Apriori Itemset Generation With Oracle SQL
Explore an Apriori itemset generation with Oracle SQL.
Join the DZone community and get the full member experience.
Join For FreeThe Apriori Principle is given by the following description:
If an itemset is frequent, then all of its subsets must also be frequent. Conversely, if a subset is infrequent, then all of its supersets must be infrequent too.
In this article, I have tried to generate the most frequent items with Oracle SQL.
The data used in this article is given below:

First, I created a table named "APR_ITEMS_BOUGHT" with the following script and manually inserted the data into the table:
CREATE TABLE APR_ITEMS_BOUGHT
(
TID NUMBER,
ITEMS VARCHAR2(50)
)After creating the table above, the itemsets are inserted in columns to a new table. The script for generating the table is:
CREATE TABLE APRIORI
(
TID NUMBER,
ITEM_A varchar2(10),
ITEM_B varchar2(10),
ITEM_C varchar2(10),
ITEM_D varchar2(10),
ITEM_E varchar2(10),
ITEM_F varchar2(10)
)Finding the frequent itemsets has two steps:
- Generating candidate items set
- Generating frequent items set
Now the itemset generation can be started. The first candidate table "C1" is created in the following script;
create table C1 AS
SELECT ITEM ITEM_1, CNT, ALL_CNT FROM (
select 'A' ITEM, SUM(CASE WHEN ITEM_A = 'A' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
UNION ALL
select 'B' ITEM, SUM(CASE WHEN ITEM_B = 'B' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
UNION ALL
select 'C' ITEM, SUM(CASE WHEN ITEM_C = 'C' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
UNION ALL
select 'D' ITEM, SUM(CASE WHEN ITEM_D = 'D' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
UNION ALL
select 'E' ITEM, SUM(CASE WHEN ITEM_E = 'E' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
UNION ALL
select 'F' ITEM, SUM(CASE WHEN ITEM_F = 'F' THEN 1 ELSE 0 END) CNT, COUNT(*) ALL_CNT
from apriori
)
Then the frequent itemset is created. I choose min support and min confidence values as:
- Min support %40
- Min confidence %60
create table F1 AS
SELECT ITEM_1, SUPPORT, CNT FROM (
SELECT ITEM_1, CNT / ALL_CNT SUPPORT, CNT FROM C1
)
WHERE SUPPORT >= 0.4 --PRUNINGThe result of both the "C1" and "F1" sets are shown below;

The C1 table has three columns: ITEM column gives the items in the market basket, CNT column gives how many transactions the item has, and ALL_CNT column gives all transactions count. After pruning with a %40 support value, we are left with the following frequent itemsets:
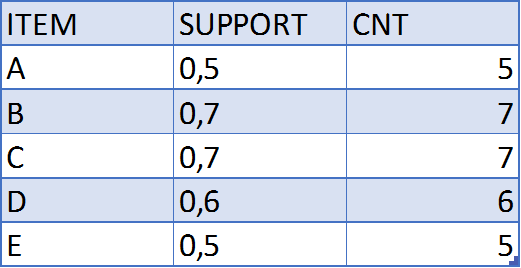
The F1 table has also three columns: the ITEM column, SUPPORT value for each column, and the transaction count in the CNT column.
For the second itemset generation and frequent itemset, the pruned F1 table will be used.
CREATE TABLE APRIORI_VERTICAL AS
SELECT TID, ITEM_A ITEM FROM APRIORI A
WHERE ITEM_A <> '0'
UNION ALL
SELECT TID, ITEM_B ITEM FROM APRIORI A
WHERE ITEM_B <> '0'
UNION ALL
SELECT TID, ITEM_C ITEM FROM APRIORI A
WHERE ITEM_C <> '0'
UNION ALL
SELECT TID, ITEM_D ITEM FROM APRIORI A
WHERE ITEM_D <> '0'
UNION ALL
SELECT TID, ITEM_E ITEM FROM APRIORI A
WHERE ITEM_E <> '0'
UNION ALL
SELECT TID, ITEM_F ITEM FROM APRIORI A
WHERE ITEM_F <> '0'
CREATE TABLE FREQ_ITEM_2 AS
SELECT A.ITEM_1, B.ITEM_1 ITEM_2
FROM F1 A , F1 B
WHERE A.ITEM_1 < B.ITEM_1
CREATE TABLE C2 AS
SELECT Z.ITEM_1 ITEM_1, Z.ITEM_2 ITEM_2, CNT, REC_CNT ALL_CNT, FIRST_INSTANCE_COUNT
FROM
(
SELECT C.ITEM_1, C.ITEM_2, COUNT(DISTINCT C.TID) CNT
FROM
(
SELECT * FROM FREQ_ITEM_2
) X
INNER JOIN
(
SELECT A1.TID, A1.ITEM ITEM_1, A2.ITEM ITEM_2
FROM APRIORI_VERTICAL A1 CROSS JOIN APRIORI_VERTICAL A2
WHERE A1.TID = A2.TID
AND A1.ITEM < A2.ITEM
) C
ON X.ITEM_1 = C.ITEM_1 AND X.ITEM_2 = C.ITEM_2
GROUP BY C.ITEM_1, C.ITEM_2
) Z
CROSS JOIN
(
SELECT COUNT(*) REC_CNT
FROM
(
SELECT * FROM FREQ_ITEM_2
) Z
) D
INNER JOIN
(
SELECT A.ITEM_1, COUNT(DISTINCT TID) FIRST_INSTANCE_COUNT
FROM FREQ_ITEM_2 A , APRIORI_VERTICAL B
WHERE A.ITEM_1 = B.ITEM
GROUP BY A.ITEM_1
) E ON Z.ITEM_1 = E.ITEM_1F2 table
CREATE TABLE F2 AS
SELECT ITEM_1, ITEM_2, SUPPORT, CONFIDENCE, CNT FROM (
SELECT ITEM_1, ITEM_2, TRUNC(CNT / ALL_CNT,2) SUPPORT, TRUNC(CNT / FIRST_INSTANCE_COUNT,2) CONFIDENCE, CNT FROM C2
)
WHERE SUPPORT >= 0.4 --PRUNING
OR CONFIDENCE >= 0.6 --PRUNINGAfter creating the F2 table, we are left with the following records, which means the most frequent couples:
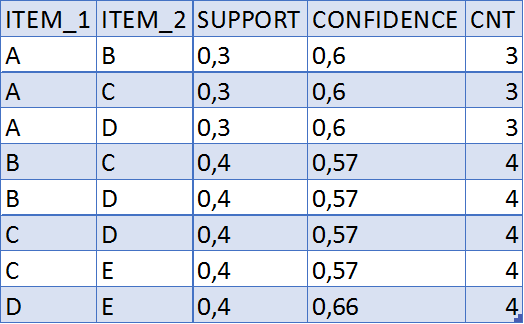
The most frequent items for the third step:
CREATE TABLE FREQ_ITEM_3 AS
SELECT A.ITEM_1 ITEM_1, A.ITEM_2 ITEM_2, B.ITEM_2 ITEM_3
FROM
F2 A, F2 B
WHERE A.ITEM_1 = B.ITEM_1
AND A.ITEM_2 < B.ITEM_2
order by A.ITEM_1, A.ITEM_2, B.ITEM_2The 3rd C3 table:
create table C3 AS
SELECT Z.ITEM_1 ITEM_1, Z.ITEM_2 ITEM_2, Z.ITEM_3 ITEM_3, CNT, REC_CNT ALL_CNT, FIRST_INSTANCE_COUNT
FROM
(
SELECT C.Item_1, C.ITEM_2, C.ITEM_3, COUNT(DISTINCT C.TID) CNT
FROM
(
SELECT * FROM FREQ_ITEM_3
) X
INNER JOIN
(
SELECT A1.TID, a1.item ITEM_1, a2.item ITEM_2, A3.ITEM ITEM_3
FROM APRIORI_VERTICAL A1
CROSS JOIN APRIORI_VERTICAL A2
CROSS JOIN APRIORI_VERTICAL A3
where A1.TID = A2.TID
AND A1.TID = A3.TID
AND A1.ITEM < A2.ITEM
AND A1.ITEM < A3.ITEM
AND A2.ITEM < A3.ITEM
) C
ON X.ITEM_1 = C.ITEM_1 AND X.ITEM_2 = C.ITEM_2 AND X.ITEM_3 = C.ITEM_3
GROUP BY C.ITEM_1, C.ITEM_2, C.ITEM_3
) Z
CROSS JOIN
(
select COUNT(*) REC_CNT
FROM
(
SELECT * FROM FREQ_ITEM_3
) Z
) D
INNER JOIN
(
SELECT A.ITEM_1, A.ITEM_2, COUNT(DISTINCT B.TID) FIRST_INSTANCE_COUNT
FROM FREQ_ITEM_3 A , APRIORI_VERTICAL B, APRIORI_VERTICAL C
WHERE A.ITEM_1 = B.ITEM
AND A.ITEM_2 = C.ITEM
AND B.TID = C.TID
GROUP BY A.ITEM_1, A.ITEM_2
) E ON Z.ITEM_1 = E.ITEM_1 AND Z.ITEM_2 = E.ITEM_2
The 3rd pruning step for frequent itemsets, the F1 table:
create table F3 AS
SELECT ITEM_1, ITEM_2, ITEM_3, SUPPORT, CONFIDENCE, CNT FROM (
SELECT ITEM_1, ITEM_2, ITEM_3, TRUNC(CNT / ALL_CNT,2) SUPPORT, TRUNC(CNT / FIRST_INSTANCE_COUNT,2) CONFIDENCE, CNT FROM C3
)
WHERE SUPPORT >= 0.4 --PRUNING
OR CONFIDENCE >= 0.6 --PRUNINGIn the 4th step, there is no data in the frequent itemset table:
CREATE TABLE FREQ_ITEM_4 AS
SELECT A.ITEM_1 I1, A.ITEM_2 I2, a.ITEM_3, b.item_3 ITEM_4
FROM
F3 A
, F3 B
WHERE A.ITEM_1 = B.ITEM_1
AND A.ITEM_2 = B.ITEM_2
AND A.ITEM_3 < B.ITEM_3
order by A.ITEM_1, A.ITEM_2, a.ITEM_3, b.item_3So we can conclude that the most frequent itemsets are:

Let me know your thoughts in the comments below.
Opinions expressed by DZone contributors are their own.
Comments