Avoid Data Silos in Presto in Meta: The Journey From Raptor to RaptorX
This article will shed some light on the history of Raptor and why Meta eventually replaced it in favor of a new architecture based on local caching, namely RaptorX.
Join the DZone community and get the full member experience.
Join For FreeRaptor is a Presto connector (presto-raptor) used to power some critical interactive query workloads in Meta (previously Facebook). Though referred to in the ICDE 2019 paper Presto: SQL on Everything, it remains somewhat mysterious to many Presto users because there is no available documentation for this feature. This article will shed some light on the history of Raptor and why Meta eventually replaced it in favor of a new architecture based on local caching, namely RaptorX.

The Story of Raptor
Generally speaking, Presto, as a query engine, does not own storage. Instead, connectors were developed to query different external data sources. This framework is very flexible, but it is hard to offer low latency guarantees in disaggregated compute and storage architectures. Network and storage latency adds difficulty in avoiding variability. To address this limitation, Raptor was designed as a shared-nothing storage engine for Presto.
Motivation — An Initial Use Case in the AB Testing Framework
In Meta, new product features typically go through AB testing before being more broadly released. The AB testing framework allows engineers to configure experiments that roll out a new feature to a test group and then monitor key metrics against a control group. The framework gives engineers a UI to analyze their experiment’s statistics, which converts the configurations to Presto queries. The query shapes are known and limited. Queries typically join multiple large data sets, which include user, device, test, event attributes, etc. The basic requirements for this use case are:
- Accuracy: Data need to be complete, accurate, and can't be approximate.
- Flexibility: Users should be able to arbitrarily slice and dice their results.
- Freshness: Test results should be available within hours.
- Interactive Latency: Queries need to return results within seconds.
- High Availability: As a critical service for product development, there should be minimal downtime for the service.
Presto in a typical warehouse setting (i.e., using Hive connector to query warehouse data directly) could easily meet the first two requirements but not the rest. At that time, there was no near-real-time data ingestion, and most warehouse data was ingested daily, thus not satisfying the freshness requirement. Meta's data centers were already moving to a disaggregated compute/storage architecture that could not guarantee latency when scanning large tables at high QPS. A typical Presto deployment would stop the whole cluster, thus not satisfying HA requirements.
To support this critical use case, we began the journey of productionizing Raptor.
Raptor Architecture
Following is the high-level architecture of a Presto cluster with a Raptor connector.

The Raptor connector uses MySQL as its metastore for storing table and file metadata. Table data is stored on flash disks on each worker node and periodically backed up to an external storage system to enable recovery if a worker node crashes. Data is ingested into the Raptor cluster in small enough batches to provide minute-level latency, providing freshness. A standby cluster is created to provide high availability (HA).
Limitations
Having compute/storage collocated, Raptor clusters can support low-latency, high-throughput query workloads. However, the flip side of collocation is also significant.
Low Cluster Utilization
The size of a Raptor cluster is typically decided by how much data needs to be stored. As the tables grow, more worker nodes are needed due to the collocated compute/storage, which also creates challenges to repurpose these machines for other uses even when the cluster is idle.
Low Tail Performance
Because data is hard allocated to worker nodes, if a worker node is down or slow, it will inevitably affect query performance, making it hard to provide stable tail performance.
High Engineering Overhead
Raptor requires a lot of storage engine-specific features and processes like data ingestion/eviction, data compaction, data backup/restoration, data security, etc. For a disaggregated Presto cluster directly querying Meta’s data warehouse, all of these services are managed by dedicated teams, and improvements benefit all use cases. The same cannot be said for Raptor, which resulted in engineering overhead.
High Operational Overhead
The additional storage aspects of Raptor clusters also require additional operational work. The different cluster configuration and behavior means separate on-call processes must be set up.
Potential Security and Privacy Vulnerabilities
With the increasing security and privacy demands, having a unified implementation of security and privacy policies becomes more important. Using separate storage engines makes enforcing such policies extremely hard and fragile.
The Inception of RaptorX
With the pain points of Raptor, engineers at Meta started to rethink Raptor’s future in 2019. Is it possible to benefit from local flash storage without paying the cost of collocated storage / compute architecture? The direction that was decided on was to add a new local caching layer on top of a vanilla data warehouse. As a replacement for the Presto Raptor connector use cases, this project
is named RaptorX.
Technically, The RaptorX project is not related to Raptor. The intuition is that the same flash drive can be used to store Raptor tables as a data cache, thus keeping hot data on the compute nodes. The advantages of using local flash as caching rather than a storage engine are:
- It is no longer necessary for Presto to manage the data lifecycle.
- Query performance is less affected by data loss due to single-worker failure.
- Caching as a feature in the filesystem layer is part of the presto-hive connector; thus, the architecture of a RaptorX cluster is similar to other warehouse presto clusters, reducing operational overhead.
RaptorX Architecture
Following is the architecture of RaptorX:
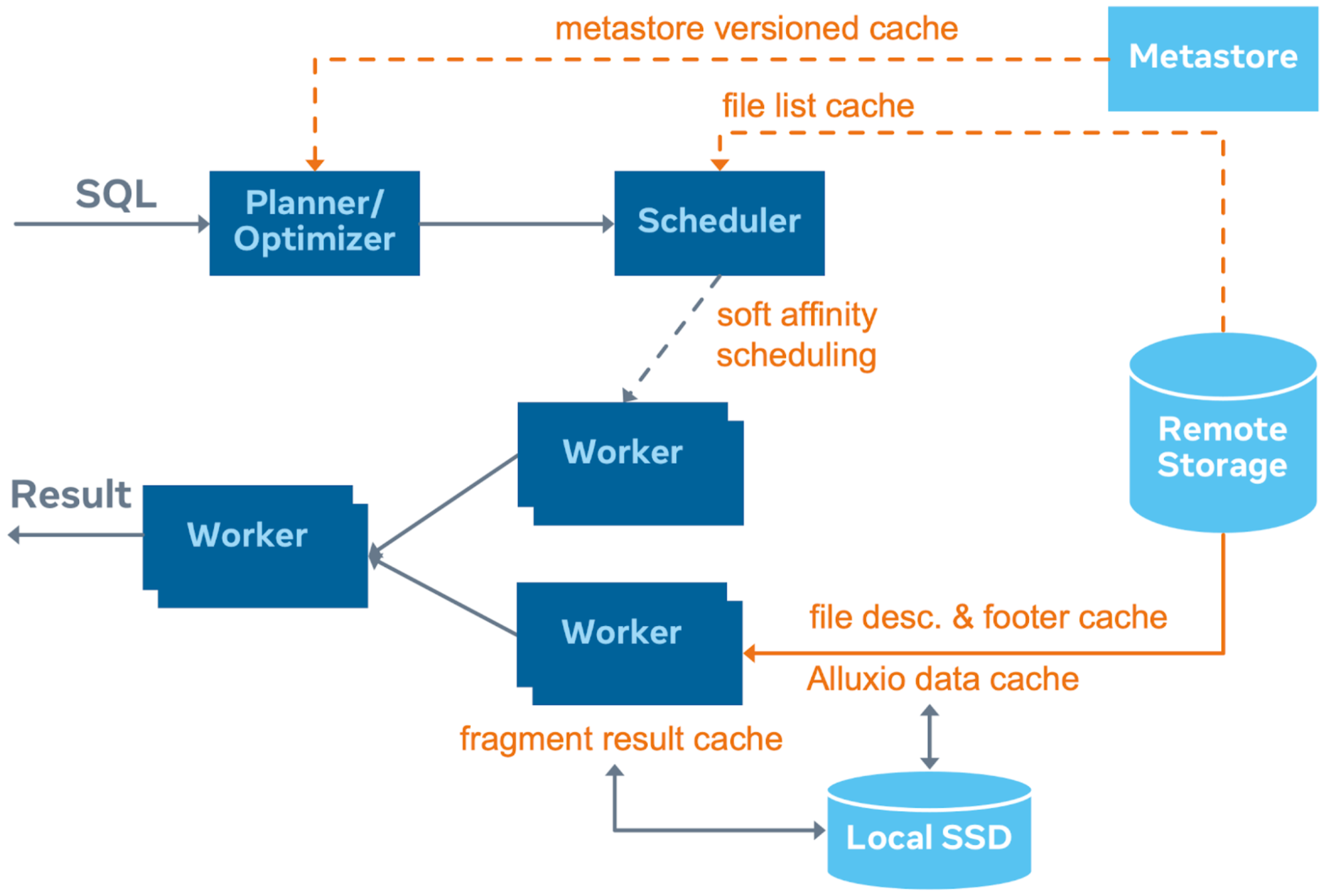
The fundamental difference between Raptor and Raptor X is how the local SSDs on workers are used. In RaptorX, Presto workers use Alluxio to cache file data locally. It is well understood that access patterns for different table columns could be very different, and columnar file formats like ORC and Parquet are commonly used for data files to increase data locality within files. Caching file fragments in small page sizes on top of columnar files will keep only frequently accessed data
close to computing. To increase cache effectiveness, the Presto coordinator tries to schedule compute that processes the same data to the same worker node. RaptorX also implements file footer and metadata caching and other smart caching strategies that improve performance further.
RaptorX vs. Raptor Performance Benchmark
We ran benchmarks to compare the performance of a RaptorX prototype against the Raptor. The benchmark is run on a cluster with ~1000 worker nodes and a single coordinator. Raptor and RaptorX use the same hardware, so the whole dataset fits in RaptorX's local SSD cache; thus cache hit rate is close to 100%.

As you can see from the benchmark result, P90 latency has an almost 2x improvement for RaptorX compared to Raptor. The difference between average query latency and P90 query latency in RaptorX is much smaller compared to Raptor. This is because, in Raptor, data is physically bound to the worker node hosting it; thus, a slow node would inevitably affect query latency. In RaptorX, instead of hard affinity between worker and data, we use soft affinity when scheduling. Soft affinity will select two worker nodes as candidates to process a split. If the first choice worker node is up and healthy, that node will be chosen; otherwise, a secondary node will be selected. Data can potentially be cached at multiple nodes, and scheduling can optimize for better CPU load balancing for the overall workload.
Migration From Raptor to RaptorX
All previous Raptor use cases in Meta are migrated to RaptorX, which provides a better user experience and is easy to scale.
A/B Testing Framework
In the previous section, we mentioned that the requirements for the A/B testing framework are: accuracy, flexibility, freshness, interactive latency, and high availability. Since RaptorX is a caching layer on the original Hive data, accuracy is guaranteed by Hive. It enjoys all the query optimization from the core Presto engine and many specific optimizations in the Hive connector. Benchmark shows that both average and P90 query latency is better than Raptor. For freshness requirements, we benefited from Meta’s near real-time warehouse data ingestion framework improvements, which improved data freshness for all Hive data. High availability was guaranteed with a standby cluster, as in Raptor.
During the migration process, traffic to the framework grew by 2X due to great user experience and organic growth. RaptorX clusters were able to support the extra traffic with the same capacity as Raptor clusters pre-migration. The clusters’ CPU capacities were fully utilized without worrying about storage limitations.
Dashboard
Another typical use case of Raptor in Meta is improving the dashboard experience. Presto is used to power many of the dashboarding use cases in Meta. Some data engineering teams inject their pre-aggregated tables into dedicated Raptor clusters for better performance. By migrating to RaptorX, data engineers can remove the ingestion step and no longer need to worry about data consistency between base tables and the pre-aggregated tables while also enjoying around 30% query latency reduction in most percentiles beyond P50.
Beyond the Scope of Raptor
Since RaptorX is very easy to use as a booster on normal Hive connector workloads, we also enabled it for Meta's warehouse interactive workloads. These are multitenant clusters that handle pretty much all non-ETL queries to Hive data through Presto, ranging from Tableau, internal dashboards, various auto-generated UI analytics queries, various in-house tooling generated workloads, pipeline prototyping, debugging, data exploration, etc. RaptorX enables these clusters to provide an opportunistic boost to queries that hit the same data set.
Raptor Architecture Details
Data Organization
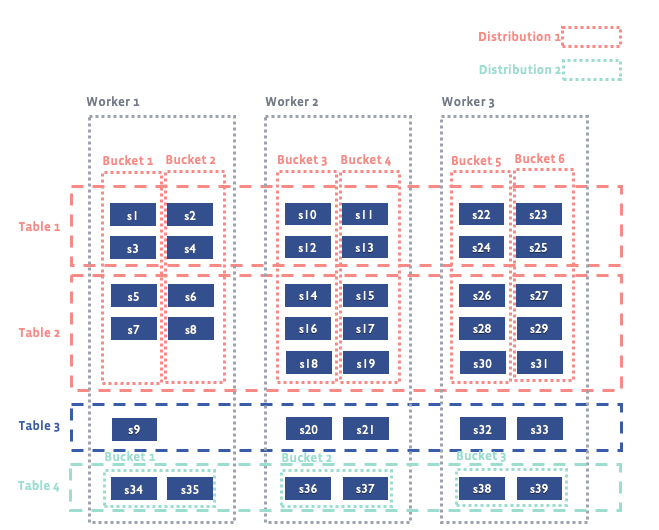
Raptor tables are hash bucketed. Data from the same bucket is stored on the same worker node. Multiple tables bucketed on the same columns are called a distribution. A table bucket can contain multiple shards. Shard is the basic immutable unit of Raptor data. A shard is stored as a file in ORC format. Tables can also have sorting properties, which allows better query optimization.
Execution Optimizations
As a native storage engine for Presto, Raptor allows Presto to schedule computation onto data nodes, thus providing low-latency, high-throughput data processing capabilities. In addition to generic SQL optimizations, the Raptor data organization enables more execution optimizations.
- Collocated Join: when joining tables in the same distribution on the bucketed columns, Raptor will do a collocated join since data with the same join keys are on the same worker, avoiding shuffling.
- Data Pruning: Raptor can do shard-level pruning and ORC reader-level pruning.
- Shard Level Pruning: column ranges of shards are stored in metadata, which can be used to skip shards based on predicates. If a table has sorting properties, shards will be sorted within a worker, which can also be used for shard pruning.
- ORC Reader Level Pruning: ORC reader uses stripe metadata to prune stripes and row groups based on a predicate. If data is ordered, ordering property also helps with pruning.
Other Features
- Temporal Column: A TIME or DATE type column can be specified as a temporal column. Raptor enforces daily boundaries on shards if a temporal column is specified. This helps with detention performance for large tables due to retention policies.
- Background Compaction: Data is usually ingested into Raptor in small time granularities for freshness; this can result in small files, which is not good for query performance. Raptor workers periodically run background jobs to compact small shards into big ones and perform external sorting to maintain sorting properties.
- Data Recovery: If a worker goes down, the coordinator will redistribute the dead worker’s data across the rest of the cluster. All workers will download the necessary data from backup storage. During recovery, if a query needs the missing data, it will block until the data is downloaded/recovered.
- Data Cleaning: Each worker has a background process to compare its assigned data with its local data. Missing data will be recovered, and stale data will be fixed.
- Data Rebalancing: If the coordinator detects data imbalance (e.g., new worker nodes added), it will fix the uneven data distribution.
Published at DZone with permission of Rongrong Zhong. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments