Who Owns the Data Stack?: How AI Is Reshaping Ownership, Architecture, and Accountability Across Teams
Build AI-native data systems with clear ownership, semantic contracts, and governance. Learn how accountability, retrieval, and data quality shape AI behavior.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2026 Trend Report, Cognitive Databases, Intelligent Data: Unified Infrastructure for Vector Search, AI-Optimized Queries, and Hybrid Workloads.
For years, some of us have argued that the data stack is part of the product and should be engineered like the application layer: as code and as a service. The market matured toward it, and the data mesh has been the clearest recent expression.
AI has eclipsed those debates and settled the matter. The data stack is now product-facing, shaping what users see, what AI answers, and which automated decisions and workflows fire. That makes one question unavoidable: When an answer depends on data across many systems and teams, who is accountable for accuracy?
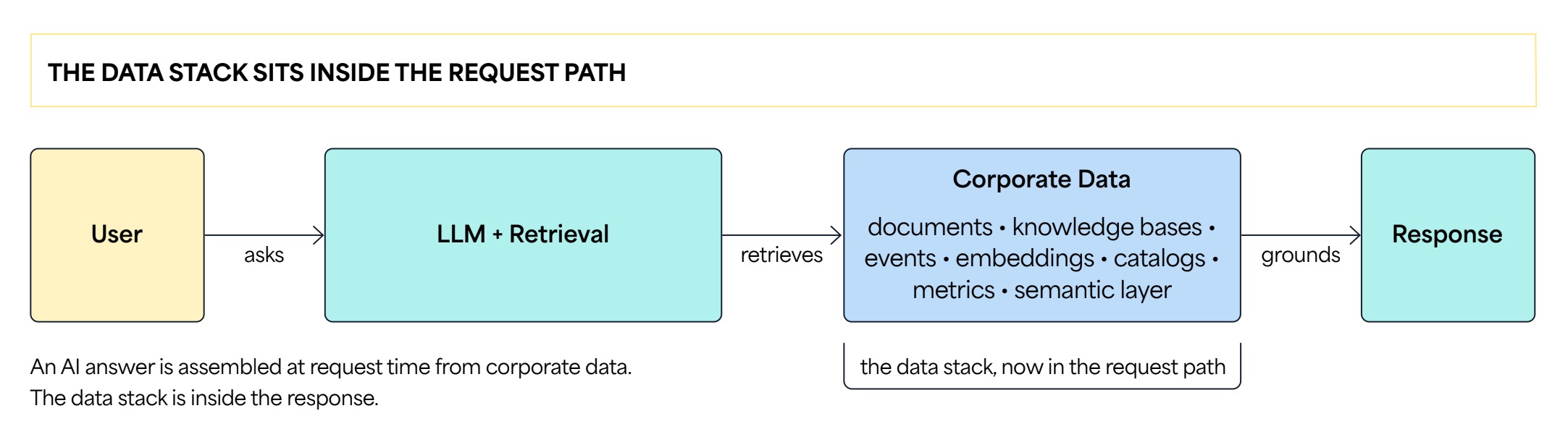
An AI answer is assembled at request time from corporate data. The data stack is inside the response.
AI Turns Data Infrastructure Into Product Behavior
AI makes the data stack part of product behavior, but raw infrastructure should not leak into the product. The goal is to abstract the stack behind durable, governed interfaces. An AI feature should consume meaning, relationships, permissions, and context.
Following data mesh and data contracts, the API layer has to evolve from returning data to exposing capabilities. A consumer, including an AI model, should depend on a contract that carries:
- Metadata – origin, lineage, meaning
- Quality – freshness, completeness, confidence
- Relationships – how entities compose and traverse
- Security – authorization applied consistently across operational, analytical, and vector stores
When meaning lives in the contract, infrastructure becomes interchangeable, and a misbehaving AI feature is no longer an opaque failure — it’s a question with an owner.
Where Ownership Breaks First
Ownership does not break at the edges of systems but much earlier, in how the organization is designed. Most technology organizations still distribute teams around components and technical specialization: applications, databases, pipelines, governance, indexing, and analytics. Each team owns its layer, though no one owns the end-to-end meaning of the data.
That worked when data only fed analytics. It fails in AI-native products, where data is product behavior, and the two lifecycles are inseparable. AI composes its behavior across every layer at once, inheriting each inconsistency in semantics, freshness, permissions, and relationships.
So this is not a handoff problem; it is a Conway’s Law problem. Architecture mirrors the organization, and AI makes the organizational seams visible to the user. Platform teams remain essential for shared abstractions, governance primitives, and standards. But product teams need to own both their features and APIs and their data end to end: its lifecycle, meaning, quality, and governance.
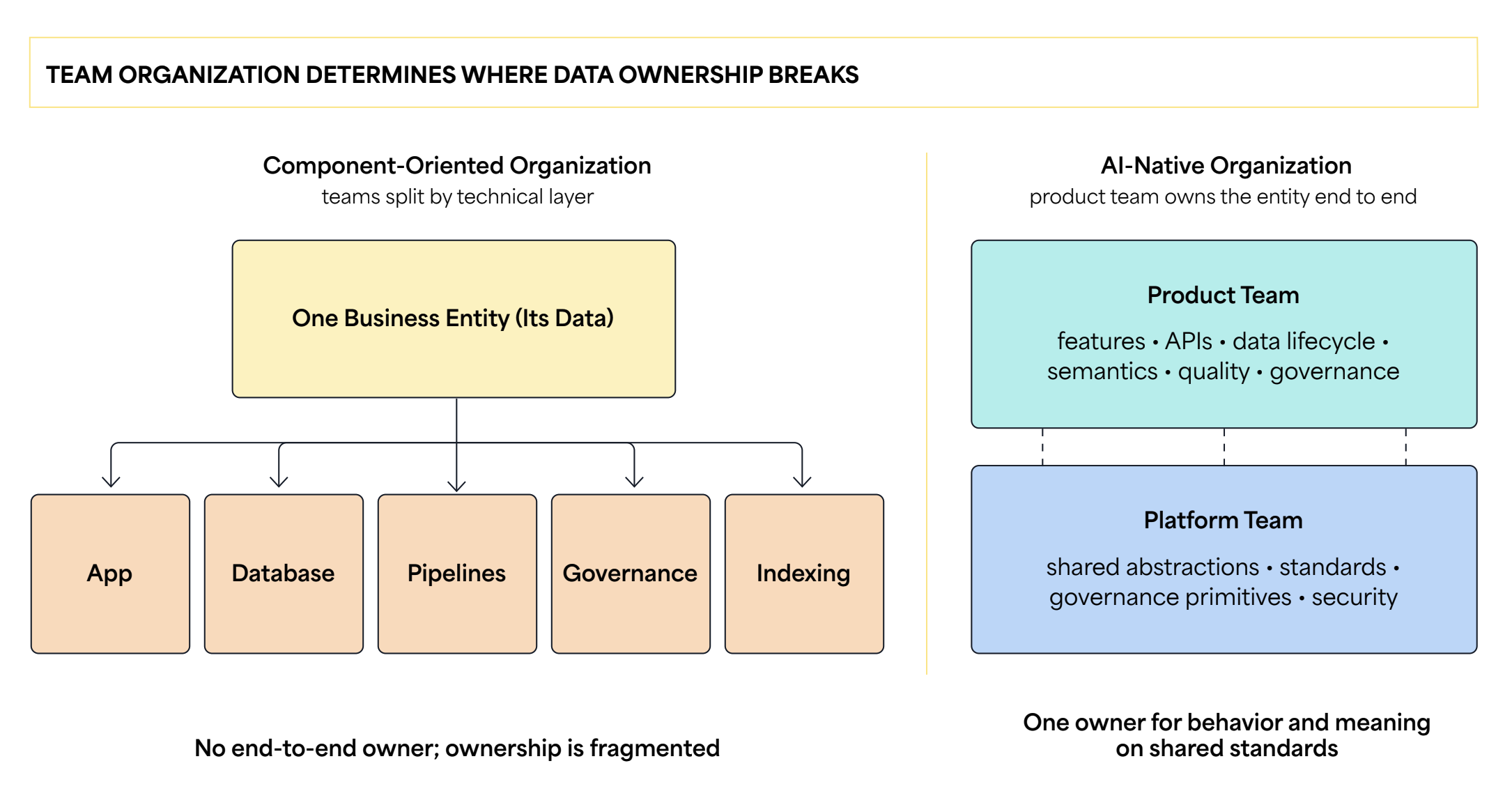
Splitting teams by technical layer scatters one business entity across many disconnected owners, and AI inherits that fragmentation. AI-native organizations give product teams end-to-end ownership of the data, with platform teams providing shared standards.
Accountability Follows Product Behavior
When data only fed dashboards, accountability could stay narrow: Did the pipeline run, and did the report match? AI moves that boundary. Once retrieval, copilots, and agents start making decisions and generating answers from data, a correct pipeline, a healthy index, and a valid access policy still don’t guarantee a correct user-facing result.
Accountability can’t be pinned to technical layers. It has to follow the behavior the user experiences. The product team that owns an AI capability is responsible for the end-to-end correctness, freshness, explainability, and safety of the data behind it. Its job is to own the contract that defines what the AI may know and retrieve.
Platform teams provide the standardized primitives that make this accountability structure possible: semantic contracts, lineage, quality signals, access enforcement, observability, and governance-aware retrieval.
The question shifts from “which team owns this layer?” to “which product team owns this behavior, and which platform capabilities guarantee it?” In AI-native systems, accountability rests with the team that owns the behavior, not the system that happened to fail.
Table: Accountability Differences Between the Layer-by-Layer and AI-Native Models
| area | layer-by-layer | ai-native |
|---|---|---|
| Source of truth | Each system decides locally | The product team owns the authoritative semantic contract |
| Quality | The data team checks pipelines | The product team owns user-facing correctness; the platform provides quality signals |
| Retrieval | The platform team owns indexes as infrastructure | A governed product capability with explicit SLOs |
| Access | The security team owns policies separately | Enforced consistently across product, data, and AI layers |
| Incidents | Routed to whichever layer failed | The product team leads; the platform, data, and security teams support as capability owners |
Architecture Choices Are Also Operating Model Choices
Architecture decisions also decide how an organization governs and evolves meaning. AI-native systems raise the stakes here because copilots and agents consume meaning — entities, relationships, metrics, and permissions — rather than tables. Semantic consistency becomes part of how the product behaves.
No central team can own the meaning of every domain, so meaning has to live close to the domain that owns the capability. But decentralization alone backfires: Without platform-enforced standards, the old central bottleneck just turns into semantic fragmentation, with every domain exposing its own definitions and contracts. The fix is to split ownership cleanly:
- Domains own the meaning
- Platform teams own the contracts that keep it consistent
Underneath, storage and processing keep churning. What actually lasts is whether stable abstractions (e.g., “employee,” “payroll,” “entitlement”) survive above them. The principle is simple: Infrastructure should be replaceable, and meaning should not. So the real operating-model choice comes down to who owns meaning, and who keeps it consistent.
Shared Data Contracts Make Accountability Concrete
If organizational fragmentation is the root problem, contracts make ownership explicit. A classic data contract is necessary but insufficient. Schema validation catches a renamed column, but it misses semantic drift, stale meaning, or a changed business definition. Those failures don’t break a build. They break behavior.
The contract has to grow from schema into semantics, carrying meaning, lineage, quality, and authorization. Crucially, it abstracts the capability and meaning a domain exposes, not the storage format underneath, so it behaves the same whether the source is a table, a document, an event, or an embedding. That makes the data contract both a producer-to-consumer check and a runtime semantic interface that retrieval, copilots, and agents all consume.
Its real value is relocating accountability to the source so drift surfaces in the producing domain while context stays local, which accelerates interoperability rather than centralizing control.
Governance Has to Travel With the Data
Traditional governance sat beside the data in the form of periodic reviews, approvals, and access checks. AI breaks that model. Data now moves continuously through pipelines, caches, embeddings, indexes, and agents, recomposed at runtime faster than any review can observe. Governance must be part of the execution model itself.
Governance travels with meaning, not storage. An embedding holds no raw rows yet reveals sensitive meaning, so policy must follow the semantic classification. The gap is sharpest in authorization. Identity systems stop at the API boundary, and AI doesn’t preserve security boundaries on its own, which turns every embedding, cache, and retrieval step into a new one to defend.
Governance therefore becomes a runtime capability that decides what AI may retrieve, infer, expose, and act on. Solving that calls for composable, declarative governance primitives embedded in the platform so auditability becomes a property of the system rather than the outcome of a project.
Accountability Gaps That Slow AI Data Work
The real cost of fragmented accountability is the constant drag on every data-powered capability. Friction is never neutral, so when teams can’t trust the platform’s freshness, semantics, or governance, they route around it and build their own, resulting in shadow pipelines, local indexes, and duplicated transformations.
Each workaround makes sense locally even as it corrodes the whole, fragmenting governance and eroding trust in the very platform it was meant to replace. And piling on more central control only hides the problem — the fragmentation just migrates into those shadow systems.
So the deeper gap was missing platform contracts.
What Clear Ownership Looks
Instead of adding more teams on more layers, clear ownership means aligning accountability with the single product experience the user meets. What you’re really investing in is the stable semantic abstractions that outlast whatever infrastructure comes and goes. And the hardest problem is how to make the organization understandable to its own AI systems.
Additional resources:
- DAMA-DMBOK: Data Management Body of Knowledge
- DAMA International – foundational guidance on data ownership, stewardship, and governance roles
- Open Data Contract Standard (ODCS) – an open spec for declaring schema, semantics, quality, and service levels between data producers and consumers
- OpenLineage – an open standard for collecting data lineage across pipelines and services, useful for tracing what AI features consume
- NIST AI Risk Management Framework (AI RMF) – a vendor-neutral framework for accountability and governance of AI systems
- Coral – exposes diverse data sources to agents through one declared SQL and semantic layer; an example of meaning being owned per source rather than centrally
- Getting Started With Data Quality, DZone Refcard by Miguel García Lorenzo
- Data Pipeline Essentials, DZone Refcard by Sudip Sengupta
- Open-Source Data Management Practices and Patterns, DZone Refcard by Abhishek Gupta
- Real-Time Data Architecture Patterns, DZone Refcard by Miguel García Lorenzo
- “Building Trusted, Performant, and Scalable Databases: A Practitioner’s Checklist” by Saurabh Dashora
This is an excerpt from DZone’s 2026 Trend Report, Cognitive Databases, Intelligent Data: Unified Infrastructure for Vector Search, AI-Optimized Queries, and Hybrid Workloads.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments