Architecting the Future of Research: A Technical Deep-Dive into NotebookLM and Gemini Integration
Explore how NotebookLM and Gemini 1.5 Pro revolutionize research through source grounding, long context windows, and content pipelines.
Join the DZone community and get the full member experience.
Join For FreeIn the rapidly evolving landscape of large language models (LLMs), the challenge has shifted from generating text to managing context. As developers and researchers, we are often overwhelmed not by a lack of information, but by the inability to synthesize vast amounts of heterogeneous data efficiently. Enter NotebookLM, a specialized research environment, and the underlying Gemini 1.5 Pro architecture. Together, they represent a paradigm shift in Retrieval-Augmented Generation (RAG) and personal knowledge management.
This article explores the technical foundations of NotebookLM, the mechanics of its integration with Gemini 1.5 Pro, and how to build production-grade content pipelines using these tools.
1. The Paradigm Shift: From Vector Search to Source Grounding
Traditional RAG systems rely on a 'chunk-and-retrieve' workflow. Documents are broken into small segments, converted into embeddings, and stored in a vector database. When a user asks a question, the system retrieves the top-K most similar chunks and feeds them into the LLM context window.
However, this approach has inherent limitations:
- Loss of Global Context: Chunking often breaks semantic connections across a document.
- Retrieval Noise: Irrelevant chunks can distract the model.
- Scaling Issues: Maintaining a vector database adds architectural complexity.
NotebookLM, powered by Gemini 1.5 Pro, utilizes a concept called Source Grounding. Because Gemini 1.5 Pro features a massive context window (up to 2 million tokens), NotebookLM does not necessarily need to perform aggressive chunking for smaller to mid-sized datasets. Instead, it can ingest entire documents, maintaining the structural and semantic integrity of the information.
The Architecture of Knowledge Processing
The following flowchart illustrates how NotebookLM processes information compared to traditional AI assistants.
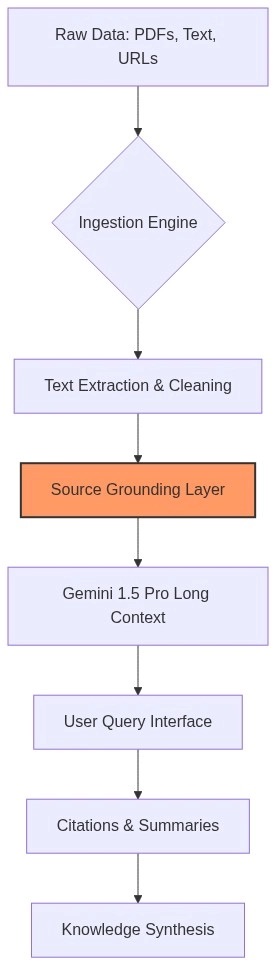
In this workflow, the Source Grounding Layer is critical. It ensures that every response generated by the model is anchored specifically to the uploaded sources, drastically reducing hallucinations (O(1) probability of hallucination relative to the source set in optimal conditions).
2. Technical Core: Gemini 1.5 Pro and Long-Context Windows
The engine driving NotebookLM is Gemini 1.5 Pro. Unlike previous iterations, this model uses a Mixture-of-Experts (MoE) architecture. When a query is made, the model only activates a subset of its neural pathways, making it more efficient despite its massive scale.
The Context Window Advantage
If you have a research project involving 50 academic papers (approximately 500,000 words), a traditional LLM with a 32k token window would require complex RAG orchestration. Gemini 1.5 Pro can ingest the entire set at once. This allows for:
- Cross-document analysis: "Compare the methodology in Paper A with the results in Paper D."
- Thematic mapping: "Identify the recurring technical bottlenecks mentioned across all 50 sources."
- Complex reasoning: Running high-order logic across the entire dataset without losing the 'thread' of the argument.
Performance Comparison Table
| Feature | Traditional RAG | NotebookLM + Gemini 1.5 Pro |
|---|---|---|
| Context Handling | Chunking and Vector Retrieval | Native Long-Context Ingestion |
| Hallucination Risk | High (Retrieval of wrong chunks) | Low (Direct source grounding) |
| Setup Complexity | High (Vector DB, Embeddings) | Low (Direct file upload) |
| Cross-Source Synthesis | Limited by chunk size | Comprehensive (Full-source visibility) |
| Data Latency | Fast for small queries | Variable (Large context takes longer to process) |
3. Building a Research Pipeline with Gemini API and NotebookLM
While NotebookLM provides a superior UI for research, a technical content pipeline often starts with raw data that requires pre-processing. We can use the Gemini API to clean, format, and prepare data before feeding it into NotebookLM.
Practical Code Example: Data Pre-processing for NotebookLM
Suppose you have several messy OCR-processed PDFs or raw technical transcripts. Before uploading them to NotebookLM, you can use the Gemini API to structure them into clean Markdown. This ensures that NotebookLM’s grounding mechanism works with the highest possible signal-to-noise ratio.
import google.generativeai as genai
import os
# Configure your API Key
genai.configure(api_key="YOUR_GEMINI_API_KEY")
# Initialize Gemini 1.5 Pro
model = genai.GenerativeModel('gemini-1.5-pro')
def clean_technical_document(raw_text):
"""
Uses Gemini to clean and structure raw text for NotebookLM ingestion.
"""
prompt = f"""
Analyze the following raw technical text.
1. Remove any OCR errors or noise.
2. Structure it into clean Markdown with clear headings.
3. Extract a metadata summary at the top (Author, Date, Core Tech).
4. Ensure all code blocks are properly formatted.
Raw Text:
{raw_text}
"""
response = model.generate_content(prompt)
return response.text
# Example Usage
with open("raw_research_notes.txt", "r") as f:
messy_data = f.read()
structured_data = clean_technical_document(messy_data)
# Save for NotebookLM upload
with open("cleaned_research_for_notebook.md", "w") as f:
f.write(structured_data)
print("Document cleaned and ready for NotebookLM.")
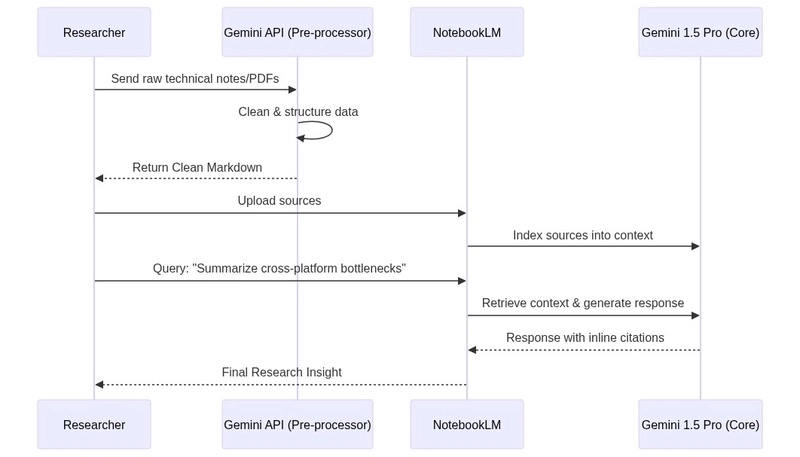
How the Integration Works (Sequence Diagram)
The interaction between the user, the pre-processing script, NotebookLM, and the Gemini model creates a robust knowledge loop.
4. Advanced Use Cases for Content Pipelines
Integrating these tools allows for the creation of "Content Engines" where the distance between research and publication is minimized.
Use Case A: Technical Documentation Audits
If you are a lead engineer managing a legacy codebase, you can upload your entire repository's documentation (READMEs, Swagger specs, Architecture ADRs) into NotebookLM.
Workflow:
- Upload all documentation.
- Use the "Audio Overview" feature to generate a high-level summary of the architecture for new hires.
- Query the notebook to find contradictions: "Where does the API documentation disagree with the internal security policy?"
Use Case B: Thematic Content Creation
For technical writers, NotebookLM acts as a co-author. By uploading transcriptions of interviews with subject matter experts (SMEs), raw code samples, and whitepapers, you can generate a technical article roadmap.
Pipeline Logic:
- Step 1 (Ingest): Upload SME interview transcripts.
- Step 2 (Synthesize): Ask "What are the three most controversial technical opinions expressed in these interviews?"
- Step 3 (Draft): Use the synthesized points to create a detailed outline, ensuring every point cites a specific timestamp or document page.
5. Managing Data and Entity Relationships
One of the strengths of NotebookLM is how it manages the relationship between different entities across sources. For a complex project, the data model within your "Notebook" might look like this:

This ERD logic allows the model to maintain a high degree of precision. Unlike a generic chatbot that "remembers" things vaguely, NotebookLM maintains a strict relationship between a response and its origin (the citation).
6. Technical Limitations and Best Practices
While powerful, the Gemini/NotebookLM integration requires a strategic approach to yield the best results.
Addressing Latency
Processing 1 million tokens is not instantaneous. When you query a massive notebook, there is a distinct "computation lag" as Gemini performs its attention mechanism across the full context.
Optimization Tips:
- Prune irrelevant data: Even with a large window, noise slows down processing. Use the pre-processing script shown earlier to remove boilerplate text.
- Specific Prompting: Instead of "Tell me about this project," use "Summarize the database migration strategy for PostgreSQL specifically."
- Logical Grouping: Create separate Notebooks for distinct architectural components (e.g., one for Frontend, one for DevOps) rather than one giant "dump" notebook.
Privacy and Data Security
Enterprise users should be aware that while Google provides robust data protection, the terms of service vary between the consumer NotebookLM and the enterprise Gemini API. Always ensure that sensitive keys or PII (Personally Identifiable Information) are redacted during the pre-processing stage using a simple regex or a dedicated PII-detection model.
import re
def redact_pii(text):
"""
Simple regex to redact potential API keys or emails before AI processing.
"""
# Redact common API key patterns
text = re.sub(r'sk-[a-zA-Z0-9]{32,}', '[REDACTED_API_KEY]', text)
# Redact emails
text = re.sub(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', '[REDACTED_EMAIL]', text)
return text7. The Future: Multi-Modal Knowledge Bases
With the recent updates to Gemini 1.5 Pro, multi-modality is the next frontier for NotebookLM. We are moving toward a reality where you can upload video recordings of technical meetings, UI/UX screen recordings, and architectural diagrams (as images) directly into your research notebook.
Imagine asking: "Show me the timestamp in the meeting where the CTO expressed concerns about the latency of the microservices, and cross-reference that with the latency charts in the PDF report."
This level of cross-modal synthesis is only possible because of the integration between the specialized grounding of NotebookLM and the generalized intelligence of Gemini.
Conclusion
NotebookLM, underpinned by the Gemini 1.5 Pro architecture, represents more than just a better summarization tool. It is a fundamental shift in how we interact with information. By moving away from the constraints of traditional vector-based RAG and embracing long-context source grounding, we can build research and content pipelines that are more accurate, more comprehensive, and significantly more efficient.
For developers, the opportunity lies in the middle layer: using the Gemini API to orchestrate, clean, and pipe data into these specialized research environments. As the context window continues to grow, our ability to manage the global state of our knowledge will become the primary differentiator in technical productivity.
Further Reading & Resources
Published at DZone with permission of Jubin Abhishek Soni. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments