How to Banish Anxiety, Lower MTTR, and Stay on Budget During Incident Response
Cutting log ingestion seems thrifty — until an outage happens and suddenly you really need those signals! See how zero-cost ingestion can get rid of MTTR anxiety.
Join the DZone community and get the full member experience.
Join For FreeSince I started in technology in 1992 (over three decades ago!), I’ve encountered countless scenarios where I was expected to “do more with less.” Whether it meant delivering more with fewer team members or working within constrained hardware resources, this mindset has been a recurring theme.
One experience stands out from my time as a backend architect on a cloud modernization project. To reduce costs, we were asked to minimize or eliminate service-level logging — logging that we relied on heavily for debugging and incident analysis. The decision was driven by the high cost of log ingestion on our observability platform.
This worked — until it didn’t.
We Really Needed Those Logs!
Inevitably, an unexpected issue arose, and we needed those missing logs. They turned out to be the only way to pinpoint the root cause. Without them, hours ticked by without a solution, uncertainty grew, and anxiety followed the entire team.
// Sample (but not the real) log line removed during our cost-cutting
{
"timestamp": "2025-03-21T14:05:03Z",
"service": "preference-engine",
"level": "ERROR",
"message": "Worker queue overflow: unable to dispatch to worker pool",
"requestId": "abc123",
"userId": "admin_42"
}Had we kept it, a simple, structured error log (such as the above) could have been easily filtered in a logging platform with a simple log query (such as the below) and allowed us to understand, diagnose, and fix the problem.
_sourceCategory=prod/preference-engine "Worker queue overflow"
| count by userId, requestIdBeing told to drastically reduce our logging put the entire project into a vulnerable state.
Lean Doesn’t Have to Mean Starved for Resources
To be clear, the “do more with less” mindset isn’t inherently bad. Many startups thrive by focusing on key priorities and leveraging lightweight, efficient software. Minimalist design can lead to better quality, provided that key tooling remains in place.
But this wasn’t the “good” kind of lean. And our deadline to move to the cloud was fixed. We were racing against a browser deprecation date. That meant rewriting services to a cloud-native design, coordinating with client teams, and delivering under pressure. With no time for complete test coverage or deep observability integrations, we relied on logs to resolve our issues and help determine the root cause for unexpected scenarios. That was OK at first, we just inserted the necessary logging while working on each method.
But when logging was cut back, the team was exposed. Our primary safety net was gone.
Root Cause Without a Net
Internal testing went well. As production approached, we felt confident in our new cloud-based architecture. We had resolved known issues in the test and met our deadline.
But we soon realized that our confidence was misplaced and our test coverage was lacking.
Once we were in production and real customers were using the platform, those pesky unanticipated edge cases emerged. And of course, without detailed logs or sufficient observability, we had no way to investigate the issue. The limited telemetry available simply wasn’t enough to determine what had gone wrong.
If we had logs for both the backend tests and production customers on the frontend, we could have known what was happening and alerted the team (and the user). It would be a simple log query:
_sourceCategory=prod/preference-engine OR prod/frontend error
| join ( _sourceCategory=prod/tester-feedback “queue error” )
on requestId
| fields requestId, _sourceCategory, messageBut without the logs, reproducing the incidents locally was nearly impossible. There was just too much variability in real-world use cases. We attempted to re-enable partial logging, but this just led back to the increased ingestion costs we were asked to cut, without delivering actionable insights.
In some cases, we couldn’t identify the root cause at all. That’s a tough position to be in: knowing there’s a problem affecting users and being unable to explain it. It created a pervasive sense of helplessness across the team.
MTTR vs. Signal Quality
Yet another problem was that in our incident retrospectives, mean time to recovery (MTTR) was being treated as a headline metric. But we found that MTTR was most often a symptom, not a root cause.
Industry benchmarks usually show elite teams achieve MTTR in under an hour. But what we realized was that speed isn’t just automation — it’s high-fidelity signals. Low-fidelity signals, such as generic 500 errors or delayed alerting from aggregate metrics, don’t really help. They just introduce ambiguity and waste resources (such as precious triage time and logging budget).
In contrast, detailed, contextual signals — like structured logs with userId, requestId, and a service trace — cut directly to the root cause. Observability platforms can reduce MTTR, but only if the data you ingest is actionable.
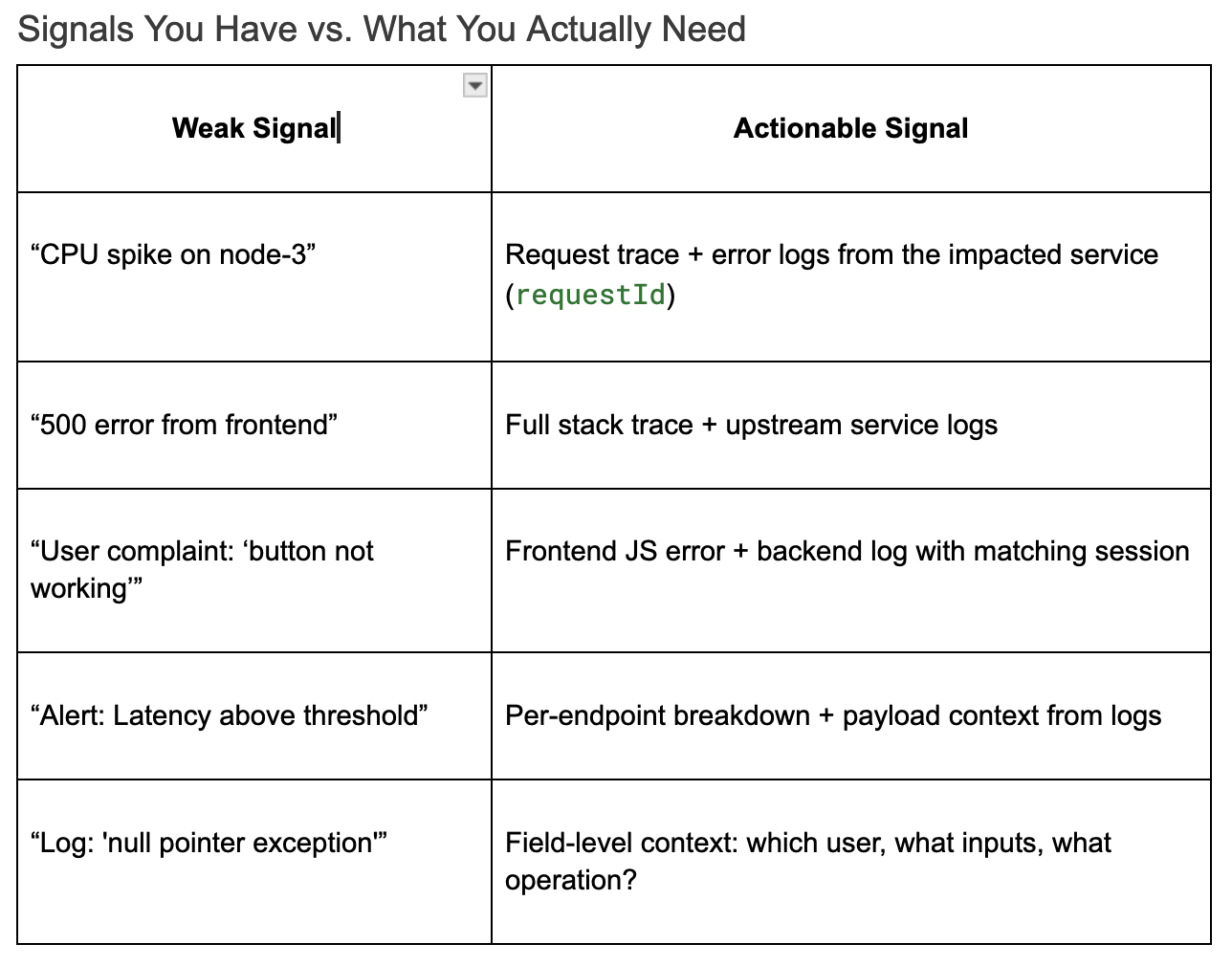
If your logs aren’t answering these questions, your MTTR isn’t about team speed — it’s about signal clarity.
How Sumo Logic’s Model Could Have Saved The Day
So what could have gone differently — and better — during my cloud modernization project?
First, I really wish we had had better log analytics and application performance monitoring (APM). And along with that, APM, log management, service monitors, alerts, and defined metrics are closely aligned with functional success or failure. I wish (on every project) that for every new feature, I had an associated metric tied to its success.
And I want my logs back! In my earlier publication, “DevSecOps: It’s Time To Pay for Your Demand, Not Ingestion,” I explored how Sumo Logic disrupted the observability space by offering a pay-per-analysis model. Logs can be ingested continuously, but you only pay when you need to query or analyze them.
Are you a team without full unit test coverage? Suffering from a lack of real-time alerts or granular metrics? On a tight budget? Withering from lack of logs?
With zero-cost full ingestion, teams can log as much as they need without worries. And when that incident does finally occur (and it will), analysis can be triggered on-demand, at a justifiable cost directly tied to customer impact or business continuity. The budget folks are happy; you’re happy.
This approach restores control and lowers anxiety because teams are empowered to investigate thoroughly when it matters most.
But Wait: You Also Need Machine-Assisted Triage to Clear Up Your Queries
But there’s one more step. Modern observability isn’t just about having all that beautiful log data — it’s also about knowing where to look in that data. As mentioned above, you need organized, high-fidelity signals.
When you have unlimited ingestion, you have a ton of data. And when you start looking for information, you need a place to start. To help, Sumo Logic also provides machine-assisted triage tools that automatically group anomalous behavior, detect outliers, and surface correlated signals across services before you write a single query.
Behind the scenes, Sumo Logic used statistical algorithms and machine learning to:
- Cluster logs by similarity (even if phrased differently across nodes).
- Detect outliers in metrics and logs (e.g., error spikes per service, region, or user cohort).
- Enrich anomalies with metadata (e.g., AWS tags, Kubernetes pod info, deployment markers).
- Natural language processing clusters logs by semantic similarity, not just string matching.
This is especially useful in the high-volume environment of unlimited ingest. Instead of sifting through tens of thousands of log lines, you get “log signatures” — condensed patterns that represent groups of related events.
Example Workflow
_sourceCategory=prod/* error
| logreduceThis single command clusters noisy log data into actionable buckets like:
Error: Worker queue overflow
Error: Auth token expired for user *
Error: Timeout in service *Once clustered, teams can pivot to deeper context:
| where message matches "Auth token expired*"
| count by userId, regionThe result? Fewer blind searches. Faster decision paths. Less anxiety during an incident.
Conclusion
The “do more with less” philosophy doesn’t have to put engineering teams at a disadvantage. But it must be accompanied by the right tools. Without them, even the most capable teams can feel like they’re navigating aimlessly during an incident, leading to frustration and stress.
My readers may recall my personal mission statement, which I feel can apply to any IT professional:
“Focus your time on delivering features/functionality that extends the value of your intellectual property. Leverage frameworks, products, and services for everything else.” — J. Vester
In this article, we looked at how a zero-cost ingestion model aligns with this mission. It helps teams quickly identify root causes, reduce downtime, and lower stress levels — all without breaking the budget. Let’s keep those logs!
Have a really great day!
Opinions expressed by DZone contributors are their own.
Comments