Build an Advanced RAG App: Query Rewriting
Building on the last article where we learned how to build a basic RAG app, now take the first step into Advanced RAG with query rewriting.
Join the DZone community and get the full member experience.
Join For FreeIn the last article, I established the basic architecture for a basic RAG app. In case you missed that, I recommend that you first read that article. That will set the base from which we can improve our RAG system. Also in that last article, I listed some common pitfalls that RAG applications tend to fail on. We will be tackling some of them with some advanced techniques in this article.
To recap, a basic RAG app uses a separate knowledge base that aids the LLM in answering the user’s questions by providing it with more context. This is also called a retrieve-then-read approach.
The Problem
To answer the user’s question, our RAG app will retrieve appropriate based on the query itself. It will find chunks of text on the vector DB with similar content to whatever the user is asking. Other knowledge bases (search engines, etc.) also apply. The problem is that the chunk of information where the answer lies might not be similar to what the user is asking. The question can be badly written, or expressed differently to what we expect. And, if our RAG app can’t find the information needed to answer the question, it won’t answer correctly.
There are many ways to solve this problem, but for this article, we will look at query rewriting.
What Is Query Rewriting?
Simply put, query rewriting means we will rewrite the user query in our own words so that our RAG app will know best how to answer. Instead of just doing retrieve-then-read, our app will do a rewrite-retrieve-read approach.
We use a Generative AI model to rewrite the question. This model can be a large model, like (or the same as) the one we use to answer the question in the final step. It can also be a smaller model, specially trained to perform this task.
Additionally, query rewriting can take many different forms depending on the needs of the app. Most of the time, basic query rewriting will be enough. But, depending on the complexity of the questions we need to answer, we might need more advanced techniques like HyDE, multi-querying, or step-back questions. More information on those is in the following section.
Why Does It Work?
Query rewriting usually gives better performance in any RAG app that is knowledge-intensive. This is because RAG applications are sensitive to the phrasing and specific keywords of the query. Paraphrasing this query is helpful in the following scenarios:
- It restructures oddly written questions so they can be better understood by our system.
- It erases context given by the user which is irrelevant to the query.
- It can introduce common keywords, which will give it a better chance of matching up with the correct context.
- It can split complex questions into different sub-questions, which can be more easily responded to separately, each with their corresponding context.
- It can answer questions that require multiple levels of thinking by generating a step-back question, which is a higher-level concept question to the one from the user. It then uses both the original and the step-back questions to retrieve context.
- It can use more advanced query rewriting techniques like HyDE to generate hypothetical documents to answer the question. These hypothetical documents will better capture the intent of the question and match up with the embeddings that contain the answer in the vector DB.
How To Implement Query Rewriting
We have established that there are different strategies for query rewriting depending on the complexity of the questions. We will briefly discuss how to implement each of them. After, we will see a real example to compare the result of a basic RAG app versus a RAG app with query rewriting. You can also follow all the examples in the article’s Google Colab notebook.
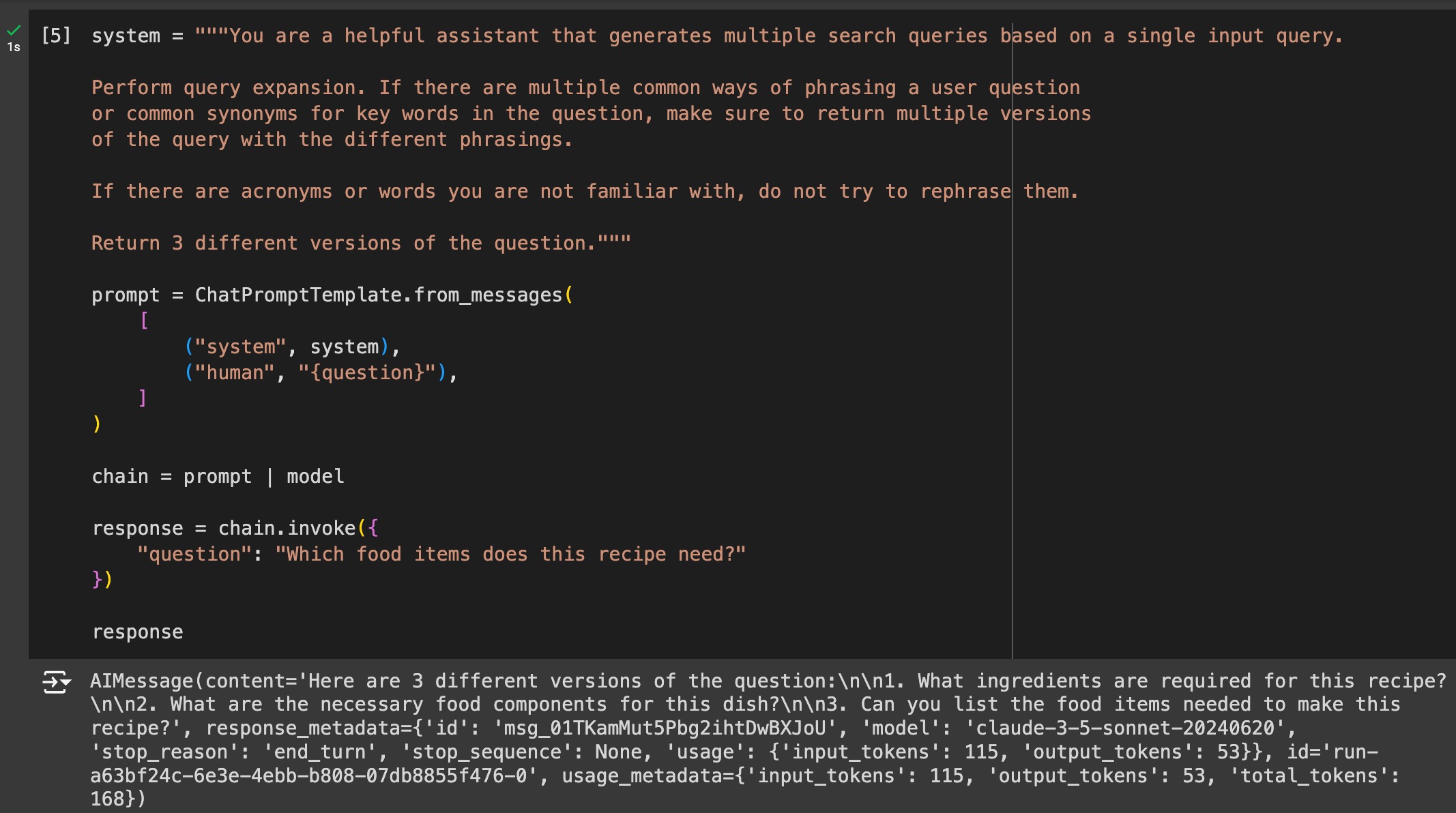
Zero-Shot Query Rewriting
This is simple query rewriting. Zero-shot refers to the prompt engineering technique of giving examples of the task to the LLM, which in this case, we give none.
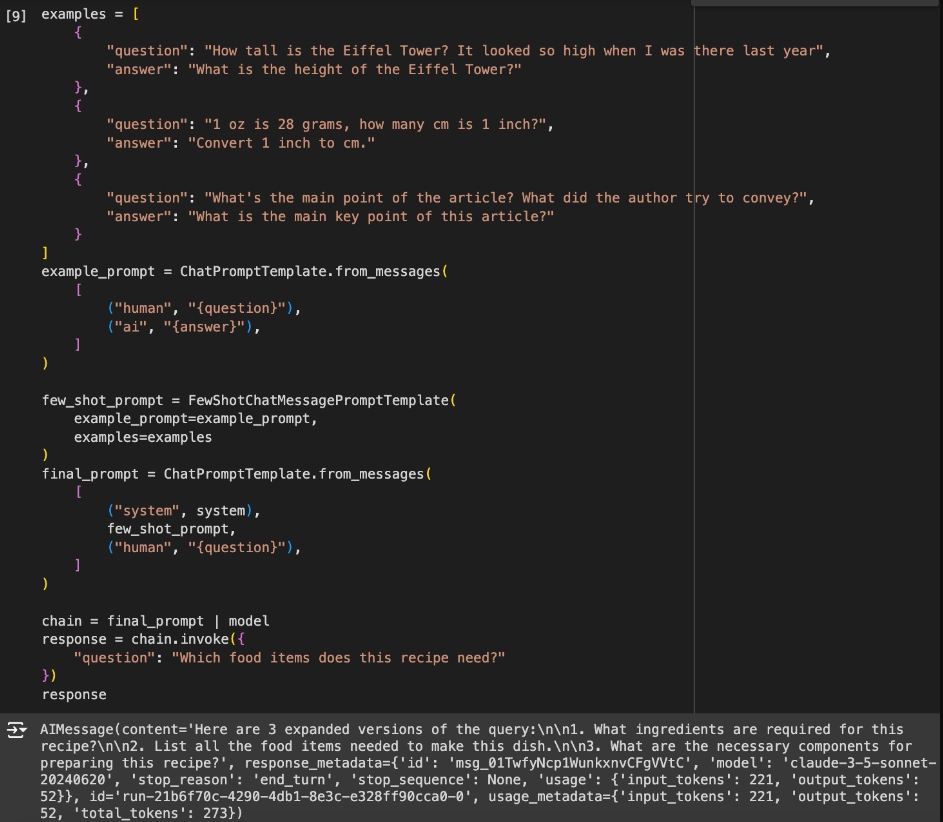
Few-Shot Query Rewriting
For a slightly better result at the cost of using a few more tokens per rewrite, we can give some examples of how we want the rewrite to be done.
Trainable Rewriter
We can fine-tune a pre-trained model to perform the query rewriting task. Instead of relying on examples, we can teach it how query rewriting should be done to achieve the best results in context retrieving. Also, we can further train it using reinforcement learning so it can learn to recognize problematic queries and avoid toxic and harmful phrases. We can also use an open-source model that has already been trained by somebody else on the task of query rewriting.
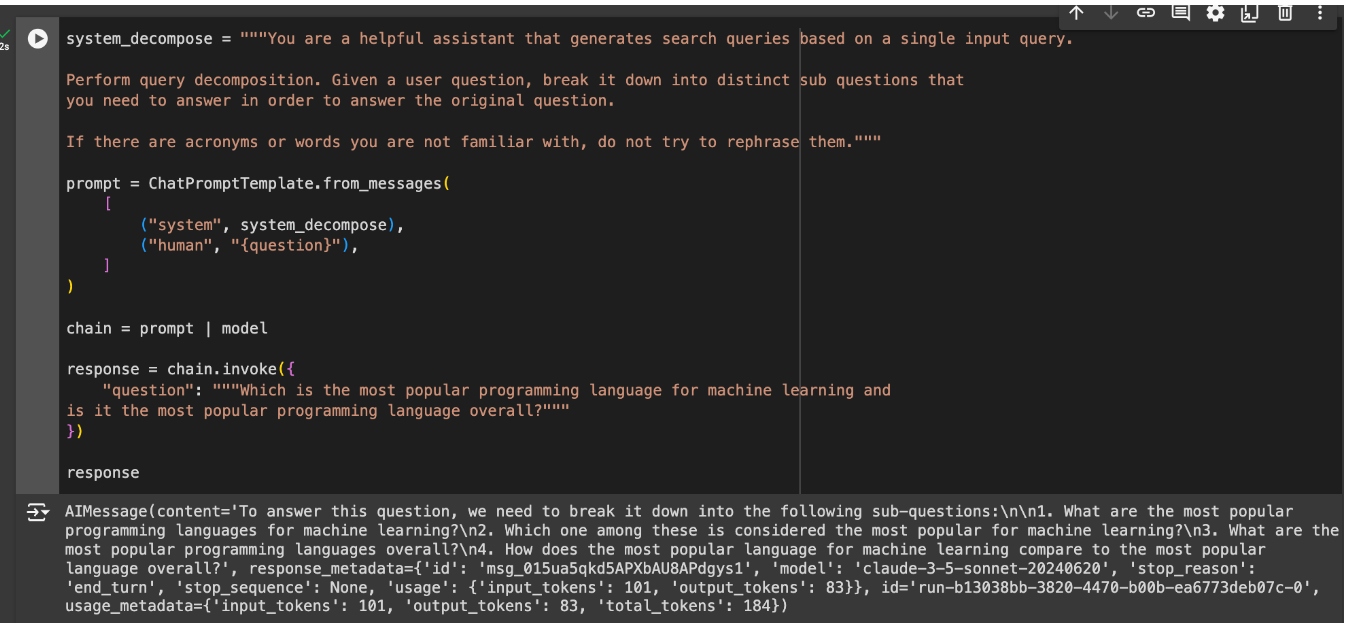
Sub-Queries
If the user query contains multiple questions, this can make context retrieval tricky. Each question probably needs different information, and we are not going to get all of it using all the questions as the basis for information retrieval. To solve this problem, we can decompose the input into multiple sub-queries, and perform retrieval for each of the sub-queries.
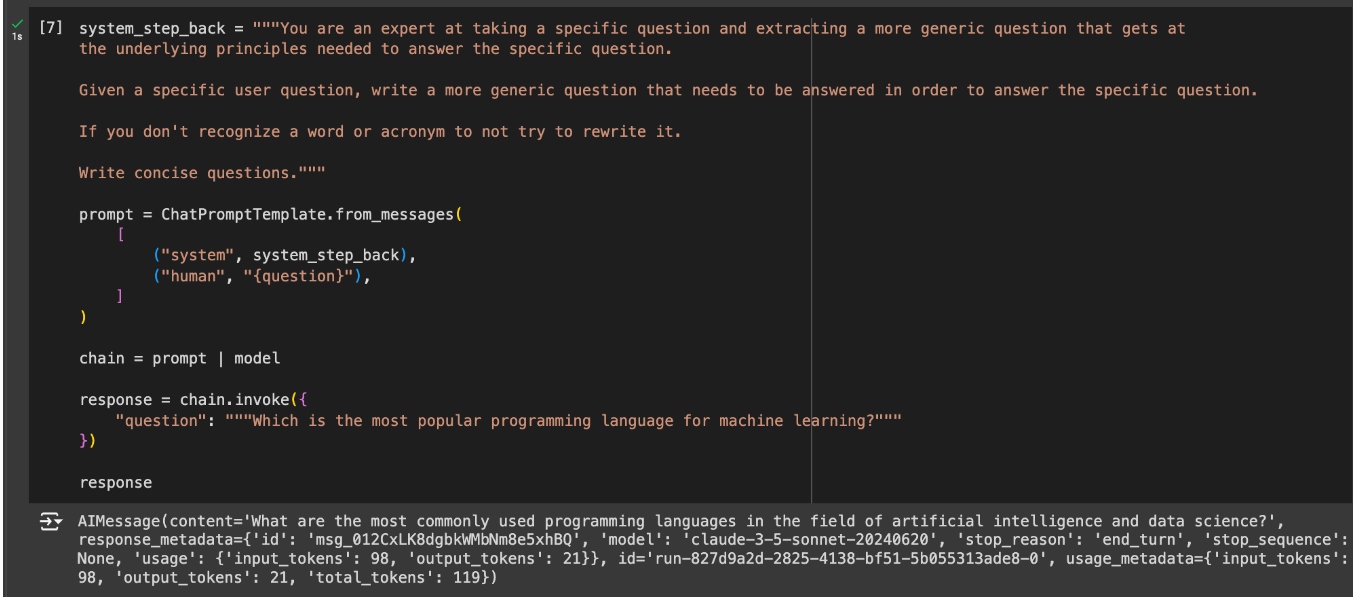
Step-Back Prompt
Many questions can be a bit too complex for the RAG pipeline’s retrieval to grasp the multiple levels of information needed to answer them. For these cases, it can be helpful to generate multiple additional queries to use for retrieval. These queries will be more generic than the original query. This will enable the RAG pipeline to retrieve relevant information on multiple levels.
HyDE
Another method to improve how queries are matched with context chunks is Hypothetical Document Embeddings or HyDE. Sometimes, questions and answers are not that semantically similar, which can cause the RAG pipeline to miss critical context chunks in the retrieval stage. However, even if the query is semantically different, a response to the query should be semantically similar to another response to the same query. The HyDE method consists of creating hypothetical context chunks that answer the query and using them to match the real context that will help the LLM answer.
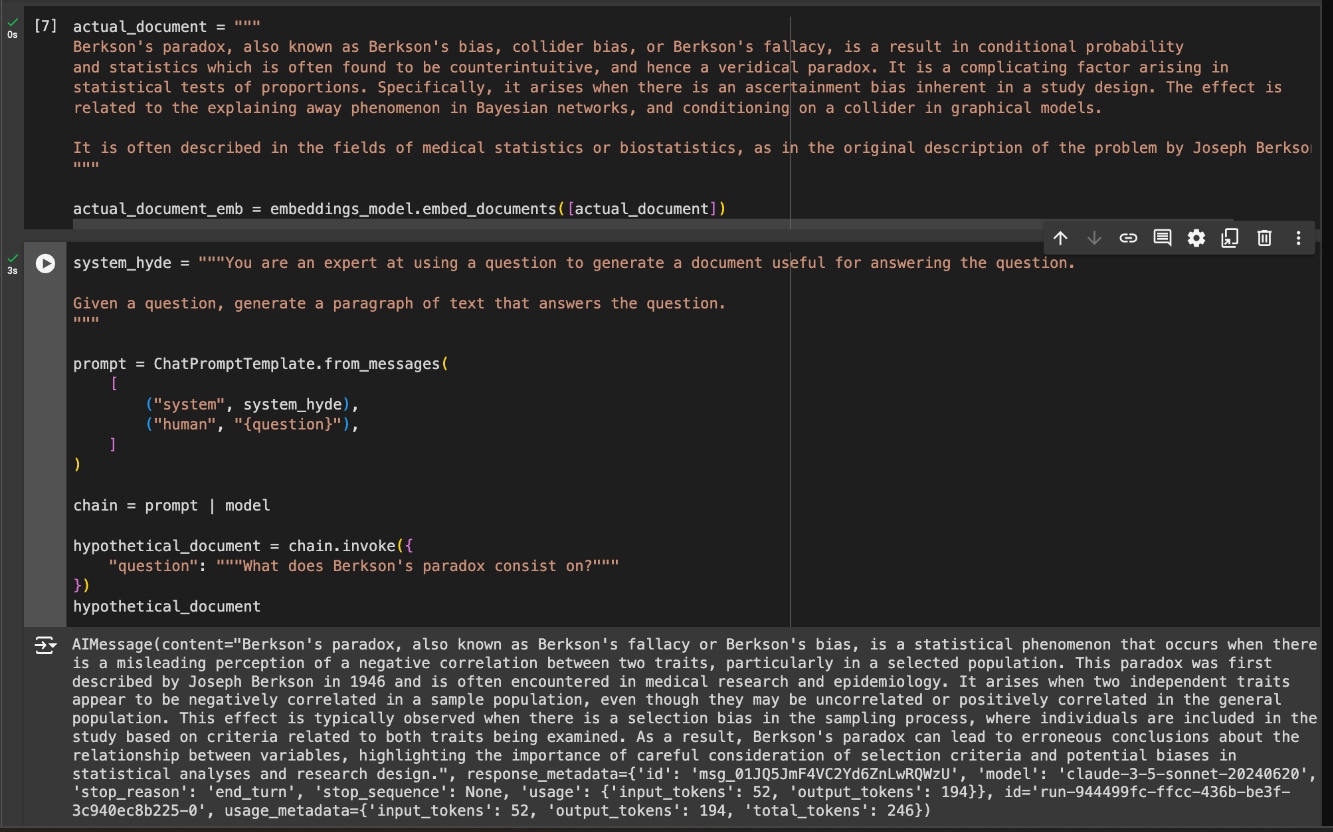

Example: RAG With vs Without Query Rewriting
Taking the RAG pipeline from the last article, “How To Build a Basic RAG App," we will introduce query rewriting into it. We will ask it a question a bit more advanced than last time and observe whether the response improves with query rewriting over without it. First, let’s build the same RAG pipeline. Only this time, I’ll only use the top document returned from the vector database to be less forgiving to missed documents.
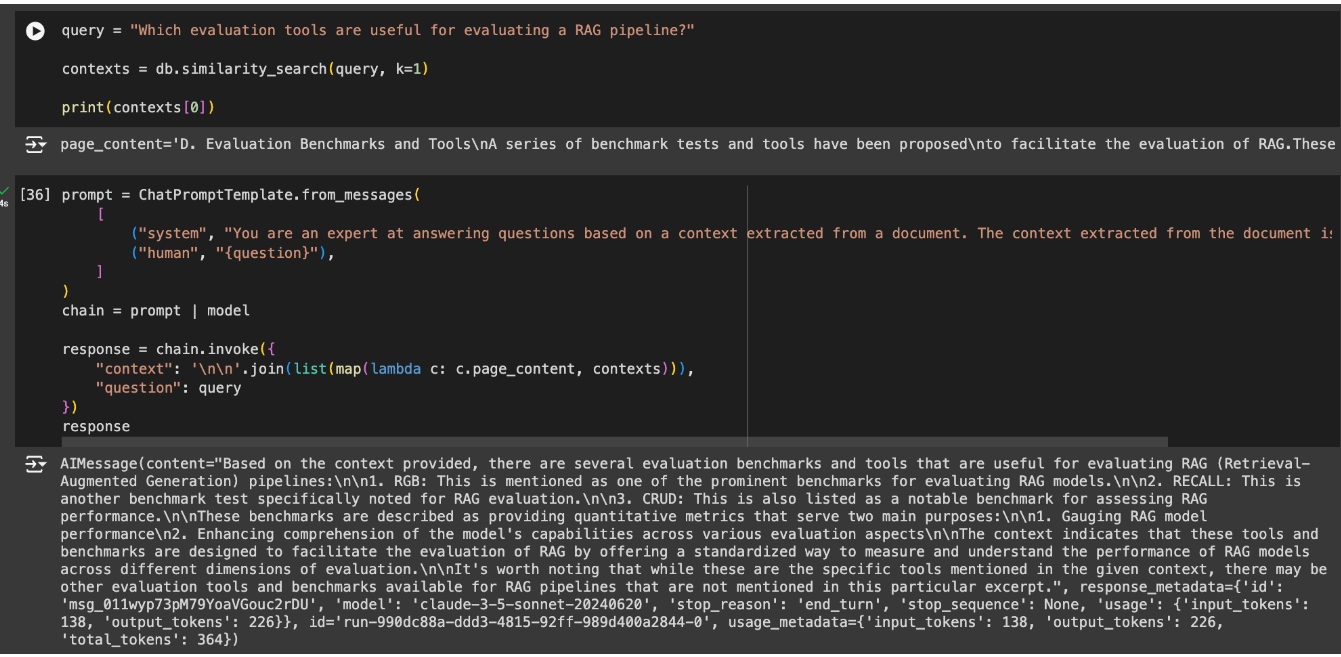
The response is good and based on the context, but it got caught up in me asking about evaluation and missed that I was specifically asking for tools. Therefore, the context used does have information on some benchmarks, but it misses the next chunk of information that talks about tools.
Now, let’s implement the same RAG pipeline but now, with query rewriting. As well as the query rewriting prompts, we have already seen in the previous examples, I’ll be using a Pydantic parser to extract and iterate over the generated alternative queries.
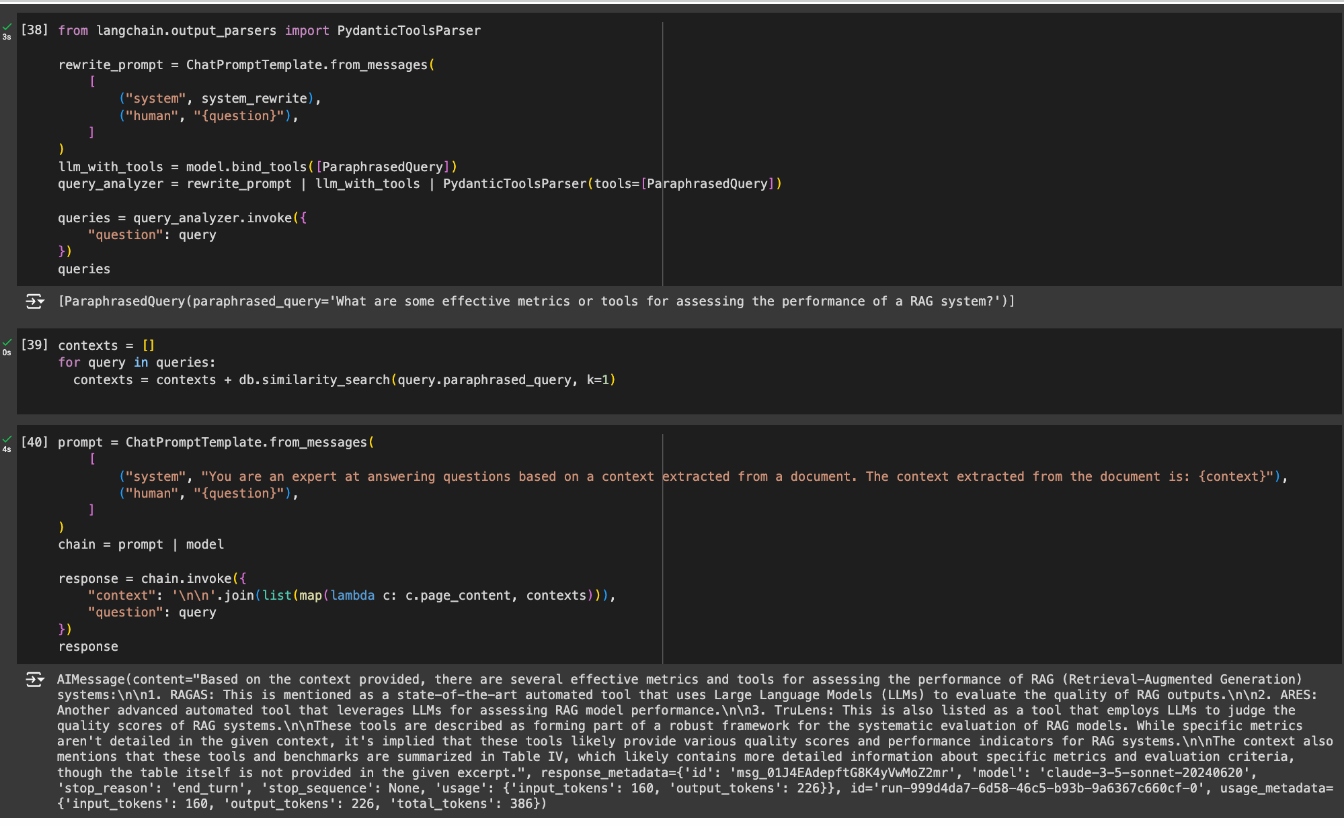
The new query now matches with the chunk of information I wanted to get my answer from, giving the LLM a better chance of answering a much better response to my question.
Conclusion
We have taken our first step out of basic RAG pipelines and into Advanced RAG. Query rewriting is a very simple Advanced RAG technique, but a powerful one for improving the results of a RAG pipeline. We have gone over different ways to implement it depending on what kind of questions we need to improve. In future articles, we will go over other Advanced RAG techniques that can tackle different RAG issues than those seen in this article.
Published at DZone with permission of Roger Oriol. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments