Considered one of the most crucial components of modern data-driven applications, a data pipeline automates the extraction, correlation, and analysis of data for seamless decision making. When building a data pipeline that is production-ready, consistent, and reproducible, there are plenty of factors to consider that make it a highly technical affair. This section explores the key considerations, components, and options available when building a data pipeline in production.
Components of a Data Pipeline
The data pipeline relies on a combination of tools and methodologies to enable efficient extraction and transformation of data.
Figure 1: Common components of a data pipeline
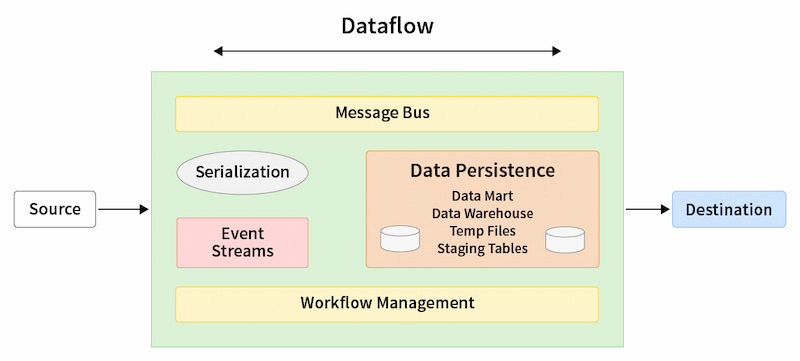
Event Frameworks
Event processing encompasses analysis and decision making based on the data streamed continuously from applications. These systems extract information from data points that respond to tasks performed by users or various application services. Any identifiable task or process that causes a change in the system is marked as an event, which is recorded in an event log for processing and analysis.
Message Bus
A message bus is the combination of a messaging infrastructure and a data model that receives and queues the data sent between different systems. Leveraging an asynchronous messaging mechanism, applications use a message bus to instantaneously exchange data between systems without having to wait for an acknowledgement. A well-architected message bus also allows disparate systems to communicate using their own protocols without worrying about system inaccessibility, errors, or conflicts.
Data Persistence
Persisting data refers to the ability of an application to store and retrieve information so that it can be processed in batches. Data persistence can be achieved in several ways, such as by storing it on the block, object, or file storage devices that ensure data is durable and resilient in the event of system failure. Data persistence also includes back-up drives that provide readily available replicas for automatic recovery when a server crashes. The data persistence layer creates the foundation for unifying multiple data sources and destinations into a single pipeline.
Workflow Management
In data pipelines, a workflow comprises a set of tasks with directional dependencies. These tasks filter, transform, and move data across systems, often triggering events. Workflow management tools like Apache Airflow structure these tasks within the pipeline, making it easier to automate, supervise, and manage tasks.
Serialization Frameworks
Serialization tools convert data objects into byte streams that can easily be stored, processed, or transmitted. Most firms operate with multiple data pipelines built using different approaches and technologies. Data serialization frameworks define storage formats that make it easy to identify and access relevant data, then write it to another location.
Key Considerations
In this section, we review factors to consider when building and deploying a modern data pipeline.
Self-Managed vs. Unified Data Orchestration Platform
Organizations can choose whether to leverage third-party enterprise services or self-managed orchestration frameworks for deploying data pipelines. The traditional approach is to build in-house data pipelines that require provisioning infrastructure in a self-managed, private data center setup. This offers various benefits, including flexible customization and complete control over data handling. However, self-managed orchestration frameworks rely on a number of various tools and niche skills. Such platforms are also considered less flexible for handling pipelines that require constant scaling or high availability.
On the other hand, unified data orchestration platforms are supported by the right tools and skills that offer higher computing power and replication that enables organizations to scale quickly while maintaining minimum latency.
Online Transaction Processing vs. Online Analytical Processing
Online transaction processing (OLTP) and online analytical processing (OLAP) are the two primary data processing mechanisms. An OLTP system captures, stores, and processes user transactions in real time, where every transaction is made up of individual records consisting of multiple fields and columns.
An OLAP system relies on large amounts of historical data to perform high-speed, multidimensional analysis. This data typically comes from a combination of sources, including OLTP databases, data marts, data warehouses, or any other centralized data store. OLAP systems are considered ideal for business intelligence, data mining, and other use cases that require complicated analytical calculations.
Query Options
These are a set of query string parameters that help to fine-tune the order and amount of data a service will return for objects identified by the Uniform Resource Identifier (URI). These options essentially define a set of data transformations that are to be applied before returning the result, and they can be applied to any task except the DELETE operation. Some commonly used query options include:
Filter enables the client to exclude a collection of resources addressed by the URI.Expand specifies a list of resources related to the data stream that will be included in the response.Select allows the client to request a specific set of properties for each resource type.OrderBy sorts resources in a specified order.
Data Processing Options
There are two primary approaches to cleaning, enriching, and transforming data before integration into the pipeline: ETL and ELT. In ETL (extract, transform, load), data is first transformed in the staging server before it is loaded to the destination storage or data warehouse. ETL is easier to implement and is suited for on-premises data pipelines running mostly structured, relational data.
On the other hand, in ELT (extract, load, transform), data is loaded directly into the destination system before processing or transformation. When compared to ETL, ELT is more flexible and scalable, making it suitable for both structured and unstructured cloud workloads.
