An Architecturally-Evident Coding Style
Join the DZone community and get the full member experience.
Join For Freeokay, this is the separate blog post that i referred to in software architecture vs code . what exactly do we mean by an "architecturally-evident coding style"? i built a simple content aggregator for the local tech community here in jersey called techtribes.je , which is basically made up of a web server, a couple of databases and a standalone java application that is responsible for actually aggegrating the content displayed on the website. you can read a little more about the software architecture at techtribes.je - containers . the following diagram is a zoom-in of the standalone content updater application, showing how it's been decomposed.
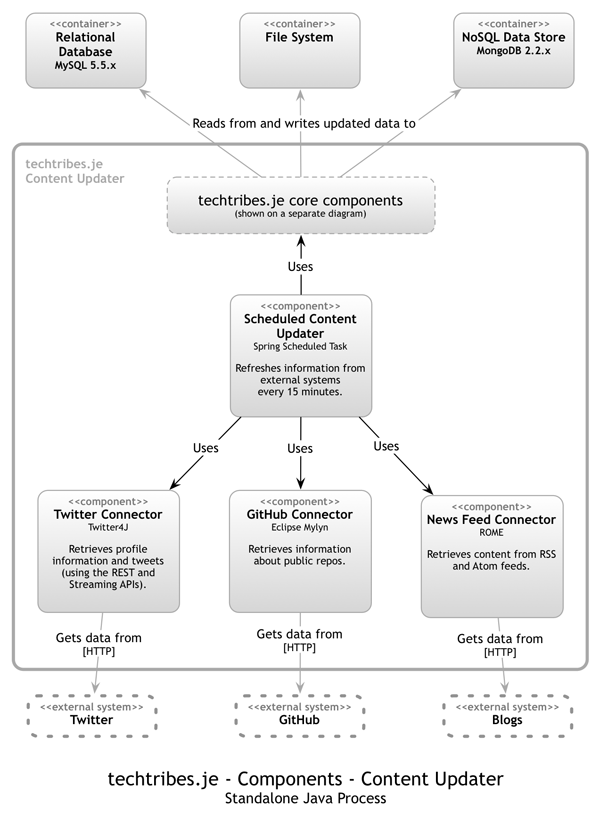
this diagram says that the content updater application is made up of a number of core components (which are shown on a separate diagram for brevity) and an additional four components - a scheduled content updater, a twitter connector, a github connector and a news feed connector. this diagram shows a really nice, simple architecture view of how my standalone content updater application has been decomposed into a small number of components. "component" is a hugely overloaded term in the software development industry, but essentially all i'm referring to is a collection of related behaviour sitting behind a nice clean interface.
back to the "architecturally-evident coding style" and the basic premise is that the code should reflect the architecture. in other words, if i look at the code, i should be able to clearly identify each of the components that i've shown on the diagram. since the code for techtribes.je is open source and on github, you can go and take a look for yourself as to whether this is the case. and it is ... there's a je.techtribes.component package that contains sub-packages for each of the components shown on the diagram. from a technical perspective, each of these are simply spring beans with a public interface and a package-protected implementation. that's it; the code reflects the architecture as illustrated on the diagram.
so what about those core components then? well, here's a diagram showing those.

again, this diagram shows a nice simple decomposition of the core of my techtribes.je system into coarse-grained components. and again, browsing the source code will reveal the same one-to-one mapping between boxes on the diagram and packages in the code. this requires conscious effort to do but i like the simple and explicit nature of the relationship between the architecture and the code.
when architecture and code don't match
the interesting part of this story is that while i'd always viewed my system as a collection of "components", the code didn't actually look like that. to take an example, there's a tweet component on the core components diagram, which basically provides crud access to tweets in a mongodb database. the diagram suggests that it's a single black box component, but my initial implementation was very different. the following diagram illustrates why.
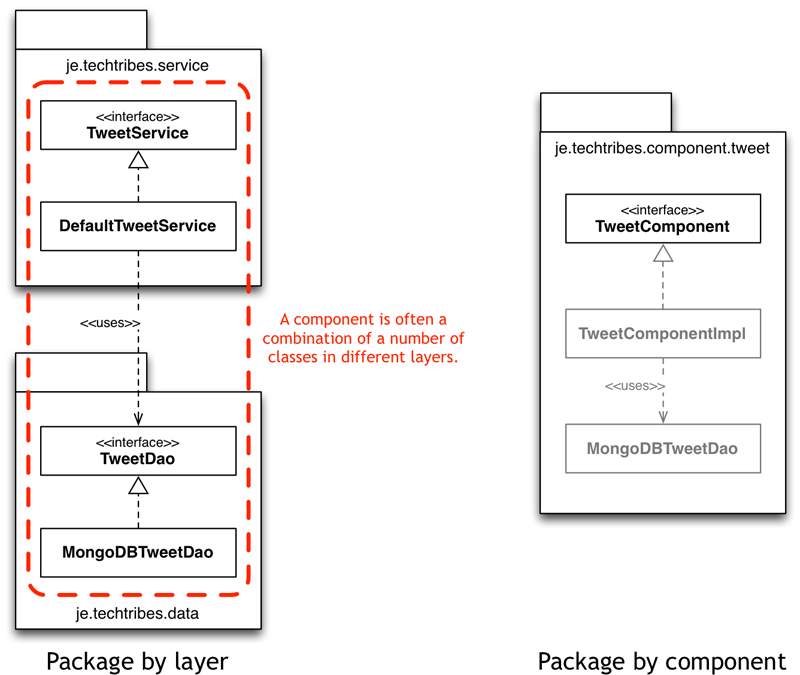
my initial implementation of the tweet component looked like the picture on the left - i'd taken a "package by layer" approach and broken my tweet component down into a separate service and data access object. this is your stereotypical layered architecture that many (most?) books and tutorials present as a way to build (e.g.) web applications. it's also pretty much how i've built most software in the past too and i'm sure you've seen the same, especially in systems that use a dependency injection framework where we create a bunch of things in layers and wire them all together. layered architectures have a number of benefits but they aren't a silver bullet .
this is a great example of where the code doesn't quite reflect the architecture - the tweet component is a single box on an architecture diagram but implemented as a collection of classes across a layered architecture when you look at the code. imagine having a large, complex codebase where the architecture diagrams tell a different story from the code. the easy way to fix this is to simply redraw the core components diagram to show that it's really a layered architecture made up of services collaborating with data access objects. the result is a much more complex diagram but it also feels like that diagram is starting to show too much detail.
the other option is to change the code to match my architectural vision. and that's what i did. i reorganised the code to be packaged by component rather than packaged by layer. in essence, i merged the services and data access objects together into a single package so that i was left with a public interface and a package protected implementation. here's the tweet component on github .
but what about...
again, there's a clean simple mapping from the diagram into the code and the code cleanly reflects the architecture. it does raise a number of interesting questions though.
- why aren't you using a layered architecture?
- where did the tweetdao interface go?
- how do you mock out your dao implementation to do unit testing?
- what happens if i want to call the dao directly?
- what happens if you want to change the way that you store tweets?
layers are now an implementation detail
this is still a layered architecture, it's just that the layers are now a component implementation detail rather than being first-class architectural building blocks. and that's nice, because i can think about my components as being my architecturally significant structural elements and it's these building blocks that are defined in my dependency injection framework. something i often see in layered architectures is code bypassing a services layer to directly access a dao or repository. these sort of shortcuts are exactly why layered architectures often become corrupted and turn into big balls of mud. in my codebase, if any consumer wants access to tweets, they are forced to use the tweet component in its entirety because the dao is an internal implementation detail. and because i have layers inside my component, i can still switch out my tweet data storage from mongodb to something else. that change is still isolated.
component testing vs unit testing
ah, unit testing. bundling up my tweet service and dao into a single component makes the resulting tweet component harder to unit test because everything is package protected. sure, it's not impossible to provide a mock implementation of the mongodbtweetdao but i need to jump through some hoops. the other approach is to simply not do unit testing and instead test my tweet component through its public interface. dhh recently published a blog post called test-induced design damage and i agree with the overall message; perhaps we are breaking up our systems unnecessarily just in order to unit test them. there's very little to be gained from unit testing the various sub-parts of my tweet component in isolation, so in this case i've opted to do automated component testing instead where i test the component as a black-box through its component interface. mongodb is lightweight and fast, with the resulting component tests running acceptably quick for me, even on my ageing macbook air. i'm not saying that you should never unit test code in isolation, and indeed there are some situations where component testing isn't feasible. for example, if you're using asynchronous and/or third party services, you probably do want to ability to provide a mock implementation for unit testing. the point is that we shouldn't blindly create designs where everything can be mocked out and unit tested in isolation.
food for thought
the purpose of this blog post was to provide some more detail around how to ensure that code reflects architecture and to illustrate an approach to do this. i like the structure imposed by forcing my codebase to reflect the architecture. it requires some discipline and thinking about how to neatly carve-up the responsibilities across the codebase, but i think the effort is rewarded. it's also a nice stepping stone towards micro-services. my techtribes.je system is constructed from a number of in-process components that i treat as my architectural building blocks. the thinking behind creating a micro-services architecture is essentially the same, albeit the components (services) are running out-of-process. this isn't a silver bullet by any means, but i hope it's provided some food for thought around designing software and structuring a codebase with an architecturally-evident coding style.
Published at DZone with permission of Simon Brown. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments