Architecting an Embedded Efficiency Layer: A Platform Deep Dive into Day-Two Operational Tuning
Learn how platform teams can embed continuous optimization into internal developer platforms using GitOps, HITL workflows, and full-stack tuning.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2026 Trend Report, Platform Engineering and DevOps: How Internal Platforms, Developer Experience, and Modern DevOps Practices Accelerate Software Delivery.
I am developing a reference guide for platform teams that want continuous optimization embedded directly into their internal developer platforms. In this proposed model, “done” means automated, full-stack tuning recommendations that fit safely and seamlessly into existing engineering workflows.
Building golden paths for pre-deployment tasks is relatively straightforward because engineering teams share the primary goal of shipping applications faster. However, after deployment, sustained efficiency frequently becomes a neglected task that is “someone else’s job.” Developers prioritize shipping, SREs protect safety buffers, and FinOps pushes for cost reduction. The reference model proposes a dedicated efficiency layer as a required platform capability designed to reconcile those priorities without requiring a replatform.
In this one-layer deep dive, we focus only on the embedded efficiency layer: its interfaces, interaction model, and what it requires to be credible.
Project Constraints
I anchor my design on the assumption that engineering teams are already managing their production deployments through established IaC and GitOps practices. Unlike pre-deployment pipelines that often enforce strict corporate standards, a post-deployment efficiency optimizer cannot be rigidly opinionated. Every microservice possesses unique architectural characteristics and operational requirements that demand a highly configurable approach to system optimization.
I recommend allowing teams to define explicit parameters based on the workload context, dictating whether a particular service requires a specific operational profile.
| Profile | Intent | Tradeoff |
|---|---|---|
|
Cost-first |
Aggressive cloud cost reduction |
Less headroom, higher reliability risk |
|
Performance-first |
Maximum throughput performance |
Higher cost (maybe), tighter buffers |
|
Reliability-first |
Expanded reliability buffer for unpredictable traffic spikes |
Higher baseline spend |
Architecting the Day-Two Golden Path
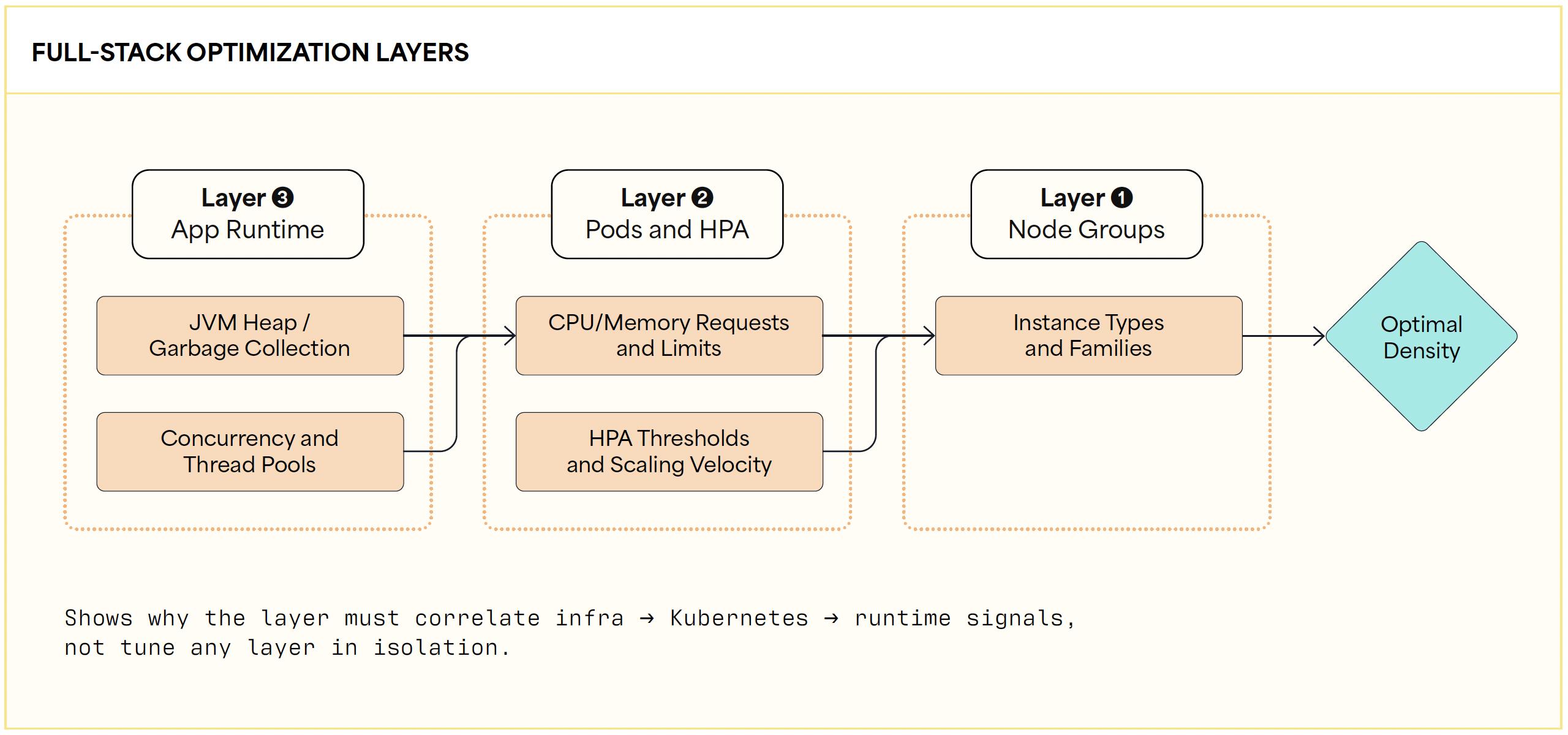
Effective efficiency optimization requires an architectural deep dive beyond superficial cloud scaling metrics. The framework I recommend orchestrates continuous tuning across the entire technological stack, cascading from the underlying infrastructure nodes down through Kubernetes configurations and directly into the application runtime.
Adjusting CPU requests and memory limits at the container level is mathematically insufficient if the underlying Java Virtual Machine or application runtime parameters remain poorly calibrated for those newly allocated resources. Consequently, the guide treats the underlying correlation engine as a mandatory architectural component for producing holistic configuration recommendations.
FLOW: infrastructure metrics + Kubernetes signals + app monitoring
→ correlation engine → recommendations (infra/k8s/runtime)
The Interaction Model
The foundational principle governing this architectural layer is an explicit human-in-the-loop (HITL) model. Fully autonomous, black-box changes erode trust when operators can’t see the reasoning behind configuration updates. Instead, the multi-dimensional tuning recommendations surface inside the developer’s GitOps workflow, presenting clear explainability about how a change affects latency, reliability, and cost. HITL ensures engineers retain final approval over critical production changes, but it introduces review latency and requires significantly more comprehensive explainability documentation for every recommendation.
Scenario Walkthrough
A critical microservice begins experiencing rising cloud costs alongside escalating p95 latency. The embedded optimization engine detects the drift, correlates the cross-stack metrics, and proposes two runtime adjustments via an automated GitOps pull request. The application owner reviews the generated explainability visuals, verifies that the tuning resolves the latency issue without violating any existing rule, and manually merges the request. The platform seamlessly applies the validated configuration and continuously tracks the resulting operational benefits.
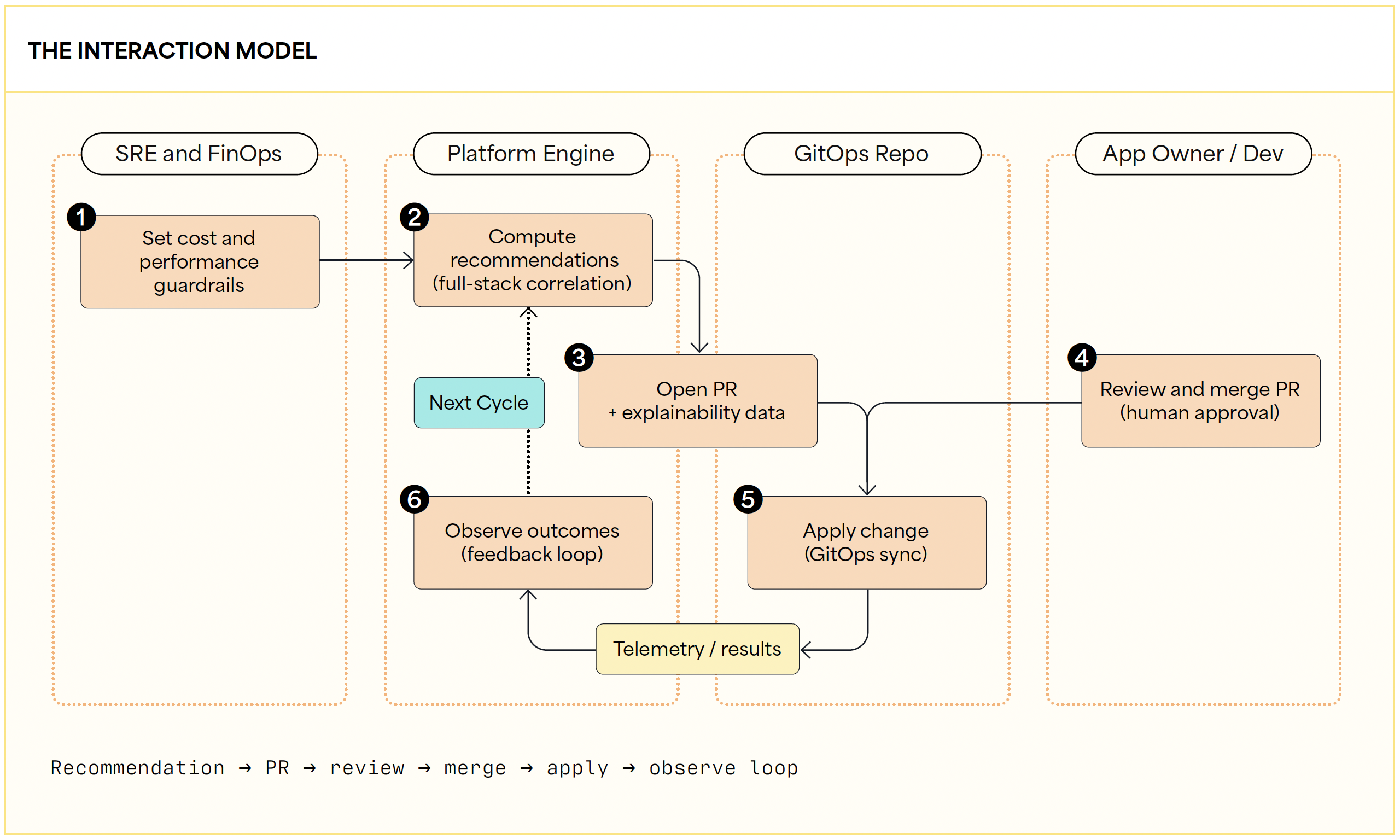
Figure 2: The Interaction Model
That workflow only holds if the following choices are true:
| Capability | tradeoff | what makes it workable |
|---|---|---|
|
Tuning profiles |
Requires explicit rules definition |
Profile selection per service or category |
|
Full-stack tuning |
More complexity than infra-only |
Correlation across infra + app metrics |
|
GitOps surfacing |
Adds workflow touchpoints |
PR-based delivery in existing process |
|
Human in the loop |
Review PRs and recommendation docs |
Explainability visuals + approval step |
Takeaways
Based on the framework in this reference guide, here is what I would tell someone building an embedded efficiency layer next, based on their involvement:
- Designing the interaction model: Prioritize operator trust and mathematical transparency over fully autonomous, unexplainable actions.
- Defining the technical scope: Ensure your engine tunes the entire stack, from the underlying infrastructure down to the application runtime, rather than settling for superficial cloud resource constraints.
- Navigating the sociotechnical divide: Treat the optimization layer as a collaborative platform capability that grounds the competing priorities of developers, reliability engineers, and FinOps, not a financial audit mechanism.
This is an excerpt from DZone’s 2026 Trend Report, Platform Engineering and DevOps: How Internal Platforms, Developer Experience, and Modern DevOps Practices Accelerate Software Delivery.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments