API Test Parameterization With Spock
In this blog post, a performance testing expert will cover the different ways one can parameterize Groovy tests in Spock.
Join the DZone community and get the full member experience.
Join For FreeSpock, a comprehensive testing framework (learn more here) for Java and Groovy, is very flexible when it comes to parameterized tests. Spock offers a complete portfolio of parameterizing techniques that can be adapted to your test, even for very complex tests. This blog post will cover different ways to parameterize Groovy tests in Spock.
Testing is not always trivial, especially when your testing is based on incoming data. For example, if you have an API endpoint that accepts a textual input, and then executes a specific action on the backend based on this input, this will mean that the test body (the code) itself is the same, but the incoming data is different (the execution results might also be different).
You can write the same test multiple times and change the data each time, but there is an easier and quicker way to run these kinds of tests. This way is called parameterization.
Parametrization is the technique of changing test data for the same test method and thus making the test run the same code for changing data. In other words, we run the same tests for different data. Parameterization removes code duplications, making tests clearer and nicer to work on, it saves time, and it makes test management easier.
The easiest way to detect the need for parametrization is to ask yourself every time you copy/paste an existing test, "Is this test that much different from the previous one?" If the answer is 'no,' then it is time for parameters to come into play.
Parameterizing Tests in Spock
Let's look at an example. Assume we have a method in our API backend that takes the parameter 'filename' and returns 'true' if the file type is JPG or JPEG, and 'false' if it is TIFF or BMP. The Spock test for this method without parameterization would be the following:
def "validate image with extension JPG"() {
given: "image validator and a jpg file"
ImageNameValidator validator = new ImageNameValidator()
pictureFile = 'building.jpg'
expect: "that the filename is valid"
validator.isValidImageExtension(pictureFile)
}
def "validate image with extension JPEG"() {
given: "image validator and a jpeg file"
ImageNameValidator validator = new ImageNameValidator()
pictureFile = house.jpeg'
expect: "that the filename is valid"
validator.isValidImageExtension(pictureFile)
}
def "validate image with extension BMP"() {
given: "image validator and a bmp file"
ImageNameValidator validator = new ImageNameValidator()
pictureFile = 'dog.bmp
expect: "that the filename is invalid"
!validator.isValidImageExtension(pictureFile)
}
def "validate image with extension TIFF"() {
given: "image validator and a tiff file"
ImageNameValidator validator = new ImageNameValidator()
pictureFile = cat.tiff
expect: "that the filename is valid"
!validator.isValidImageExtension(pictureFile)
}Notice that each test method by itself is a well-structured code snippet. Each test/step is documented, tests one piece of data, and the trigger action is a short piece of code. The problem stems from the collection of all of these test methods one after another in the script, as they all have the exact same business logic. Parameterization will turn the complex duplications into "clean code," which is clearer, quicker, and easier to manage.
Now let's use Spock's power to parameterize this same test:
def "validate #pictureFile for extension validity"() {
given: "image validator and an image file"
ImageNameValidator validator = new ImageNameValidator()
expect: "that the filename is valid"
validator.isValidImageExtension(pictureFile) == isPictureValid
where: 'sample image names are:'
pictureFile || isPictureValid
'building.jpg' || true
'house.jpeg' || true
'dog.bmp' || false
'cat.tiff' || false
}Now, the test method examines multiple scenarios, in which the test logic is always the same (validate filename) and only the input and output is different. The test code is fixed, the test input and output data come in the form of parameters, and thus you have a parameterized test!
Now we will look at the different and advanced ways to parameterize your tests in Spock shown in the code above. We will do so by using Spock's Where Block, with two methods: with data tables, for simpler use cases, or with data pipes, for more complex cases. Don't worry, we will explain everything.
Writing Parameters by Using the Where Block of Spock
In Spock, the test method is structured into 'Blocks.' Different blocks are used for different functions. Spock has several blocks:
- setup/given - responsible for setting up the test.
- when/then - triggers the code/defines what is under test.
- and - adjustment block, used in pair with all other blocks (given: and: , when: and: etc., etc.).
- expect - same as then:
- cleanup - cleans up the setup
- where - the block that is responsible for parametrization
The where: Block is the structure that is responsible for input and output parameters for parameterized tests. The Spock framework treats everything after the where: Block as parameters and is able to manipulate and create "separate" tests for each "line" of parameters. The where: Block can be combined with all other blocks, but it has to be the last block inside the Spock test. Only an and Block might follow a where: Block (and that would be rare).
In the code we used, this is the where: Block:
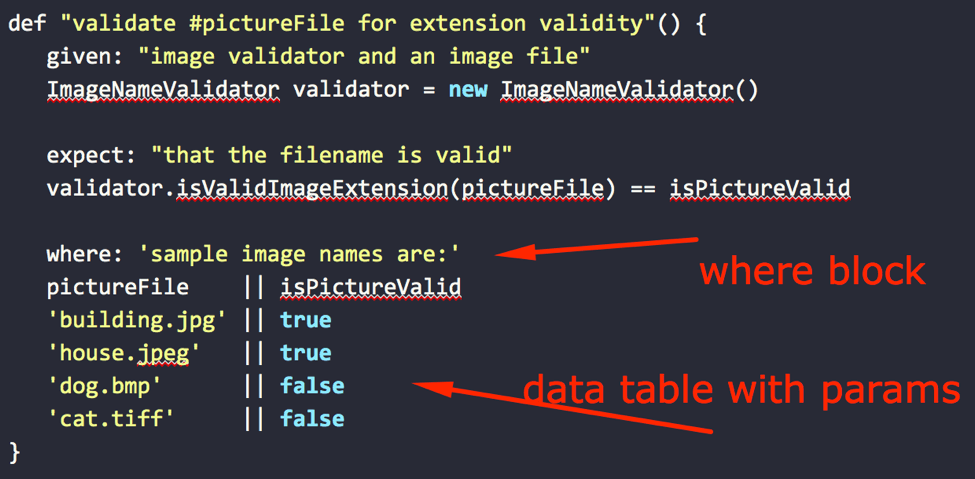
Option 1 - Using Data Tables
The example code also uses data tables. Data tables are the default way to write parameters in the where: Block.
A data table can hold multiple tests, in which each line is a scenario and each column is an input or output variable for that scenario. The data table contains a header that names each parameter. You have to make sure that the names you give the parameters do not clash with existing variables in the source code (either in local or global scope).
This is the data table in the example:
The usage of the dual pipe symbol (||) is used strictly for readability and does not affect the way Spock uses the data table. You can omit it if you think it is not needed, but my recommendation is to always keep it. The dual pipe is used in data tables to mark where the test data is finished and the data that you are validating is started.
Data Tables Limitations
There are three main where: Block limitations:
- The where: Block has to be last.
- The parameter should describe its variable type.
- Spock data tables must have at least two columns. If you are writing a test that has only one parameter, you must use a "filler" in the form of
-for a second column, as shown in the following code snippet.
def "Tiff, gif, bmp and mov are invalid extensions"() {
given: "an image extension checker"
ImageChecker checker = new ImageChecker()
expect: "that the only valid filenames are accepted"
!checker.isImageValid(pictureFile)
where: "sample images are:"
pictureFile || -
'screenshot.tiff' || -
'IM4.gif' || -
'IMG234.bmp' || -
'sky.mov' || -
}Spock supports the following types of data tables (read more) :
- Data tables - This is the declarative style. Easy to write but doesn't cope with complex tests. Readable by nontechnical people.
- Data tables with programmatic expressions as values - A bit more flexible than data tables but with some loss in readability.
- Data pipes with fully dynamic input and output - Flexible but not as readable as data tables.
- Custom data iterators - Your nuclear option when all else fails. They can be used for any extreme corner case of data generation. Unreadable for nontechnical people.
Viewing Test Results With the @Unroll Annotation
It's important to understand that the where: Block is a parameterized test that "spawns" multiple test runs (as many lines that it has). This means that a single test method that contains a where: Block with three scenarios will be run by Spock as three individual test methods (with the same code). All the scenarios of the where: Block are tested individually.
Unfortunately, for compatibility reasons, Spock still presents the collection of parameterized scenarios as a single test in the testing environment.
This is not a problem when all the tests in the parameterized test succeed. But when one of them fails, we are in trouble. Because then the whole test will be shown as failed.
This is where the @Unroll annotations come in. We need to annotate our test method with @Unroll as shown in this code snippet:
@Unroll
def "validate #pictureFile for extension validity"() {
given: "image validator and an image file"
ImageNameValidator validator = new ImageNameValidator()
expect: "that the filename is valid"
validator.isValidImageExtension(pictureFile) == isPictureValid
where: 'sample image names are:'
pictureFile || isPictureValid
'building.jpg' || true
'house.jpeg' || true
'dog.bmp' || false
'cat.tiff' || false
}Then you will see all the executions separately:
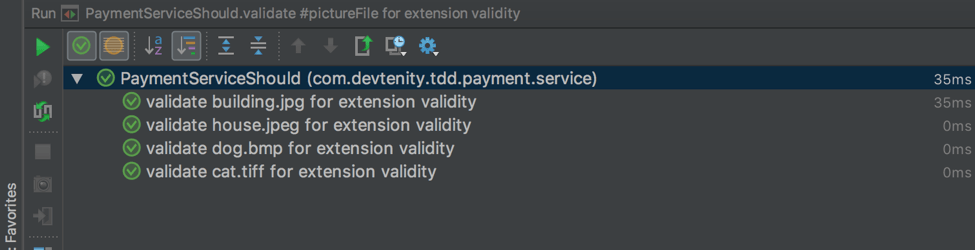
Now, if one of the tests fails, you will see the following results:

By the way, all the data tables we saw so far contain scalar values. But nothing is stopping you from using custom classes, collections object factories or any other Groovy expressions.
Option 2 - Using Data Pipes for Calculating Input/Output Parameters
Data pipes are a lower-level construct of Spock parameterized tests that can be used when you want to dynamically create/read test parameters.
Our example code snippet with data pipes will look like this:
def "validate #pictureFile for extension validity"() {
given: "image validator and an image file"
ImageNameValidator validator = new ImageNameValidator()
expect: "that the filename is valid"
validator.isValidImageExtension(pictureFile) == isPictureValid
where: 'sample image names are:'
pictureFile << ['building.jpg', 'house.jpeg', 'dog.bmp', 'cat.tiff']
isPictureValid << [true, true, true, false]
}Take a peek at the where: Block in this code. This is the only difference when changing the data table to the data pipes (read more).
Now we will go over three types of parameters you can calculate in data pipes: dynamic parameters, constant parameters, and dependent parameters.
Dynamic Parameters
In some cases, you need data from a certain range but you don't care which number from the range is tested. For example, if you need to hit an endpoint of your API with any number between 1 and 1,000. Obviously, you won't write all the options by hand. For these needs, you can use auto-generated ranges.
Here is how to write the ranges in Groovy. The left facing arrows (called leftShift in Groovy) are idiomatic Groovy that allows you to use the leftShift method to append actions, and they connect the values to the data variable. The value range is put in square brackets. The dots mean "to."
numberToPost << [10..1000]Another helpful auto-generation can be used by consuming GroovyCollections.combinations. GroovyCollections.combinations is a default Groovy library, as shown in the following snippet (read more). Here, the range is all the combinations of sample/Sample/SAMPLE with all possible variations of the j p e g letters. (Ex: sample.jpeg, sample.sPeg, SAMPLE.jpEG, etc.).
GroovyCollections.combinations([['sample.', 'Sample.', 'SAMPLE.'],
['j', 'J'], ['p', 'P'], ['e', 'E'], ['g','G']])*.join()Constant Parameters
There are times when one or more parameter stays constant during the complete test. In these cases, instead of using the left shift operator, you can use the assignment operator (=).
where: 'sample image names are:'
pictureFile << ['building.jpg', 'house.jpeg', 'dog.bmp', 'cat.tiff']
isPictureValid = trueIn this code, we can see the second param is constant and it will always stay true for all test executions. This is pretty nice because as developers we do not like code duplications.
Dependent Parameters
Parameters can also depend on each other:
where: "some values are dependant"
firstNumber << [1, 2, 3, 4, 5]
secondNumber = firstNumber * 2As we see in the snippet above, the parameter secondNumber is constructed from the parameter firstNumber multiplied by 2. This means that you do not need to redefine values if you already have them in the other parameter.
That's it! You now know how to write parameterized tests in Spock. Let us know in the comments sections if you have any questions.
Published at DZone with permission of . See the original article here.
Opinions expressed by DZone contributors are their own.
Comments