Architecting Intelligence: A Complete LLM-Powered Pipeline for Unstructured Document Analytics
How OCR, LLMs, and vector search work together to deliver reliable insights for analytics, compliance, and decision-making.
Join the DZone community and get the full member experience.
Join For Free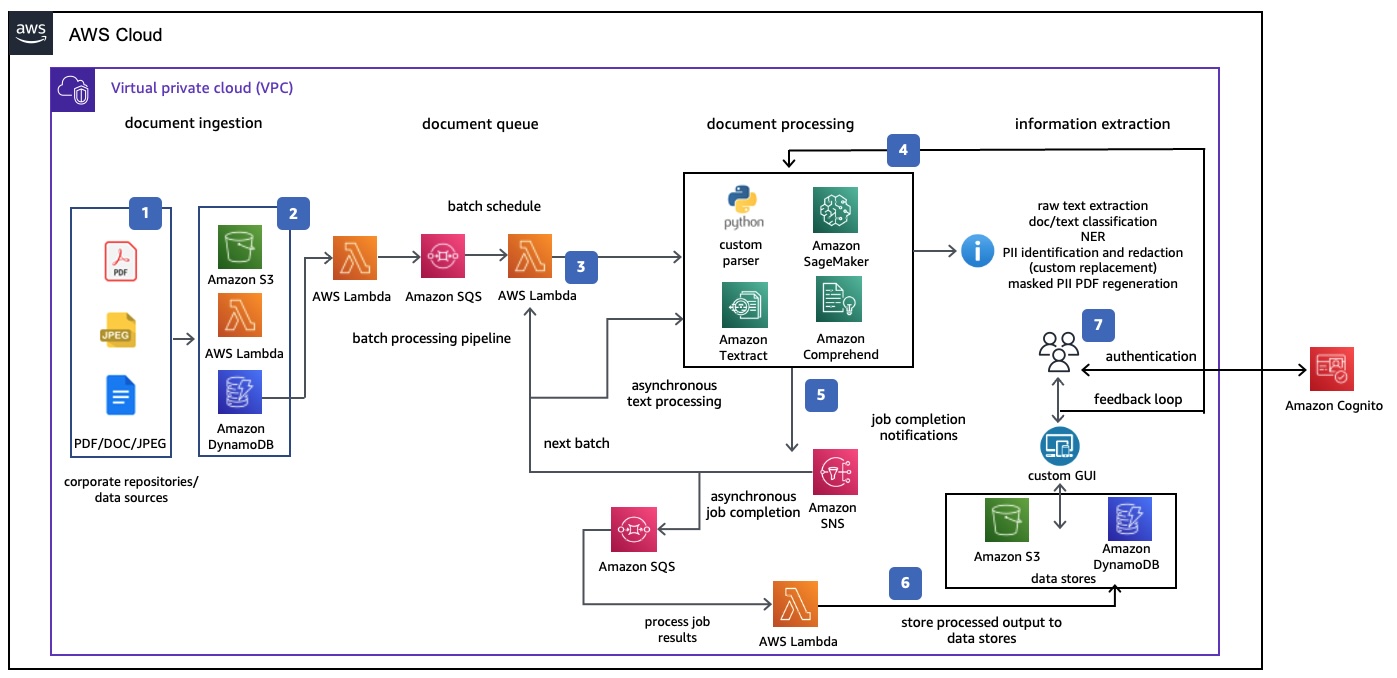
Unstructured documents remain one of the most difficult sources of truth for enterprises to operationalize. Whether it's compliance teams flooded with scanned contracts, engineering departments dealing with decades of legacy PDFs, or operations teams handling invoices and reports from heterogeneous systems, organizations continue to struggle with making these documents searchable, analyzable, and reliable. Traditional OCR workflows and keyword search engines were never built to interpret context, identify risk, or extract meaning. The emergence of LLMs, multimodal OCR engines, and vector databases has finally created a practical path toward intelligent end-to-end document understanding, moving beyond raw extraction into actual reasoning and insight generation.
In this article, I outline a modern, production-ready unstructured document analytics process, built from real-world deployment across compliance, tax, operations, and engineering functions.
The Challenge of Heterogeneous Document Ecosystems
Unstructured documents introduce complexity long before the first line of text is extracted. A single enterprise repository can contain digital PDFs, scanned images, email attachments, handwritten notes, multi-column layouts, or low-resolution files produced by outdated hardware. Each format demands a different extraction strategy, and treating them uniformly invites failure. OCR engines misinterpret characters, tables become distorted, numerical formats drift, and crucial metadata is lost in translation.
Beyond extraction, enterprises face a second and often more damaging barrier. Traditional retrieval methods rely heavily on keywords, which do little to help when two documents describe the same idea using entirely different vocabulary. Teams searching for "operational risks," for example, may miss documents that frame these issues as "site-level hazards," "process deviations," or "non-conformities." It's not simply a search problem; it's a semantic understanding problem.
This is precisely where LLMs, vector embeddings, and retrieval-augmented generation (RAG) reshape the stack. But they only function reliably when anchored to a disciplined ingestion and enrichment pipeline.
A Structured Approach to an Unstructured Problem
A robust analytics pipeline begins with ingestion — a deceptively simple step that determines the success of the entire workflow. Emails, enterprise applications, and DMS systems typically provide the entry points. Once a document arrives, the system must immediately determine whether it is digital or scanned. This distinction is not cosmetic; it dictates the extraction route and directly influences downstream quality.
Digital PDFs can move through parsing libraries such as PyMuPDF4LLM, which preserve structure and metadata with high accuracy. Scanned PDFs, however, must be routed through OCR systems like Azure Document Intelligence or AWS Textract to reconstruct text, layout, and tables. Even here, table extraction is handled as a separate sub-stream using tools such as Camelot, ensuring that structured data is not flattened or corrupted.
This bifurcated approach generates two outputs: an unstructured text stream and a structured table stream. Keeping them separate at this stage helps retain fidelity, particularly for regulatory or financial documents where a single misread number may have downstream implications.
Where LLMs Enter the Workflow
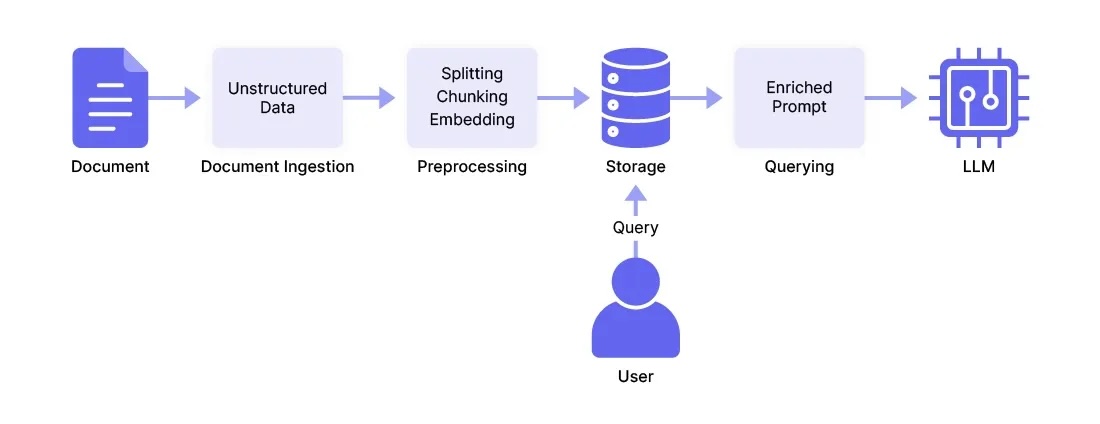
Once the raw streams are extracted, the pipeline transitions into the enrichment phase. This layer is where LLMs contribute meaningfully — not by rewriting content, but by organizing and indexing it at scale. Documents are segmented into manageable semantic chunks and embedded using high-dimensional vector models. These embeddings are stored in a vector database, where they serve as the backbone for context-aware search, analysis, and retrieval.
With the document now decomposed, LLMs can perform a range of analytical tasks: identifying sentiment, extracting risks, isolating key entities, producing summaries, or classifying thematic content. These enrichments become metadata records that later populate a structured database for analytics and reporting. It's a shift from merely storing text to storing understanding.
A crucial component of this layer is the validation loop. Every enrichment and extraction step generates a confidence score or anomaly indicator. When mismatches or low-confidence sections are detected, the system feeds this data back into refinement steps — improving prompts, adjusting extraction configurations, or revisiting chunking heuristics. This feedback loop is essential in maintaining accuracy at scale and prevents common pitfalls such as hallucinations or extraction drift.
Semantic Search and the Role of RAG
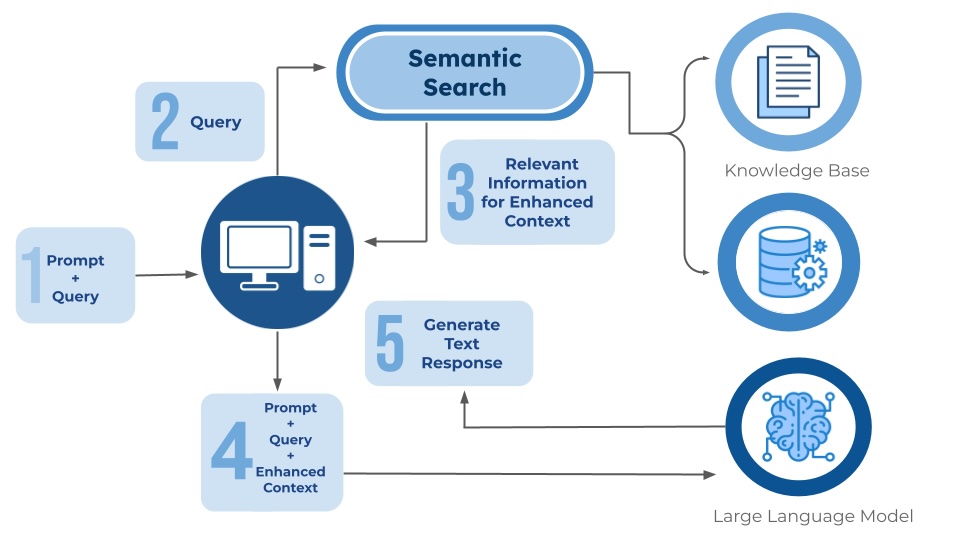
Once embeddings and metadata are in place, semantic search transforms how teams interact with their documents. Instead of depending on extract phrasing, the system understands the conceptual intent behind a search query. When user queries, "documents referencing supplier delays," the vector database surfaces passages that express the underlying idea, even when the original text uses entirely different terminology.
Retrieval-augmented generation completes the loop by grounding LLM responses in retrieved, source-authenticated content. By forcing the model to answer questions strictly using retrieved evidence, RAG dramatically reduces hallucinations and aligns outputs with verifiable document segments. This grounding is critical for domains such as legal, healthcare, engineering, and finance, where errors carry real operational risks.
Going From Insight to Intelligence: Storing the Final Output
After enrichment, the text stream, the table stream, and metadata records are consolidated into a structured database. From here, the data is usable not only for manual exploration but also for automated dashboards, trend analysis, audit support, and compliance reporting. Over time, the organization builds a searchable, semantically indexed intelligence layer over its entire document ecosystem, turning each new document into an incremental contributor to institutional knowledge.
This architecture does more than modernise extraction; it enables organisations to identify emerging risks, detect patterns, analyse sentiment shifts, and search across concepts rather than strings. It elevates documents from passive archives to active contributors in decision processes.
In the End...
Intelligent document analytics requires more than a single LLM or OCR engine. It demands a deliberately orchestrated pipeline — one that respects the complexity of unstructured data while leveraging modern AI to interpret it meaningfully. By combining classification, structured extraction, LLM-driven enrichment, embeddings, semantic search, and continuous validation, the architecture outlined here enables enterprises to unlock real value from their document repositories.
As AI adoption accelerates, such systems will become the backbone of enterprise automation and knowledge management.
Opinions expressed by DZone contributors are their own.
Comments