AWS EventBridge as Your System's Nervous System: The Architecture Nobody Talks About
EventBridge handles our 4M daily events. When Stripe changed APIs, we spent $1,200 and 4 days instead of $180K and 6 weeks.
Join the DZone community and get the full member experience.
Join For FreeI was sitting in a Tuesday standup when our VP dropped the bomb.
"Stripe is deprecating their v2 webhooks. We have 90 days."
My stomach dropped. We had webhook handlers scattered across seven different services: order processing, inventory updates, email notifications, analytics pipelines. Each one was directly coupled to Stripe's webhook format — the kind of technical debt you promise yourself you'll fix "next quarter" for two years running.
Platform engineering did the math on the whiteboard. Updating seven services, each with its own deployment pipeline, database migrations, and testing requirements. Conservative estimate: $180K in engineering costs. Best case: six weeks. Worst case: we miss the deadline and payments break.
Except we didn’t spend $180K. We spent $1,200 and finished in four days.
Because nine months earlier, I’d convinced the team to rebuild our event architecture around EventBridge. And everyone thought I was crazy.
The Architecture That Seemed Like Overkill
Let me take you back to that architecture review meeting in March. I’d just spent two weeks building a proof of concept that routed all external webhooks through EventBridge instead of having them hit our services directly.
The pushback was immediate and predictable.
"Why add another layer? Webhooks work fine."
"This seems like premature optimization."
"Do we really need AWS EventBridge for this?"
Here’s what I was seeing that nobody else was: our system didn’t have a nervous system. It had seven independent organisms that happened to live in the same body. When Stripe sent a payment_intent.succeeded event, it would directly wake up the order service. That service would manually call the inventory service, which would call the notification service, which would call analytics.
It worked. But it was brittle as hell.
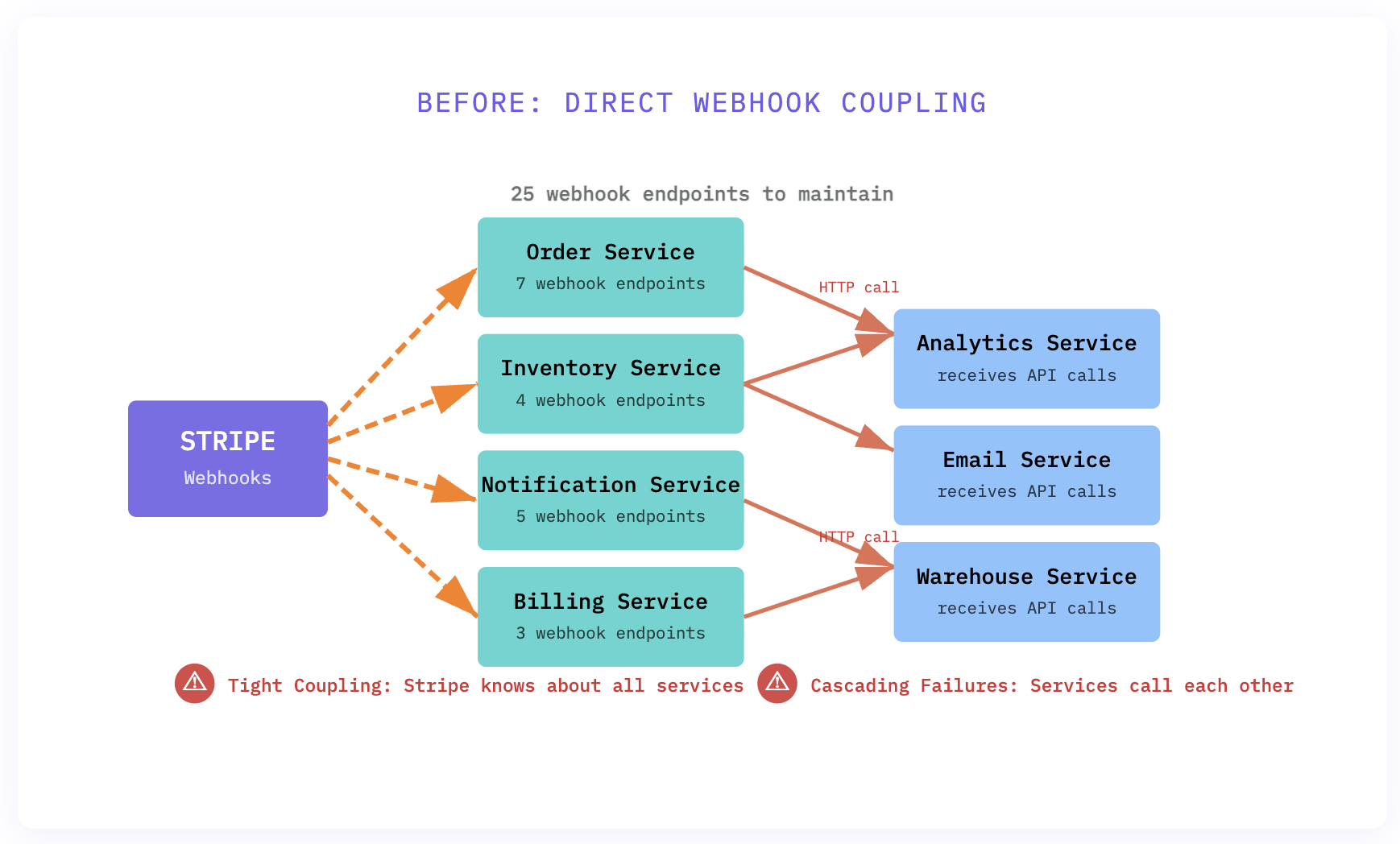
The EventBridge architecture I proposed flipped this completely. Instead of services talking to each other, they all talked to EventBridge. Every external webhook hit a single Lambda function that normalized the event and published it to our event bus. Services subscribed to the events they cared about.
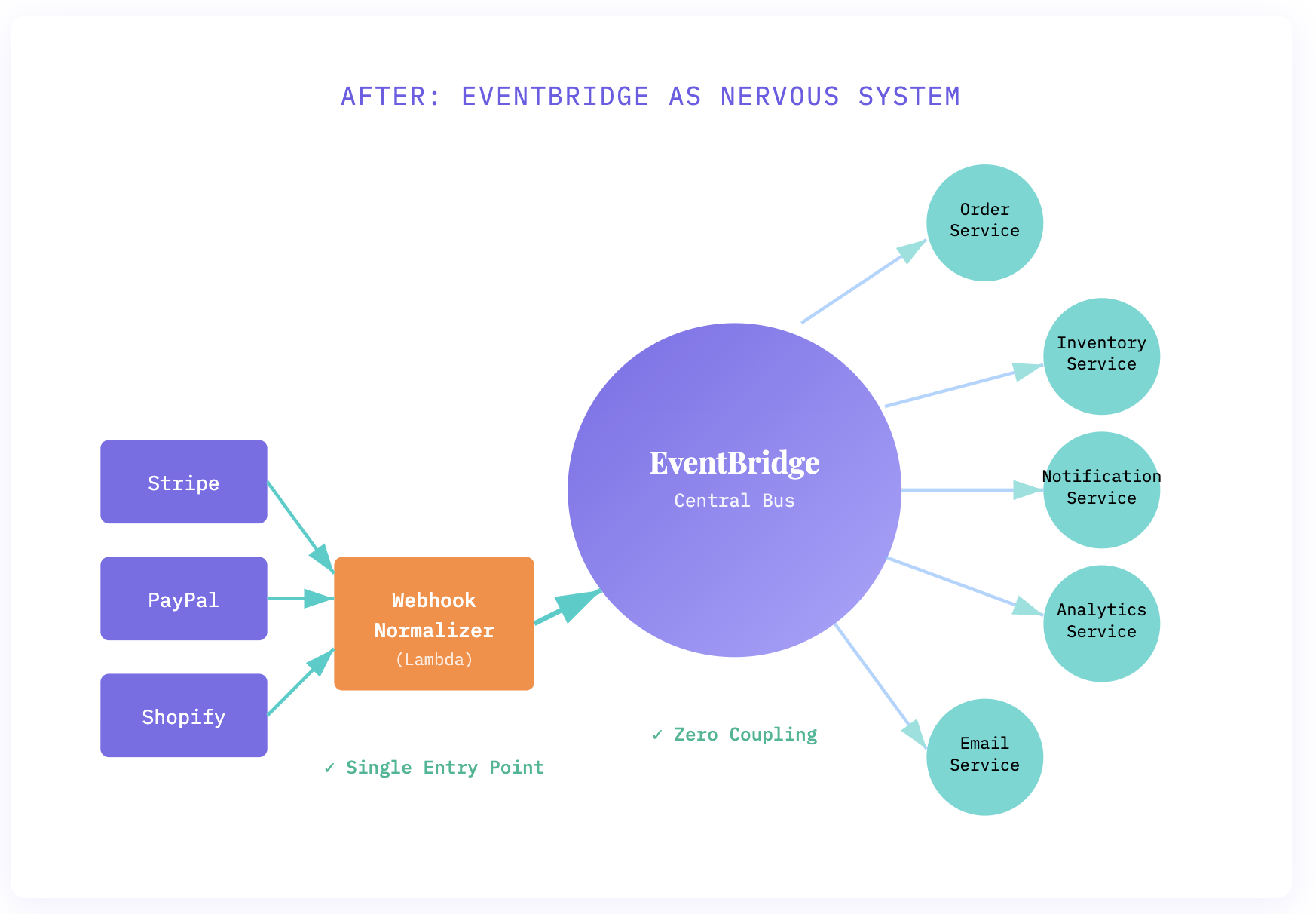
The beauty? No service knew where events came from. The order service didn’t know whether a payment.completed event came from Stripe, PayPal, or a test harness. It just knew: payment completed, process order.
Why It’s Actually a Nervous System
The nervous system metaphor isn’t just cute marketing. It’s architecturally precise.
Your nervous system doesn’t have your hand directly talk to your foot. When you touch something hot, sensory neurons send signals to the spinal cord. The spinal cord routes those signals to the brain. The brain processes them and sends signals back through motor neurons. Each part is specialized, decoupled, and completely unaware of the others’ implementation details.
That’s exactly what EventBridge does. External webhooks are sensory input. The webhook normalizer is the spinal cord — immediate, reflexive processing. EventBridge is the neural pathway. Individual services are motor neurons — specialized responders.
The killer feature isn’t the technical architecture. It’s what happens when you need to change something. Just like you can train your nervous system to respond differently to stimuli, you can rewire your EventBridge rules without touching application code.
When Stripe changed its API, here’s what we did:
We updated the webhook normalizer Lambda (68 lines of code). Changed the event shape from Stripe’s v2 format to v3. Published to the same EventBridge event pattern. Done.
Every downstream service kept working because they consumed normalized events, not Stripe’s raw payloads. We did it on a Wednesday afternoon. Zero downtime. Zero service updates. Zero database migrations.
The Patterns Nobody Documents
Here’s what I learned building this that you won’t find in AWS documentation.
Pattern 1: Event Normalization at the Edge
Don’t let raw external events onto your bus. Ever. Your webhook handler should transform vendor-specific payloads into domain events. When we integrated PayPal, our services didn’t care. They still received payment.completed events with the same schema.
Pattern 2: Event Versioning from Day One
We screwed this up initially. Six months in, we needed to change the event schema. Half our services were still consuming v1 events. Now every event includes a version field, and EventBridge rules route based on version. Services can migrate on their own schedule.
Pattern 3: Dead Letter Queues for Everything
This saved us during Black Friday. A bug in the inventory service caused it to reject 15% of order.created events. Because we had DLQs configured, those events sat safely in a queue while we fixed the bug, then we replayed them. Zero lost orders.
Pattern 4: Archive Anything That Touches Money
EventBridge archiving is criminally underused. We archive every payment-related event for 90 days. When customers dispute charges, we have perfect audit trails. When the finance team needs transaction reports, we replay archived events. Cost? $47/month for 2.1M archived events.
The Real Cost
Let’s talk money, because everyone assumes EventBridge is expensive.
We process 4 million events per day. That’s 120M events per month. At $1.00 per million events published and $0.20 per million events delivered to targets, our monthly EventBridge bill is around $280.
For that $280, we eliminated:
- $180K in migration costs (already paid for itself)
- 14 inter-service API calls that were costing $890/month in NAT gateway charges
- 3 RDS instances we were using for “event storage” ($440/month)
- Approximately 40 hours per month spent debugging service-to-service communication issues
The ROI is absurd. But it gets better.
The Second-Order Benefits
Six months after deployment, weird things started happening.
The analytics team built a new real-time dashboard without asking engineering for anything. They just subscribed to relevant events and built their pipeline. Two days. Zero meetings.
When we needed to add fraud detection, we didn’t modify existing services. We deployed a new fraud service that subscribed to payment.initiated events and published fraud.detected events. The payment service added a rule to listen for fraud events. Done.
We started treating events like data. Product managers would ask, "What events do we have around checkout?" — and we could actually answer. We built an internal event catalog. New developers could browse available events before writing a single line of code.
The system became genuinely antifragile. It got stronger from shocks instead of weaker.
What I’d Do Differently
If I were starting over, I’d invest in event schema validation earlier. We use JSON Schema now, but we should have started with it. Too many bugs came from services expecting fields that didn’t exist.
I’d also set up better monitoring from day one. We can see EventBridge metrics, but tracking event flow through the entire system required custom CloudWatch dashboards and Lambda instrumentation. There’s no out-of-the-box “nervous system health” view.
And I’d push back harder against the “this seems like overkill” argument. The pattern only seems like over-engineering until you need to change something. Then it suddenly becomes the only sane architecture.
The best architectures are the ones that make future changes easy, not the ones that make the initial build fast.
When NOT to Use This Pattern
I’m not saying EventBridge is always the answer. If you have three microservices that rarely change, direct HTTP calls are fine. If your entire system fits in a single Lambda function, you don’t need this.
But if you’re building something that will integrate with external systems, if you expect service boundaries to shift, if you’re growing a team that needs to work on different parts of the system independently — this pattern will save you.
It did for us.
That Tuesday, when our VP announced the Stripe migration, the room went quiet for about five seconds. Then I said, "We’re fine. The normalizer handles this."
Everyone looked confused. Then relieved. Then slightly annoyed that they’d braced for a crisis that wasn’t coming.
That’s the nervous system working exactly as designed. The hand touches something hot, signals fire, the system reacts — and you barely notice the complexity underneath.
That’s the architecture nobody talks about.
Opinions expressed by DZone contributors are their own.
Comments