Approaches to Masking Email Addresses
Using Data Masker for SQL Server from Redgate Software, you are able to not only preserve the demographic, usefulness, and integrity of the data.
Join the DZone community and get the full member experience.
Join For FreeA recent Data Governance Survey conducted by Redgate of over 500 SQL Server professionals showed that 61% of respondents were using production data for non-production workflows; a process that is often seen as necessary for the reliability of development, testing, and other similar workflows. However, with data privacy legislation such as the GDPR, POPI, and HIPAA, we can often be prevented from utilizing this data unless we are able to anonymize/pseudonymize or mask it first.
When masking these sets of data, we are often required to mask a variety of data-types from names to credit card numbers and, unsurprisingly, email addresses. Ultimately, data copied into pre-production workflows should never compromise the security of data subjects stored in production; the most obvious blunder to avoid being never accidentally sending an email to all your contacts that exist in Test.
There are several ways to achieve the desired effect of anonymizing/pseudonymizing these email addresses and this post discusses a few frequently used approaches, as well as how you can use Redgate's Data Masker for SQL Server to achieve realistic masking of email columns.
NULL or TRUNCATE

If you want to be sure that you've protected all the sensitive emails, and do not have the desire to remove all sensitive information altogether, as Wetherspoons chose to do, you can either completely TRUNCATE the tables, or NULL out all the emails so that there is no sensitive data at all. This has the benefit of complete peace of mind but comes at the cost of not having realistic information in any pre-production environments, which is (most often) useful for developing meaningful changes or fixes.
UPDATE All the Rows With the Same Fake Email

Sometimes it is not enough to simply NULL all of the addresses because the field is used for testing or development purposes and you need to have something (anything) displayed. Updating all of the email addresses to the same fake value would not only allow you to protect the details of the data subjects but also to return some data for queries, making it more useful than the previous technique.
UPDATE All the Emails to Be Random

There are many ways to achieve the technique of randomizing email addresses. The screenshot above demonstrates potentially the easiest way of achieving this by generating a unique value (of type uniqueidentifier) of a certain length and appending it with a fake email address.
The code can be expanded so that you only generate strings of certain lengths, containing only certain characters, and it only appends it with certain email addresses randomly, and this would give you different values for different rows in the table. This means that you'll have realistic dev and test results with specific values (like [email protected]) that you can trace back to certain rows if you are investigating certain issues.
Use Data Masker for SQL Server (1): Insertion/Substitution Rules
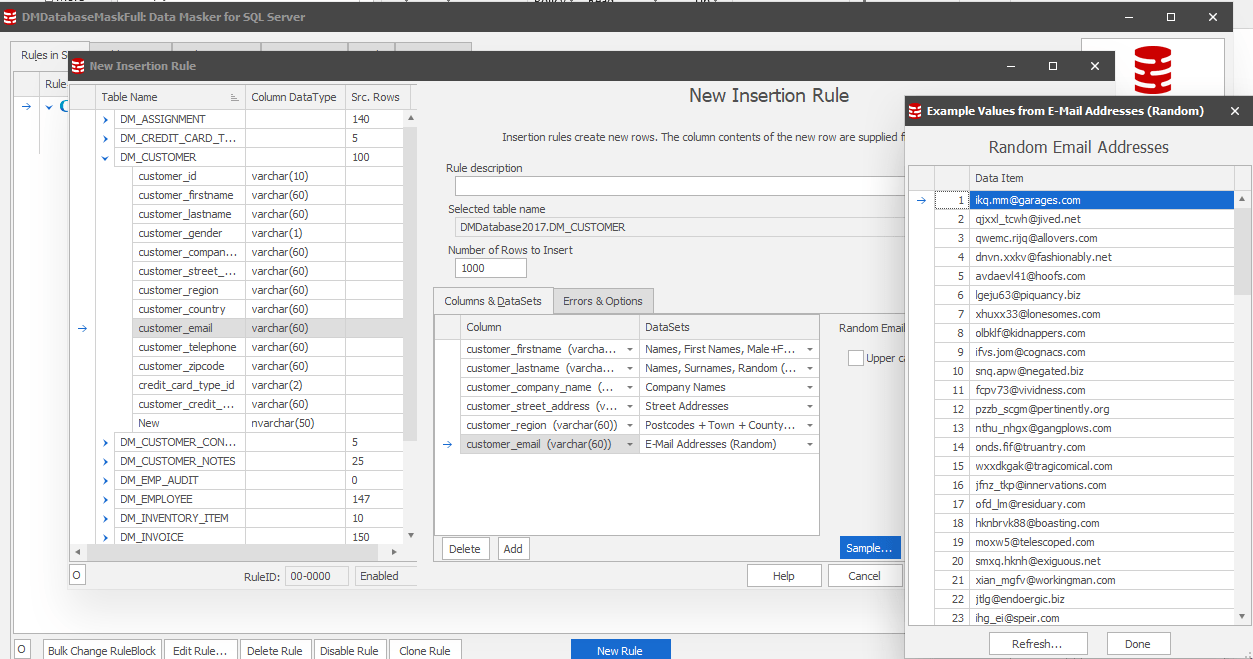
In Redgate's Data Masker for SQL Server, you have the option to either generate brand new rows of information (Insertion Rules) or substitute existing rows with realistic and/or random data (Substitution Rules). Not only can we use the pre-existing random Email Addresses Dataset, but it also allows us to generate or substitute values for everything from names to SSNs to zip codes with respective States and Towns, etc.
This way you can either start afresh with realistic data or retain the other potentially useful columns in the rows which do not contain any sensitive data. This keeps the masked data useful and can allow you to retain the demographics for dev/test/reporting purposes.
Use Data Masker for SQL Server (2): Row-Internal Sync Rules
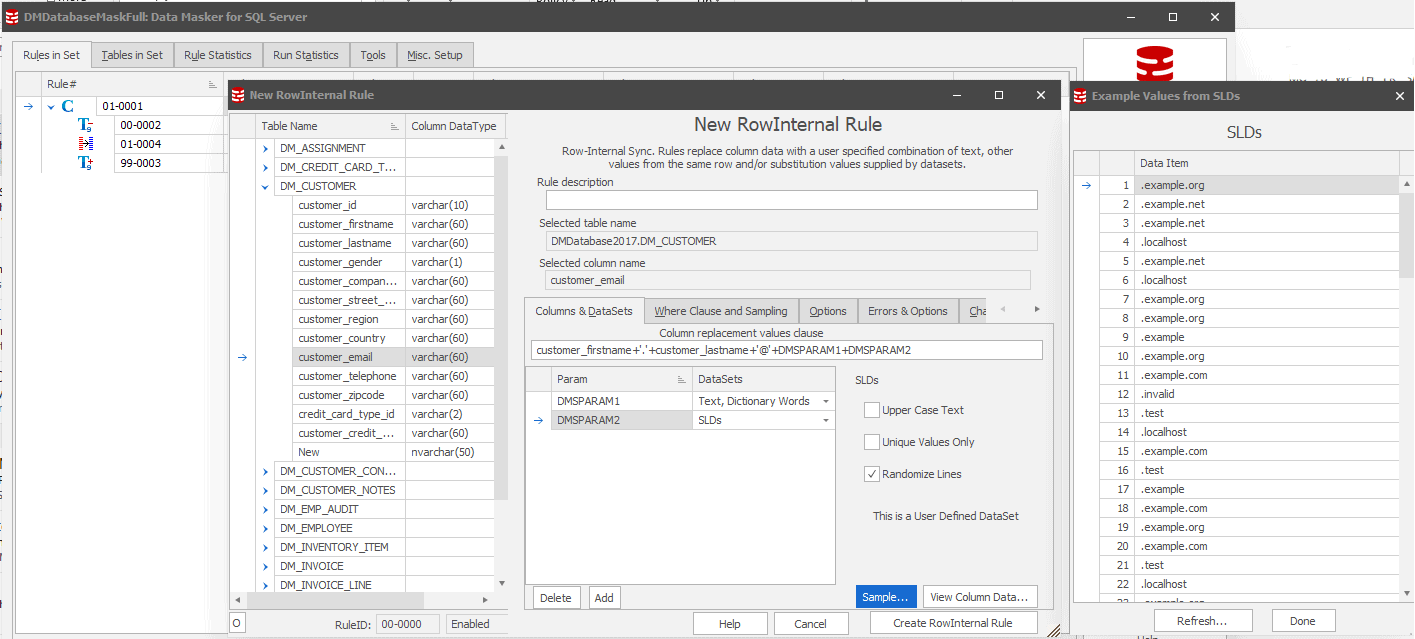
When you use Data Masker for SQL Server to mask the other values in a table, such as names, we can use this information to generate realistic email addresses based on those very same masked values. In this instance, you have a row of data that has already been masked (using a Substitution Rule) as 'Jamie' and 'Smith' (First and Last Name columns), and you want an email address that reflects this to further add to the usefulness and ease of interpretation of the data.
Using a Row-Internal Sync Rule in Data Masker, we can concatenate these masked values together with random email domains (in this example, I use a user-defined dataset 'SLDs' to give values such as @example.com). The example given above uses the masked First and Last Name columns, '.', '@' and a mixture of random dictionary words and second level domains to give an email address like [email protected], which looks realistic and is broadly useful, but ultimately will never compromise the original data subject's information.
Use Data Masker for SQL Server (3): Retaining Email Spread Uusing the Sync Manager
In some rare situations, it may be desirable to retain the spread of email addresses such that @gmail.com and @hotmail.com are always masked to the same values so the data set is truly representative of the data you're going to be working with. By using a combination of the above techniques as well as a couple of Command and Sync Rules, we can get around this using Data Masker.
In the below example (assuming we have already masked the name columns), we follow through the process which is:
- Use a Command Rule in Data Masker to substring the email column to be just the email domains.
- Use a Row-Internal Sync rule converted to a Sync Manager Rule (the change manager tab in the rule) to preserve the spread of domains so emailone.co.uk would always become emailtwo.co.uk, etc.
- Use a Row-Internal Sync rule to synchronize these values with the masked name fields.
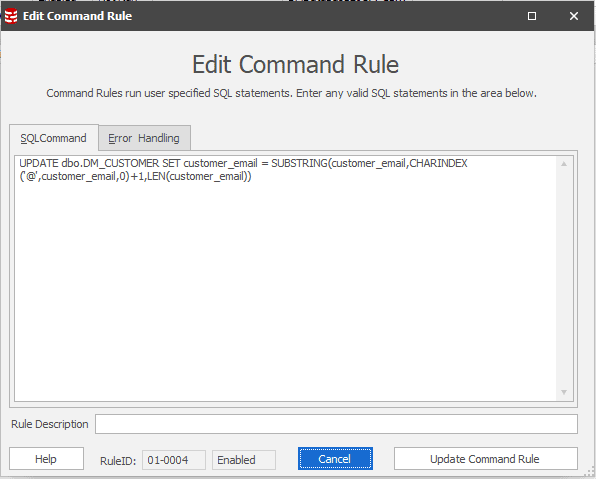 Figure 1: Create a Command Rule to substring the email address
Figure 1: Create a Command Rule to substring the email address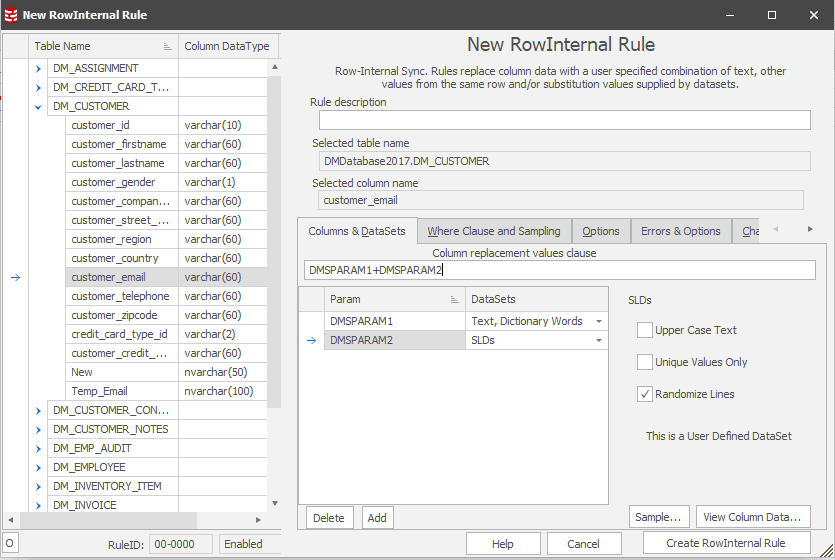 Figure 2: Create Row Internal rule to generate new email domains
Figure 2: Create Row Internal rule to generate new email domains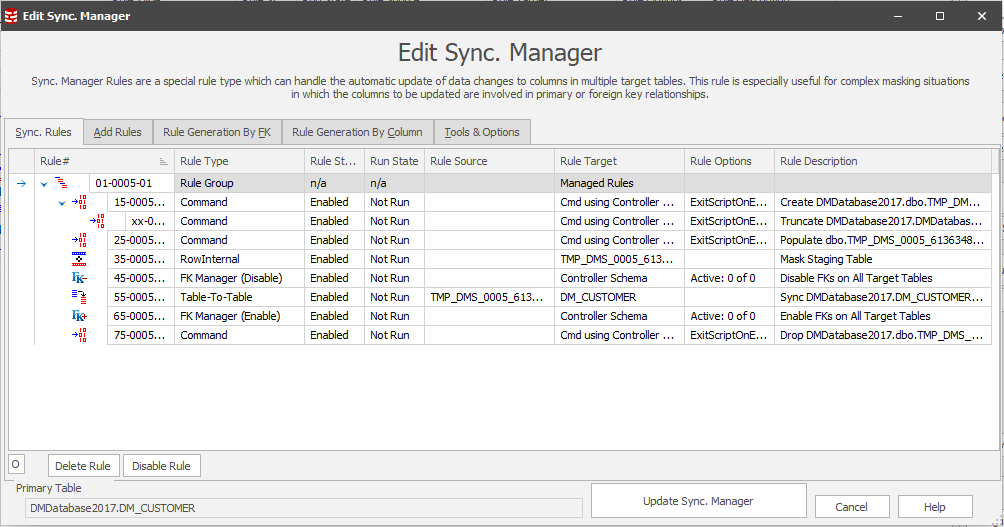 Figure 3: Convert rule to Sync Manager (change manager tab) - this will create a staging table during the masking operation which holds the distinct values and will map them to new masked values.
Figure 3: Convert rule to Sync Manager (change manager tab) - this will create a staging table during the masking operation which holds the distinct values and will map them to new masked values.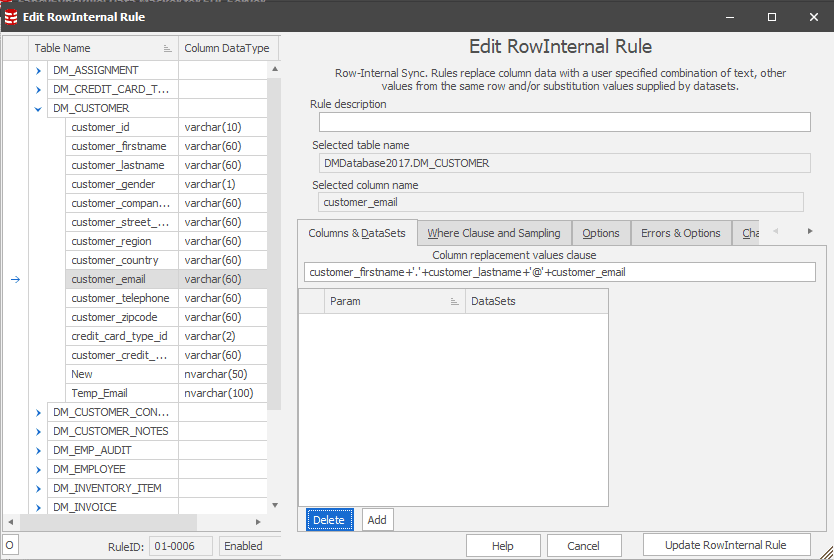 Figure 4: Define a new Row-Internal Sync rule to repopulate customer_email with the masked name values and the newly masked email domains
Figure 4: Define a new Row-Internal Sync rule to repopulate customer_email with the masked name values and the newly masked email domains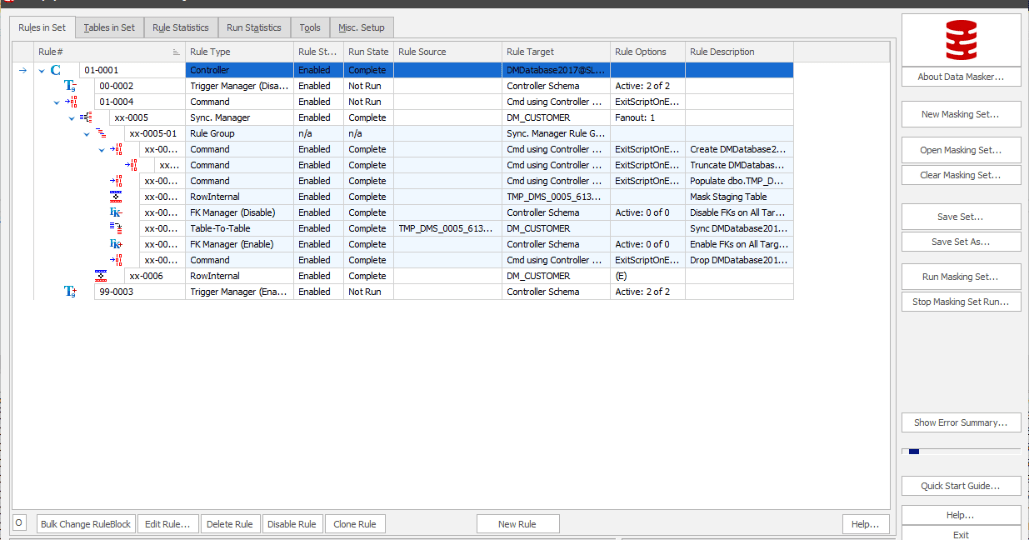 Figure 5: Final ruleset as it appears in Data Masker
Figure 5: Final ruleset as it appears in Data Masker Figure 6: Data before the masking set run
Figure 6: Data before the masking set run Figure 7: Data post-masking set run
Figure 7: Data post-masking set run
Conclusion
Although there are many methods to achieve the result of masking sensitive information in your databases, it is generally accepted that regardless which approach you take, it is considered best practice to ensure that you are protecting the original individual to whom the data relates to allow the wider processing of this information. More information about this can be found in the Anonymization Code of Practice from the UK's Information Commissioner's Office.
Using Data Masker for SQL Server from Redgate Software, you are able to not only preserve the demographic, usefulness, and integrity of the data you're using in non-production workflows but ensure you're not duplicating sensitive data and growing the risks typically associated with data protection.
Published at DZone with permission of Chris Unwin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments