop treating that document as mere documentation and start treating it as the source from which the gateway is produced. You write the contract once. The gateway is generated from it. There is no second artifact to keep in sync, because there is no second artifact. When the contract changes, the gateway changes, by construction, because one is derived from the other rather than maintained in parallel with it.
That single move — collapsing two sources of truth into one — is where almost all of the long-term benefit comes from. Everything else is mechanics.
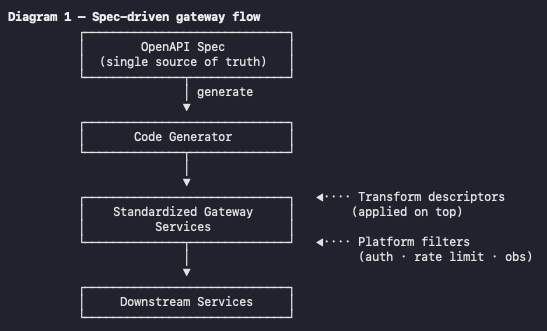
What "Generating the Gateway" Really Means
In practice, you point a generator at the specification, and it produces standardized service code: the routing, the request and response models, the parameter binding, all wired to the operations the spec declares. The open-source tooling for this is mature; a single command turns a specification file into a working, conventional codebase. It looks roughly like this, and this is about as code-heavy as the idea needs to get:
openapi-generator-cli generate -i widgets.yaml -g spring -o ./widgets-gatewayWhat comes out the other side is not a black box or an opaque configuration blob. It is ordinary source code — the kind your engineers already know how to read, test, and debug. That property turns out to matter enormously in production. When something misbehaves at two in the morning, the difference between "decode the gateway's configuration DSL and infer what it's doing" and "open the generated method and read it" is the difference between a long incident and a short one.
The second property that matters is consistency. Because every API is produced by the same generator from the same kind of input, every API behaves the same way. They log the same way, page the same way, validate the same way, and fail the same way. Cross-cutting behavior — the way you emit metrics, the shape of your error responses, your house conventions — is expressed once, in the generation templates, and then applied uniformly to every endpoint on the platform. What used to be a hundred manual edits scattered across a hundred config files becomes a single change in one place. That uniformity is quietly one of the most valuable things you get, because it makes the entire API surface predictable, and predictability is what lets you operate at scale without heroics.
Where the Custom Logic Is Allowed to Live
No real gateway is pure generation. There is always behavior that the specification doesn't capture cleanly — renaming a public field to its internal equivalent, translating between formats, enforcing authentication, applying rate limits that differ by endpoint. The instinct, when you first hit one of these, is to reach into the generated code and edit it by hand. That instinct is po design against, because the moment someone hand-edits generated output, the next regeneration either erases their work or forces a painful manual merge, and the whole model starts to feel fragile and untrustworthy.
The discipline that keeps it healthy is to treat the generated code as strictly read-only and to give every piece of custom behavior a designated home outside of it. Field mappings and transforms become declarative descriptors that the build applies on top of the generated services — they sit next to the contract, version alongside it, and never touch the generated files. Custom authentication filter lives in clearly marked extension points that the generator is explicitly told to leave alone. Cross-cutting platform concerns — auth, rate limiting, observability — don't get regenerated per API at all; they run as middleware in front of the generated handlers and read their policy from annotations carried in the specification itself, so even the operational rules trace back to the one source of truth.
Stated as a rule for code review, it's a single sentence: never hand-edit generated code. Everything custom is either an override of its templates, or an extension point it has been told not to overwrite. Hold that line, and the model stays clean for years. Let it slip, and you slowly reinvent the very drift you were trying to escape.
The Regeneration Workflow Is the Actual Work
It's tempting to think the generator is the hard part. It isn't. The generator is a solved problem. The thing that determines whether this approach survives contact with a real organization is the workflow around it — the pipeline that takes a change to the specification and turns it into a deployed gateway, reliably and visibly, every time.
That pipeline has a few stages, and each one earns its place. The specification gets validated on every change, so a mes generation. The code gets regenerated in a clean, reproducible step with a pinned tool version, so there's no "work on my machine" drift. The generated output gets diffed, and that diff is surfaced directly in the pull request — this is the stage teams are most tempted to skip and most regret skipping, because being able to see exactly what a one-line spec change did to the gateway is the single thing that earns engineers' trust in the whole system. And then it gets tested, including a contraended change to the public shape before a customer does.
The cultural shift underneath all of this is that you start treating the specification like source code rather than lisioned, reviewed, and gated on the pipeline passing, exactly as your application code is. Once teams internalize that the spec is the system, the rest follows naturally.
The Trade-Offs, Stated Honestly
This approach is not free, and pretending otherwise does no one any favors. The regeneration loop has a real cost: if it's slow or flaky, engineers will route around it and start hand-editing, and the moment they do, you've lost the entire benefit. Making that loop
fast, reproducible, and trustworthy is not a nice-to-have; it's the price of admission. Generated code also tends to brson would hand-write — that's the cost of standardization, and while it usually pays for itself many times over, it's a real thing your engineers will notice. And custom logic, as discussed, needs a clear and well-understood home from day one, or it quietly leaks back into the generated files and rots the model from the inside.
None of these are reasons not to do it. They're reasons to do it deliberately, with the workflow and the conventions designed up front rather than discovered painfully later.
How to Adopt It Without a Painful Migration
The worst way to introduce this is all at once, as a big-bang rewrite of an existing, heavily-configured gateway. The right way is to start where there's nothing to reconcile: new APIs. Build them spec-first from the beginning, and use them to prove out the generator, the templates, the extension points, and the pipeline in a low-stakes setting. Let the workflow become boring — trust without thinking about it- begin migrating existing APIs one resource at a time, leaning on the diff step to confirm that each one behaves identically before and after the switch. Incremental, observable, reversible — that's how a model like this takes root without putting the platform at risk.
Closing Thoughts
Generating your gateway from OpenAPI specifications doesn't make complexity disappear. What it does is move the complexity from a place where it hurts you - brittle, drifting, hand-maintained configuration spread across teams — to a place where it's manageable: a disciplined specification-and-pipeline workflow with a single source of truth.
In exchange, you get a gateway whose be contract your consumers already read, generated consistently across your entire API surface, debuggable like ordinary software, and safe to change because every change flows through validation, generation, and a visible diff. For a large, multi-team platform, that is a trade well worth making — and, in my experience, one you only wish you'd made sooner.
Opinions expressed by DZone contributors are their own.
Comments