Architecting Trustworthy AI: Engineering Patterns for High-Stakes Environments
This post presents three domain-agnostic engineering patterns for building AI systems that remain safe even when the model is wrong.
Join the DZone community and get the full member experience.
Join For FreeSoftware engineers are great at talking about how to make things dependable: we have names for things like circuit breakers, bulkheads, making sure something can be done multiple times with the same result (idempotency), and making sure a system will fall apart in a manageable way (graceful degradation). We're good at building systems to fail safely if a database isn't working or a dependent service is taking too long.
However, we don't have a comparable, well-defined way of discussing systems that fail in a way that is likely to be wrong, and where the kind of failure isn't a network going down, but a prediction that is confidently, but incorrectly, given to you. And what’s more, it’s up to a person to find that mistake, and that person might not even be looking.
That gap is the engineering problem this article addresses.
Drawing on a production sociotechnical framework for AI-enabled platforms operating in high-stakes environments, the patterns below are directly applicable to any system where incorrect outputs carry significant consequences - financial services, legal tech, autonomous systems, or safety-critical infrastructure. The specific domain is illustrative; the engineering is universal.
Why Probabilistic Systems Need a Different Reliability Model
Traditional, predictable systems fail loudly. A null pointer exception, a 500 error, something that should always be true not being true, these are all visible, can be recorded, and can be caught by the usual ways we keep an eye on things.
Probabilistic AI models fail silently. They confidently continue to generate outputs even when they are outside their training distribution. They don't raise exceptions when the data distribution shifts. They don't emit warnings when their predictions get worse. They just start making mistakes at a large scale, invisibly.
This leads to three failure cases that deterministic patterns don't cover:
- Distribution shift – The statistical characteristics of the input data change over time. A model trained on a certain type of data or property will, without warning, use what it has learned on a completely different set of data. The model's confidence scores remain unchanged.
- Reasoning drift in agentic pipelines – In multi-step AI workflows, errors at step N are used as the ground truth for step N+1. Long-horizon agentic tasks have been shown to result in over 20-30% difference in output across a multi-step pipeline, even when the individual steps work. This is the AI version of a cascading failure in a distributed system - but more challenging to identify because there is no "system failure" or no failure of a "single component".
- Automation bias as a system property – When AI systems start off by performing well, human supervisors progressively relax their level of oversight. This is not a weakness; it's a predictable natural system behavior. This is to say that when AI does fail, human overseers are temporarily blind to the failure because of their own prior trust.
The engineering challenge is to build systems that remain safe even when any of the above three failure modes are active.
Pattern 1: The Safety Shell
The Safety Shell is the most critical architectural pattern for high-stakes AI applications. It's a deterministic, rule-based layer that wraps the probabilistic model and enforces invariants the model cannot guarantee on its own. One can think of this as the Microsoft Gatekeeper Pattern, applied specifically to ML inference.
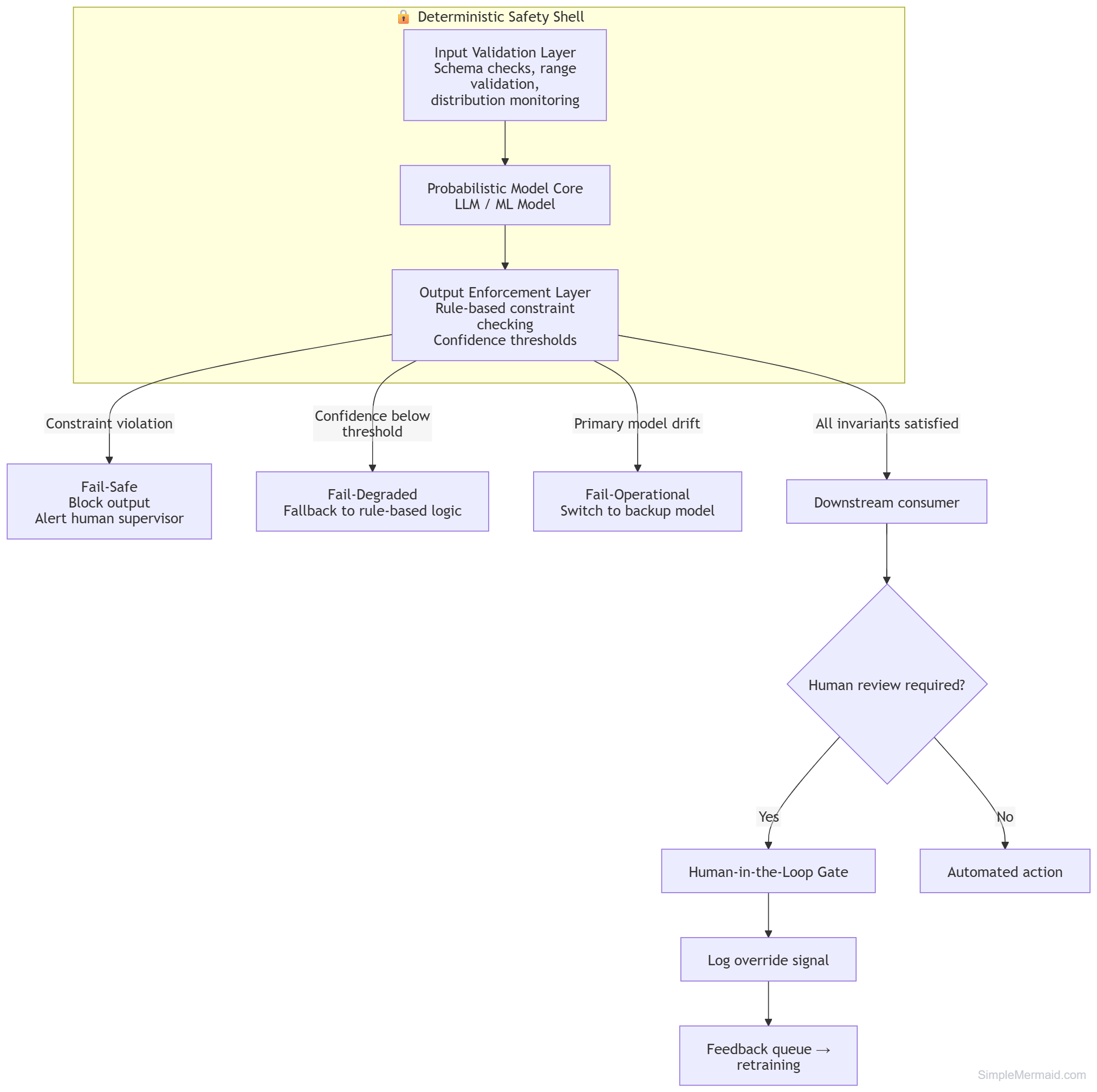
The three fail modes map directly to the circuit breaker pattern:
from enum import Enum
class FailMode(Enum):
SAFE = "block_and_alert"
DEGRADED = "rule_based_fallback"
OPERATIONAL = "switch_to_backup"
class SafetyShell:
def __init__(self, model, backup_model, rule_engine, drift_monitor):
self.model = model
self.backup_model = backup_model
self.rule_engine = rule_engine
self.drift_monitor = drift_monitor
def evaluate(self, input_data):
# Layer 1: Input validation — check schema and distribution
if not self.rule_engine.is_in_distribution(input_data):
self.drift_monitor.record(input_data)
return {"mode": FailMode.DEGRADED, "output": self.rule_engine.fallback(input_data)}
# Layer 2: Probabilistic model inference
output = self.model.predict(input_data)
# Layer 3: Hard constraint enforcement (deterministic)
violation = self.rule_engine.check_constraints(output)
if violation:
return {"mode": FailMode.SAFE, "output": None, "alert": f"Constraint violated: {violation}"}
# Layer 4: Confidence threshold
if output.confidence < 0.70:
return {"mode": FailMode.DEGRADED, "output": self.rule_engine.fallback(input_data)}
# Layer 5: Drift-triggered failover
if self.drift_monitor.is_drifting(self.model):
return {"mode": FailMode.OPERATIONAL, "output": self.backup_model.predict(input_data)}
return {"mode": None, "output": output} # All clearThe key insight is that the model does not know when it's wrong. The shell does. These are fundamentally different capabilities.
Pattern 2: Uncertainty Quantification via Conformal Prediction
The typical output of an AI system is a single scalar — a probability, a score, a classification label. Such confidence scores (e.g., "87% sure") are often poorly calibrated. This is an engineering tradeoff that leads to a reliability issue: it masks uncertainty in the model with a precise-looking number. High-stakes systems need to output uncertainty as a primary output, not a derived metric.
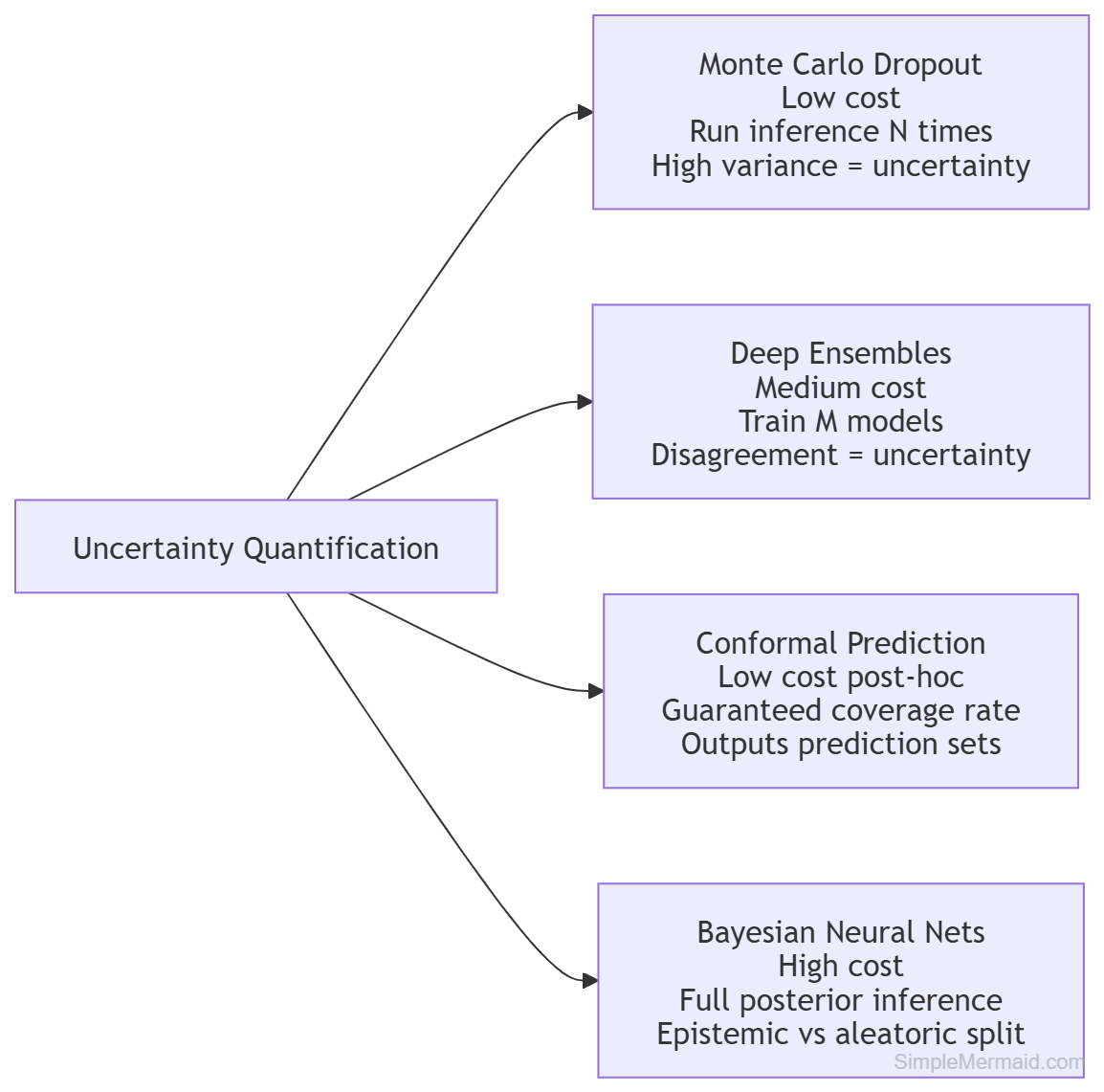
Conformal prediction is particularly noteworthy because it's efficient and provides coverage guarantees for its predictions, which no traditional ML model provides. Rather than "class A (87% confidence)", a conformal predictor returns a set: {"class A", "class B"} with a guaranteed error rate of ≤5% across the test distribution. This is more valuable for systems with human reviewers, as it leaves the reviewer to know what the model cannot reliably decide between, rather than making a binary decision.
from nonconformist.cp import IcpClassifier
from nonconformist.nc import ClassifierNc, MarginErrFunc
# Initialize with a 95% confidence requirement
nc = ClassifierNc(base_model, MarginErrFunc())
icp = IcpClassifier(nc)
icp.calibrate(X_cal, y_cal)
# Returns plausible classes rather than a single 'best guess'
prediction_sets = icp.predict(X_test, significance=0.05)Pattern 3: Multi-Agent Quality Control
With the emergence of multi-agent pipelines in AI systems, a new pattern of reliability emerges: multi-agent quality control. The design does not assume the output of one agent to be the truth for the next agent: it explicitly allocates some agents to audit other agents.
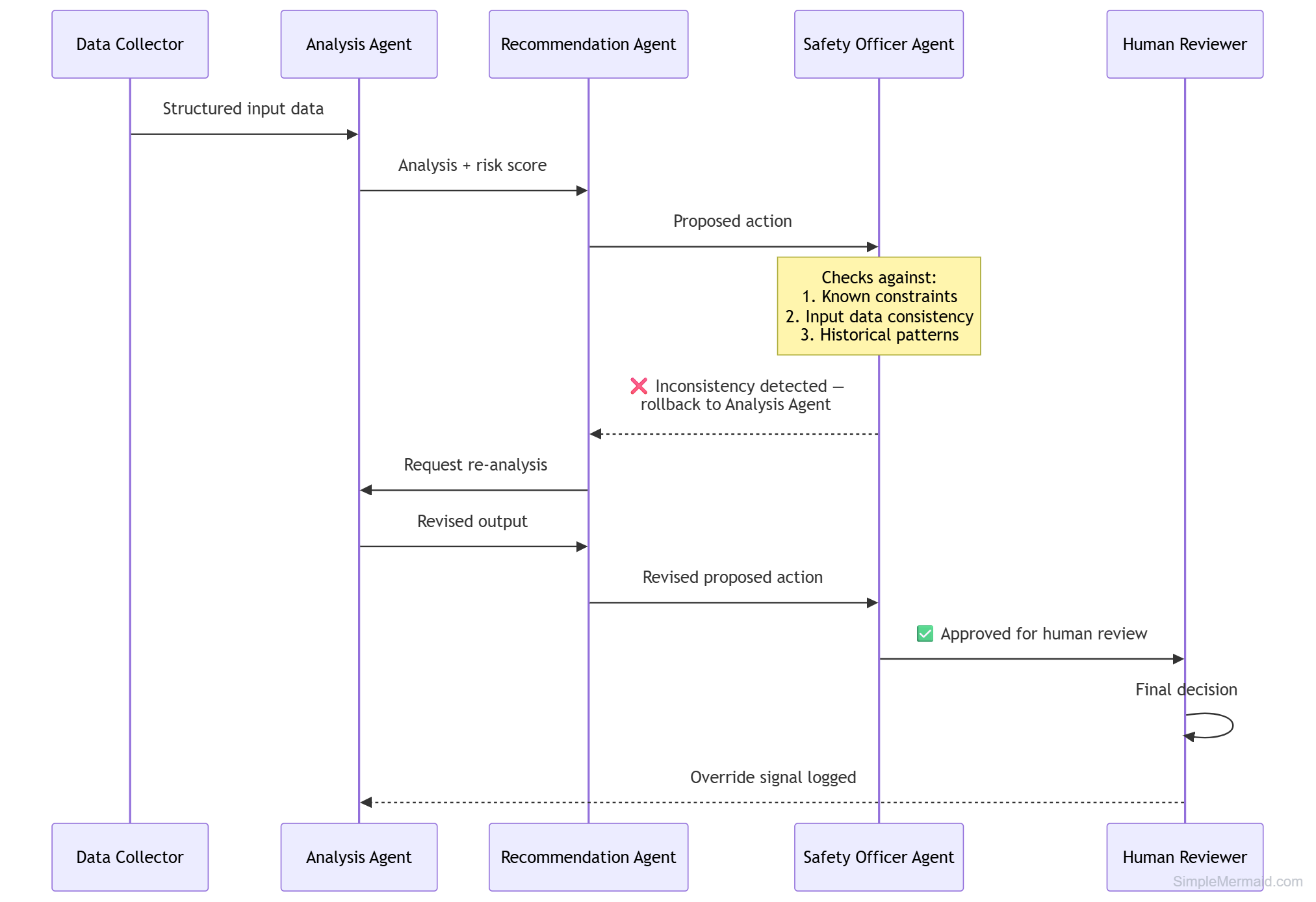
This pattern prevents single-point failures from propagating through the pipeline and creates explicit audit trails at every agent boundary.
Prevention by design: The most reliable agentic systems don't just leave it up to the Safety Officer agent to catch every error; they restrict the capabilities of the other agents. Narrow the action space. Limit the damage. Let the Safety Officer deal with edge cases, not core invariants.
Patterns in Action: A Case Study
It's easier to grasp abstract patterns when they're applied. Take a smart power grid load balancer with an AI controller:
- A sensor fault is rated negative energy consumption, which is physically impossible.
- In the absence of a Safety Shell, the model attempts to correct the anomaly by surging power to one of the transformers.
- Pattern 1 becomes active: The input validation layer identifies the out-of-distribution reading; the constraint engine identifies the negative consumption value as a physical invariant violation ->
FailMode.SAFEtriggers, prevents the output, and signals the human operator. - Pattern 2 context: The ambiguity of the model was high on this input — a conformal predictor would have encountered the ambiguity even prior to the Safety Shell's firing, giving the operator an earlier warning signal.
- Pattern 3 occurs: The Safety Officer agent records the inter-agent disagreement, including the exact model version, sensor snapshot, and constraint that fired, giving the ops team a complete reconstruction trail with no human investigation. Since the system is running under a phased autonomy (10% human audit mode), the blocked action routes to a human operator to verify, who rightly says no to the surge command.
- The override signal is fed back into the retraining queue, and a sensor recalibration ticket is automatically created.
The same sequence would unfold identically whether the domain was a power grid, a fraud-detecting engine, or an autonomous vehicle routing system. The patterns are domain-independent; the definition of constraints is modified.
This is also the reason why phased autonomy is used to provide a documented track record that governance stakeholders and regulators must be able to view before granting further autonomy - the audit trail is not just to be debugged with, but the evidence of safe operation.
Measuring Reliability Beyond Accuracy
High-stakes AI production monitoring should measure these metrics in addition to the traditional model performance:
|
Metric |
What It Catches |
Implementation |
|---|---|---|
|
Feature distribution drift |
Silent failure from data changes |
KL-divergence or PSI on rolling windows |
|
Override rate |
Automation trust gap |
Log every human-AI disagreement event |
|
Expected Calibration Error (ECE) |
Overconfident wrong predictions |
Reliability diagrams on production data |
|
Latency p99 |
Dangerous delays in time-sensitive contexts |
Standard APM tooling |
|
Constraint violation rate |
Safety Shell effectiveness |
Event counter in M2M audit log |
|
Inter-agent disagreement rate |
Multi-agent pipeline health |
Logged at Safety Officer agent boundary |
The override rate deserves special attention: this is the direct outcome of behavioral trust. When operators consistently reject AI outputs, the system is providing no value regardless of accuracy. Transparent and well-calibrated production systems are likely to have an override rate of ~15%; systems in which the output is opaque are likely to have an override rate of ~74%. Monitor this number on a weekly basis.
The Reliability Maturity Model
Use this to assess where your system sits and what to build next:
|
Level |
Label |
Characteristics |
Implementation Focus |
|---|---|---|---|
|
1 |
Naive |
No monitoring. Vendor explanations accepted at face value. Incidents drive all improvements. |
Establish baseline logging |
|
2 |
Guarded |
Safety Shell active. Output constraints enforced. Fails safely on violations. Accuracy dashboards live. |
Implement Pattern 1 + drift alerts |
|
3 |
Sociotechnical |
FAME framework active. Backup models. HITL feedback loops. M2M audit trail. Phased autonomy rollout. |
Implement Patterns 2-3 |
|
4 |
Verifiable |
Formal verification of safety properties. Continuous adversarial testing. System improves automatically from human overrides. |
Add formal methods + red-teaming |
The majority of the production AI systems sit at Level 1 or 2. To reach Level 2 — the minimum possible safety posture in high-stakes settings — it is necessary to introduce the Safety Shell and specify the concrete fail modes. That work is scoped and can be accomplished without retraining the underlying model.
The Pre-Ship Engineering Checklist
Before deploying to a high-stakes AI system:
- Safety Shell implemented with fail-safe, fail-degraded, and fail-operational modes defined and tested.
- Uncertainty measured, quantified, and brought to downstream consumers (conformal prediction or ensemble disagreement)
- M2M audit logging captures all inter-agent interactions with data version, model version, and constraint check results.
- Feature distribution monitoring notifies prior to accuracy deterioration rather than after.
- Documented phased autonomy plan with override rate thresholds and automated rollback triggers that are defined in advance.
- Override rate instrumented and monitored as a primary reliability measure (target: <15% to get high-confidence results)
- Expected Calibration Error (ECE) Calculated on Production data, not only on test sets.
- Rollback procedures tested and documented prior to go-live, not following an incident.
Conclusion
Opinions expressed by DZone contributors are their own.
Comments