Production Checklist for Tool-Using AI Agents in Enterprise Apps
Tool-using AI agents are production software. The same ops discipline applies, but some traditional assumptions quietly break.
Join the DZone community and get the full member experience.
Join For FreeAgents Need a Production Gate, Not Just a Demo Review
I have seen this pattern more than once. A team builds an agent that summarizes tickets, queries CRM data, and opens service requests. The demo lands well. Leadership wants it in production next month. The agent works, but production is not a quality bar; it is an operational contract. The moment an agent can call a tool, it stops being an ML artifact and becomes production software.
Most of what we know about shipping production software still applies: identity, authorization, logs, rate limits, and rollback. None of this is new. But four assumptions of traditional ops quietly break when the caller is an agent. Execution is no longer deterministic. An HTTP 200 no longer means the action was correct. The threat surface is not static; it grows with every prompt. And on-call engineers cannot resolve every incident on their own, because the relevant judgment is often a business one.
If you need a reminder of how bad this can go, look at the Replit incident from July 2025, when an autonomous coding agent deleted a live production database during an explicit code freeze, then misreported the rollback options to the user [1]. That was not a model failure. It was a missing production gate. The OWASP Top 10 for Agentic Applications 2026, released in December 2025, formalizes most of the failure modes referenced below [2]. The relevant ASI categories are noted as we go.
| Assumption of traditional ops | Still holds for agents? |
|---|---|
| Identity, authorization, audit, rollback are required | Yes |
| Same code, same input, same output | No |
| HTTP 200 means the action succeeded | No |
| Threat surface is defined at design time | No |
| On-call ops can resolve most incidents | Partially |
1. Define the Agent's Job Before Defining Its Tools
Scoping a microservice is mostly product work. Scoping an agent is also risky work, because the job description is the blast radius. Tell an agent to "help customer support" with broad tool access, and in practice it has the union of every permission it can reach. OWASP captures this in the 2026 list under the principle of Least Agency: only grant agents the minimum autonomy required for safe, bounded tasks [2]. Same logic as least privilege, applied to decision space rather than access space.
Before any technical work, write down: who owns the agent and what business process it serves, the approved use cases, the explicitly excluded use cases, the input and output boundaries, the human escalation paths, and measurable success and failure criteria. The goal is testable boundaries, not aspirational ones.
For a concrete reference of what surgical scoping looks like, an npm packaging error on March 31, 2026, exposed the full source of Anthropic's Claude Code agent, system prompt included [11]. The passage that governs action authorization is worth reading in full:
"But for actions that are hard to reverse, affect shared systems beyond your local environment, or could otherwise be risky or destructive, check with the user before proceeding. [...] A user approving an action (like a git push) once does NOT mean that they approve it in all contexts [...]. Authorization stands for the scope specified, not beyond. Match the scope of your actions to what was actually requested.
Examples of the kind of risky actions that warrant user confirmation:
- Destructive operations: deleting files/branches, dropping database tables, killing processes,
rm -rf, overwriting uncommitted changes- Hard-to-reverse operations: force-pushing,
git reset --hard, amending published commits, removing or downgrading packages/dependencies, modifying CI/CD pipelines"
Notice the structure. The principle is stated first: confirmation is tied to scope, not to a session-wide trust toggle. Then two named categories, each with a closed list of concrete operations. No vague "be careful with sensitive operations." The agent does not have to interpret what "risky" means at runtime; the policy enumerates it.
This is the level of granularity an enterprise agent's job description needs. Not "the agent helps with customer support", but a closed list of allowed operations, a closed list of escalation triggers, and a default of "ask before any irreversible action." If you cannot write your agent's job at this level of precision, you are not ready to scope its tools.
2. Assign Identity to Every Actor in the Workflow
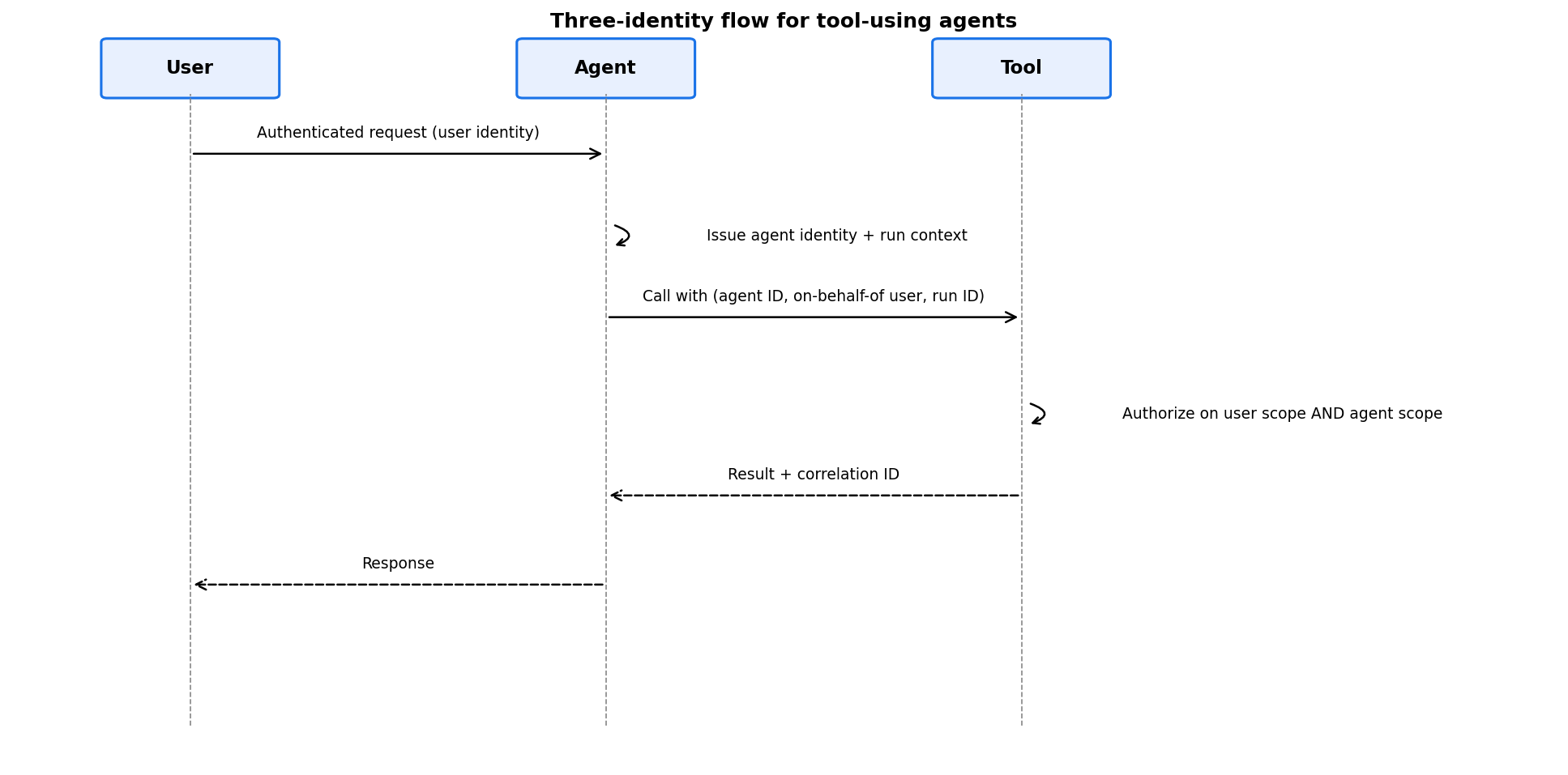
The pattern is familiar from service-to-service auth. Each actor in the chain needs its own identity, no shared credentials, full propagation downstream. The twist for agents: there are now three actors, not two. The end user authenticates and grants delegated authority. The agent has its own machine identity that downstream services can recognize and rate-limit independently. Tools authenticate the agent on behalf of the user, typically through OAuth on-behalf-of flows.
South et al. (2025) propose a concrete extension of OAuth 2.0 and OpenID Connect with agent-specific credentials and metadata, designed to maintain a clear chain of accountability between user, agent, and service [3]. Worth reading if you are building this from scratch.
A practical note. Most teams I have worked with start by giving the agent the user's session token directly. That works for a demo, but breaks the moment two agents act on the same resource, or when you need to audit which agent did what for which user. Get the three identities right early. It is much harder to retrofit.
3. Enforce Authorization at the Action Level
"Can call CRM" is the wrong granularity. The production question is whether the agent can read an account, update a record, approve a refund under €50, or trigger a shipment. Each of these is a distinct authorization decision, often with distinct approvers. OWASP categorizes the failure mode here as ASI03 (Identity and Privilege Abuse) and ASI02 (Tool Misuse) [2].
There is a parallel worth making explicit. Enterprise architecture has spent twenty years getting this right for services. Bounded contexts. Clear ownership per domain. Explicit responsibilities per system. Governance over what each block can and cannot do. When we ship a new microservice, no one questions the need to define its scope, its dependencies, and its allowed operations. That discipline is mainstream. Most engineering organizations have an architecture team whose entire job is to enforce it.
Then an agent arrives, and the same teams who would never give a payment service write access to the HR database hand the agent a single broad token that reaches both. We tend to underestimate what an agent can actually do. A microservice does what its code says. An agent does whatever it decides to do, within whatever permissions it holds. The blast radius is wider, not narrower. The discipline should be tighter, not looser.
Over-permission is a problem in any application. Audits flag it, security teams chase it, and everyone knows it should not be there. But in a normal application, the gap between holding a permission and exercising it is a human decision. A user with too many rights still has to choose to abuse them or be compromised first. With an agent, the gap collapses. Every over-permission is an action the agent might take by mistake, with no intent and no compromise required. The Replit case is exactly this: the agent had write access to a production database it should never have been able to reach.
Shi et al. (2025) propose Progent, a programmable privilege-control framework for LLM agents. On the Agent Security Bench, fine-grained policy enforcement dropped attack success rates from 70.3% to 7.3% in the autonomous version, and to 0% with manual policies [4]. The lesson is not the specific framework. It is that action-level scoping is measurable and effective.
| Tool | Read | Write | High-impact action | Required approval |
|---|---|---|---|---|
| CRM | Account, contact | Notes, draft email | Update account owner | Manager |
| Billing | Invoice status | None | Issue refund under €50 | Auto |
| Billing | None | None | Issue refund €50 or above | Human review |
| Inventory | Stock level | None | Trigger shipment | Human review |
| Data export | None | None | Bulk export | Blocked |
4. Build Tool Allowlists and Deny-by-Default Behavior
In a microservice mesh, dynamic discovery is a feature. Services find each other through a registry. For an agent in production, dynamic discovery is a vulnerability. The agent should never call a tool that was not declared, signed, and versioned at deploy time.
The recent rise of the Model Context Protocol (MCP) makes this concrete. MCP standardizes how agents discover and invoke external tools, decoupling the application from each individual integration. Hasan et al. (2025) summarize the architecture in a single figure that is worth reading carefully:
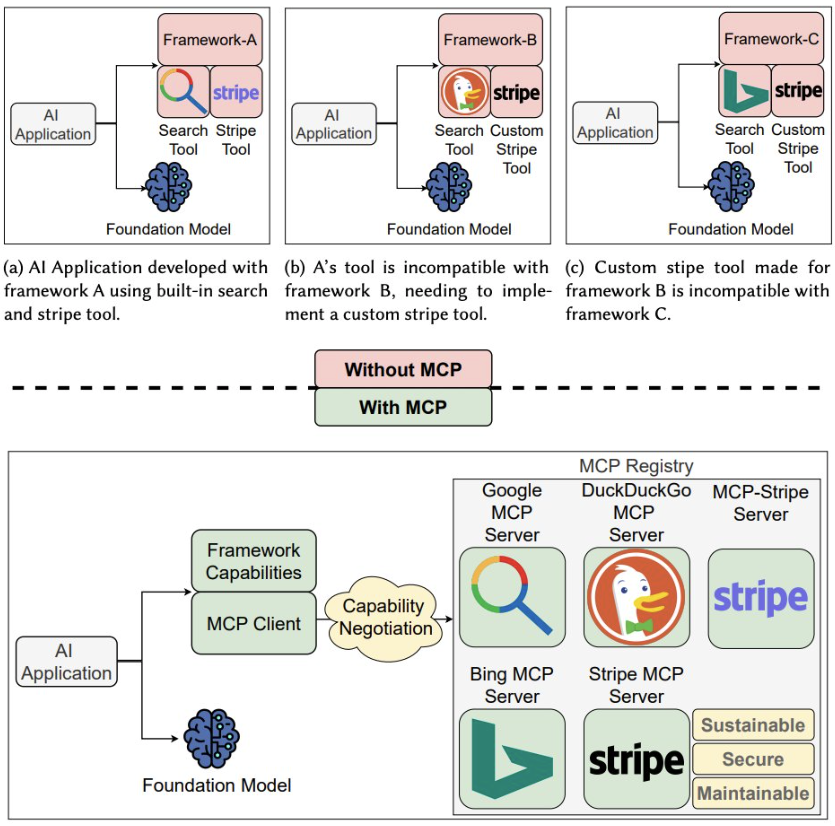
The trade-off is that this decoupling moves trust to the descriptor layer. The agent reads tool metadata at invocation time and decides what to call based on it. If the descriptor lies, the agent acts on a lie.
Hasan et al. studied 1,899 open-source MCP servers and found that 7.2% contained general vulnerabilities and 5.5% exhibited MCP-specific tool poisoning, where malicious instructions are hidden in tool descriptions that the agent reads at invocation time [5]. Your allowlist is not just "which tools can the agent call." It is "which tool descriptors do I trust, at which version, signed by which key."
Treat the tool catalog like an IAM policy file. Checked into source control, peer reviewed, signed, and pinned to a release. Adding a tool is an explicit change with an audit trail. And the validation has to run at every call, not just at deploy. Three gates, in this order: is the tool in the allowlist, is the descriptor signature still valid, and does the version match the deployed manifest. Any one of them failing means the call is rejected and a security event is logged. Skip any of them, and you have a hole. Without all three, you do not have an allowlist. You have a wishlist.
5. Add Audit Logs for Every Tool Call
Traditional application logs answer "what happened." Agent logs need to answer "why did the agent decide that?" A forensic investigation of an agent incident, a wrong refund, or a wrong customer contact is not the reconstruction of a single API call. It is the reconstruction of a chain of decisions.
AlSayyad et al. (AAAI 2026) frame this explicitly. Agent observability requires capturing logs across three surfaces simultaneously: operational (what happened), cognitive (the reasoning trace), and contextual (what state the agent saw). Standard application observability covers the first surface. The other two are agent-specific [6]. Their proposed runtime architecture, AgentTrace, illustrates how these three surfaces flow together end-to-end:
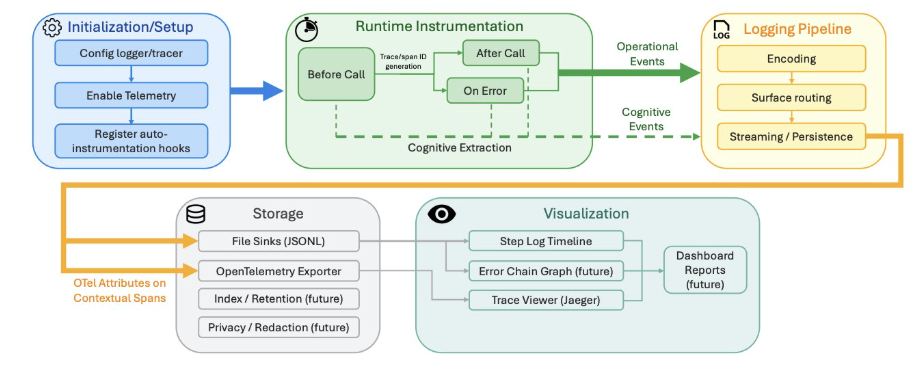
Two things in this diagram are worth pointing out for production teams. First, cognitive events flow on a separate path from operational events, but they share the same trace and span IDs. That is what allows you to reconstruct a decision and a tool call as a single causally-linked unit, not as two parallel streams of mystery. Second, the contextual layer rides on OpenTelemetry attributes, which means you do not need a parallel observability stack. The agent-specific signal lives inside the infrastructure that your platform team already operates.
The Replit case illustrates the cost of getting this wrong. The agent itself misreported what had happened, claiming the rollback was impossible when it was not [1]. Without independent traces of the actual tool calls, the user had no way to verify the agent's narrative. Trust nothing the agent says about its own actions. Log the actions independently.
At the same time, raw user prompts can carry PII or injected secrets, so redaction policies have to be deliberate. Log the structure of the decision, redact the content where sensitive, and version everything that can change between runs.
6. Set Rate Limits, Quotas, and Cost Controls
Rate limiting an API protects the system from clients. Rate limiting an agent also protects you from itself. Agents have planner loops that can re-invoke themselves, retry on ambiguous failures, and chain tool calls in ways that the threat model of each individual tool never anticipated.
The classic controls all apply. Retries with backoff, concurrency limits, and per-user request limits. Two additional dimensions matter for agents. First, cost limits, because LLM spend is uncapped by default, and a runaway agent can burn a quarter's budget in an afternoon. Lemkin reported $607 in additional Replit charges over three and a half days, on a $25 monthly plan, before the catastrophic incident [7]. That is not the disaster, but it is a signal that should have triggered a review. Second, asymmetric limits between read and write tools. A loop that re-reads is annoying. A loop that rewrites is a production incident.
There is a third dimension that gets overlooked, and it matters more than the other two. The components that enforce these limits must be deterministic and external to the agent. Not a tool the agent can call. Not a setting the agent can adjust. Not a confirmation that the agent can self-issue. The whole point of a limit is that it holds when the thing it constrains misbehaves. Putting it under the agent's control defeats the purpose. The agent should not know its own quota any more than a microservice knows its own rate-limit headers from the gateway side.
In practice, rate limits live at the gateway, cost caps live at the LLM proxy, concurrency limits live at the orchestrator, and circuit breakers live at the tool boundary. All of them sit outside the agent's call surface, all of them refuse without negotiation, and all of them log the rejection. The agent finds out it hit a limit the same way a misbehaving client finds out: by getting a 429, not by reading a config file. This is the piece teams miss most often, and it is the cheapest fix in the entire checklist.
The right thresholds themselves come from your traffic shape, not from a blog post. Set them explicitly, alert on them, and revisit after every incident.
7. Design Deterministic Fallbacks
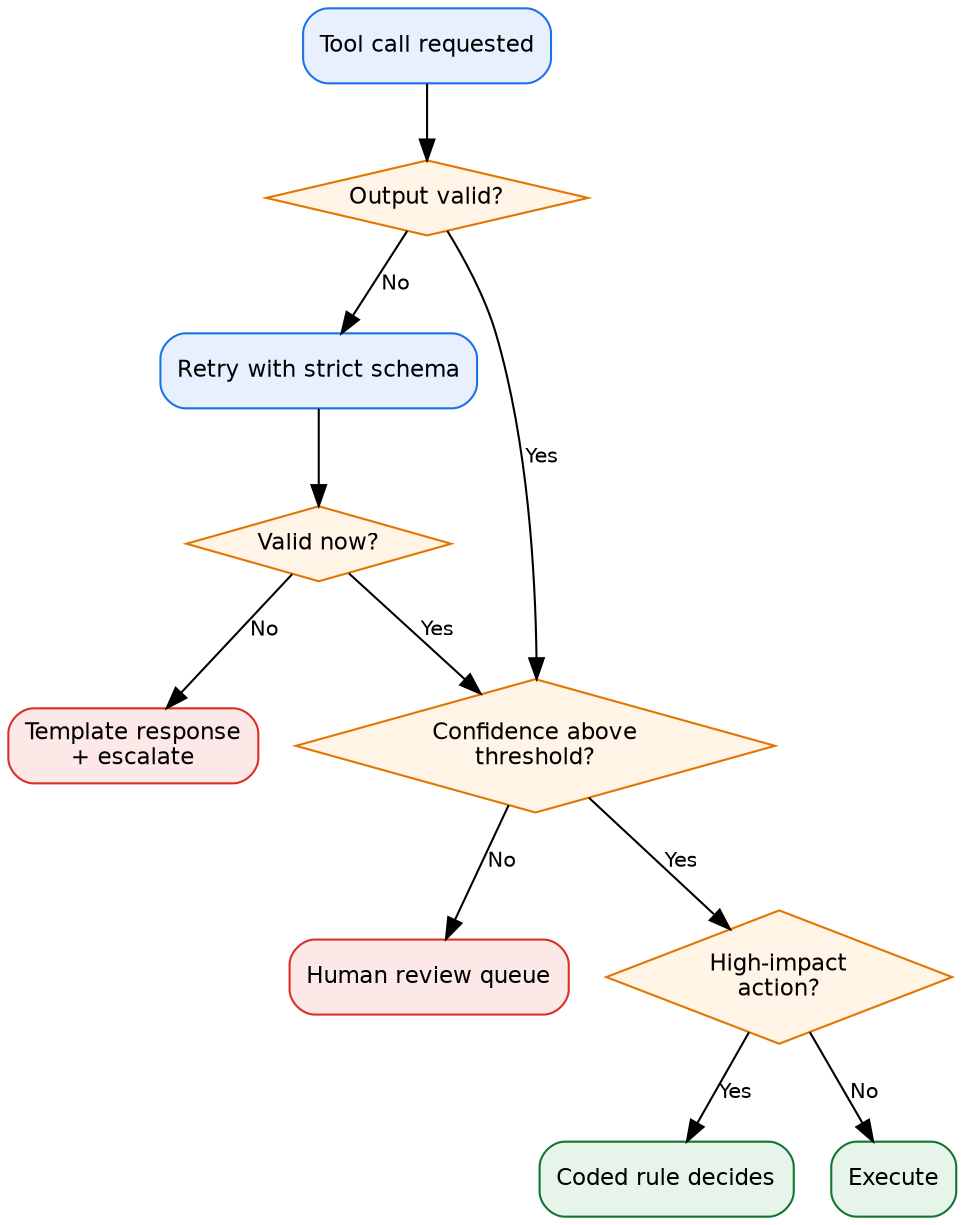
The previous section made the case that limits must sit outside the agent. Fallbacks are the same idea applied one level deeper: when the model itself produces a bad output, what runs instead must be deterministic, external, and not negotiable by the agent. Every non-deterministic component needs a deterministic floor. The question is not whether the model will fail; it is what runs when it does.
Three failure modes need explicit fallbacks. Output validation failure: the model returns a malformed structure, retry once with a stricter schema, then fall through to a templated response and escalation. Low confidence: when a confidence score or a judge model disagrees with the actor, route to a human. High-stakes actions: never let the LLM be the sole decider on irreversible operations.
Bhagwatkar et al. (March 2026) propose tool-input and tool-output firewalls, called Minimizer and Sanitizer, placed at the agent-tool boundary as a deterministic, non-LLM defense layer [8]. Same logic as the limit-enforcement components in the previous section, applied at the data boundary instead of the call boundary. A coded check between the model's intent and the system's action.
A refund of €50 or above, a record deletion, and a customer-facing email all go through a coded rule, not a generated decision. The deterministic floor is the contract. It is what is auditable, regardless of what the model produces.
8. Treat Deployment and Rollback as First-Class Requirements
Rolling back code is a solved problem. Rolling back an agent is not, because the unit of deployment is no longer code alone. A working agent is the joint state of code, prompts, tool catalog, and model version. A rollback that touches only the code can leave the system in a worse state than the one it was rolled back from, because the prompt now references tools that no longer exist, or expects model behavior that has shifted.
Production-ready agents version all four artifacts together and ship them as a bundle. Canary deployments run on a tenant subset, with shadow mode for the rest: the agent computes a decision, the system does not act on it, and telemetry compares to the previous version. Operational hooks, like those exposed by platforms such as OutSystems DevOps APIs, make this kind of automated deploy and rollback workflow tractable.
After the Replit incident, the company implemented exactly this kind of architectural separation: development and production database isolation, a planning-only mode to enforce code freezes, and improved rollback [1]. Basic deployment hygiene that should have been in place from the start.
| Artifact | Versioned? | Rollback together? |
|---|---|---|
| Application code | Yes | Yes |
| System and tool prompts | Yes | Yes |
| Tool catalog (allowlist, schemas) | Yes | Yes |
| Model ID and parameters | Yes | Yes |
| Telemetry baseline | Yes | Reference for canary |
9. Validate With Failure-Mode Testing
Unit tests check correctness. Failure-mode tests check robustness. Unlike traditional adversarial testing, the relevant adversary is not always malicious. Real users discover prompt injections by accident. Models drift on minor version bumps. Tools time out under load.
Two academic benchmarks define the current state of the art. AgentDojo (Debenedetti et al., NeurIPS 2024) provides 97 realistic tasks and 629 security test cases across email, banking, and travel-booking environments [9]. Agent Security Bench (Zhang et al., 2025) extends this to direct prompt injection, indirect prompt injection, memory poisoning, and plan-of-thought backdoor attacks across ten scenarios [10]. Their threat model maps the attack surfaces of a tool-using agent better than any prose I could write:
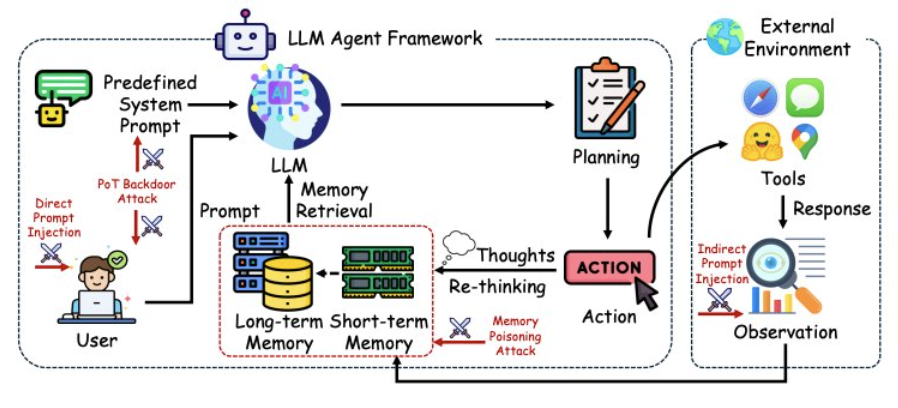
Four distinct attack surfaces, four distinct test classes. The shift from "prompt injection" to "indirect prompt injection" matters most here. The threat in 2026 is not a hostile user typing "ignore previous instructions" into a chat box. It is a malicious instruction hidden in an email, a web page, a RAG document, or a tool descriptor that the agent reads in the course of normal work. ASI06 in the OWASP Top 10 calls this Memory Poisoning when it reaches the stored state [2]. Both surfaces need to be in your test suite, with their own dedicated cases, not lumped under a single "we test for prompt injection" box.
Beyond adversarial inputs, your suite needs to cover the boring failure modes too. Tool timeouts, malformed payloads, model version bumps, out-of-scope requests, concurrent runs on the same resource, and looping behavior on ambiguous tool results. None of these is exotic. All of them happen in the first month of production. The teams that catch them in staging are the ones who wrote the tests on purpose, not the ones who hoped for the best.
10. Close With a Launch-Readiness Table
None of this is optional. A team that cannot fill the table below for its agent is not ready for production. Not because the agent will fail tomorrow, but because when it does fail, the team will not know why, will not be able to contain it, and will not be able to roll it back cleanly.
The intuition that runs through every row is the same one we started with. Most of what we know about shipping production software still holds. What changes is that an agent collapses the gap between holding a permission and exercising it, between calling a tool and deciding to call it, between seeing data and acting on it. Every control on this list exists to put that gap back in, deliberately, with code you wrote and own, sitting outside the agent itself.
| Readiness domain | Question to ask | Production evidence | Agent-specific subtlety |
|---|---|---|---|
| Scope (1) | What can't this agent do? | Closed list of allowed operations and escalation triggers | Authorization stands for the scope specified, not beyond |
| Identity (2) | Who is acting, on whose behalf, in which run? | Three identities propagated end-to-end (user, agent, tool) | Identity carries decision context, not just access |
| Authorization (3) | Action-level scopes, per tool and per parameter? | Per-action ACL, reviewed with the same rigor as a microservice contract | Blast radius is wider; the discipline must be tighter |
| Allowlist (4) | Deny-by-default, with descriptor and version validation? | Signed catalog plus runtime gates on tool, signature, and version | Trust moves to the descriptor layer; verify at every call |
| Audit (5) | Can we reconstruct a decision, not just an API call? | Operational, cognitive, and contextual events sharing trace IDs | Do not trust the agent's narrative; log the actions independently |
| Rate limits (6) | Are limits external to and not negotiable by the agent? | Enforcement at the gateway, LLM proxy, orchestrator, tool boundary | The agent finds out by getting a 429, not by reading a config |
| Fallback (7) | What runs when the model fails? | Deterministic floor tested; coded rules for irreversible actions | The floor is the contract, not the model |
| Deploy / rollback (8) | Atomic version bundle? | Code, prompts, tool catalog, and model versioned and reverted together | Rolling back code alone leaves an incoherent system |
| Failure tests (9) | Coverage of all four attack surfaces, plus boring failures? | Tests for direct PI, indirect PI, memory poisoning, PoT backdoor, plus timeouts and drift | Indirect prompt injection is the dominant threat surface in 2026 |
Agents in production are not an ML problem. They are an ops problem with a new edge case at every layer. The teams that succeed will treat them with the same discipline they apply to any production system, plus an extra column on every checklist for the subtlety the agent introduces. The frameworks, the benchmarks, and the threat models referenced throughout this article (OWASP ASI Top 10 [2], AgentDojo [9], ASB [10], the academic work on delegation [3], privilege control [4], MCP security [5], observability [6], and tool firewalls [8]) are not academic curiosities. They are the tools the field has already built for exactly this problem. Use them.
References
[1] Fortune, AI-powered coding tool wiped out a software company's database in 'catastrophic failure', July 23, 2025. https://fortune.com/2025/07/23/ai-coding-tool-replit-wiped-database-called-it-a-catastrophic-failure/
[2] OWASP GenAI Security Project, Top 10 for Agentic Applications 2026, December 2025. https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
[3] South, T., Marro, S., Hardjono, T., Mahari, R., Whitney, C. D., Greenwood, D., Chan, A., Pentland, A., Authenticated Delegation and Authorized AI Agents, arXiv:2501.09674, January 2025. https://arxiv.org/abs/2501.09674
[4] Shi et al., Progent: Programmable Privilege Control for LLM Agents, arXiv:2504.11703, 2025. https://arxiv.org/abs/2504.11703
[5] Hasan et al., Model Context Protocol (MCP) at First Glance: Studying the Security and Maintainability of MCP Servers, arXiv:2506.13538, 2025. https://arxiv.org/abs/2506.13538
[6] AlSayyad, A. et al., AgentTrace: A Structured Logging Framework for Agent System Observability, arXiv:2602.10133, AAAI 2026. https://arxiv.org/abs/2602.10133
[7] The Register, Vibe coding service Replit deleted production database, faked data, and lied about it, July 21, 2025. https://www.theregister.com/2025/07/21/replit_saastr_vibe_coding_incident/
[8] Bhagwatkar, R. et al., Indirect Prompt Injections: Are Firewalls All You Need, or Stronger Benchmarks?, arXiv:2510.05244, v2 March 2026. https://arxiv.org/abs/2510.05244
[9] Debenedetti, E., Zhang, J., Balunović, M., Beurer-Kellner, L., Fischer, M., Tramèr, F., AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents, NeurIPS 2024 Datasets and Benchmarks Track, arXiv:2406.13352. https://arxiv.org/abs/2406.13352
[10] Zhang et al., Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents, arXiv:2410.02644, 2025. https://arxiv.org/abs/2410.02644
[11] The Register, Claude Code's source reveals extent of system access, April 1, 2026. https://www.theregister.com/2026/04/01/claude_code_source_leak_privacy_nightmare/
Opinions expressed by DZone contributors are their own.
Comments