Chat With Your Knowledge Base: A Hands-On Java and LangChain4j Guide
In this hands-on guide, you will learn to build a Java RAG chat application with LangChain4j to query your custom knowledge base.
Join the DZone community and get the full member experience.
Join For FreeDisclaimer: This article details an experimental project built for learning and demonstration purposes. The implementation described is not intended as a production-grade solution. Some parts of the code were generated using JetBrains’ AI Agent, Junie.
Large language models (LLMs) like GPT-4, Llama, and Gemini have revolutionized how we interact with information. However, their knowledge is generally limited to the data they were trained on. What if you need an AI assistant that understands your specific domain knowledge — your company’s internal documentation, product specs, or operational data from a complex system?
This is where retrieval-augmented generation (RAG) comes in. RAG enhances LLMs by providing them with relevant information retrieved from your specific knowledge sources before they generate a response. This allows them to answer questions based on data they weren’t originally trained on.
This article is a hands-on guide for Java developers looking to build such a system. We’ll walk through creating a simple application that allows you to “chat” with a custom knowledge base using Java and the LangChain4j library. LangChain4j simplifies the process of integrating LLMs and building AI applications within the Java ecosystem.
By the end of this guide, you’ll have built a basic RAG pipeline that:
- Loads information from local text files representing your knowledge base.
- Processes and stores this information in a way the LLM can access.
- Uses an LLM (like OpenAI’s GPT or a local model via Ollama) combined with retrieved knowledge to answer your questions.
What Is Retrieval-Augmented Generation (RAG)?
Imagine asking an LLM a question about a specific error code in your internal system. Without RAG, the LLM might guess or say it doesn’t know.
RAG changes this by adding a crucial step:
- Retrieve: When you ask a question, the system first searches your specific knowledge base (documents, databases, etc.) for information relevant to your query.
- Augment: This retrieved information (the “context”) is then added to your original question and sent as a more detailed prompt to the LLM.
- Generate: The LLM uses both your question and the provided context to generate an informed answer.
Essentially, RAG gives the LLM the relevant “cheat sheet” just before it needs to answer your domain-specific question.
Why LangChain4j?
LangChain4j is a Java library inspired by the popular Python LangChain project. It provides helpful abstractions and tools to streamline the development of LLM-powered applications in Java. It simplifies tasks like:
- Connecting to various LLM providers (OpenAI, Ollama, Gemini, etc.).
- Managing prompts and chat memory.
- Loading and transforming documents.
- Integrating with embedding models and vector stores (essential for RAG).
- Creating AI services and agents.
Using LangChain4j means you can focus more on your application’s logic rather than the boilerplate code often involved in API integrations and data handling for AI tasks.
The Scenario: Querying Operational Knowledge
For this demo, we won’t build a full-blown industrial system interface. Instead, we’ll simulate a knowledge base containing basic information about technical components, their status, and known issues or operational rules. This information will be stored in simple text files. Our goal is to build a chat interface that can answer questions based only on the information in these files, using RAG.
Prerequisites
Before we start coding, make sure you have the following installed:
- Java Development Kit (JDK): Version 17 or later is recommended; JDK 21 or later is preferred.
- Build tool: Apache Maven or Gradle. We’ll use Maven examples here.
- IDE: A Java IDE like IntelliJ IDEA, Eclipse, or VS Code with Java extensions.
- LLM access: You need a way to interact with a large language model (LLM). Choose one:
- Option A (OpenAI): An API key from OpenAI. You can get one from their website. LangChain4j allows using “demo” as a key for basic, rate-limited testing.
- Option B (Ollama – Local): Install Ollama on your machine. After installation, pull a model via the command line (e.g., ollama pull llama3 or ollama pull mistral). This allows you to run the LLM entirely locally.
Step 1: Project Setup (Maven)
Create a new Maven project in your IDE. Open the pom.xml file and add the necessary LangChain4j dependencies.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>${langchain4j.version}</version>
</dependency>You can choose either the langchain4j-open-ai or langchain4j-ollama dependency.
Step 2: Creating the Knowledge Base Files
We need some raw data to feed our RAG system. Create a directory named src/main/resources in your project structure. Inside this directory, create two text files:
src/main/resources/components.txt
Component ID: PUMP-001. Type: Centrifugal Pump. Status: Running. Connected to: VALVE-001, PIPE-002. Location: Sector A.
Component ID: VALVE-001. Type: Gate Valve. Status: Open. Connected to: PUMP-001, TANK-A. Location: Sector A.
Component ID: SENSOR-T1. Type: Temperature Sensor. Monitors: PUMP-001 Casing. Reading: 65C. Unit: Celsius. Location: Sector A.
Component ID: SENSOR-P1. Type: Pressure Sensor. Monitors: PIPE-002. Reading: 150. Unit: PSI. Location: Sector B.
Component ID: MOTOR-001. Type: Electric Motor. Status: Running. Drives: PUMP-001. Location: Sector A.src/main/resources/knowledge.txt
Fault ID: F001. Description: High Temperature on PUMP-001. Possible Causes: Low lubrication, bearing wear, blocked outlet VALVE-001. Recommended Action: Check lubrication levels and bearing condition.
Event ID: E001. Description: Pressure drop in PIPE-002 below 100 PSI. Related Components: PUMP-001, VALVE-001, SENSOR-P1. Possible Causes: Leak in PIPE-002, PUMP-001 failure, VALVE-001 partially closed.
Rule ID: R001. Condition: If SENSOR-T1 reading > 80C. Action: Generate HIGH_TEMP_ALERT for PUMP-001. Priority: High.
Maintenance Note M001: PUMP-001 bearings last replaced 6 months ago. Next inspection due in 1 month.
Safety Procedure S001: Before servicing PUMP-001, ensure MOTOR-001 is locked out and VALVE-001 is closed.These files contain simple, factual statements about our simulated system.
Step 3: Ingesting the Knowledge (Building the RAG Pipeline)
Now, we write the Java code to load these files, process them, and store them in a way that’s searchable. This process involves:
- Loading: Reading the content from the text files.
- Splitting: Breaking down the documents into smaller, manageable chunks (or “segments”). This is important because LLMs have limits on how much text they can process at once, and smaller chunks often lead to more relevant retrieval.
- Embedding: Converting each text segment into a numerical vector (an “embedding”) using an Embedding Model. These vectors capture the semantic meaning of the text. Similar concepts will have similar vectors.
- Storing: Saving these embeddings along with their corresponding text segments in an “Embedding Store” (often a vector database, but we’ll use a simple in-memory store for this demo).
Create a new Java class, KnowledgeBaseIngestor.java:
package com.example; // Use your package name
package ca.bazlur.util;
import ca.bazlur.service.KnowledgeBaseService;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel; // Choose one
// import dev.langchain4j.model.ollama.OllamaEmbeddingModel; // Choose one
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.io.IOException;
import java.io.InputStream;
import java.net.URISyntaxException;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.Objects;
public class KnowledgeBaseIngestor {
/**
* Loads documents from resource files, creates embeddings, and stores them in an in-memory store.
*
* @return An EmbeddingStore containing the processed knowledge base.
* @throws URISyntaxException if the resource file paths are invalid.
*/
public static EmbeddingStore<TextSegment> ingestData() throws URISyntaxException, IOException {
System.out.println("Starting knowledge base ingestion...");
// --- 1. Load Documents ---
Document componentsDoc = loadDocumentFromResource("components.txt", new TextDocumentParser());
Document knowledgeDoc = loadDocumentFromResource("knowledge.txt", new TextDocumentParser());
List<Document> documents = List.of(componentsDoc, knowledgeDoc);
System.out.println("Documents loaded successfully.");
// --- 2. Setup Embedding Model ---
// Choose *one* embedding model provider:
// Option A: OpenAI (Requires OPENAI_API_KEY environment variable or use "demo")
// System.out.println("Initializing OpenAI Embedding Model...");
// EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
// .apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
// .logRequests(true) // Optional: Log requests to OpenAI
// .logResponses(true) // Optional: Log responses from OpenAI
// .build();
// Option B: Ollama (Requires Ollama server running locally)
System.out.println("Initializing Ollama Embedding Model...");
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434") // Default Ollama URL
.modelName("llama3")
.build();
System.out.println("Embedding Model initialized.");
// --- 3. Setup Embedding Store ---
// We use a simple in-memory store for this demo.
// For persistent storage, explore options like Chroma, Pinecone, Weaviate, etc.
System.out.println("Initializing In-Memory Embedding Store...");
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
System.out.println("Embedding Store initialized.");
// --- 4. Setup Ingestion Pipeline ---
// Define how documents are split into segments (chunking strategy)
// recursive(maxSegmentSize, maxOverlap) splits text recursively, trying to keep paragraphs/sentences together.
// 300 characters per segment, 30 characters overlap between segments.
DocumentSplitter splitter = DocumentSplitters.recursive(300, 30);
System.out.println("Using recursive document splitter (300 chars, 30 overlap).");
// EmbeddingStoreIngestor handles splitting, embedding, and storing.
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
// --- 5. Ingest Documents ---
System.out.println("Ingesting documents into the embedding store...");
ingestor.ingest(documents);
System.out.println("Ingestion complete. Embedding store contains");
return embeddingStore;
}
/**
* Helper method to get the Path of a resource file.
* Handles running from IDE and within a JAR file.
* @param resourceName The name of the file in src/main/resources
* @return The Path object for the resource.
* @throws URISyntaxException If the resource URL is malformed.
* @throws RuntimeException If the resource is not found.
*/
private static Document loadDocumentFromResource(String resourceName, DocumentParser parser) throws IOException {
try (InputStream inputStream = getResourceAsStream(resourceName)) {
Objects.requireNonNull(inputStream, "Resource not found: " + resourceName);
return parser.parse(inputStream);
}
}
protected static InputStream getResourceAsStream(String resourceName) {
return KnowledgeBaseService.class.getClassLoader().getResourceAsStream(resourceName);
}
public static void main(String[] args) {
try {
EmbeddingStore<TextSegment> store = ingestData();
} catch (URISyntaxException e) {
System.err.println("Error finding resource files: " + e.getMessage());
e.printStackTrace();
} catch (Exception e) {
System.err.println("An error occurred during ingestion: " + e.getMessage());
e.printStackTrace();
}
}
}Explanation of Key Classes
- TextDocumentParser: A simple parser for plain text files.
- DocumentSplitters.recursive(): A strategy for splitting documents into segments, trying to respect sentence/paragraph boundaries. The numbers (e.g., 300, 30) control the maximum segment size and the overlap between segments.
- EmbeddingModel (OpenAiEmbeddingModel / OllamaEmbeddingModel): The interface and implementations for converting text to embeddings. Note: For Ollama, using a dedicated embedding model like nomic-embed-text is generally better than using a chat model for embedding.
- InMemoryEmbeddingStore: A basic implementation of EmbeddingStore that keeps data in memory. Suitable for demos, but data is lost when the application stops unless serialized.
- EmbeddingStoreIngestor: Orchestrates the process of splitting documents, embedding the segments, and adding them to the embedding store.
Step 4: Building the Chat Interface (AiService)
Now we create the main application class that will handle user interaction. It will:
- Initialize the knowledge base by calling our KnowledgeBaseIngestor.
- Set up a Chat Language Model (the LLM that generates responses).
- Set up a ContentRetriever that uses the embedding store to find relevant context for user queries.
- Use LangChain4j’s AiServices to create a simple chat interface.
- Optionally use ChatMemory to allow the assistant to remember the conversation history.
Create a new Java class, KnowledgeAssistant.java:
package ca.bazlur.util;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.ollama.OllamaChatModel;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.store.embedding.EmbeddingStore;
import java.util.Scanner;
public class KnowledgeAssistant {
interface Assistant {
@SystemMessage("""
You are an AI assistant specialized in querying operational knowledge about technical systems
(components, status, faults, procedures). Answer user questions accurately and concisely,
relying *strictly* on the information provided in the context. Do not use any prior knowledge or make assumptions.
""")
String chat(String userMessage);
}
public static void main(String[] args) {
try {
// --- 1. Ingest Knowledge Base ---
EmbeddingStore<TextSegment> embeddingStore = KnowledgeBaseIngestor.ingestData();
// --- 2. Setup Chat Model ---
// Option A: OpenAI
/*
System.out.println("Initializing OpenAI Chat Model...");
ChatLanguageModel chatModel = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
.modelName("gpt-4o") // Or gpt-4o, etc.
.logRequests(true)
.logResponses(true)
.build();
// We also need the corresponding embedding model for the retriever
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY") != null ? System.getenv("OPENAI_API_KEY") : "demo")
.logRequests(true)
.logResponses(true)
.build();
*/
// Option B: Ollama
System.out.println("Initializing Ollama Chat Model...");
ChatLanguageModel chatModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3") // Or mistral, etc.
.build();
// We also need the corresponding embedding model for the retriever
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
System.out.println("Chat Model initialized.");
// --- 3. Setup Content Retriever (RAG) ---
System.out.println("Initializing Content Retriever...");
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel) // Use the *same* embedding model used during ingestion
.maxResults(3) // Retrieve top 3 most relevant segments
.minScore(0.6) // Filter out segments with relevance score below 0.6
.build();
System.out.println("Content Retriever initialized.");
// --- 4. Setup Chat Memory (Optional) ---
// This allows the assistant to remember previous parts of the conversation.
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
System.out.println("Chat Memory initialized (window size 10).");
// --- 5. Create the AiService ---
// AiServices wires together the chat model, retriever, memory, etc.
// It automatically implements the Assistant interface based on annotations and configuration.
System.out.println("Creating AI Service...");
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
System.out.println("AI Service created. Assistant is ready.");
// --- 6. Start Interactive Chat Loop ---
Scanner scanner = new Scanner(System.in);
System.out.println("\nAssistant: Hello! Ask me about the system components or known issues.");
while (true) {
System.out.print("You: ");
String userQuery = scanner.nextLine();
if ("exit".equalsIgnoreCase(userQuery)) {
System.out.println("Assistant: Goodbye!");
break;
}
String assistantResponse = assistant.chat(userQuery);
System.out.println("Assistant: " + assistantResponse);
}
scanner.close();
} catch (Exception e) {
System.err.println("An error occurred during assistant setup or chat: " + e.getMessage());
e.printStackTrace();
}
}
}Explanation of Key Classes
- ChatLanguageModel (OpenAiChatModel / OllamaChatModel): Interface and implementations for the core LLM that generates responses.
- EmbeddingStoreContentRetriever: An implementation of ContentRetriever specifically designed to work with an EmbeddingStore. It takes the user query, embeds it using the same EmbeddingModel used during ingestion, searches the EmbeddingStore for similar embeddings, and retrieves the corresponding text segments.
- ChatMemory (MessageWindowChatMemory): Stores the history of the conversation. MessageWindowChatMemory keeps only the last N messages.
- AiServices: A powerful factory in LangChain4j that creates an implementation of your defined interface (here, Assistant). It automatically handles:
- Taking the user message.
- (If ContentRetriever is provided) Retrieving relevant context.
- (If ChatMemory is provided) Loading previous messages.
- Constructing the final prompt (including context and history) for the ChatLanguageModel.
- Getting the response from the LLM.
- (If ChatMemory is provided) Saving the current exchange.
- Returning the LLM’s response.
Step 5: Running and Testing
- Set environment variable (if using OpenAI): Make sure your
OPENAI_API_KEYenvironment variable is set. - Run Ollama (if using Ollama): Ensure your Ollama application is running in the background.
- Compile: Use Maven to compile your project (e.g., mvn clean compile).
- Run: Execute the
KnowledgeAssistantclass. You can run it from your IDE or use Maven to create an executable JAR (mvn clean package) and run it (java -jar target/knowledge-base-chat-1.0-SNAPSHOT.jar).
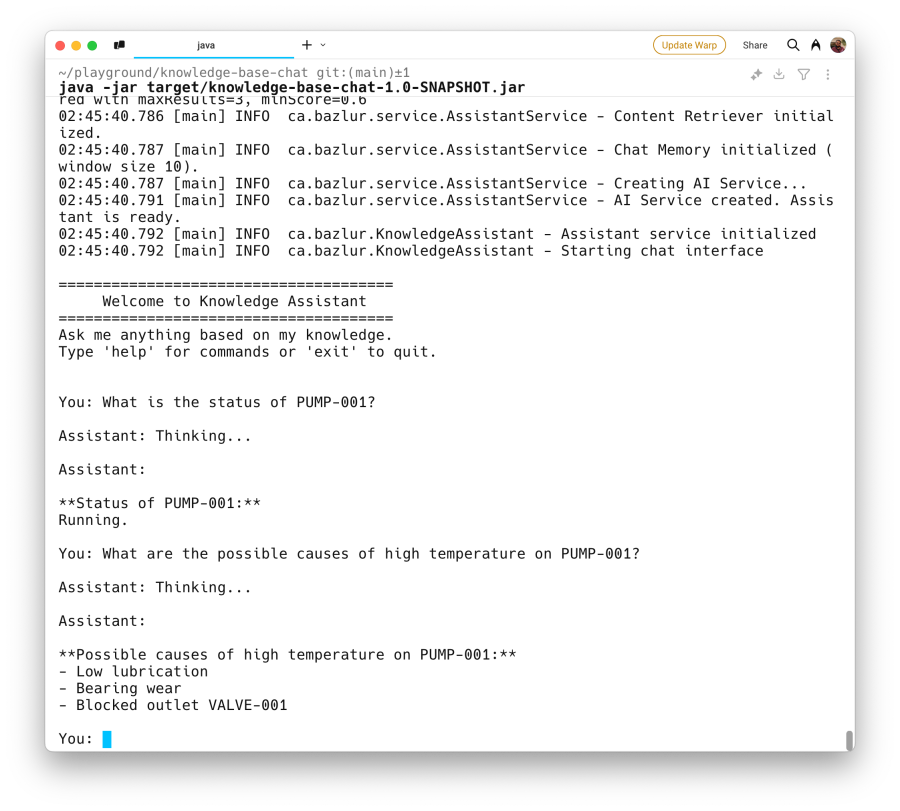
Once running, you should see the ingestion messages followed by the “Assistant: Hello!” prompt. Try asking questions based on the content of components.txt and knowledge.txt:
- You: What is the status of PUMP-001?
- You: Where is SENSOR-P1 located?
- You: What are the possible causes of high temperature on PUMP-001?
- You: What is rule R001?
- You: Tell me about PUMP-001.
- You: What is the safety procedure for PUMP-001?
Observe how the assistant’s answers are derived from the information you provided in the text files, demonstrating the RAG process in action.
Conclusion
Congratulations! You’ve built a basic retrieval-augmented generation (RAG) application using Java and LangChain4j. You’ve seen how to load custom knowledge, process it into searchable embeddings, and create an AI assistant that leverages this specific information to provide relevant answers.
This approach of combining the power of LLMs with your domain-specific data opens up vast possibilities for building intelligent applications that truly understand your world.
Resources
For the complete source code, visit: https://github.com/rokon12/knowledge-base-chat.
If you’re looking for more examples integrating LLMs with Java, especially within the Jakarta EE context, you might find this repository helpful: https://github.com/learnj-ai/llm-jakarta.
Published at DZone with permission of A N M Bazlur Rahman. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments