AWS Serverless Data Lake: Built Real-time Using Apache Hudi, AWS Glue, and Kinesis Stream
In an enterprise system, populating a data lake relies heavily on interdependent batch processes. Today’s business demands high-quality data in minutes or seconds.
Join the DZone community and get the full member experience.
Join For FreeIn an enterprise system, populating a data lake relies heavily on interdependent batch processes. Typically these data lakes are updated at a frequency set to a few hours. Today’s business demands high-quality data not in a matter of hours or days but in minutes or seconds.
The typical steps to update the data lake are (a) build incremental data (b) read the existing data lake files, update incremental changes, and rewrite the data lake files (note: S3 files are immutable). This also brings in the challenge of ACID compliance between readers and writers of a data lake.
Apache Hudi stands for Hadoop upserts and incremental. Hudi is a data storage framework that sits on top of HDFS, S3, etc. Hudi brings in streaming primitives to allow incrementally process Update/Delete of records and fetch records that have changed.
In our set up we have DynamoDB as the primary database. Changes in DynamoDB need to reflect in the S3 data lake almost immediately. The setup to bring this together:
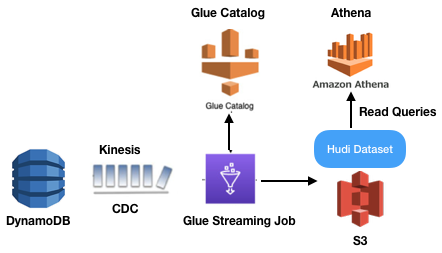
Enable Change Data Capture (CDC) on DynamoDB. The changes are pushed to the Kinesis stream.
A Glue (Spark) job acts as a consumer of this change stream. The changes are microbatched using window length. In the script below this length is 100 seconds. The records are then processed and pushed to S3 using hudi connector libraries.
x
spark = SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer').config('spark.sql.hive.convertMetastoreParquet','false').config('hoodie.datasource.hive_sync.use_jdbc','false').getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(spark.sparkContext)
commonConfig = {'hoodie.datasource.write.hive_style_partitioning' : 'true','className' : 'org.apache.hudi', 'hoodie.datasource.hive_sync.use_jdbc':'false', 'hoodie.datasource.write.precombine.field': 'id', 'hoodie.datasource.write.recordkey.field': 'id', 'hoodie.table.name': 'cust_hudi_f1', 'hoodie.consistency.check.enabled': 'true', 'hoodie.datasource.hive_sync.database': 'default', 'hoodie.datasource.hive_sync.table': 'cust_hudi_f1', 'hoodie.datasource.hive_sync.enable': 'true', 'path': 's3://' + 'x14lambdasource/Unsaved' + '/cust_hudi/test_data_20'}
partitionDataConfig = { 'hoodie.datasource.write.keygenerator.class' : 'org.apache.hudi.keygen.ComplexKeyGenerator', 'hoodie.datasource.write.partitionpath.field': "partitionkey, partitionkey2 ", 'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor', 'hoodie.datasource.hive_sync.partition_fields': "partitionkey, partitionkey2"}
incrementalConfig = {'hoodie.upsert.shuffle.parallelism': 68, 'hoodie.datasource.write.operation': 'upsert', 'hoodie.cleaner.policy': 'KEEP_LATEST_COMMITS', 'hoodie.cleaner.commits.retained': 2}
combinedConf = {**commonConfig, **partitionDataConfig, **incrementalConfig}
glue_temp_storage = "s3://x14lambdasource/Unsaved"
data_frame_DataSource0 = glueContext.create_data_frame.from_catalog(database = "default", table_name = "test_cdc_cust", transformation_ctx = "DataSource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
def processBatch(data_frame, batchId):
if (data_frame.count() > 0):
DataSource0 = DynamicFrame.fromDF(data_frame, glueContext, "from_data_frame")
your_map = [
('eventName', 'string', 'eventName', 'string'),
('userIdentity', 'string', 'userIdentity', 'string'),
('eventSource', 'string', 'eventSource', 'string'),
('tableName', 'string', 'tableName', 'string'),
('recordFormat', 'string', 'recordFormat', 'string'),
('eventID', 'string', 'eventID', 'string'),
('dynamodb.ApproximateCreationDateTime', 'long', 'ApproximateCreationDateTime', 'long'),
('dynamodb.SizeBytes', 'long', 'SizeBytes', 'long'),
('dynamodb.NewImage.id.S', 'string', 'id', 'string'),
('dynamodb.NewImage.custName.S', 'string', 'custName', 'string'),
('dynamodb.NewImage.email.S', 'string', 'email', 'string'),
('dynamodb.NewImage.registrationDate.S', 'string', 'registrationDate', 'string'),
('awsRegion', 'string', 'awsRegion', 'string')
]
new_df = ApplyMapping.apply(frame = DataSource0, mappings=your_map, transformation_ctx = "applymapping1")
abc = new_df.toDF()
inputDf = abc.withColumn('update_ts_dms',to_timestamp(abc["registrationDate"])).withColumn('partitionkey',abc["id"].substr(-1,1)).withColumn('partitionkey2',abc["id"].substr(-2,1))
# glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(inputDf, glueContext, "inputDf"), connection_type = "marketplace.spark", connection_options = combinedConf)
glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(inputDf, glueContext, "inputDf"), connection_type = "custom.spark", connection_options = combinedConf)
glueContext.forEachBatch(frame = data_frame_DataSource0, batch_function = processBatch, options = {"windowSize": "100 seconds", "checkpointLocation": "s3://x14lambdasource/Unsaved/checkpoint1/"})
The bits to note in the script:
The script assumes a simple customer record in DynamoDB with the following attributes getting inserted or changed:
id(partition key),custName(sort key),email,registrationDate.Various configuration settings are telling Hudi how to function. We have enabled sync with Hive, which means that metatables will also get created in AWS Glue Catalog. This table can then also be accessed using AWS Athena to query data in real-time.
There is a partition key mentioned in the configuration. This partition key for demonstration purposes is the last digit of the customer id. This will essentially create 10 partitions (0-9) and place customer data in various partitions. There is also a setting here that tells hudi to create hive-style partitions.
You can also control the number of commits through configuration. This will allow you to time travel in data.
The hudi write happens using connectors. There are two lines here (one commented). Either you can use MarketPlace Connector Or use your own custom connector.
Finally, you notice the glue line where we set up the consumer to get a bunch of records every 100 seconds.
Set up of Hudi Connector in AWS Glue
Market Place Connector: You can go to AWS Marketplace and search for "Apache Hudi Connector." The steps from there on are pretty simple and guided through the AWS console.
- Custom Connector: In some organizations, AWS marketplace access is not available. In order to enable this, you would need two Jar files, Hudi-Spark bundle: hudi-spark-bundle_2.11-0.5.3-rc2. I have compiled this jar and placed it in my GitHub repo for easy reference.
Also, you need an Avro-Schema jar, again available on my repo.
In order to create the connector, go to AWS Glue Studio -> Create Custom connector. Selecthudi-spark-bundle_2.11-0.5.3-rc2Jar as S3 URL Connector Type:Sparkand Class Name:org.apache.hudi.DefaultSource. Also while creating your Glue job using a custom connector, include the Avro-Schema jar as a dependent jar.
That is it, now all inserts/updates in DynamoDB will seamlessly reflect in your S3 data lake with real-time access. The script and jars are available in my GitHub repo.
Happy Coding!
Opinions expressed by DZone contributors are their own.
Comments