ASP.NET Web Forms Modernization Series (Part 1): Data Access Layer Considerations
This is the first post in this series dedicated to ASP.NET Web Forms modernization and today, we will discuss data access layer considerations.
Join the DZone community and get the full member experience.
Join For FreeThis is part 1 in a series of blog posts dedicated to ASP.NET Web Forms modernization. The series expands on the topics discussed in the Migration Guide: ASP.NET Web Forms to Modern ASP.NET – a compilation of technical considerations for modernizing legacy .NET web applications, gathered from our experience doing many .NET modernization projects.
Here is a list of all articles in the ASP.NET Web Forms modernization series:
- Part 1 – Data Access Layer Considerations (you are here!)
Coming up next (stick around!):
- Part 2 – Business Logic Layer Considerations
- Part 3 – UI Layer Considerations
- Part 4 – Single Page Application Framework Considerations
- Part 5 – Server Application Considerations
- Part 6 – Testing, Deployment, and Operational Considerations
Introduction
Your business application is as good as your data. The impact any software system has on the business is directly proportional to the quality, structure, and meaning of the data it gathers and organizes. That’s why we are cautious when it comes to data in a software modernization project. The data layer in any system is the stable foundation on which the application evolves. And no matter how rapidly you change frameworks, technologies, and components, the data layer is the single piece in your system you must touch carefully.
Preserve and Reuse Your Data
Modernizing the typical legacy Web Forms application brings many considerations across the application stack – how do I transform my back-end to modern .NET, how do I design and create the API efficiently, what type of front-end technology should I use? Preserving the fundamental capability of your application (and thus its positive value), however, essentially means you must continue providing the ability to access, process, and analyze data the same way as before.
Any slight change or missing feature in the data capabilities of the new system you design and your shiny new application is already less valuable to your users than the one they’re currently using. That’s the opposite of successful software modernization. You don’t want that.

When talking about software modernization, everybody sees the project as an opportunity to do better, to fix old problems, eliminate existing limitations, and create a top-notch system design that would make any software architect proud. Naturally, technical leaders start having heated conversations about switching to better relational database technologies, going from a relational to a document-based database, or drastically changing the database schema to support that all-time requested feature that we could not deliver before due to the limitations in the current schema.
At my company, we’re very cautious about the topic of data when designing a modern .NET application to replace a legacy. Our main objective – is data preservation and reuse. All existing data sources, data structure, and operations must be available in the new system; all critical system capabilities related to data query and manipulation – preserved. We have repeatedly seen that being conservative with changes at the data level is the best approach for meeting existing system capabilities efficiently. Improvements to data (schema and operations) can only come if the new system provides all data capabilities the legacy one does.
Understanding Data Preservation
The easiest way to think about data preservation is to ask, “Can the new system run independently on old data and provide all data operations the legacy one does?” If you can swap the old system with the new one overnight, and the user can continue with their business in the morning right where they left off – you have achieved data preservation and reuse. You preserved all the data without loss, enabling the same data operations as before. Your users are not worse off having switched to your modern application. Your system meets the table stakes requirements.
As technologists, we realize there could be many ways to skin this cat. You could rewrite your entire database schema, change to a different RDBMS system, or rearchitect your data access code entirely and still provide data compatibility with your legacy system. We often do this early in greenfield software development projects – we experiment with different database technologies and data flow architectures and change them as necessary. However, in a software modernization project, time and cost efficiency are primary objectives for the overall project. Most often than not, going the long and costly route of a complete data re-architecture is not an option.
As system architects and software consultants, we understand that the development time required to get to the baseline system capabilities (those already provided by your legacy system) does not add business value on its own. It’s the improvements, new features, and better experiences on top of the legacy system that we’re after in software modernization. The quicker we can release those, the higher the project’s overall value to the business. And preserving and reusing data is low-hanging fruit.
Make Entity Framework Your Friend
Data access technology in Microsoft .NET has evolved significantly in the last decade. What started as ADO – a set of data classes for working with MS Access data – evolved into ADO.NET – a unified data access framework for all kinds of SQL and XML data. Nowadays, Entity Framework – a modern, lightweight object-relational mapper for .NET – is the industry standard approach for working with SQL-based data. It is well supported in all recent versions of the .NET Framework and Modern .NET (.NET 6 at the time of writing) and provides multiple approaches for mapping your data – starting schema-first or code-first.
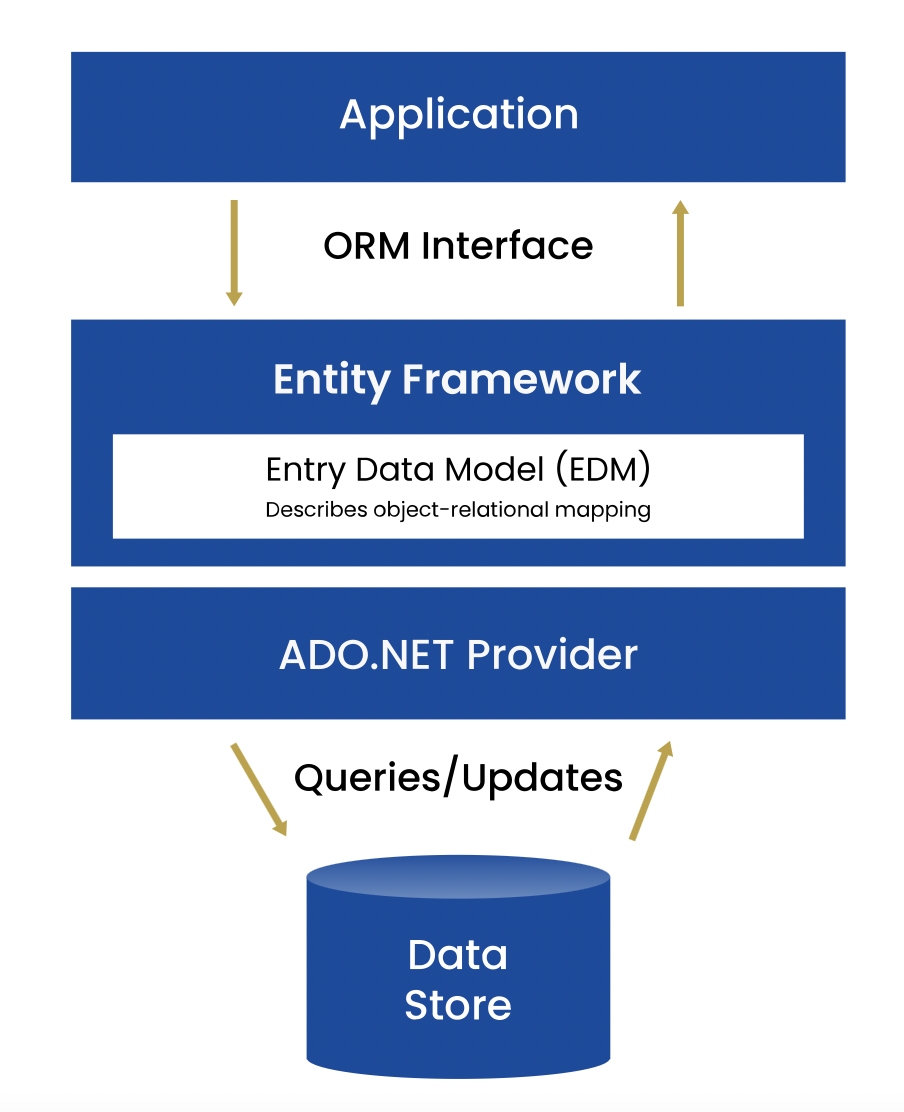
Almost all modern .NET application architectures we create at Resolute build on Entity Framework for relational database access. It provides a convenient object-oriented abstraction over relational data, good coding patterns (database contexts and data collections), enables flexible data loading mechanisms (eager, lazy, and explicit loading), and connects to a multitude of relational databases, including the most popular open-source databases – MySQL and PostgreSQL, as well as non-Microsoft, enterprise-grade RDBMS systems like Oracle and IBM Db2.
Entity Framework has been around for quite a while, certainly going back to the heyday of ASP.NET Web Forms. Suppose you’re modernizing a legacy Web Forms application that is already based on Entity Framework. In that case, you’re ahead of the modernization game because you can take a migration path from EF6 (.NET Framework-compatible) to EF Core (modern .NET-compatible). Similarly, if your in-app data is based on LINQ to SQL – a data mapping and query technology similar to and succeeded by Entity Framework – you can migrate to Entity Framework Core relatively easily using the database-first approach. Migration enables entity code and database schema reuse and is a fast track to bringing your data access layer to modern .NET.
Segregate Data Access Code in Entities and Services
A well-designed software system is layered – it has a data layer (that stores and retrieves information), a logic layer (that implements your domain-specific business logic), and a presentation layer (for interacting with the user). Each layer has a set of clearly defined responsibilities, provided by a well-defined public interface used by the layer above. The concept of an N-Tier Architecture has been written, repeated, discussed, and beaten to death for decades. It continues to be one of the most essential architectural requirements in modern software systems.
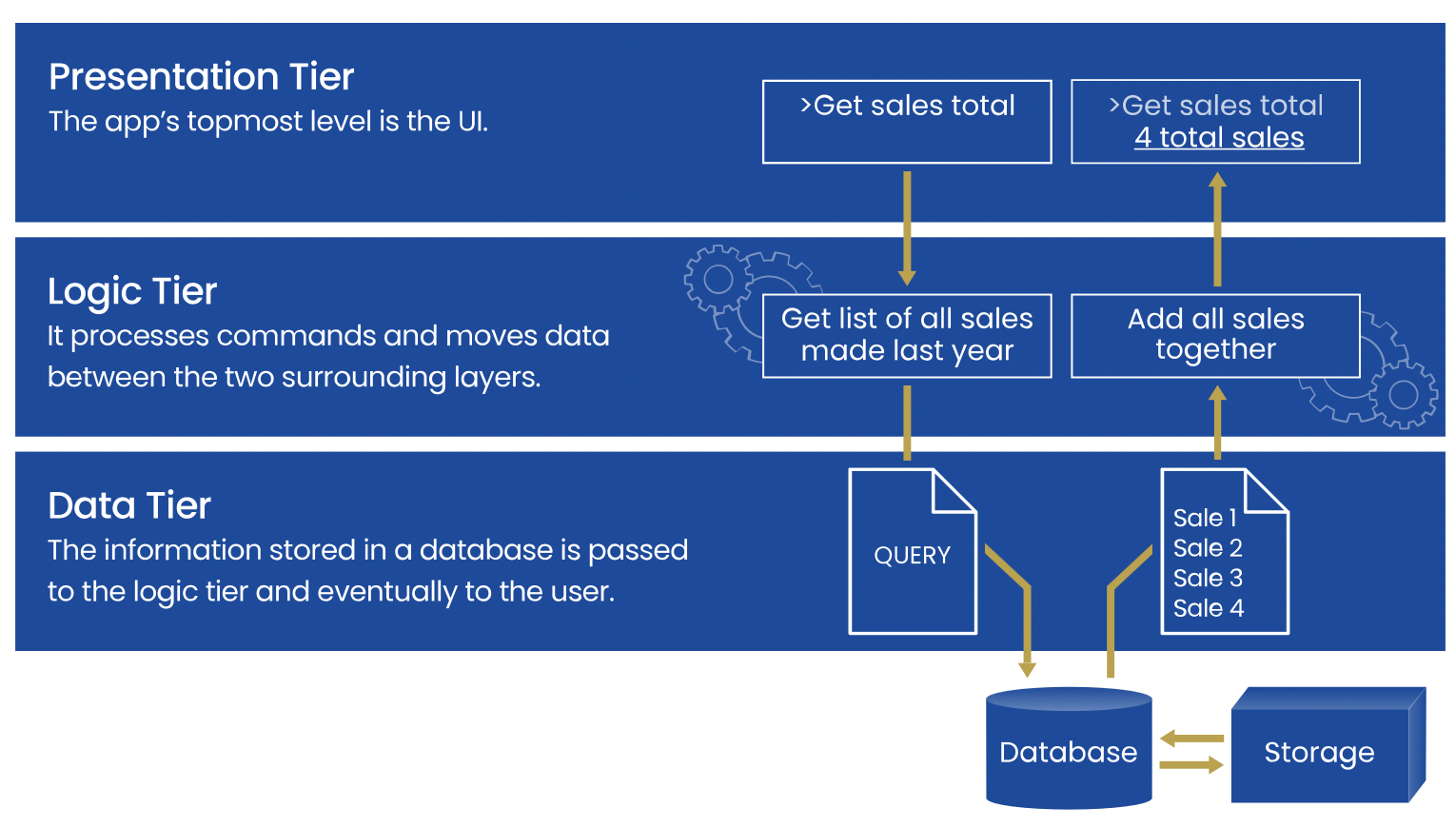
A broad architecture pattern for the data access layer we use and promote at Resolute Software is to further sub-layer that into Entities and Services. These can also directly map to C# class library projects in a .NET solution. The entity project contains plain data containers – also called contract classes. Your business logic layer, and potentially your presentation layer, too, use these entity classes to retrieve data from and send changes to the data layer.
Your data services are the primary data “workers” in your application. They provide a public API (classes and methods) for retrieving and updating data. Importantly, data service methods accept as parameters and return instances and collections of entity classes as a result. This creates a well-organized, entity-centric public API signature for your data services. Consumers of your services only care about the entities they need to retrieve or store and not about the implementation details of how the data in these objects end up in the relational database. By providing an entity-centric data API, your data access layer encapsulates the concern of data storage and retrieval, promotes code reuse (same data containers everywhere), and creates a decoupled architecture. The latter enables implementation changes in your data storage without breaking changes in your application.
Choose Right Data Access Migration Approach
If your legacy .NET application is already organized in a proper multi-tier architecture with a well-defined, entity-centric data access layer, your modernization project is simplified significantly. .NET systems that can afford to keep and reuse their data access layer substantially reduce the necessary steps to bring the data components to modern .NET. Generally, we can apply the following checklist to modernizing an already “entities plus services”-based data layer:
- Convert entity projects to .NET Standard, along with any dependencies
- Make sure entity projects depend on .NET Standard libraries only for maximum reuse
- Convert service projects to modern .NET (currently .NET 6)
- Replace Entity Framework with its modern .NET counterpart (currently EF Core 6.0)
- Replace any implementation-specific dependency (e.g. log4net or Newtonsoft.Json) with .NET 6 or .NET Standard version
We have seen this checklist apply to most modernization projects that already have a well-structured data access layer. Of course, your mileage may vary. Particularly, the dependency graph may not always be that simple (standalone entities and services that depend on them). Still, the general guidance is to make sure your contracts are .NET Standard libraries (and as few of them as possible, ideally one), and your service projects target .NET 6 and have all their dependencies target .NET 6 or .NET Standard.
Of course, finding a well-structured, well-architected data access in a legacy .NET application is an architect’s bliss, but the reality is not always as optimistic. Our team is often involved in Web Forms projects using legacy ADO.NET for the data access (think DataSets instead of Entities), typically writing SQL queries in C# with SqlDataAdapter, or in some cases, querying SQL databases straight from ASPX pages with SqlDataSource controls. Another similarly challenging example is an app that uses SQL stored procedures heavily, where a lot of the business logic has been implemented at the database level.
From a modernization perspective, these scenarios represent the worst case since none of these legacy data access patterns follow the decoupled, object-oriented paradigm of entities and services. They return data in tables, not objects, and the data access code is typically tightly coupled to the UI layer. Not much of this code can be reused when modernizing, as shifting to an entity-focused data architecture typically constitutes a complete rewrite of the data access layer.
When a legacy application uses ADO.NET-based data access, a sensible mid-point architecture approach could be to refactor data access methods into data services instead of a complete rewrite and a switch to Entity Framework Core. Since ADO.NET is part of modern .NET, C# code that uses ADO.NET classes (e.g., SqlDataProvider, SqlDataReader, etc.) can be reused in a modern .NET project. However, the trade-off to keeping this code is the manual writing of entity classes in C# and the mapping code that transforms DataSet instances into entity collections. Depending on the schema size and complexity of the data, manually creating entity classes can be a major development effort. System architects advising on the correct approach, in this case, should take into consideration the opportunity cost of investing this dev time into a full-blown Entity Framework migration.
Consider Performance Implications
Your data architecture directly impacts the performance of your application. Even if you preserve the same database server and schema, how your application executes queries against the database affects your system’s data throughput. Too often, we see inefficient queries loading tons of unnecessary data or being executed repeatedly for the same result set. We all can do better.
When designing the data flow in a system, here are some fundamental performance principles for efficient data access that we adhere to:
- Retrieve as little data at a time as necessary – don’t bring the entire jungle together with the monkey
- Fetch related data only if needed – load data on demand, not in anticipation
- Cache frequent, immutable data – because fetching the same data twice is just inefficient
- Monitor and optimize query execution – with actual data and real users
Finally, a quick note on data performance and horizontal scalability. In a world where applications increasingly run in the cloud, we see major development effort invested in application performance through “horizontal scaling” – replicating application instances that work simultaneously to provide service for more concurrent users. At the same time, we see little effort being put into improving data efficiency in those applications – optimizing queries, removing the retrieval of unnecessary data, or reducing the “chattiness” between the client and the server.
Conclusion
Regardless of the number of scalability improvements done at the application runtime level, data access will always be a bottleneck unless we plan, execute, and optimize efficient data pathways. We must plan for the expected data and user load, create and execute on efficient system architecture, and constantly optimize data ingress and egress. Anything less is sub-optimal data architecture.
Data storage, access, and throughput are just some of the many considerations we should make when we embark on a software modernization journey.
Opinions expressed by DZone contributors are their own.
Comments