Hallucination Has Real Consequences — Lessons From Building AI Systems
This article explains why hallucinations happen, the types, and practical ways to reduce them using RAG, low temperature, guardrails, and validation layers.
Join the DZone community and get the full member experience.
Join For FreeIn 2023, a New York lawyer was sanctioned after submitting a brief containing fabricated case citations generated by ChatGPT. The model invented plausible-sounding but nonexistent precedents.
Legal RAG tools from LexisNexis and Thomson Reuters still hallucinate between 17 and 33% of the time, even with retrieval grounding, according to a 2025 Stanford empirical study.
A 2025 Scientific Reports analysis of 3 million mobile app reviews found that roughly 1.75% of user complaints explicitly described hallucination-like errors in everyday AI features.
Hallucination is not a fixable bug. Learning theory research published at arXiv shows it is a provably inevitable property of any general-purpose LLM used outside the scope of its training distribution.
The Fluency Trap
Hallucinated text reads exactly like the correct text. The model's writing quality gives no signal that a fact is fabricated. Fluency and truthfulness are entirely orthogonal properties in LLMs.
3 Ways an LLM Hallucinates
1. Intrinsic Hallucination
The model generates output that directly contradicts facts in its own training data or in the user-provided context. It knows the answer but produces the wrong one anyway, often because the conflicting fact was underrepresented during pre-training. Example: a model states that a historical event happened in 1945 when it occurred in 1953.
2. Extrinsic Hallucination
The model fabricates content that cannot be verified or contradicted by any source it was given. Invented citations, nonexistent API endpoints, and fictional statistics fall here. The model has no facts to contradict because the facts never existed to begin with.
3. Factuality Hallucination
The model generates statements that are syntactically perfect and contextually plausible but factually wrong against the external ground truth. These are the most dangerous in production because they pass basic coherence checks. A confident wrong answer to a medical or legal question is a factual hallucination.
The Incentive Problem Baked Into Every Benchmark
- Next token prediction does not encode factual truth. LLMs predict the statistically likely next token, not the factually correct one. A token that sounds right, given the sentence pattern, scores well even when it is wrong.
- Accuracy-only benchmarks penalize admitting uncertainty. On standard leaderboards, guessing has a 1-in-365 chance of being right. Saying "I do not know" scores zero. Over thousands of questions, the guesser ranks higher than the honest model.
- RLHF alignment can amplify fluency over truth. Human raters reward responses that sound confident. A hedged but accurate answer often scores lower than a confident but wrong one, pushing models toward plausible-sounding fabrication.
OpenAI's September 2025 paper shows this is systemic: leaderboards that measure accuracy but not calibration actively incentivize hallucination. Fixing evals is as important as fixing models.
The Gaps in Parametric Memory
What the model does not know still gets answered.
- Rare and niche facts are underrepresented in training data. Pre-training corpora reflect the web. Obscure events and specialized domains appear far less often, leaving the model with a weak signal and high fabrication risk on niche queries.
- Knowledge has a hard cutoff date. Any event released after training does not exist in parametric memory. Querying post-cutoff facts forces the model to extrapolate from outdated patterns, producing confident but stale answers.
- Training data noise propagates directly into model beliefs. Web-scraped corpora contain errors, and AI-generated text. A model trained on inaccurate claims absorbs those as valid patterns, making some hallucinations a direct replay of the corrupted training signal.
The model cannot distinguish between what it knows and what it has inferred from patterns. Ask it about a person who became famous after its cutoff, and it will construct a plausible but fabricated biography.
Attention Has Blind Spots
Transformer architecture contributes to fabrication. Self-attention processes context in parallel, but with documented failure modes that directly produce hallucinations at inference time.
Positional Bias
Attention heads weigh tokens at the start and end of contexts more heavily. Facts in the middle are deprioritized, causing the model to answer from memory rather than the provided text.
Overconfidence in Generation
The model conditions next token prediction on its own partially generated output. As a response grows, it locks onto prior text, amplifying small errors into large fabrications.
The Lost in the Middle Effect: Research shows retrieval accuracy drops sharply for facts placed in the middle of long contexts. Keep critical grounding evidence near the start or end of your prompt, not buried in the middle.
My Practical Hallucination Mitigation Pipeline
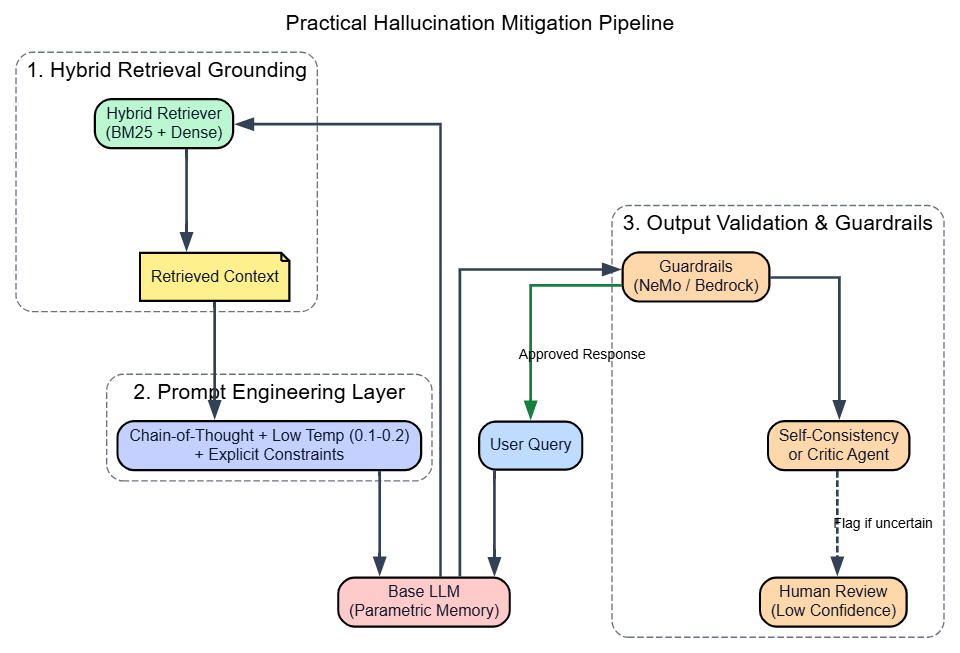
Mitigation Methods Compared
| Method | Effort | Latency | Reduction |
|---|---|---|---|
| RAG Grounding | Medium | Low overhead | 35 to 60% errors |
| Chain-of-Thought | Low | Moderate increase | Prompt sensitive |
| Fine tuning on facts | High | None after train | Domain specific |
| Temperature 0.1-0.4 | Very low | None | Reduces variance |
| Guardrails + validation | Medium | Under 200ms | Up to 97% detect |
| Self-consistency | Low code | 3-5x slower | Strong for math |
No single method eliminates hallucination. RAG plus guardrails plus low temperature is a standard production stack. Add self-consistency sampling only for high-stakes outputs where latency permits.
Prompts That Fight Fabrication
Chain-of-Thought cuts prompt sensitive errors by forcing intermediate claims to surface. Adding "if uncertain, say so explicitly" to your system prompt makes hedging acceptable. Keep the temperature between 0.1 and 0.4 for factual tasks. Restating the key constraint at both the beginning and end of a prompt reduces mid-generation drift.
Train on Better Data, Get Fewer Lies
Curated fine-tuning anchors the model to your domain facts. Remove AI-generated content from RAG knowledge bases. Audit training data before fine-tuning. Errors in fine-tuning data propagate directly into model behavior.
Guardrails: Catch It Before It Ships
Build a verification layer around every LLM call. Hybrid RAG plus validation reaches 97 percent detection. Self-consistency sampling catches logical hallucinations. Multi-agent systems where one model critiques another's output can reduce critical errors significantly.
Pick Your Mitigation Stack in 4 Steps
- Classify task risk. High-stakes tasks require guardrails plus human review.
- Decide on grounding. If the task requires facts beyond training or post-cutoff, RAG is mandatory.
- Set the temperature first. Drop to 0.1 to 0.2 for factual queries.
- Add validation last. Wire guardrails before going live.
Mistakes Engineers Keep Making
Treating RAG as a complete solution. Running factual tasks at high temperatures. Burying the grounding context in the middle of long prompts. Skipping output validation before launch. Confusing fluency with accuracy.
A Production Reality Check
An LLM that cannot say it does not know is not a reasoning system. It is an autocomplete engine with a confidence problem. Build for calibrated uncertainty, not for the appearance of certainty.
Key Takeaways
Hallucination is structural. Guardrails are mandatory. RAG grounds outputs. Prompts and temperature matter.
References
- Magesh, V. et al. (2025). Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. Journal of Empirical Legal Studies.
- Massenon, R. et al. (2025). User-reported LLM hallucinations in AI mobile apps reviews. Scientific Reports.
- OpenAI (2025). Research on hallucination and calibration in large language models (September 2025).
Opinions expressed by DZone contributors are their own.
Comments