ToolOrchestra vs Mixture of Experts: Routing Intelligence at Scale
Learn about two fundamental architectural patterns reshaping how we build intelligent systems. Explore ToolOrchestra, Mixture of Experts (MoE), and other AI patterns.
Join the DZone community and get the full member experience.
Join For FreeLast year, I came across Mixture of Experts (MoE) through this research paper published in Nature. Later in 2025, Nvidia published a research paper on ToolOrchestra. While reading the paper, I kept thinking about MoE and how ToolOrchestra is similar to or different from it.
In this article, you will learn about two fundamental architectural patterns reshaping how we build intelligent systems. We'll explore ToolOrchestra and Mixture of Experts (MoE), understand their inner workings, compare them with other routing-based architectures, and discover how they can work together.
What Is Mixture of Experts?
Simply put, Mixture of Experts is an architectural pattern that splits a large model into multiple specialized sub-networks called experts. Instead of one monolithic model handling every input, you activate only the experts needed for each specific task.
The concept dates back to 1991 with the paper "Adaptive Mixture of Local Experts." The core idea is straightforward: route each input to the most suitable expert, activate only what you need, and keep the rest idle.
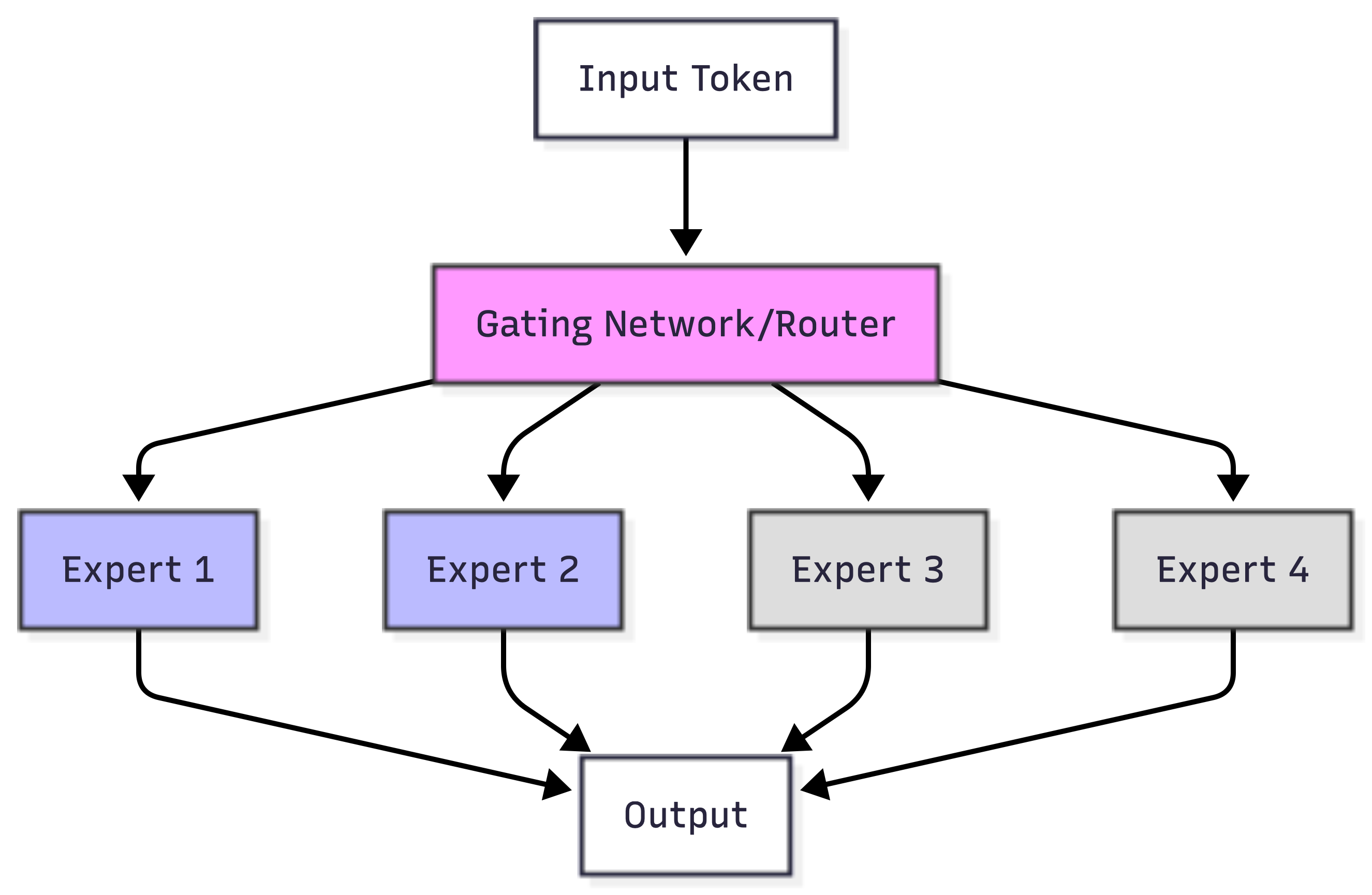
How MoE Works
In transformer models, MoE layers typically replace the feedforward layers. These feedforward layers consume most of the compute as models scale. Replace them with MoE, and you get massive efficiency gains.
Key components:
- Gating network – Decides which experts process which tokens
- Experts – Specialized sub-networks (typically feedforward networks)
- Load balancing – Ensures no single expert gets overwhelmed
- Sparse activation – Only activates selected experts per token
Routing strategies:
| Strategy | Description | Example Model |
|---|---|---|
| Top-1 | Each token goes to one expert | Switch Transformer |
| Top-2 | Each token goes to two experts | GShard, Mixtral 8x7B |
| Expert Choice | Experts select tokens | Expert Choice Routing |
| Soft Routing | Weighted combination of all experts | Soft MoE |
What Is ToolOrchestra?
ToolOrchestra, introduced by NVIDIA researchers in November 2025, takes a different approach. Instead of splitting one model into parts, it uses a small 8-billion-parameter model to coordinate multiple complete models and tools.
Think of it as a conductor leading an orchestra. The orchestrator model analyzes a problem, breaks it down, and calls different "instruments" to solve each piece.
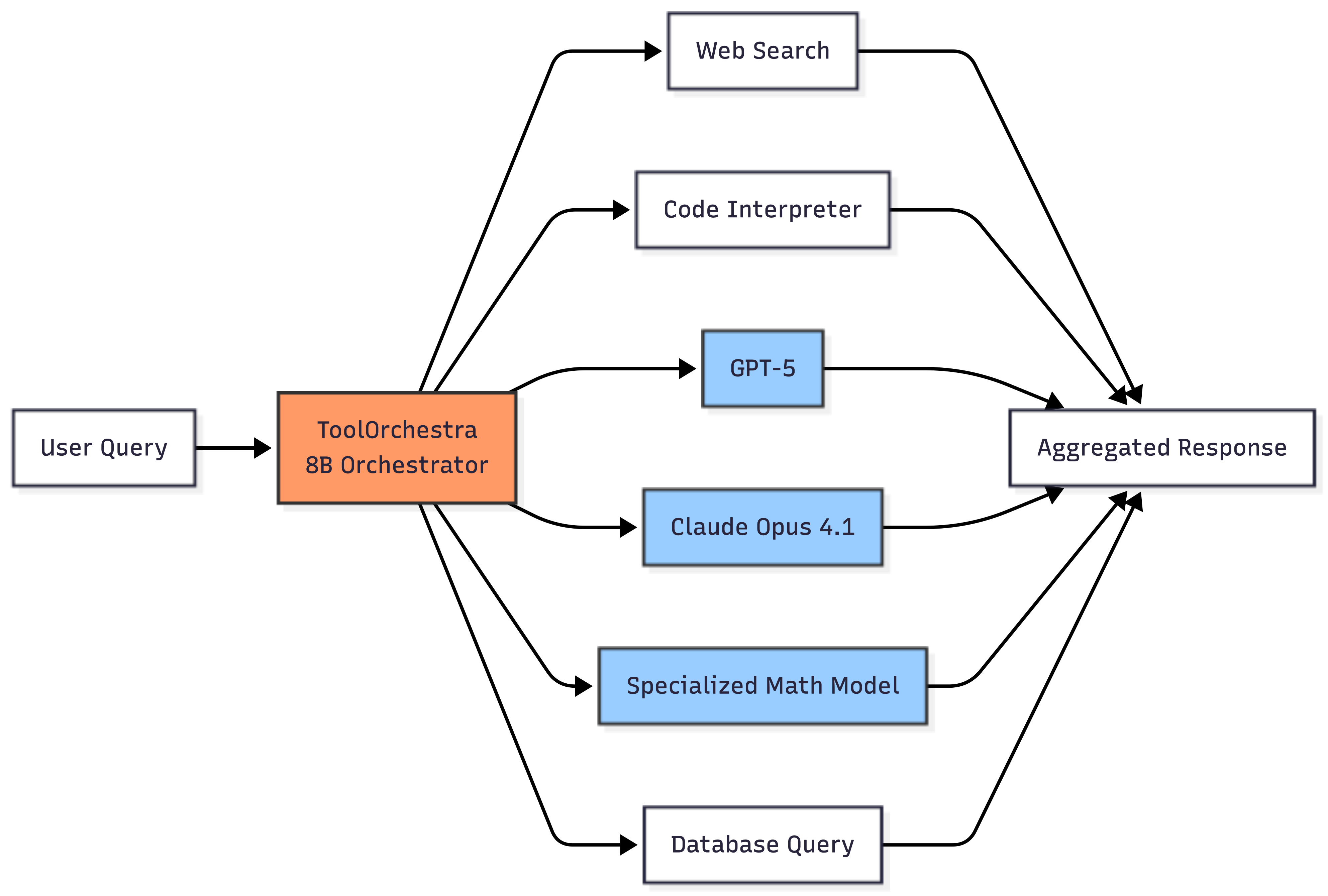
How ToolOrchestra Works
The breakthrough is in how it learns to orchestrate. ToolOrchestra uses reinforcement learning with three reward types:
Reward structure:
| Reward Type | Purpose | Focus |
|---|---|---|
| Outcome | Getting the right answer | Correctness |
| Efficiency | Using cheaper tools when possible | Cost optimization |
| Preference | Respecting user tool preferences | User control |
The training uses a synthetic data pipeline called ToolScale. It automatically generates databases, API schemas, and complex tasks with verified solutions. This gives the orchestrator thousands of examples to learn from through trial and error.
Core Differences
Let me break down the fundamental differences between these two approaches:
| Aspect | Mixture of Experts | ToolOrchestra |
|---|---|---|
| Granularity | Token-level routing | Task-level routing |
| Scope | Within a single model | Across multiple systems |
| Components | Sub-networks (experts) | Complete models and tools |
| Training | Joint training of all experts | Only orchestrator trains |
| Activation | Sparse parameter activation | Selective system invocation |
| Memory | All experts in memory | Tools loaded on demand |
| External Access | No external tools | Web, APIs, databases |
The fundamental difference is in what gets split up. MoE splits a single model's parameters into specialized sub-networks. All experts live inside one model architecture, sharing the same input and working on the same task at the parameter level.
ToolOrchestra splits tasks across different complete systems. The orchestrator is a small, standalone model that coordinates other models and tools. Each tool or model it calls is fully independent, potentially running on different hardware, using different architectures, and even created by different companies.
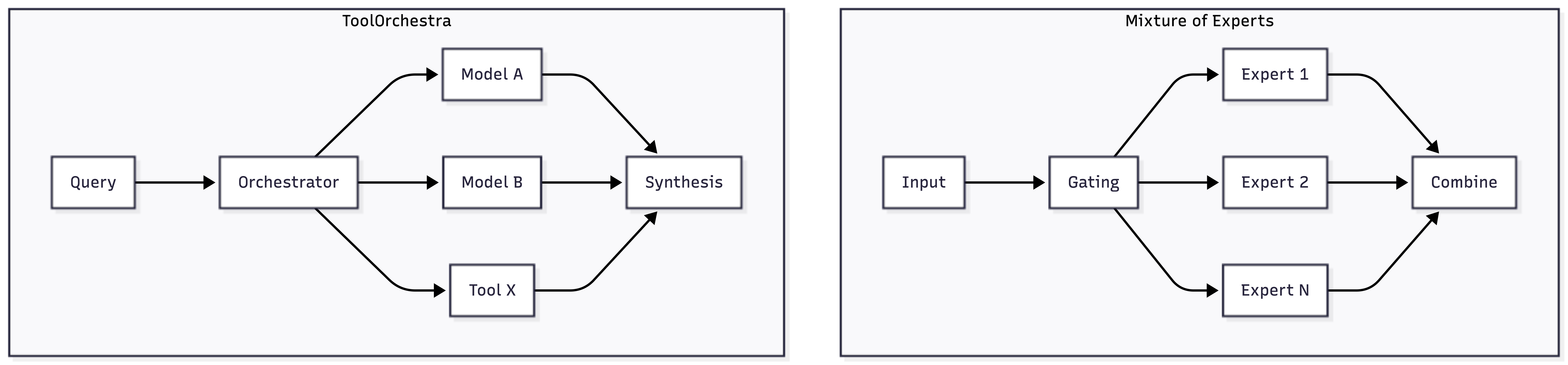
Commonalities and Shared Principles
Both architectures attack the same problem: inefficiency. Running a massive model for every task wastes compute and money. MoE and ToolOrchestra both use sparsity and specialization to avoid this waste.
Shared design principles:
- Routing as a core mechanism – Both use learned routing to direct inputs to the right specialists
- Modularity – Break down monolithic systems into specialized components
- Sparsity – Activate only what you need for each input
- Automatic learning – Routing policies are learned, not hardcoded
- Specialization over generalization – Focused experts outperform generalists on specific tasks
Related Architectural Methods
Several other patterns fit into this landscape of modular, routing-based intelligence. Let me walk you through the key ones.
Before diving into the specific architectures, I want to mention that I've written extensively about AI infrastructure and optimization techniques. If you're interested in understanding how these architectural patterns work in production environments, check out my article on NVIDIA MIG with GPU Optimization in Kubernetes, which covers how GPU partitioning works similarly to expert routing in MoE systems.
Ensemble Methods
Ensemble learning combines predictions from multiple models. Unlike MoE, where routing is learned, ensembles often use simpler combination strategies.
Common ensemble techniques:
| Technique | How It Works | Best For |
|---|---|---|
| Bagging | Train on different data subsets | Reducing variance |
| Voting | Majority vote or averaging | Classification tasks |
| Stacking | Meta-learner combines predictions | Complex problems |
| Weighted Average | Learned weights for each model | Regression tasks |
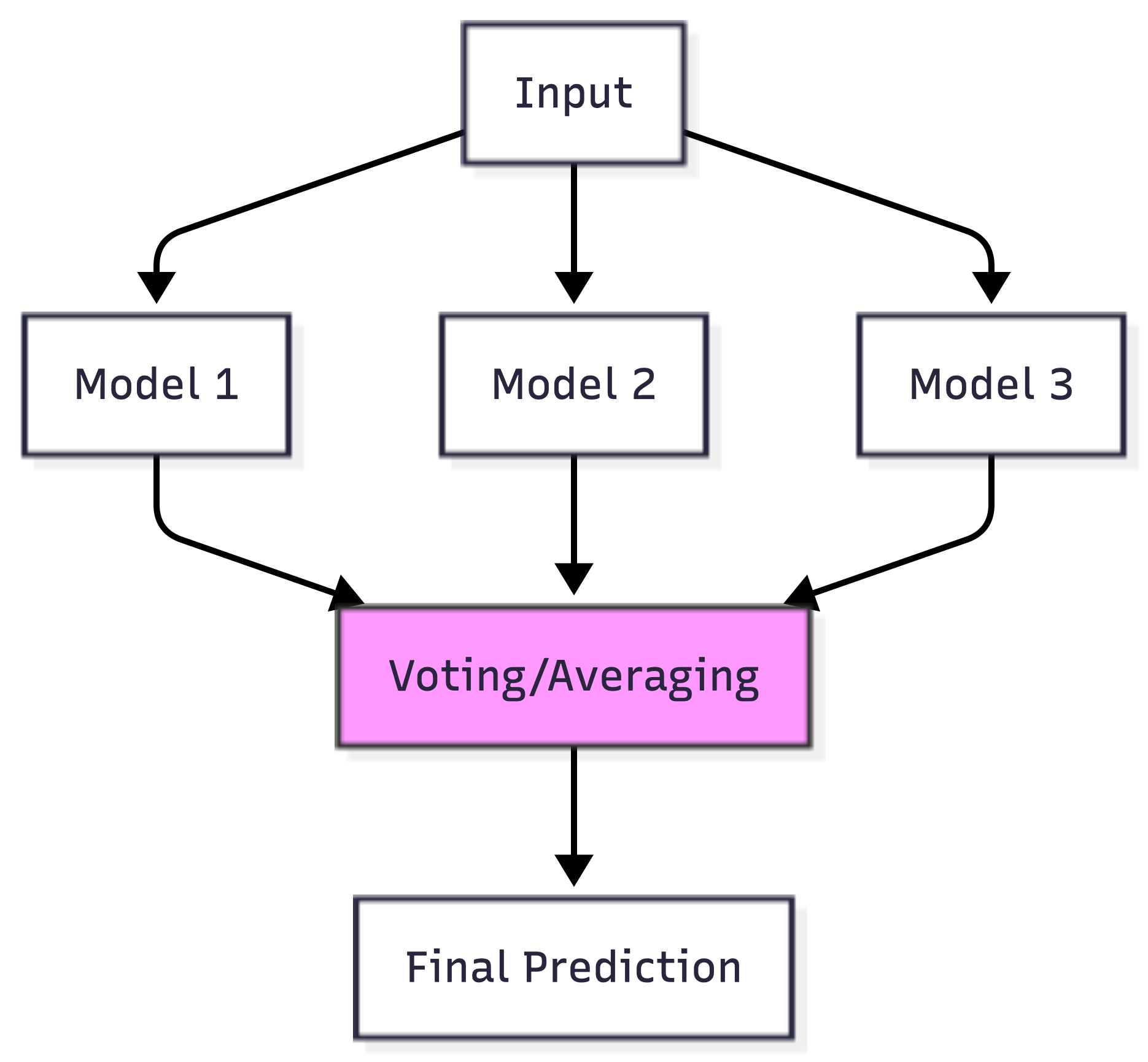
The key difference from MoE is that ensemble methods typically run all models for every input, then combine results. MoE only activates selected experts. Ensemble methods are simpler to implement but less efficient.
Capsule Networks With Dynamic Routing
Capsule Networks, introduced by Geoffrey Hinton in 2017, use a routing mechanism called "routing-by-agreement." While different from MoE and orchestration, capsules share the idea of learned routing.
How capsule routing works:
Instead of routing tokens to experts, capsules route outputs to higher-level capsules based on agreement. Lower-level capsules send their output vectors to higher-level capsules that "agree" with their predictions.
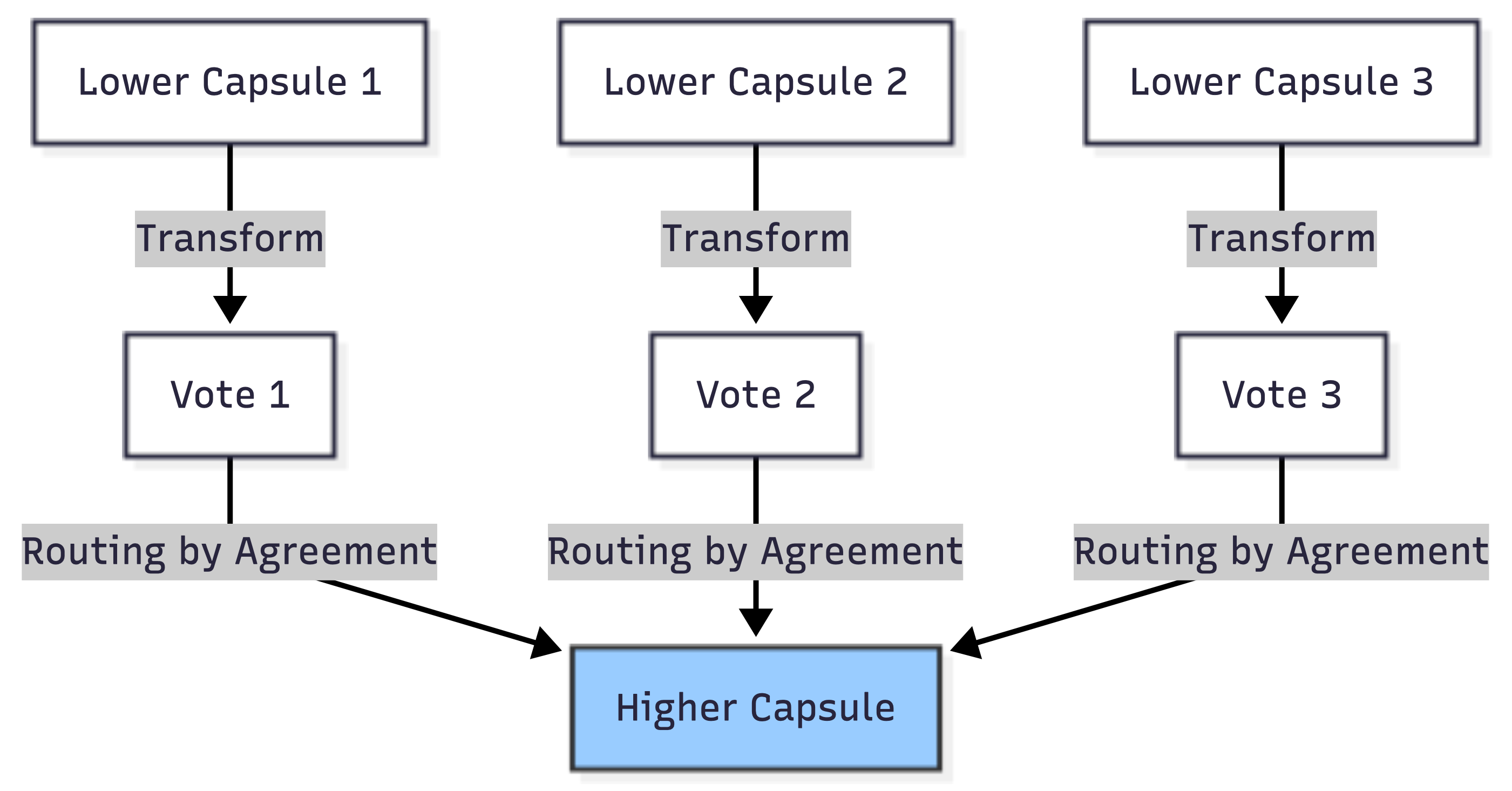
Key concepts:
- Capsules as vectors: Unlike neurons that output scalars, capsules output vectors. The length represents probability, the direction represents properties.
- Dynamic routing: Iteratively updates routing coefficients based on agreement between predictions
- Spatial relationships: Better at understanding part-whole relationships in images
| Feature | Traditional CNN | Capsule Network |
|---|---|---|
| Output | Scalar activations | Vector capsules |
| Routing | Fixed pooling | Dynamic routing |
| Spatial Info | Lost through pooling | Preserved in vectors |
| Iterations | None | 3-5 routing iterations |
Multi-Agent Neural Systems
These architectures organize intelligence as multiple cooperating agents. Each agent is a specialized neural network that communicates with others.
Agent-based architectures:
- Modular Graph Neural Networks (ModGNN) – Agents communicate through graph structures for multi-agent coordination
- Neural Agent Networks (NAN) – Distributed systems where agents act like neurons
- Agentic Neural Networks – Self-evolving systems that optimize both structure and prompts
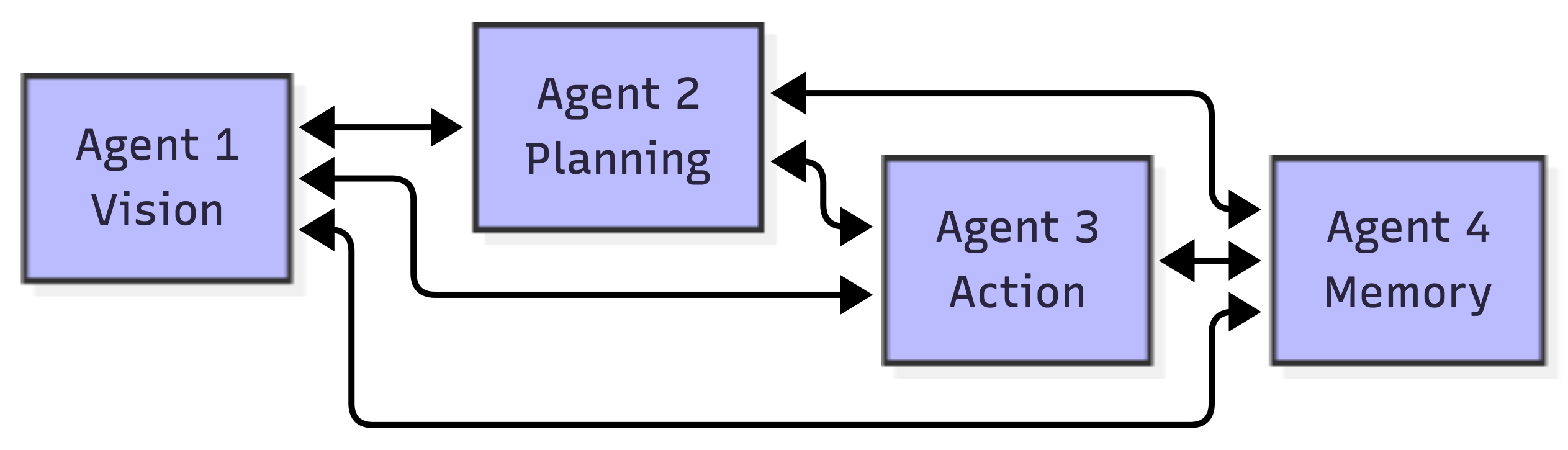
Comparison with MoE and Orchestration:
| Architecture | Communication | Independence | Training |
|---|---|---|---|
| MoE | Through gating | Sub-networks | Joint |
| ToolOrchestra | Through orchestrator | Fully independent | Separate |
| Multi-Agent | Peer-to-peer | Semi-independent | Can be joint or separate |
Hierarchical Mixture of Experts
HMoE adds layers to the basic MoE pattern. First-level routing decides broad categories, then second-level routing picks specific experts.
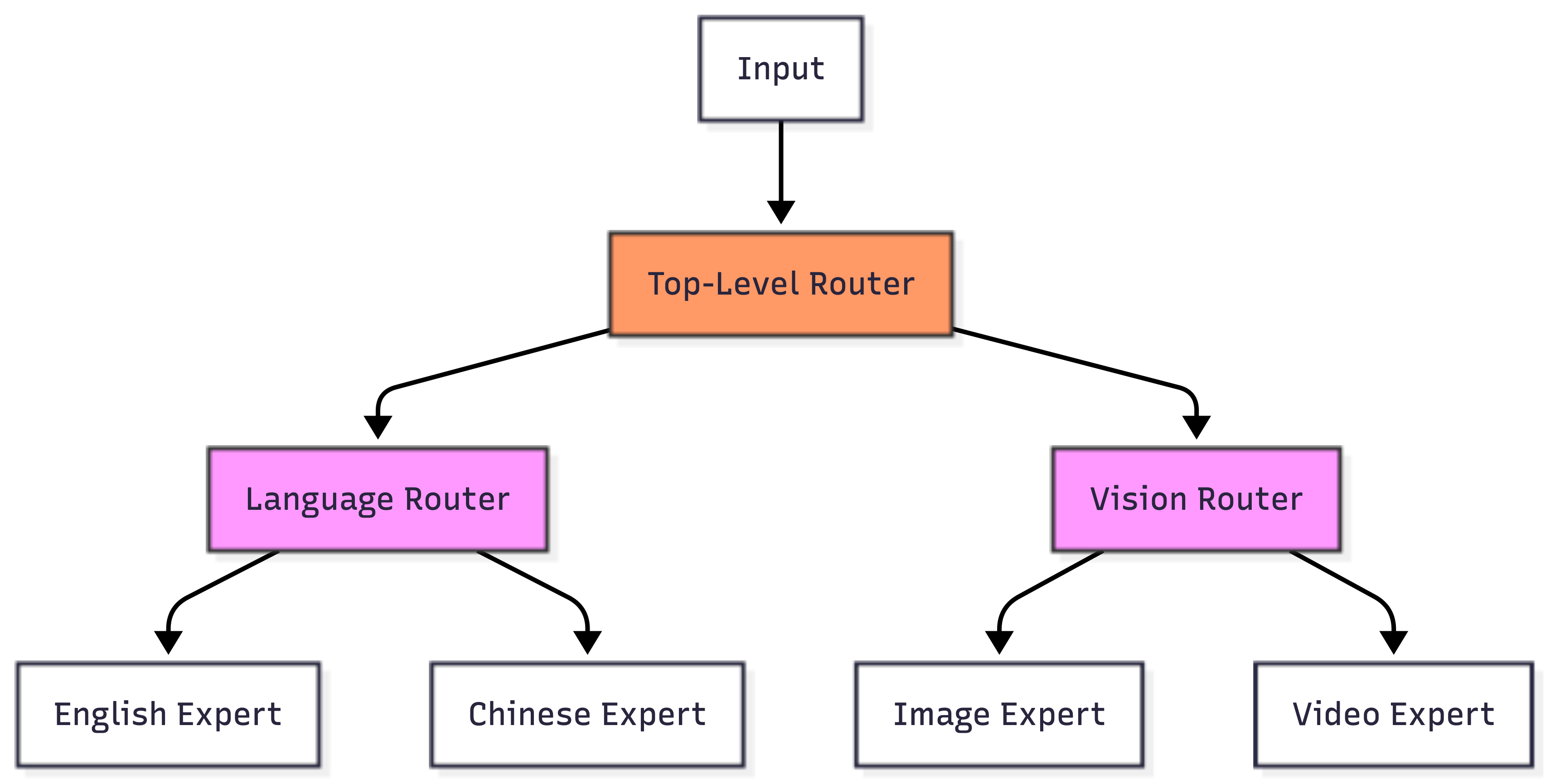
This pattern is similar to ToolOrchestra's hierarchical potential. Both can build multi-level routing systems.
Retrieval-Augmented Generation (RAG)
RAG combines language models with retrieval systems. Before generating, the system searches a database for relevant information.
RAG architecture:
| Component | Purpose | Similar To |
|---|---|---|
| Query Encoder | Transform input | MoE gating |
| Retriever | Find relevant docs | Tool selection |
| Reader/Generator | Produce answer | Expert activation |
RAG is closer to orchestration than MoE. The retriever acts like a tool, and the generator coordinates between input and retrieved knowledge.
Compound AI Systems
Compound AI Systems, as defined by Berkeley AI Research, tackle tasks using multiple interacting components. This is the broad category that includes both orchestration and some ensemble methods.
I recently wrote about the Model Context Protocol (MCP), which is Anthropic's approach to standardizing how AI systems connect with external data sources. MCP represents a compound AI pattern where models orchestrate access to various data sources through a universal protocol. The principles align closely with ToolOrchestra's approach to coordinating multiple tools.
Characteristics:
- Multiple model calls in sequence or parallel
- External tools (databases, APIs, code execution)
- Retrieval and generation combined
- Multi-step reasoning chains
Examples:
- Chain-of-Thought systems – Break problems into reasoning steps
- ReAct (Reasoning + Acting) – Combine reasoning with tool use
- AutoGPT-style agents – Autonomous task decomposition and execution
Neural-Symbolic Architectures
These systems integrate neural networks with symbolic reasoning. The neural part handles pattern recognition, the symbolic part handles logical reasoning.
Layered architecture:
| Layer | Type | Function |
|---|---|---|
| Perception | Neural | Process sensory input |
| Reasoning | Symbolic | Apply logical rules |
| Planning | Hybrid | Combine both approaches |
This is similar to orchestration, where different tools have different capabilities. The routing decides whether to use neural or symbolic processing.
Comparison Table: All Architectures
| Architecture | Routing Type | Components | Training | Best Use Case |
|---|---|---|---|---|
| MoE | Token-level, learned | Sub-networks | Joint | Parameter efficiency |
| ToolOrchestra | Task-level, learned | Independent systems | Orchestrator only | Flexible composition |
| Ensemble | No routing / simple | Independent models | Separate | Reducing variance |
| Capsule Networks | Agreement-based | Vector capsules | Joint | Spatial relationships |
| Multi-Agent | Peer communication | Autonomous agents | Joint or separate | Complex coordination |
| HMoE | Multi-level, learned | Hierarchical experts | Joint | Nested specialization |
| RAG | Query-based | Retriever + Generator | Separate | Knowledge grounding |
| Compound AI | Multi-step | Chains of components | Mixed | Complex workflows |
Implementation Considerations
When building systems with these architectures, keep these points in mind:
When to use MoE:
- Training massive models from scratch
- Need parameter efficiency at inference
- Single model deployment preferred
- Have expertise in distributed training
When to use ToolOrchestra:
- Building applications with existing models
- Need to swap components frequently
- Want to use external tools (APIs, databases)
- Prefer faster iteration and easier maintenance
When to use ensembles:
- Have multiple trained models
- Want simple implementation
- Can afford running all models
- Need variance reduction
When to use multi-agent:
- Complex coordination needed
- Agents should learn from each other
- Real-time communication required
- Distributed decision making
For those interested in the infrastructure side of deploying these architectures, I've written several articles that might help. My piece on Multizone Kubernetes and VPC Load Balancer Setup shows how to deploy distributed systems across zones, which is similar to how you'd deploy multiple experts or orchestrated models.
I've also published guides on DZone about cloud infrastructure and automation that apply directly to deploying these kinds of systems.
Conclusion
The trend is clear: break things into specialized components, learn to route intelligently, activate only what you need. Whether that specialization happens inside a model through MoE, across models through orchestration, or through multi-agent coordination, the principle holds.
Emerging patterns:
- Multi-level routing – Orchestration at application level, MoE at model level, capsule-like routing for spatial features
- Dynamic expert creation – Models that spawn new experts as needed based on task distribution
- Cross-architecture routing – Systems that route between fundamentally different architectures (transformers, RNNs, symbolic systems)
- Learned cost functions – Systems that optimize for user-specific cost/quality tradeoffs
- Federated orchestration – Orchestrators coordinating models across different organizations
Research directions:
- Better routing algorithms that generalize across domains
- Automatic architecture search for routing patterns
- Efficient training methods for sparse systems
- Theoretical understanding of when routing helps
- Combining symbolic and neural routing
Key Takeaways
If you've made it this far, here's what you should remember:
- MoE splits parameters, ToolOrchestra splits tasks, Ensembles split predictions, and multi-agents split responsibilities. All use routing, but at different levels and for different purposes.
- They complement each other. An orchestrator can coordinate MoE models. Capsule networks can use MoE-style experts. Multi-agent systems can use orchestration for high-level coordination. The combinations are endless.
- The future is modular. Neither approach alone is the answer. The next generation of systems will use multiple levels of routing and specialization working together.
- Start small, scale up. You don't need to build everything at once. Start with simple routing logic. Add specialized components. Layer on complexity as you learn what works.
This isn't just about saving compute. It's about making intelligence more accessible, more controllable, and more aligned with how we actually want to use it. Breaking monolithic systems into specialized, coordinated components is how we'll build the next generation of AI.
For those just starting their AI journey, my Awesome-AI guide provides a comprehensive roadmap for mastering machine learning and deep learning, which forms the foundation for understanding these advanced architectures.
Further reading:
- ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration (Su et al., NVIDIA, November 2025) — The foundational paper introducing orchestration with RL
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Fedus et al., Google Research, 2021) — Pioneering work on MoE scaling
- Dynamic Routing Between Capsules (Sabour et al., Hinton, 2017) — Introduction to capsule networks and routing-by-agreement
- The Shift from Models to Compound AI Systems (Zaharia et al., Berkeley AI Research, 2024) — Defining compound AI systems
- Compound AI Systems Optimization: A Survey (Lee et al., 2025) — Comprehensive survey of optimization methods
- Optimizing Model Selection for Compound AI Systems (Chen et al., Stanford/Berkeley, 2025) — LLMSelector framework
- Towards Resource-Efficient Compound AI Systems (Chaudhry et al., 2025) — Resource optimization approaches
Opinions expressed by DZone contributors are their own.
Comments