From Simple Lookups to Agentic Reasoning: The Rise of Smart RAG Systems
RAG has grown from basic retrieval to agent-like AI, gaining memory, smarter routing, HyDe, adaptive search, and fact checks to deliver better, grounded answers.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-Augmented Generation (RAG) is a technique in large language models (LLMs) that enhances text generation by incorporating external data retrieval into the process. Unlike traditional LLM usage that relies solely on the model’s pre-trained knowledge, RAG allows an AI to “look things up” in outside sources during generation. This significantly improves the factual accuracy and relevance of responses by grounding them in real-time information, helping mitigate issues like hallucinations (fabricated or inaccurate facts) and outdated knowledge. In essence, RAG gives AI a dynamic memory beyond its static training data.
However, the story of RAG doesn’t end with the basic idea of retrieval + generation. Over time, a series of RAG architectures have emerged – each one introduced to solve specific shortcomings of the earlier approaches. What began as a simple concept has grown into a sophisticated ecosystem of patterns, each designed to tackle real-world challenges such as maintaining conversational context, handling multiple data sources, and improving retrieval relevance. In this article, we’ll explore the major RAG architectures in an evolutionary sequence. We’ll see how each new architecture builds upon and resolves the limitations of its predecessor, using visual diagrams to illustrate the problem each one tackles and the solution it provides.
Simple RAG
The LLM first retrieves relevant documents from a static knowledge source (e.g., a database or vector index), then generates a response grounded in that retrieved information.
Simple RAG is the most basic form of retrieval-augmented generation. In this setup, when a user asks a question, the system retrieves pertinent information from a fixed knowledge base and feeds it to the LLM to generate a fact-informed answer. This straightforward pipeline typically involves a document store (the external data, such as a database or enterprise knowledge base) and a retriever that finds relevant text for the query. By consulting an external knowledge source at generation time, Simple RAG ensures the answer is up-to-date and grounded in real data, which greatly reduces hallucinations and improves accuracy.
- Workflow: The user provides a query, the system retrieves relevant documents from the database, and the LLM generates a response based on those documents.
- Use Case: This basic approach works well for domains with a bounded, static information set. For example, an FAQ chatbot or documentation assistant can use Simple RAG to answer questions by looking up answers in a product manual or knowledge base, ensuring responses stay factual within that content.
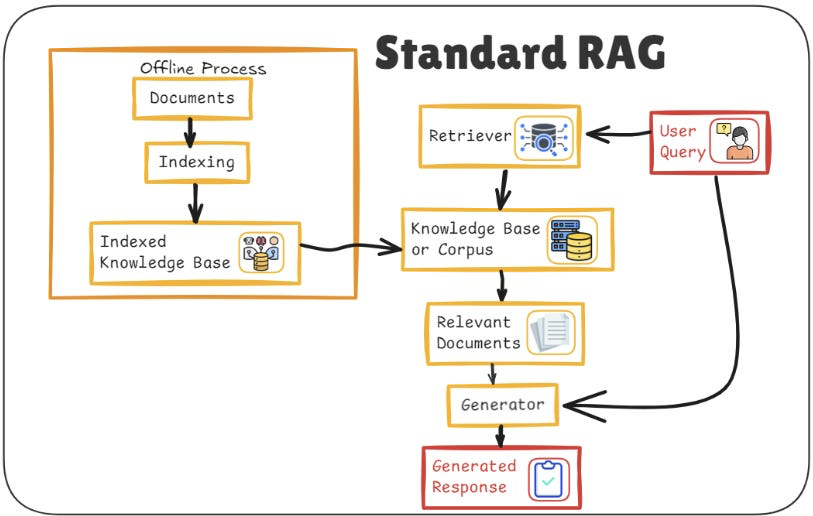
Limitation: While Simple RAG is a great improvement over using an LLM alone, it has a notable weakness – it treats each query in isolation. There is no memory of previous interactions or context. In a multi-turn conversation or any scenario requiring the AI to remember what was said earlier, Simple RAG falls short. It cannot carry information from one question to the next, often resulting in repetitive or inconsistent answers in a dialogue setting. This lack of context management is the main challenge that the next evolution of RAG aims to solve.
Simple RAG With Memory
This architecture extends Simple RAG by adding a memory component. The system can incorporate stored context from prior user interactions along with new retrieved documents when generating a response.
Simple RAG with Memory addresses the context limitation of the basic RAG. It introduces a persistent memory storage for the AI model to retain information from previous interactions. In practical terms, the model can now remember what the user asked or what answers were given earlier, and use that alongside newly retrieved data for the current query. By doing so, it maintains continuity in conversation and avoids forgetting earlier details.
- Workflow: The user submits a query. The system first accesses memory, retrieving any relevant information from prior turns or stored context. Next, it performs the usual document retrieval from the external knowledge source for new information. Finally, the LLM generates an answer that integrates both the past context (from memory) and the newly retrieved facts.
- Use Case: This architecture is especially useful for chatbots and conversational agents in customer service or personal assistants. For instance, a support bot that can recall a user’s name or issue from earlier in the chat will deliver a far better experience. It’s also valuable for personalized recommendations or any scenario where historical context needs to inform the current response.
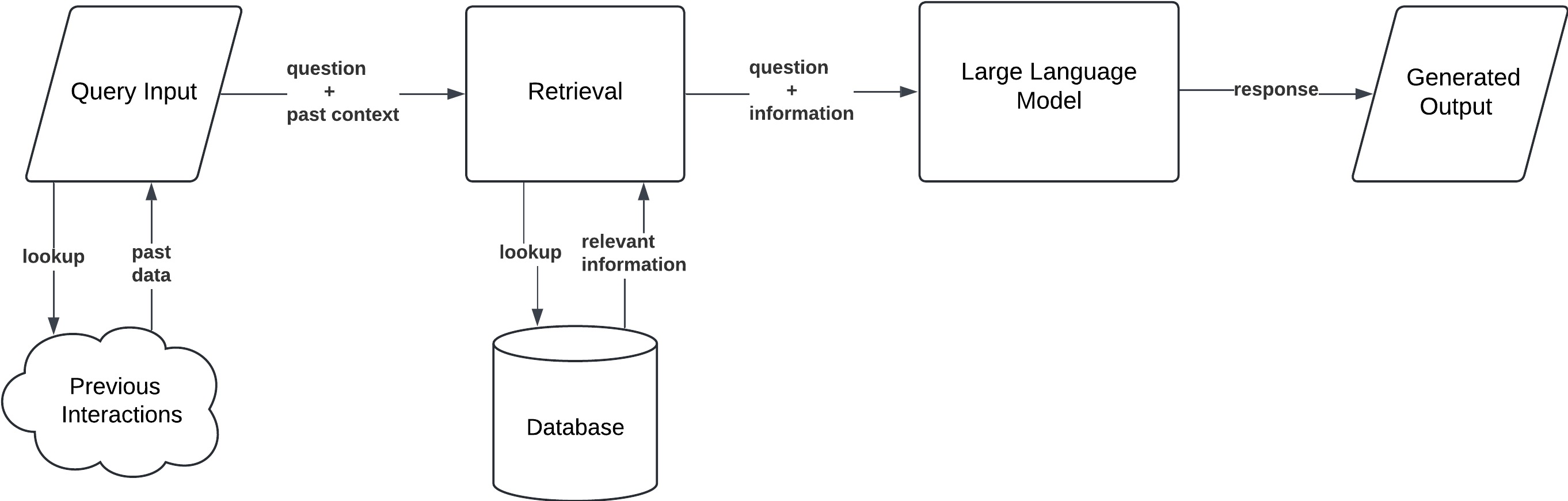
By adding memory, RAG with Memory solves the immediate challenge of context continuity. The AI no longer starts from scratch every query – it can build on a conversation. What’s next? As applications grow, another challenge emerges: not all queries should hit the same data source. Simple and Memory RAG typically query a fixed set of documents. But what if an organization has multiple knowledge bases or tools? Querying all of them every time is inefficient. The next architecture tackles this by making the retrieval smarter about where to look.
Branched RAG
An architecture that can route queries to different knowledge sources. Instead of searching everything, the system branches to the most relevant source (database, API, document set, etc.) based on the query.
Branched RAG introduces intelligent source selection. In previous architectures, the system typically searched one fixed index or had to search all possible data sources for every query. Branched RAG solves the inefficiency of that approach by evaluating the query and directing the retrieval to the most appropriate resource. In other words, the RAG pipeline can branch into different information sources depending on what the question is about.
- Workflow: The user’s query is analyzed, and the system decides which knowledge source(s) are most likely to contain the answer (this is often called a router or branch selector step). For example, a legal question might be routed to a law database, whereas a coding question goes to a Stack Overflow archive. Only the selected source is then queried for retrieval, and the LLM generates the answer from that targeted information.
- Use Case: Branched RAG shines when dealing with multiple domains or large heterogeneous corpora. For instance, an AI assistant for a big company might need to handle HR policy questions, IT support issues, and finance data lookups. With branched retrieval, the assistant can choose the correct internal database for each query rather than searching a merged, bloated index or, worse, missing answers because it looked in the wrong place. This results in more efficient and relevant responses since irrelevant sources are skipped.
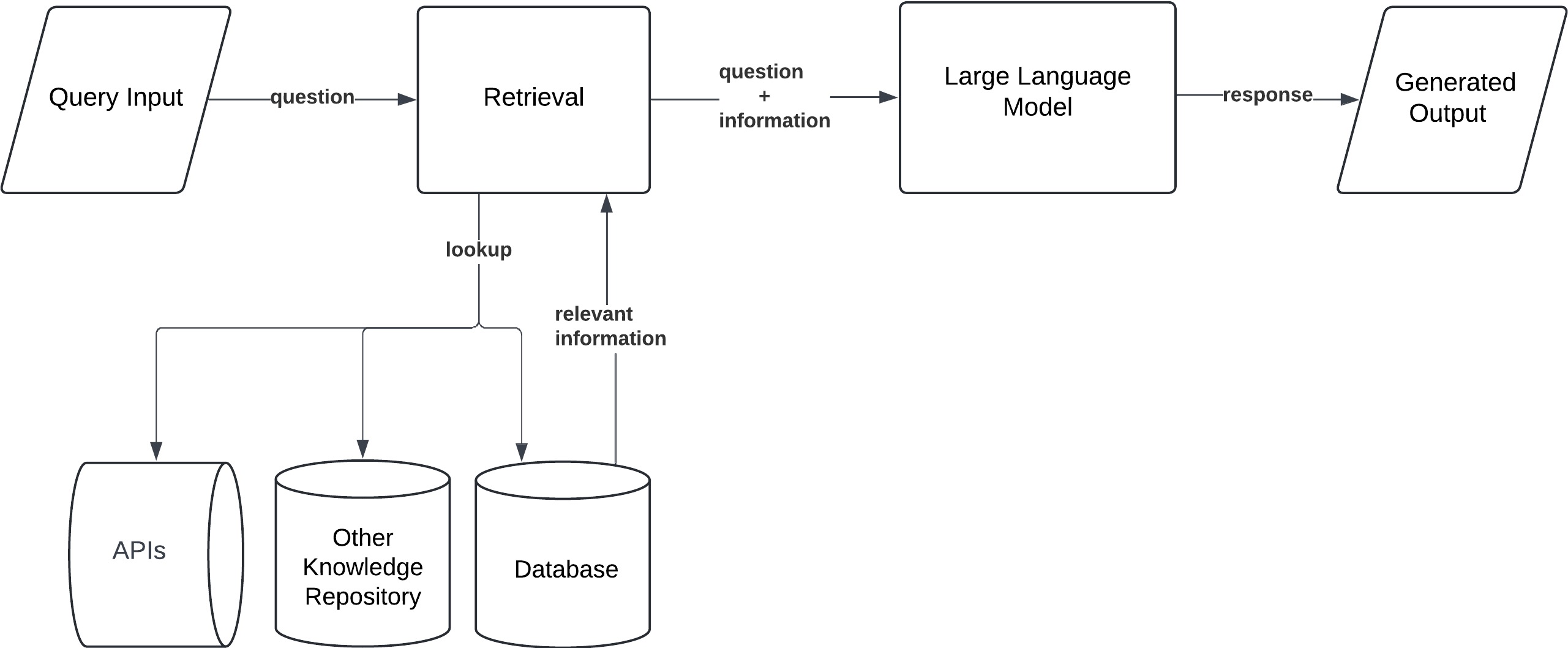
By routing queries to the right source, Branched RAG reduces noise and improves precision. It solves the challenge of scaling RAG across multiple knowledge bases. Yet, it assumes the user’s query is well-formed enough to determine the right branch. What if the query is unclear or doesn’t directly match any document? In such cases, even a smart branch might retrieve nothing useful. The next innovation addresses this by having the model actively imagine a better query representation to guide retrieval when the user’s question isn’t specific enough.
HyDe (Hypothetical Document Embedding)
Before searching the knowledge base, the model creates a hypothetical document or ideal answer embedding based on the query, and uses that as a guide to retrieve real documents that match the “ideal” content.
HyDe, short for Hypothetical Document Embedding, is a unique variant of RAG that tackles the problem of vague or hard-to-match queries. In previous architectures, retrieval is driven directly by the user’s query. But if that query is poorly worded or very broad, the system might not fetch the best information. HyDe’s solution is for the model to first generate a hypothetical answer or document internally (essentially, what the model thinks an ideal answer would contain), convert that to an embedding, and then retrieve actual documents similar to that hypothetical content. This can dramatically improve the relevance of retrieved info for difficult queries.
- Workflow: The user provides a prompt. The system uses the LLM (or another generative component) to create a hypothetical document/answer representation as if it were responding without retrieval. This hypothetical answer isn’t shown to the user; instead, it’s turned into an embedding vector. That vector is then used to retrieve real documents from the knowledge base that are closest to this ideal answer. Finally, the LLM generates the final answer using those retrieved documents (optionally influenced by the hypothetical it created).
- Use Case: HyDe is particularly useful for research and creative queries. For example, if a user asks a very open-ended question like “What are the impacts of technology on cognitive development?”, a straightforward keyword search might miss relevant papers that don’t match the query wording. HyDe would first have the model hypothesize an answer (perhaps mentioning concepts like attention span, memory, studies on screen time, etc.), then use that to fetch documents covering those concepts. It’s also handy for cases where the question is ambiguous – the hypothetical answer helps clarify what information is needed. In creative content generation, HyDe can help by exploring an “ideal” narrative and then grounding it with factual details from retrieval.
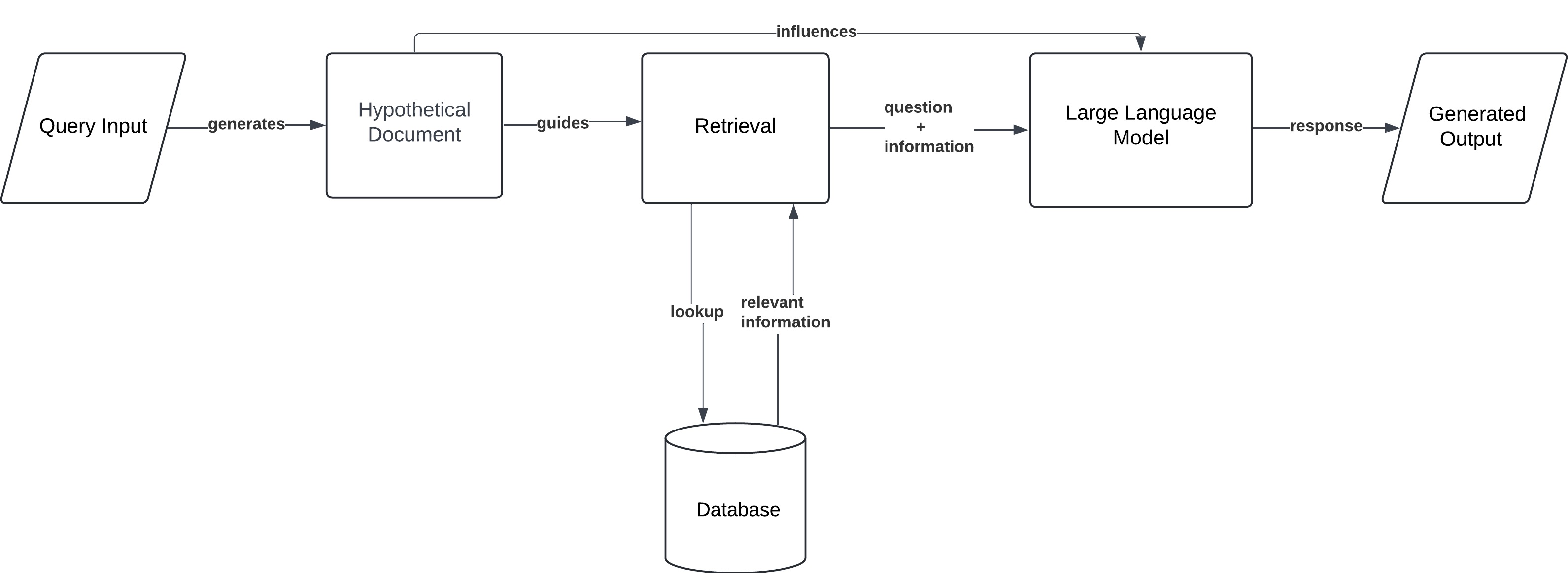
HyDe effectively addresses the challenge of retrieval when user queries are not precise. By guiding search with a model-generated preview of the answer, it increases the odds of finding the right information. This adds complexity, but yields better results for complex questions. Up to this point, the architectures we’ve seen still follow a mostly fixed strategy per query (with variations in memory or branching). Next, we look at an approach that can adapt its retrieval strategy on the fly depending on the query’s needs, making the process more efficient and scalable for diverse workloads.
Adaptive RAG
A conditional retrieval strategy. The system examines the query and decides how to retrieve information: a simple query might query one source with minimal effort, while a complex query triggers a more extensive retrieval (multiple sources or iterative searching). This adaptability optimizes speed vs. depth.
Adaptive RAG is a dynamic approach that does not treat all queries equally. The idea here is to adjust the retrieval strategy based on the complexity or nature of the question. Simpler queries get a lightweight retrieval (for speed), whereas harder queries get a heavier, multi-faceted retrieval (for thoroughness). This architecture solves a challenge in earlier systems: using a one-size-fits-all retrieval process. In a naive RAG, whether the question is “What’s the capital of France?” or a detailed analytical query, the system might always retrieve the same number of documents from the same places. Adaptive RAG introduces logic to make this more efficient and flexible.
- Workflow: The user submits a query. An initial analysis of the query’s complexity is performed (this could be a simple heuristic like question length or a trained classifier). Based on this, the system branches into different retrieval modes. For an easy factoid question, it might query just a single trusted source or retrieve only a couple of snippets. For a complex question, it could fan out to multiple databases/APIs or use an iterative search strategy. After retrieval, the LLM generates the answer as usual, but the key is that the amount and sources of retrieved information are tailored to the query.
- Use Case: Adaptive RAG is valuable in enterprise search or any AI assistant that handles mixed types of queries with varying difficulty levels. For instance, consider an AI research assistant: some queries are straightforward definitions, while others require digging through scientific literature. Adaptive RAG might do a quick lookup in a glossary for the former, but perform a broad search across multiple research paper databases for the latter. This ensures that simple queries get lightning-fast responses, and only complex queries incur the cost of heavy retrieval. It provides a better balance of speed vs. depth on a case-by-case basis.

By adapting to query complexity, this architecture prevents overkill retrieval when it’s not needed, and ensures thoroughness when it is. It addresses the efficiency and scalability issues that can arise if every query, no matter how trivial or complex, is treated with the same heavy pipeline. Yet, even with adaptive strategies, all the architectures so far share a common trait: they trust the retrieved documents as-is and generate an answer. What if the retrieved info is misleading or insufficient? The next architecture explicitly tackles the scenario where the initial retrieval might fail to provide good support by introducing an extra step to critically evaluate and correct the retrieved knowledge before answering.
Corrective RAG (CRAG)
This architecture adds a self-check and refinement loop. Retrieved documents are broken into “knowledge strips” and graded for relevance. If they aren’t good enough (fail a relevance threshold), the system performs additional retrieval (e.g., a web search or alternate query) before final answer generation.
Corrective RAG (CRAG) augments the standard RAG pipeline with a self-reflection mechanism on the retrieved content. The motivation is to catch cases where the initial retrieval may have missed the mark – perhaps the documents retrieved are off-topic, outdated, or incomplete – and to fix that before generating the final answer. In earlier architectures, if the retrieval fetched poor information, the LLM might either produce a wrong answer or hallucinate to fill gaps. CRAG’s approach is to grade the retrieved info for quality and iterate if necessary.
- Workflow: After the usual retrieval step, the CRAG system breaks down the retrieved text into smaller piecesoften called “knowledge strips,” and then evaluates each for relevance to the query. This can be done by an LLM itself or some scoring function. If these knowledge pieces don’t meet a certain relevance or quality threshold, the system doesn’t proceed to generation yet. Instead, it will seek additional information – for example, by running a broader web search or querying a different database – to supplement or replace the weak parts. Only once it has a sufficiently relevant set of documents does the LLM generate the answer. Essentially, CRAG inserts a loop of retrieve → evaluate → refine before the final answer.
- Use Case: Corrective RAG is ideal for high-stakes or accuracy-critical applications. Think of domains like legal analysis, medical Q&A, or financial reporting, where providing an incorrect or unsupported answer could have serious consequences. In such cases, it’s worth the extra steps to double-check the evidence. For example, a medical chatbot using CRAG might retrieve information from a medical database, but if those documents don’t directly answer the patient’s question, the system might automatically search recent medical literature or clinical guidelines online to ensure no critical detail is missing. CRAG’s self-grading step helps catch errors or omissions, dramatically improving the quality of the output.
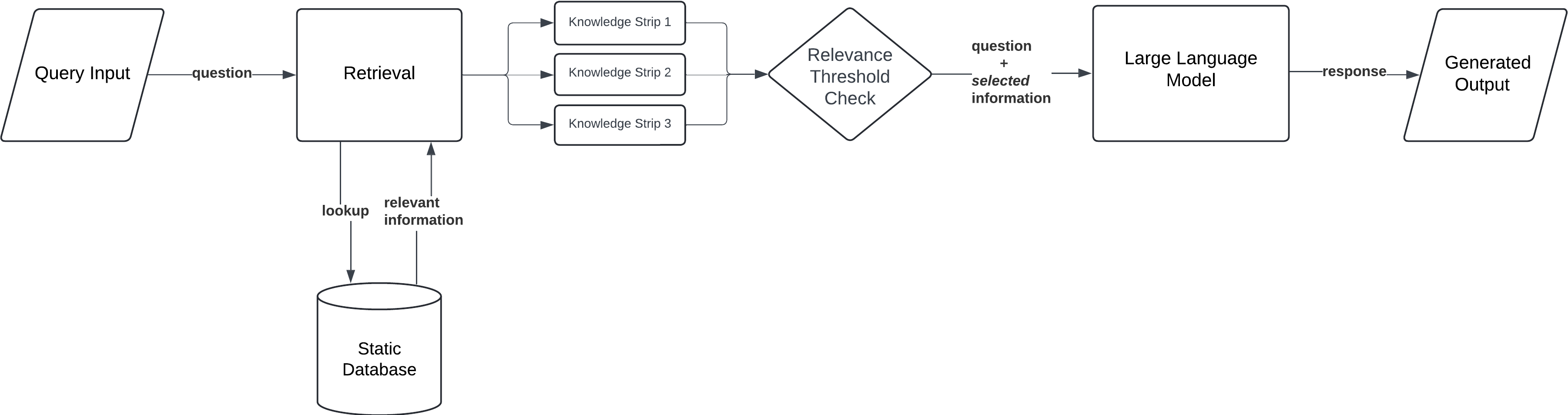
By incorporating a feedback loop on retrieved data, CRAG solves the challenge of garbage-in, garbage-out in RAG systems. It refuses to generate an answer if it’s not confident in the source material’s relevance, thus further reducing hallucinations and increasing reliability. Now, up to CRAG, the retrieval process still happens before the generation step (albeit possibly with multiple passes). The next idea is to blur that line: what if the model could decide to retrieve more information in the middle of generating an answer? That’s where Self-RAG comes in – giving the LLM more agency to pull new data on the fly as it formulates its response.
Self-RAG
The model engages in a self-driven retrieval loop during generation. As it constructs the answer, the LLM can detect knowledge gaps or uncertainties, then formulate and issue new queries to fetch additional information (self-querying) before continuing. This iterative cycle continues until the answer is complete and well-supported.
Self-RAG takes the initiative one step further by allowing the LLM to proactively retrieve additional information while generating the response. In contrast to all previous architectures – where retrieval happened only once per query (before generation, aside from CRAG’s pre-generation loops) – Self-RAG enables a more interactive process. The model starts answering, but if it realizes it needs more data (perhaps a sub-question arises or it isn’t fully confident), it can pause and fetch more content, then resume answering. This addresses a limitation in the standard RAG pipeline: sometimes you don’t know what you don’t know until you start formulating an answer. Self-RAG ensures that the model can cover those blind spots by dynamically pulling in information mid-answer.
- Workflow: The user asks a question. The system might do an initial retrieval as usual and start the generation. During the generation, the LLM monitors its own output for gaps or uncertain points. When it hits a point where it needs clarification or more facts, it formulates a new internal query related to that sub-topic. It then triggers a self-retrieval loop, fetching additional documents or data relevant to that query. The new information is incorporated into the answer, and the generation continues. This can happen multiple times – essentially, the model iteratively improves the answer by retrieving more info as needed, until it’s satisfied that the answer is comprehensive and well-supported.
- Use Case: Self-RAG is powerful for exploratory tasks and complex Q&A. For example, consider a scenario of writing an in-depth report: as the AI drafts a section, it might realize it needs more statistics or an explanation of a specific concept – it can then fetch that on the fly. Another example is a multi-hop question in open-domain QA (e.g., “Find the connection between concept A in document X and concept B in document Y”). A Self-RAG system could retrieve info on concept A, start explaining it, then realize it should also retrieve info on concept B and how they link, before finalizing the answer. This approach ensures comprehensive results, as the model can keep digging until all facets of the query are addressed.
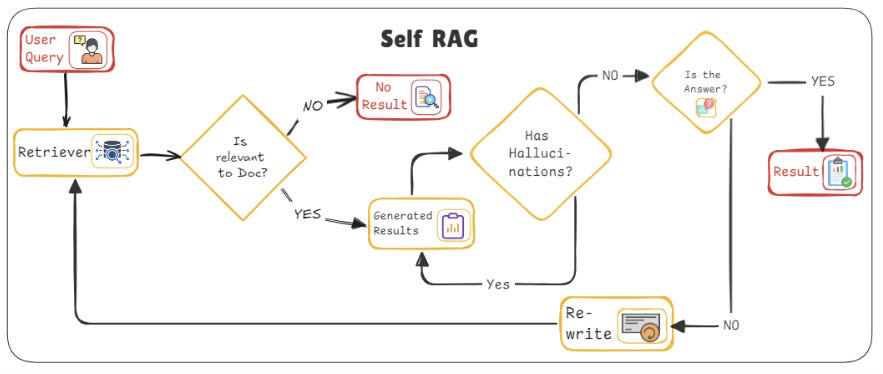
In summary, Self-RAG grants the model a degree of agency to guide its own retrieval, effectively making the retrieval-generation boundary more fluid. It solves the problem of unforeseen information needs during answer construction. This is a step toward more agent-like behavior, which sets the stage for the most advanced architecture in our discussion: Agentic RAG. Agentic RAG generalizes this idea by not just doing self-retrieval, but by orchestrating multiple agents and tools in a goal-directed way to handle extremely complex queries or tasks that go beyond a single Q&A.
Agentic RAG
An advanced multi-agent retrieval architecture. Here, the RAG system behaves like an agent that can perform multi-step reasoning and interact with multiple data sources or tools. A top-level meta-agent might spawn specialized document agents for each source or chunk of data, gather their findings, and then synthesize a final answer.
Agentic RAG represents the frontier of RAG architectures, where the model acts in a more autonomous, goal-driven manner rather than a single-pass Q&A system. In Agentic RAG, the AI can break a complex query into sub-tasks, call upon multiple agents (which could be instances of LLMs or specialized retrieval modules) to handle different pieces, and then compose the results. This architecture is inspired by the emerging trend of AI agents that can plan, reason, use tools, and perform multi-step operations to fulfill a user request. It directly addresses challenges of queries that are too complex for a single-step RAG – for example, those requiring reasoning across many documents, performing intermediate calculations, or interacting with external systems (APIs, databases) beyond just fetching text.
- Workflow: The process can vary, but a common pattern is: The user submits a complex query or task. The RAG system activates as an agent that may then spawn multiple document-specific agents or tool calls. For instance, if asked to produce a market analysis, the system could create one agent to retrieve financial data, another to gather news articles, and another to fetch expert opinions. A top-level meta-agent oversees these, deciding what needs to be done in what order. Each sub-agent retrieves or computes its piece of the puzzle. The meta-agent then synthesizes all the collected information, and the LLM generates a coherent final report/answer. Throughout this process, the agentic system can make decisions like “If data from source A is insufficient, consult source B”, or “Ask a follow-up query about X”. Essentially, it’s a flexible framework where retrieval and generation steps are interleaved and orchestrated in service of a higher goal.
- Use Case: Agentic RAG is ideal for **open-ended research, multi-source analysis, or any complex task that would normally require a human doing multiple lookups and reasoning steps. For example, an automated research assistant tasked with compiling a competitive business report might: query a financial database, read several reports, pull in social media sentiment via an API, and then summarize everything. Another example is a diagnostic assistant in healthcare that queries multiple medical knowledge bases, patient records, and guidelines to arrive at a recommendation. Agentic RAG shines in scenarios where the AI needs to autonomously figure out what to retrieve and how to combine information from many sources. It’s essentially the embodiment of an AI agent that can “do its research.”
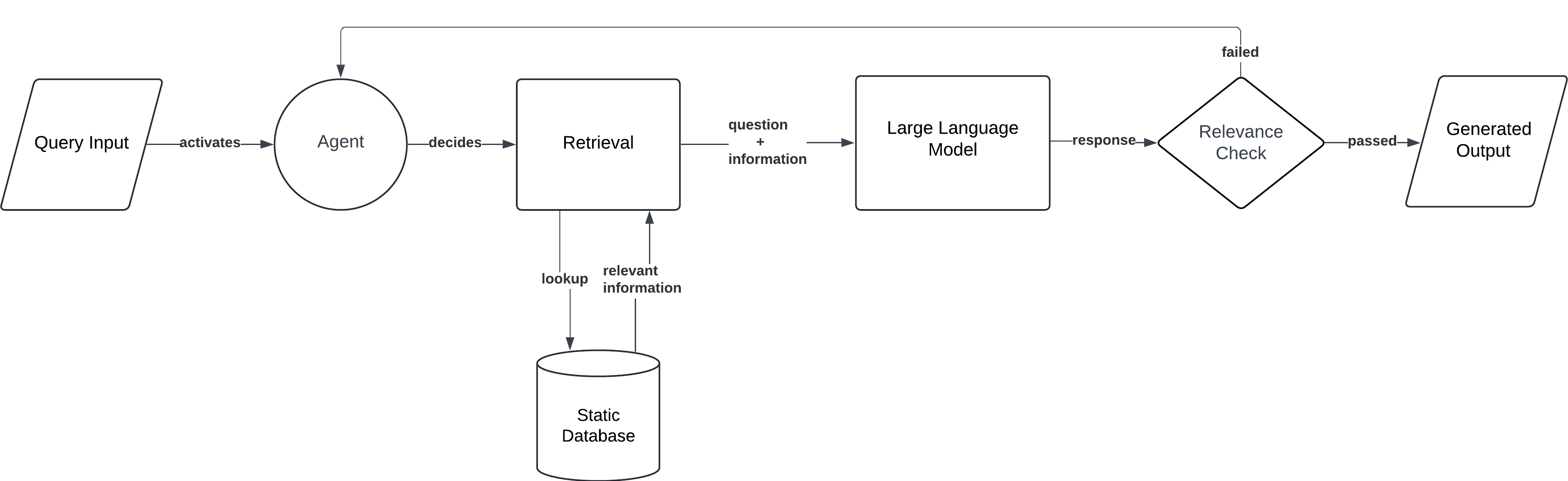
By deploying multiple agents and planning retrieval actions, Agentic RAG overcomes the limitations of simpler RAG systems in handling complexity and scale. It marks a shift from a predefined pipeline to a more adaptive, planner-executor paradigm for information retrieval and synthesis. Of course, with this power comes increased complexity in design and potential challenges in ensuring the agents stay aligned and efficient.
Conclusion
The progression from Simple RAG to Agentic RAG demonstrates an ongoing effort to make AI systems more knowledgeable, reliable, and context-aware. Each new architecture builds on the last, solving a specific bottleneck: Simple RAG brought in outside knowledge to reduce hallucinations; RAG with Memory preserved context; Branched RAG made retrieval source-aware; HyDe improved relevance for vague queries; Adaptive RAG optimized the effort spent per query; Corrective RAG put quality checks on retrieved info; Self-RAG let the model iteratively fill gaps; and Agentic RAG enabled complex multi-step reasoning across sources. This evolutionary story is essentially a series of innovations to handle the real-world demands of increasingly complex AI applications.
Choosing the right RAG architecture depends on your application’s needs. Simpler architectures are easier to implement and suffice for straightforward tasks, while advanced ones unlock capabilities at the cost of greater complexity. For example, if you just need a fact bot for a single database, Simple RAG might be enough. But if you’re building an AI research analyst, you might consider Agentic RAG to handle the breadth and depth of queries. Understanding these patterns is crucial – it’s a strategic decision as much as a technical one, affecting user experience and system performance.
One thing is clear: RAG is evolving quickly as we push the boundaries of what AI can do with the vast information available to it. By leveraging the right architecture, we empower our AI systems to not only retrieve knowledge but to do so in an intelligent, context-savvy way. This makes their generated responses more accurate, relevant, and ultimately more useful for users. Each step in this evolution brings us closer to AI that can truly act as an expert research assistant – one that remembers context, finds the best sources, double-checks its facts, and reasons through complex problems, all in the service of providing the best answers possible.
Opinions expressed by DZone contributors are their own.
Comments