Implementing Automated Validation and Anomaly Detection
Ensure high-quality data in large-scale pipelines with automated validation, anomaly detection, and scalable frameworks that maintain accuracy and consistency.
Join the DZone community and get the full member experience.
Join For FreeEnsuring data quality has become much harder because contemporary systems generate data at high volume, high velocity, and high variety. Ensuring data consistency, completeness, and accuracy is harder as large-scale data pipelines often pull data from different sources in different formats. Traditional manual review processes simply can't keep up as the datasets are constantly being expanded and updated.
Manual checks not only cause delays but also rely heavily on human judgment, and when the workload is either too big or too fast, the checks are usually no longer applicable. This situation in large-scale environments results in a lack of anomaly identification, inconsistent validation, and increased operational risk.
Automated validation and anomaly detection eliminate these drawbacks by carrying out a systematic, repeatable, and real-time quality check throughout the entire data pipeline. With these techniques, companies can detect errors at an early stage, apply standards across a large area, and reduce human involvement.
This is a structured article that introduces a scalable framework for automated data quality assurance. It describes the principles, techniques, and structure necessary to provide operational high-quality data in the case of growing systems.
Understanding Data Quality Challenges at Scale
Data quality at scale is the condition of keeping data accurate, consistent, complete, and trustworthy throughout very large systems that manage incredibly large volumes in varied formats and practical applications. As data sizes grow, tiny discrepancies that are easy to manage in smaller environments become magnified. Moreover, large data pipelines lead to data drift and delayed detection, and they also make it quite difficult to maintain the same standards across geographically distributed sources.
Poor data quality is a common issue with large systems. Changes to the schema can occur without prior notice, resulting in the disappearance of certain fields, changes to their type, or even changes in their meaning. Corrupt partitions in storage systems can render data partially or make it completely unreadable. Late-arriving data disrupts time-based aggregations and downstream computations. Pipeline failures, such as broken transforms, resource constraints, or dependency outages, result in incomplete or inconsistent outputs.
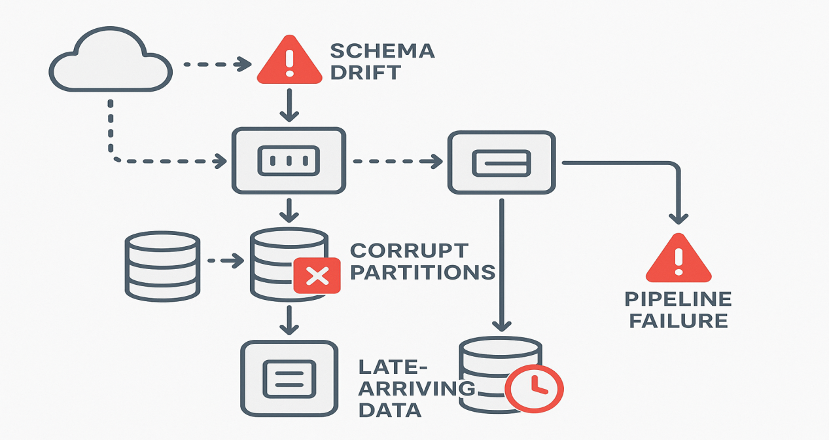
When anomalies go undetected in such environments, they will spread very quickly to downstream analytics and machine learning workflows. The defective metrics, incorrect dashboards, and tainted training data will accumulate quickly, affecting decision-making and causing model performance to deteriorate. In high-scale pipelines, even a short period of quality issues can cause widespread notification delays, underscoring the need for automated detection and control mechanisms.
Core Dimensions of Scalable Data Quality

1. Accuracy
Accuracy is a measure of how much the data corresponds to the actual values that it represents. Maintaining accuracy becomes more difficult when data volume is large, due to many scattered ingestion points, diverse data sources, and parallel processing. Mismatched transformations or partial failures in distributed systems can create subtle, hard-to-locate, inaccurate cases that are difficult to repair.
2. Completeness
Completeness ensures the presence of all mandatory fields, records, and partitions. In big data pipelines, the reasons for missing batches, dropped events, or incomplete partitions are often high-throughput ingestion and real-time streaming. Late-arriving data and partial writes are typical causes of large-scale completeness problems.
3. Consistency
Consistency is all about synchronizing meaning, formatting, and structure between the datasets. In cases involving large amounts of data, different teams might publish data with evolving schemas, leading to misalignment. When data is stored and processed in separate locations, it is common to have multiple versions of the same dataset, especially when updates propagate unevenly across nodes or regions.
4. Timeliness
Timeliness is a measure of how quickly data can be made available for use. High-speed streams, multi-stage pipelines, and large batch jobs can all add latency risks. Network congestion, queue backlogs, and distributed job scheduling can all contribute to delays in data delivery, leading to downstream analytics using outdated or incomplete data snapshots.
5. Validity
Validity is a guarantee that data adheres to the rules, formats, ranges, and business constraints that are defined. The major problem with the scale is that real-time streams and schema evolution increase the likelihood of invalid values being introduced into the system.
Some of the rules (or formulae) can be applied as follows:
Completeness rate:
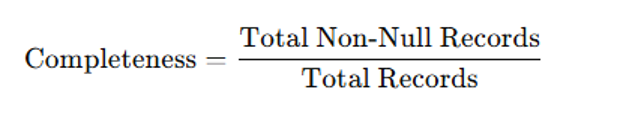
Accuracy error rate:
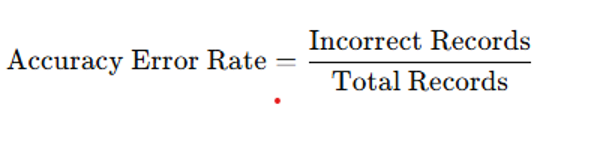
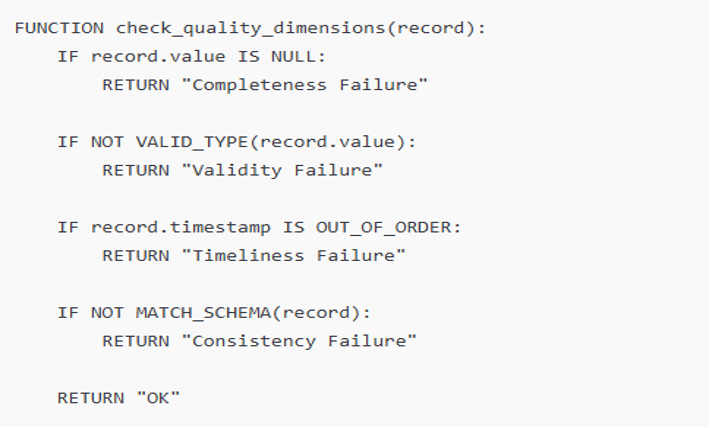
Code to check core quality dimensions:
Scale-specific context: The quality of data in distributed systems is largely determined by factors such as parallelism, consistency at last, and replication across multiple regions. On the other hand, the real-time flows of data come with unanticipated event ordering, messaging inconsistencies, and micro-batching, which may all together alter the data patterns that were expected. The high-capacity ingestion of data magnifies all the dimensions of the quality because it raises the number of errors, and at the same time, it cuts down the time for manual correction.
Timeliness lag:
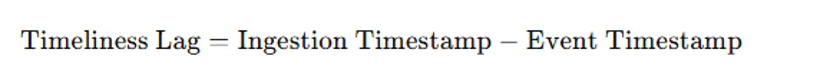
Building a Scalable Data Quality Framework
Step 1: Define Scalable Quality Rules
Create protocols that will operate smoothly in both batch and streaming environments. Choose to use flexible and parameterized validation logic that can be applied across the different datasets and stages of the pipeline. The rules that are scalable should take care of issues like schema acceptance, value ranges, completeness thresholds, and business constraints without the need for manual rewrites for each new source.
Step 2: Profile and Assess Data at Scale
Utilize distributed profiling techniques to reveal the data's characteristics, its distribution, and the presence of any anomalies, even when dealing with huge volumes of data. The likes of Spark, Snowflake, and BigQuery are the type of tools that enable concurrent profiling workloads. Use statistical sampling for rapid insight and periodic full scans to detect rare issues that might be hidden by the sampling method.
Step 3: Automate Validation in Pipelines
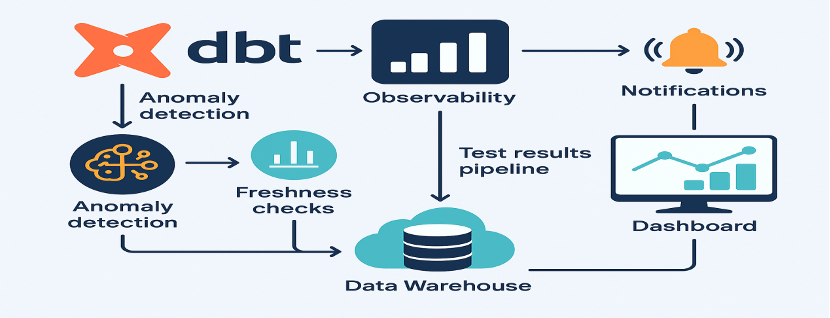
Integrate the rule-based validation checks right into ETL/ELT processes and streaming pipelines. The execution cycle for the pipeline will include automated schema validation, null checks, regex-based format checks, and threshold-driven rule application. Scalable frameworks optimized for distributed systems include Great Expectations, Deequ, and dbt tests, which are tools that come into play.
Step 4: Implement Anomaly Detection
Statistical and machine learning techniques are employed to detect deviations from expected patterns, including data drift, volume anomalies, distribution shifts, and missing or corrupt partitions. The automated large-scale anomaly detection, aligned with rule-based validation, is supported not only by using platforms such as Monte Carlo, Bigeye, and Anomalo but also by custom Spark-based jobs.
Step 5: Real-Time Monitoring and Alerts
Real-time dashboards should be created to continuously monitor quality metrics, including data freshness, completeness rates, and anomaly frequency. These dashboards can be integrated with event-driven alerting systems that send out instant notifications to the appropriate teams whenever any anomalies are detected. Consider observability practices such as lineage, metadata tracking, and health metrics as more important than individual validation checks to gain a comprehensive view of data behavior.
Step 6: Create Continuous Feedback Loops
Governance workflows and automated issue-tracking systems should be used to handle detected anomalies directly. To ensure no one person bears the responsibility alone, both data producers and consumers should participate in the remediation process. The feedback loop improves rule accuracy, making anomaly detection more reliable, and supports continuous trust across very large-scale data ecosystems.
Batch validation pseudocode:

Streaming anomaly detection pseudocode:

Tools and Technologies for Automated Validation and Anomaly Detection
In the case of such massive data volumes, quality is maintained through the use of specialized tools that have been automated for the detection and validation of abnormalities, and thus do not cause any delays to the pipeline. The technologies are divided into two main categories: rule-based validation tools and data observability/anomaly detection platforms.
1. Rule-Based Validation Tools
These instruments guide you in setting up crystal clear criteria for what comprises "good" data. They are best suited for validating schemas, checking for nulls, enforcing thresholds, and other structured constraints at most.
Great Expectations
The framework defined by a Python-based tool enables you to not only set and run expectations about your data but also keep records of them. With its ability to handle both batch and streaming validation, it is a perfect fit for distributed pipelines.
AWS Deequ
It is a library based on Apache Spark that provides an environment for large-scale, rule-based data quality checks. The stringency of constraints can be defined, metrics can be computed for extensive data, etc., and the whole process would be carried out efficiently in a distributed setup.
Soda Core/Soda Cloud
It is a service that monitors SQL-based data validation along with an observability dashboard. For instance, Soda Cloud provides the alerting and trend analysis features.
dbt Tests
Despite being a transformation framework, dbt allows data tests such as uniqueness, null checks, and referential integrity, which are integrated directly into your ETL/ELT workflows, to be performed declaratively through its functionalities.
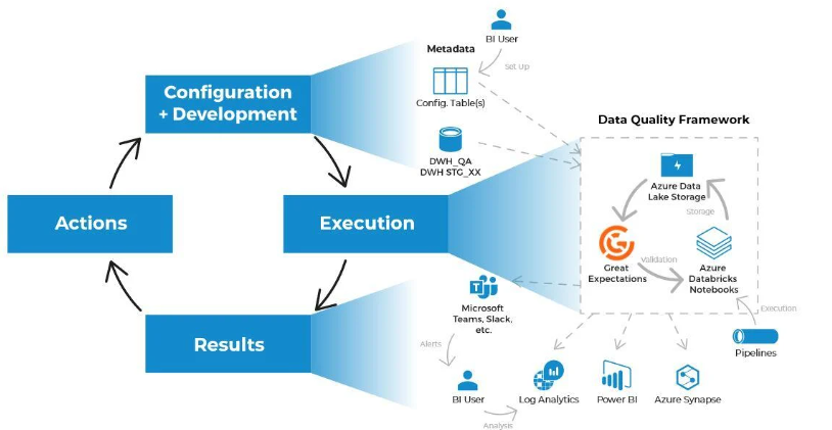
A complete architecture implementing all the above tools can be seen below:
2. Data Observability and Anomaly Detection Platforms
These tools primarily focus on detecting odd behaviors, changes in distribution, and other anomalies that may not be detected by rigid rules.
- Monte Carlo, Bigeye, and Anomalo: These are cloud data observability platforms that are always monitoring the data pipelines for any anomalies; their alerts are also tracked through lineage, and they constantly inform the teams beforehand. They use both statistical methods and machine learning techniques to discover not only volume but also schema and distribution's surprising changes.
- Stream Processors (Kafka, Flink): The high-throughput pipelines will not suffer from any delayed detection of problems in the live data streams, as the real-time stream processing frameworks can carry out validation and anomaly detection logic together with the high-throughput pipelines.
Key Takeaways
Total coverage is guaranteed by merging rule-based validation with observability/anomaly detection. Tools would need to work together effortlessly with both batch and streaming pipelines. Scalability, automation, and alerting are very important features for reducing the overhead of manual monitoring.
Common Pitfalls and How to Avoid Them
Even with automated validation and anomaly detection in place, large-scale data systems face recurring challenges. Understanding these pitfalls helps teams design more resilient frameworks.
1. Overloading Pipelines With Expensive Validation Tasks
Problem: Even if one checks various records or entire batches, it could still result in pipeline slowing, increased costs, and a bottleneck.
Solution: Apply sampling to datasets that have a very high volume, give first place to in-stream light tests, and reserve heavy computations for previously arranged batch runs. By using parameterization, let validations run either conditionally or asynchronously.
Validation cost formula:
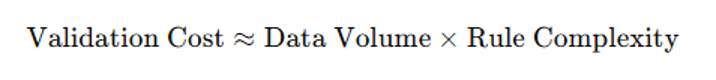
Validation detector pseudocode:

2. Depending Only on Rule-Based Checks (No Drift Detection)
Problem: Static checks can identify past issues, but cannot detect gradual changes in data distribution or schema drift.
Solution: Use a mixture of rule-based checks and statistical or ML-driven anomaly detection to identify not only distribution changes but also volume spikes as well as unexpected patterns.
3. Ignoring Metadata (Lineage, Schema Changes)
Problem: Teams are unable to grasp the repercussions of changes upstream or the failure of data pipelines that are not causing any disruptions, which, in turn, delays quick detection and troubleshooting.
Solution: Have solid lineage, schema versioning, and metadata catalogs as part of the data management process. Employ tools that will not only detect schema changes automatically but also notify affected parties.
4. No SLA/SLO Definitions for Quality
Problem: A precise assortment of service level agreements (SLAs) or objectives (SLOs) for data quality has not been determined so far, which has led to the situation where no performance standard is recognized universally, and varying degrees of application of rules are taking place.
Solution: Clearly define the quality requirements for on-time, complete, correct, and legitimate. Notifications and corrective actions should be determined based on numerical thresholds.
5. Not Closing the Loop With Automated Remediation
Problem: Detecting issues without a feedback mechanism leaves errors unresolved and increases downstream impact.
Solution: Implement automated remediation where possible (e.g., reprocessing failed batches, triggering data producer alerts) and feed detected anomalies back into governance and improvement workflows.
Key Takeaways
- Don’t depend solely on one technique; instead, apply a combination of rule-based, statistical, and ML-based verification methods.
- Integrate observability, metadata, and feedback loops into your strategy to reduce operational expenses and eliminate recurring errors.
- Define the quality targets explicitly to create accountability and achieve measurable improvement.
Conclusion
The increasing volume, speed, and diversity of data make it very difficult and unreliable to maintain data quality through manual controls. Thus, machine learning is no longer a choice; it is a necessity. By combining rule-based validation and anomaly detection, companies can stay one step ahead in their monitoring and actively manage data quality issues across both batch and streaming pipelines.
The creation of scalable and automated quality frameworks makes data quality a strategic enabler rather than a reactive burden. Moreover, it gives companies the trust and the ability to use their data effectively.
Opinions expressed by DZone contributors are their own.
Comments