Mocking Kafka for Local Spring Development
When you don't need a real Kafka cluster yet, a lightweight substitute can remove a lot of friction. Use a portable mock environment and wire it into your app.
Join the DZone community and get the full member experience.
Join For FreeSome time ago, a former teammate of mine reached out with a very specific request:
Can you add a way to mock Kafka in your app? I need something simple, just a way for me to produce messages so my app can consume them. I just don't want to spin up a real Kafka for it.
I liked that request: not asking for a Kafka replacement or full protocol compatibility, no production-grade behavior, just something small and practical.
Kafka is a great tool, and probably most of the time it is justified. This article is not an argument against it. But there is a common situation where the thing you need to test is much smaller than the infrastructure needed to support it.
Sometimes all you really want is to trigger the consumer logic, watch logs, and inspect side effects. Not to troubleshoot Docker setup, broker setup/startup, topic provisioning, or connectivity (especially in your CI).
What I decided was needed:
- a way to put messages somewhere
- a way for an app to consume it (Java Spring application with a listener)
- topics, partitions, and offsets
- maybe a predefined set of records available at each startup repeatability without a lot of setup.
I deliberately did not aim for:
- high performance
- full Kafka feature coverage (such as timestamps and every advanced behavior)
- exact production semantics.
What Was Built
It has two connected parts.
1. Kafka-Like Behavior Inside Mockachu Itself
Inside the main application (Mockachu), it keeps topic/partition data in memory, tracks producer and consumer offsets, supports initial seeded records, and exposes HTTP endpoints for producing and consuming records.
The HTTP surface looks like this:
@PostMapping(value = "/producer", produces = MediaType.APPLICATION_JSON_VALUE)
public String producer(@RequestBody List<MockachuKafkaProducerRequest> body) {
kafkaService.produce(body);
return "";
}
@PostMapping(value = "/consumer", produces = MediaType.APPLICATION_JSON_VALUE)
public CompletableFuture<List<KafkaRecord>> consumer(@RequestBody List<MockachuKafkaConsumerRequest> body) {
return CompletableFuture.supplyAsync(() -> kafkaService.consume(body));A message comes in through the producer endpoint, lands in in-memory topic/partition storage, and later gets returned through the consumer endpoint. The service keeps a map of topic-partition data and appends records with offsets as messages are produced:
private final Map<TopicPartition, TopicPartitionData> map = new ConcurrentHashMap<>();
private void produce(MockachuKafkaProducerRequest req) {
var tp = new TopicPartition(req.topic(), req.partition());
var data = map.computeIfAbsent(tp, e -> new TopicPartitionData());
var offset = data.put(
req.topic(), req.partition(), req.timestamp(), req.key(), req.value(), req.headers());
log.info("Produced to {} at offset {}", tp, offset);
}
2. A Substitute Layer for Spring
This allows a Spring application to talk to Mockachu. That is why there is a separate kafka/ folder in the repo (link is at the end of the article). It contains Mockachu-specific substitutes for the Spring Kafka producer/consumer.
The wiring in the sample app looks like this:
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, CONSUMER_URI);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new MockachuKafkaConsumerFactory<>(props, consumerSender());
}
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new MockachuKafkaProducerFactory<>(configProps, producerSender());
}What I like about this is that it keeps things mostly the same as if you use real Kafka. The application still has producer and consumer factories, KafkaTemplate and listener, but instead of talking to a real broker, it talks to Mockachu through HTTP.
What's better, you can even create another implementation of MockachuKafkaSender (the current implementation is a WebClient wrapper) and use the aforementioned producer/consumer as you see fit, without Mockachu (to maybe create your own version of Kafka mock).
Two Usage Modes
1. Manual Trigger (The Original Request)
The exact "press a button - send one message" workflow:
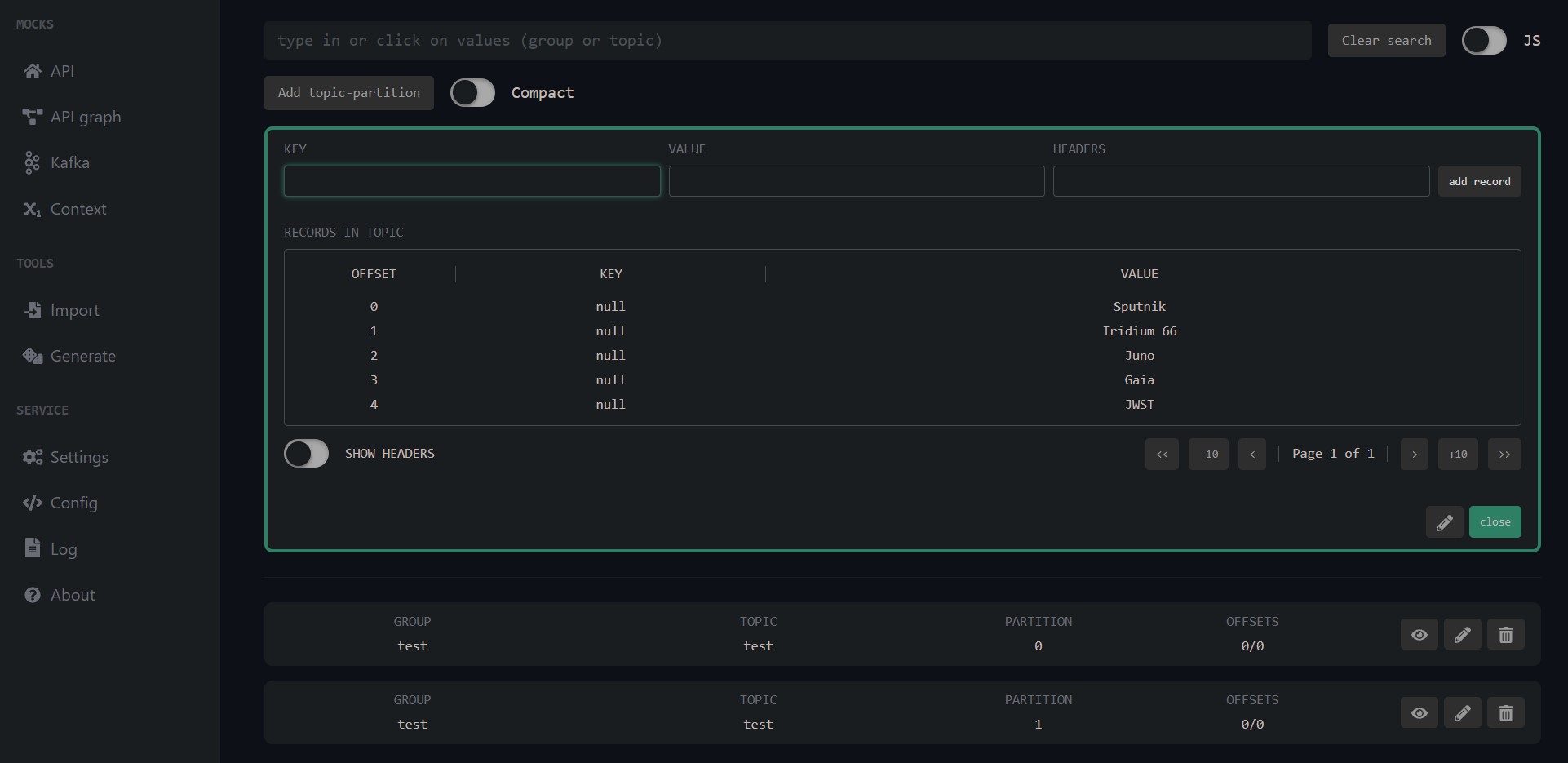
- Open Mockachu, navigate to the Kafka page, and create a Topic/Partition.
- Produce a message manually (write JSON, press "add record").
- Let the Spring consumer pick it up and see your app do its thing.
2. Seeded Startup Mode
The second mode is about a predictable/repeatable outcome. You can seed some records into topics, and they are saved in the config. A config snippet can look like this (you don't have to memorize it):
kafkaTopics:
- group: space
topic: space
partition: 0
initialData: |-
[
{ "topic": "space", "partition": 0, "value": "Sputnik" },
{ "topic": "space", "partition": 0, "value": "Juno" },
{ "topic": "space", "partition": 0, "value": "JWST" }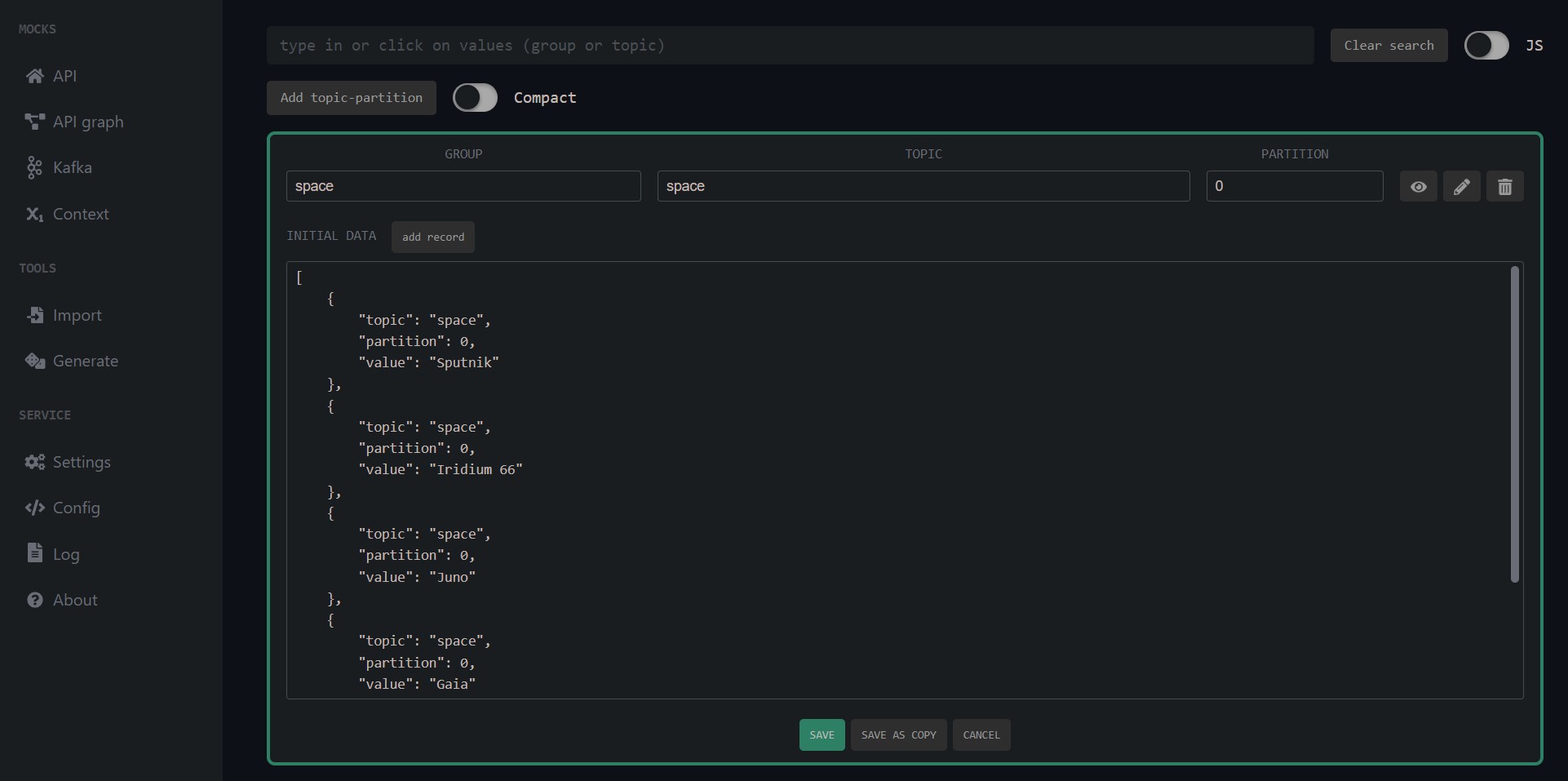
That is useful when you want to repeat the same scenarios: for team demos, processing known messages/patterns, and using it in your CI.
I like this part. Mockachu already stores a portable configuration; seeded Kafka-like records are a great addendum.
Why I Added It to Mockachu Instead of Making a Separate Tool
I did not come up with the idea "Mockachu should support Kafka"; it came from the original request. Mockachu was already a mock environment for local development. It already helped with REST mocks, scenarios, REST requests, simple tests, and dynamic behavior. So putting Kafka-like behavior there made more sense to me than creating a completely separate tool. This pushed Mockachu toward being a small local integration sandbox.
What This Is For
I think this is a good fit when you need to emulate a message broker-like behavior:
- Local Spring development
- Manually triggering consumer logic
- Lightweight demos
- Repeatable scenarios with seeded records for your CI and locally
- Early-stage test setups where a real broker would be too much.
I would not use this as a:
- Real Kafka replacement
- Production messaging system
- Compatibility guarantee for every Kafka feature
- High-throughput tool
For more details, you can visit the GitHub repo.
Opinions expressed by DZone contributors are their own.
Comments