AI Infrastructure: Compute, Storage, Observability, Security, and More
In this final article, you will learn about AI infrastructure compute, storage, observability, optimization, security, and deployment architecture.
Join the DZone community and get the full member experience.
Join For FreeIn this third article of the AI infrastructure series, you will learn about AI infrastructure compute, storage, observability, performance, optimization (deep dive), and security. This is the final part in my three-part AI infrastructure series. It's recommended to read the previous two articles published on DZone:
- AI Infrastructure for Agents and LLMs: Options, Tools, and Optimization
- AI Infrastructure Guide: Tools, Frameworks, and Architecture Flows
Compute Layer Architecture
The Compute Layer provides the raw processing power needed for AI workloads, with specialized considerations for GPU management, resource allocation, and workload scheduling. This layer must handle the unique characteristics of AI workloads: high memory requirements, long-running processes, and dynamic resource needs.
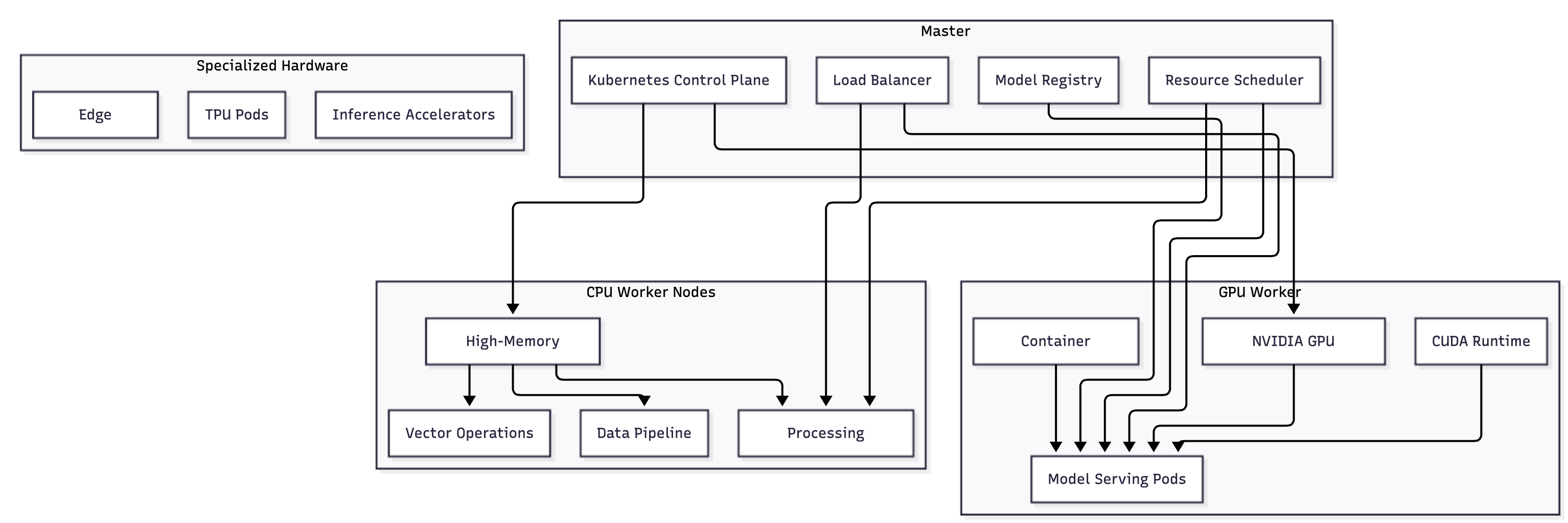
GPU Resource Management
GPU scheduling strategies: Modern AI workloads require sophisticated GPU scheduling that goes beyond simple device allocation. Key considerations include:
GPU sharing: Multiple inference workloads can often share a single GPU, especially for smaller models or during low-traffic periods. NVIDIA's Multi-Process Service (MPS) enables fine-grained GPU sharing with memory and compute isolation between processes.
Multi-GPU coordination: Large models require tensor parallelism across multiple GPUs. The scheduler must ensure that related GPU allocations are made on the same node or nodes with high-bandwidth interconnects (NVLink, InfiniBand).
Dynamics scaling: GPU resources are expensive and should be efficiently utilized. Dynamic scaling systems monitor inference queue depths and automatically scale GPU allocations based on demand patterns.
Sample configuration for GPU resource management:
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
spec:
hard:
requests.nvidia.com/gpu: "8"
limits.nvidia.com/gpu: "8"
---
apiVersion: v1
kind: LimitRange
metadata:
name: gpu-limit-range
spec:
limits:
- default:
nvidia.com/gpu: "1"
defaultRequest:
nvidia.com/gpu: "1"
type: ContainerMemory and Storage Optimization
Model loading strategies: Large language models can consume hundreds of gigabytes of memory, making efficient loading strategies critical for system performance and cost optimization.
Memory mapping: Loading models using memory-mapped files allows multiple processes to share the same model weights in memory, reducing overall memory usage and enabling faster startup times for new inference processes.
Model sharding: Distributing model weights across multiple devices or nodes enables serving of models larger than single-device memory capacity. This requires sophisticated orchestration to ensure consistent model state across shards.
Quantization integration: Runtime quantization can significantly reduce memory requirements while maintaining acceptable accuracy. Integration with quantization libraries like BitsAndBytes or GGML enables dynamic precision adjustment based on available resources.
Storage Infrastructure Flow
Storage architecture for AI applications encompasses multiple tiers of storage with different performance, capacity, and cost characteristics. The challenge lies in optimizing data placement and access patterns to minimize latency while controlling costs.
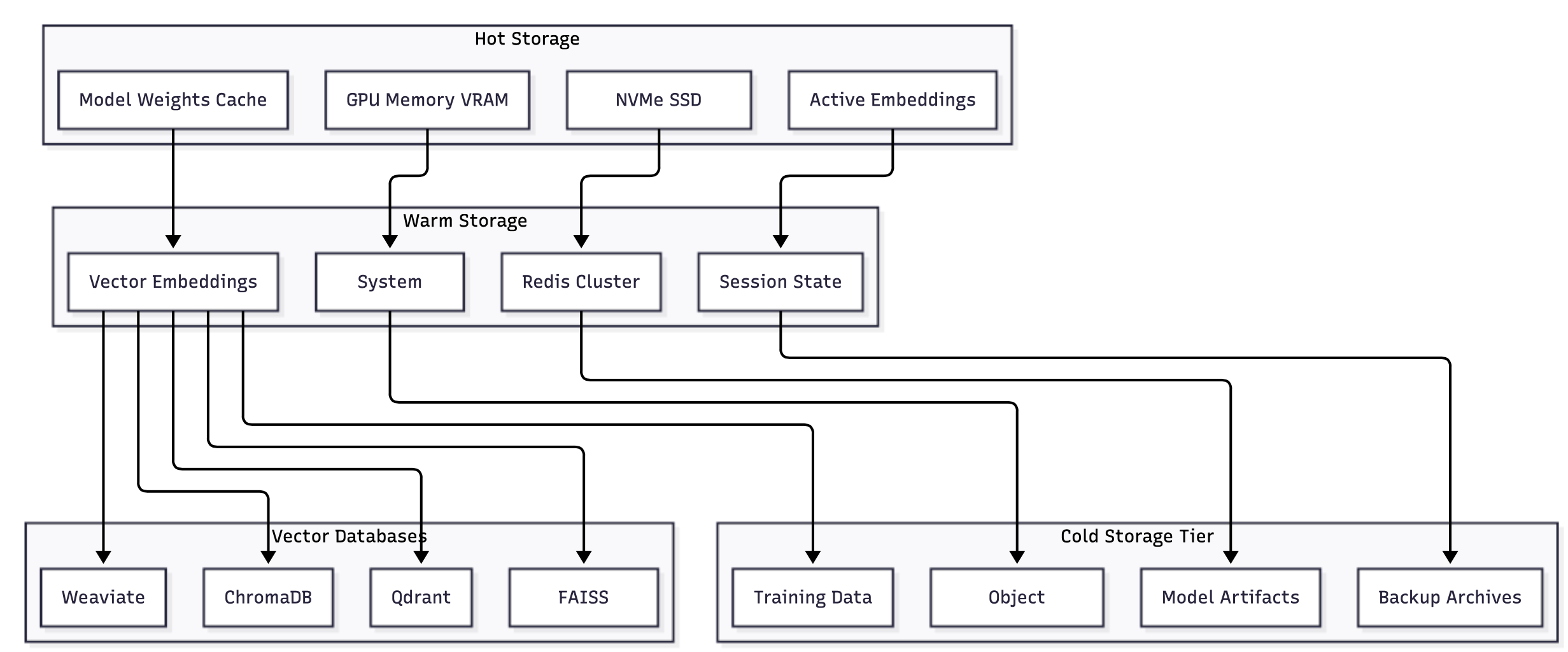
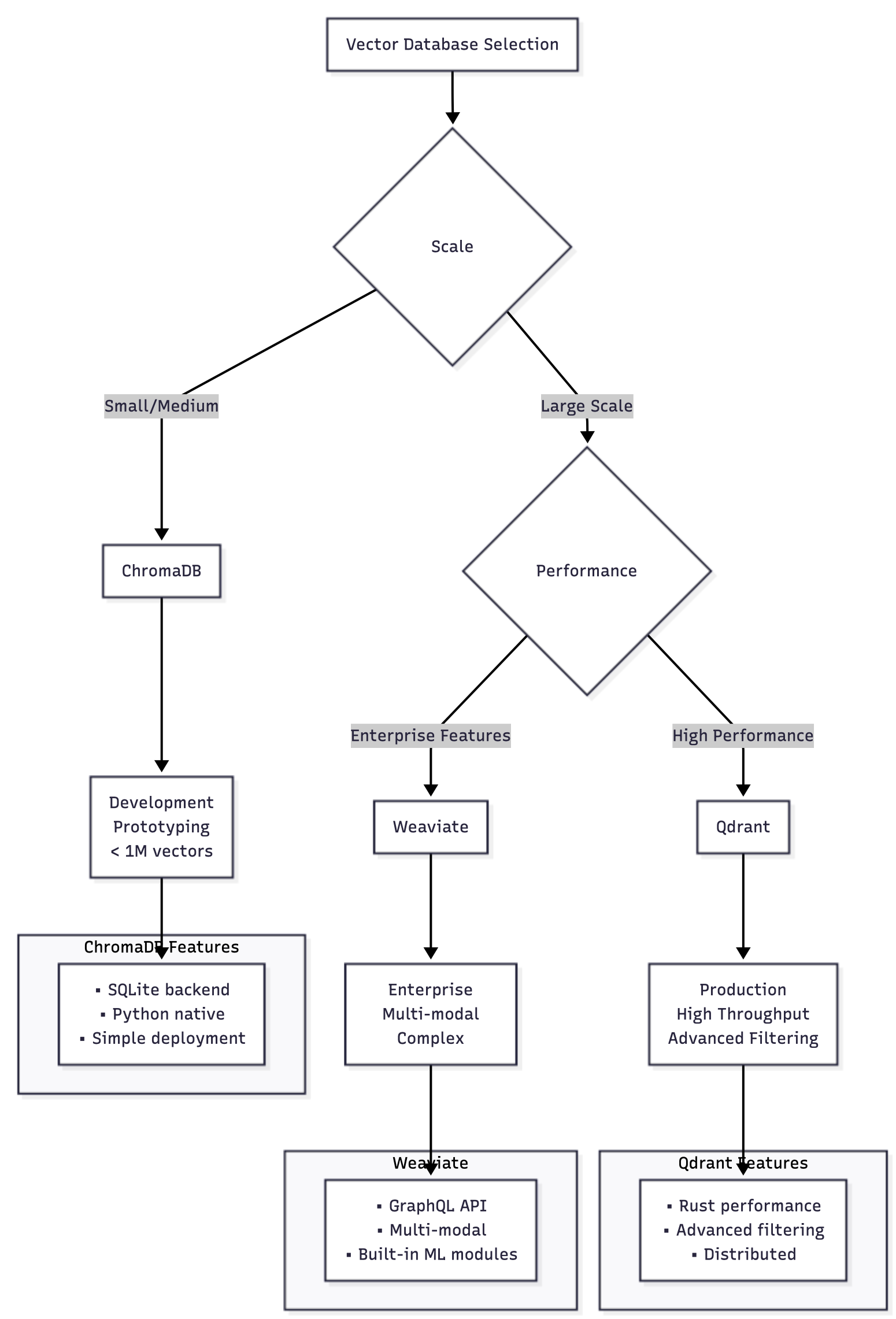
Vector Database Architecture and Selection
ChromaDB has gained popularity for its simplicity and excellent Python integration. It's particularly well-suited for development and small to medium-scale deployments where ease of use is prioritized over maximum performance. ChromaDB's persistent storage and built-in embedding functions make it an excellent choice for RAG applications.
Qdrant excels in production environments requiring high performance and advanced filtering capabilities. Its Rust-based implementation provides excellent performance characteristics, while its rich query language supports complex filtering operations that are essential for large-scale applications.
Qdrant's payload indexing allows for sophisticated filtering that combines vector similarity with structured data queries, making it ideal for applications where vector search must be combined with traditional database operations.
Weaviate provides advanced features like hybrid search (combining vector and keyword search), multi-modal capabilities, and built-in machine learning modules. Its GraphQL API makes it particularly attractive for applications requiring flexible query patterns and real-time data access.
Vector Database Selection Guide
Caching Strategies and Implementation
Multi-level caching: AI applications benefit from sophisticated caching strategies that consider the different characteristics of various data types:
Model weight caching: Model weights change infrequently but are expensive to load. Implementing intelligent caching that considers model usage patterns and available memory can significantly improve system performance.
Embedding caching: Vector embeddings are computationally expensive to generate but highly reusable. Caching strategies should consider both exact matches and approximate similarity to maximize cache hit rates.
Response caching: For applications with repeated queries, response caching can dramatically reduce computational costs. However, caching strategies must consider the non-deterministic nature of many AI models and implement appropriate cache invalidation strategies.
Monitoring and Observability Stack
Observability for AI systems requires specialized metrics, tracing capabilities, and alerting strategies that account for the unique characteristics of AI workloads. Traditional application monitoring approaches must be extended to capture AI-specific performance indicators and failure modes.
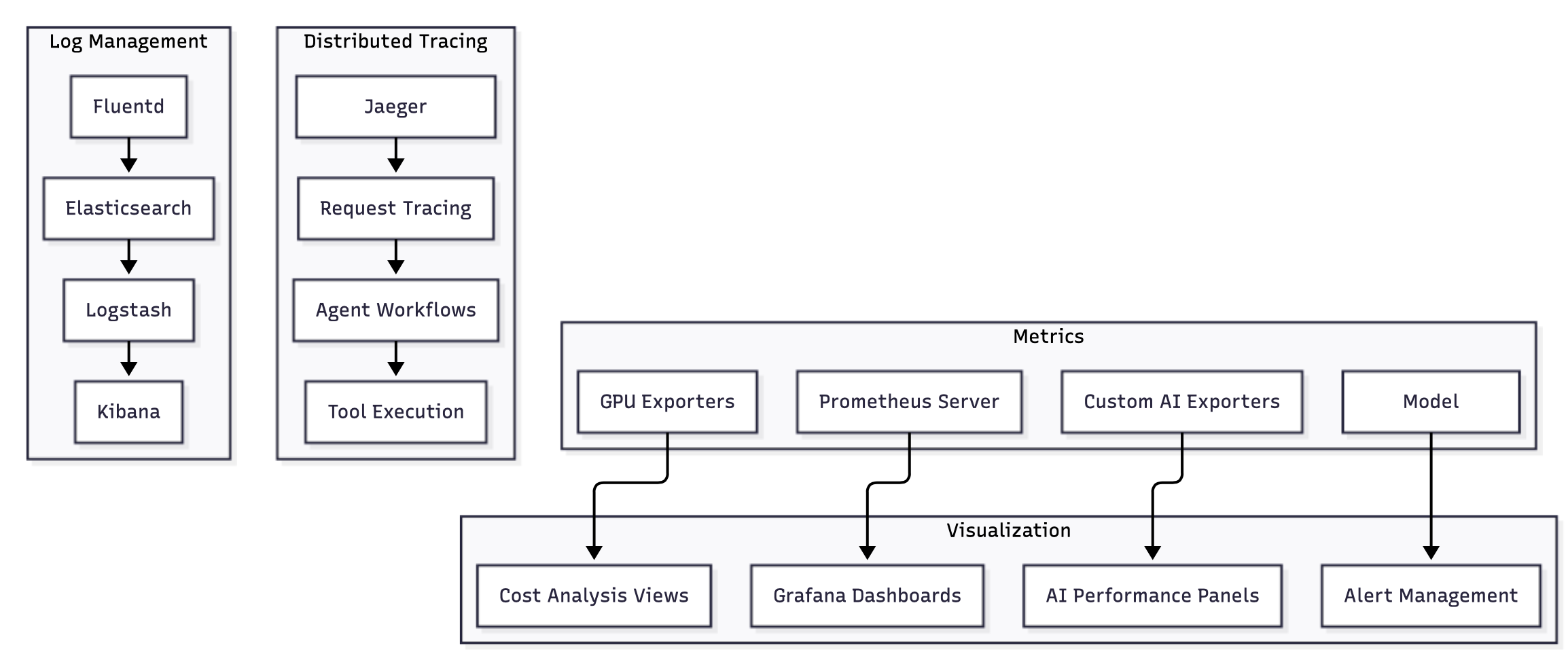
AI-Specific Metrics and KPIs
Performance metrics: AI applications require specialized performance metrics that capture both system-level and application-level performance:
Inference latency distribution: Unlike traditional web applications, where response times are relatively uniform, AI applications can have highly variable latency depending on input complexity, model size, and current system load. Monitoring should capture not just averages but full latency distributions.
Token throughput metrics: For language models, token-based metrics provide more meaningful insights than request-based metrics. Key metrics include:
- Tokens per second per GPU
- Time to first token (TTFT)
- Inter-token latency for streaming responses
- Queue time vs. processing time breakdown
GPU utilization patterns: GPU monitoring must go beyond simple utilization percentages to include:
- Memory bandwidth utilization
- Compute vs. memory-bound operation identification
- Multi-GPU coordination efficiency
- Power consumption and thermal management
Model quality metrics: Production AI systems need continuous monitoring of model quality and performance degradation:
- Response relevance scores
- Hallucination detection
- Bias and fairness metrics
- User satisfaction indicators
Distributed Tracing for AI Workflows
Request journey tracking: AI applications often involve complex workflows with multiple service interactions. Distributed tracing provides visibility into:
- Complete request lifecycle from user input to final response
- Service interaction patterns and dependencies
- Performance bottlenecks across service boundaries
- Error propagation and failure analysis
Agent decision tracing: For AI agent applications, tracing must capture the decision-making process:
- Planning phase duration and complexity
- Tool selection and execution patterns
- Reasoning chain analysis
- Memory access and update patterns
OpenTelemetry integration: Standardizing on OpenTelemetry provides vendor-neutral observability with rich semantic conventions for AI applications:
from opentelemetry import trace
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# Configure tracing for AI applications
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
jaeger_exporter = JaegerExporter(
agent_host_name="jaeger",
agent_port=6831,
)
span_processor = BatchSpanProcessor(jaeger_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
# Trace AI inference requests
with tracer.start_as_current_span("ai_inference") as span:
span.set_attribute("model.name", "llama-2-70b")
span.set_attribute("input.tokens", token_count)
span.set_attribute("inference.batch_size", batch_size)
result = model.generate(prompt)
span.set_attribute("output.tokens", len(result.tokens))
span.set_attribute("inference.latency_ms", result.latency)Alerting Strategies for AI Systems
Threshold-based slerts: Traditional alerting approaches must be adapted for AI systems:
- Dynamic thresholds: AI performance can vary significantly based on input complexity and system load
- Composite metrics: Alerts should consider multiple factors simultaneously (latency, accuracy, resource utilization)
- Context-aware alerting: Different alert thresholds for different model types or use cases
Anomaly detection: Machine learning-based anomaly detection is particularly valuable for AI systems:
- Performance anomalies: Detecting unusual patterns in inference latency or throughput
- Quality degradation: Identifying gradual degradation in model outputs
- Resource usage anomalies: Detecting unusual GPU utilization or memory consumption patterns
Predictive alerting: Advanced monitoring systems can predict issues before they impact users:
- Capacity planning: Predicting when additional resources will be needed
- Performance degradation: Early warning of model performance issues
- Cost optimization: Identifying opportunities for resource optimization
Essential Open Source Tool Matrix
Understanding the landscape of open-source tools is crucial for building cost-effective, maintainable AI infrastructure. Each tool category serves specific needs and has different trade-offs in terms of performance, features, and operational complexity.
Model Serving Frameworks Comparison

vLLM Performance Characteristics
vLLM's PagedAttention algorithm provides significant advantages for memory-constrained deployments. In benchmark tests, vLLM consistently achieves 2-4x higher throughput compared to traditional serving frameworks when serving large language models. The continuous batching feature is particularly effective for applications with variable request arrival patterns, maintaining low latency even during traffic spikes.
TensorRT-LLM Optimization Pipeline
NVIDIA's TensorRT-LLM provides the highest performance for NVIDIA GPU deployments through extensive kernel optimization and fusion. The compilation process can reduce inference latency by 50-80% compared to unoptimized models, but requires significant upfront investment in model conversion and optimization.
The TensorRT-LLM workflow involves:
- Model conversion: Converting PyTorch/HuggingFace models to TensorRT format
- Engine building: Optimizing for specific hardware configurations
- Deployment: Serving optimized engines with custom runtime
Agent Framework Analysis
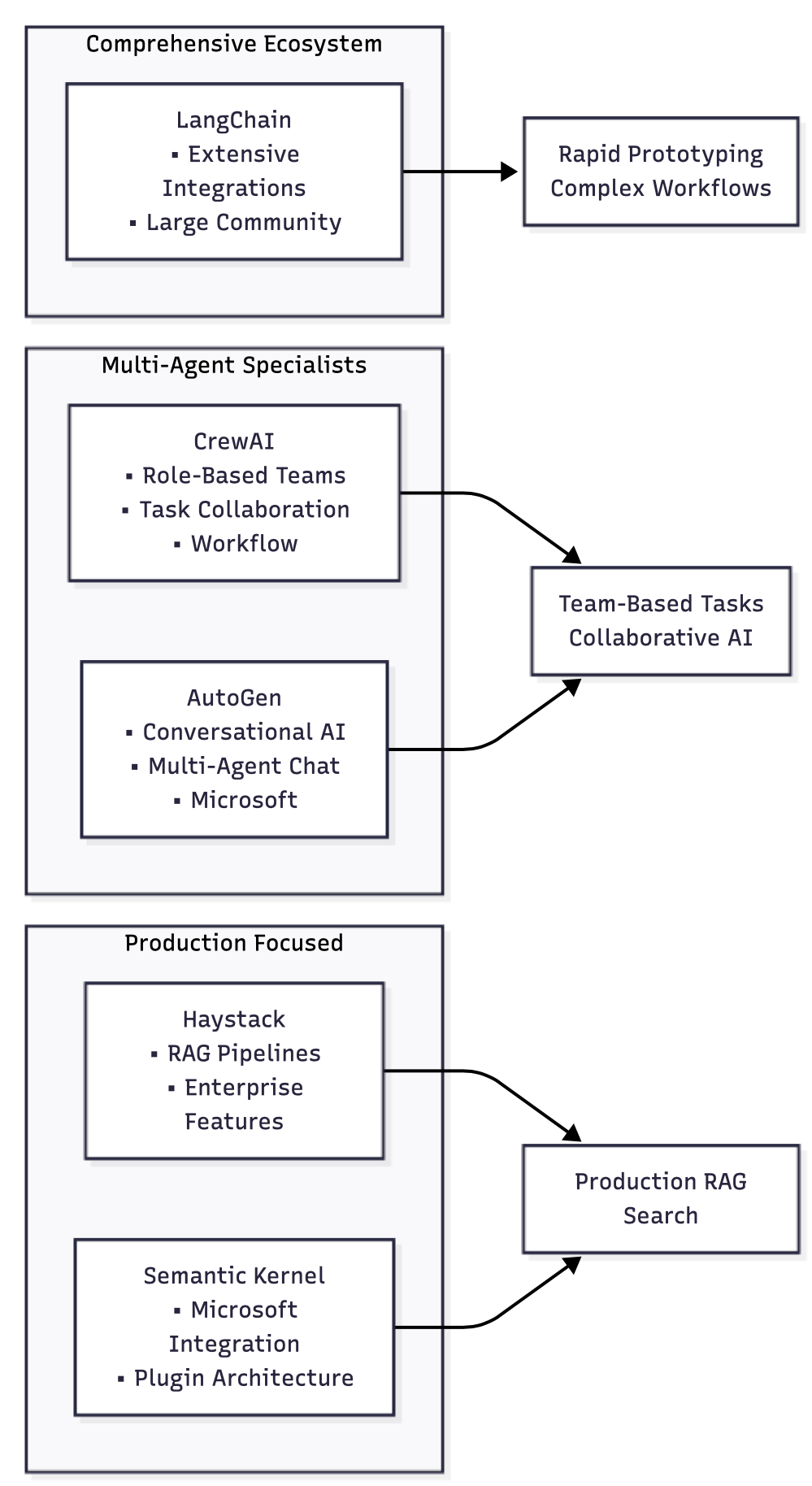
LangChain architecture deep dive: LangChain's modular architecture enables rapid development of complex AI applications through composable components. The framework's strength lies in its extensive ecosystem of integrations and pre-built components, but this can also lead to complexity and performance overhead in production environments.
Key architectural components:
- Chains: Deterministic workflows for common patterns
- Agents: Dynamic workflows that can adapt based on input
- Tools: Integrations with external services and APIs
- Memory: Persistent storage for conversation and application state
- Callbacks: Extensible hooks for monitoring and customization
CrewAI for multi-agent systems: CrewAI specializes in orchestrating teams of AI agents with different roles and capabilities. This approach is particularly effective for complex business processes that require multiple domain experts to collaborate on a solution.
CrewAI's architecture includes:
- Agents: Individual AI entities with specific roles and capabilities
- Tasks: Discrete work units that can be assigned to agents
- Crews: Teams of agents working together on related tasks
- Processes: Workflows that define how agents collaborate
Performance Optimization Deep Dive
Performance optimization for AI infrastructure requires understanding the unique characteristics of AI workloads and implementing optimizations across multiple layers of the technology stack.
Model Optimization Pipeline
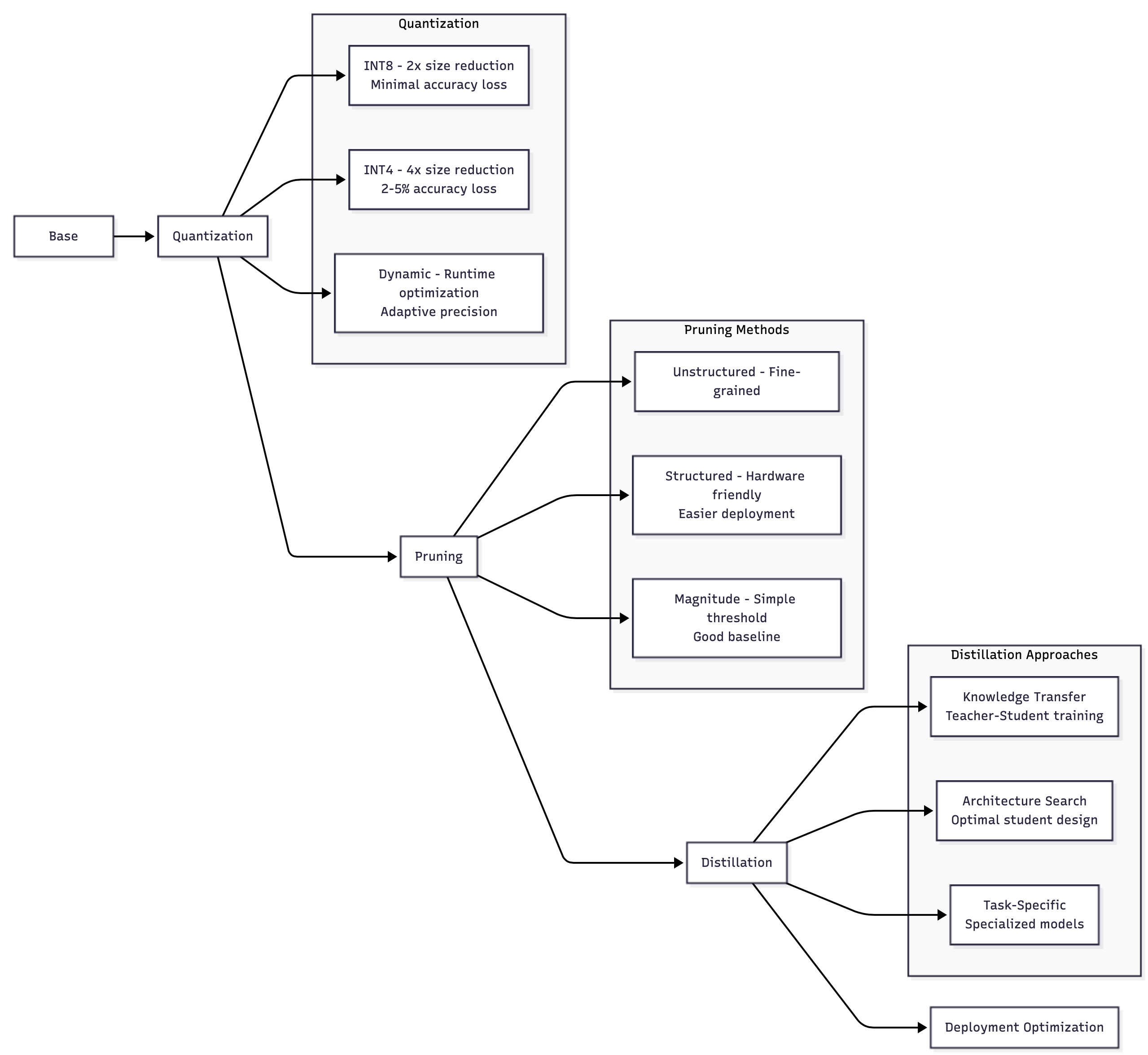
Quantization strategy selection: The choice of quantization technique depends on your specific performance requirements and accuracy constraints. INT8 quantization typically provides the best balance between performance improvement and accuracy preservation, while INT4 quantization offers maximum compression at the cost of some accuracy degradation.
Pruning implementation: Pruning removes unnecessary parameters from neural networks, reducing model size and computational requirements. Structured pruning removes entire neurons or channels, making it more hardware-friendly but potentially less effective than unstructured pruning.
Knowledge distillation workflows: Knowledge distillation enables the creation of smaller, faster models that maintain much of the performance of their larger counterparts. The process involves training a smaller "student" model to mimic the behavior of a larger "teacher" model.
Hardware Acceleration Optimization
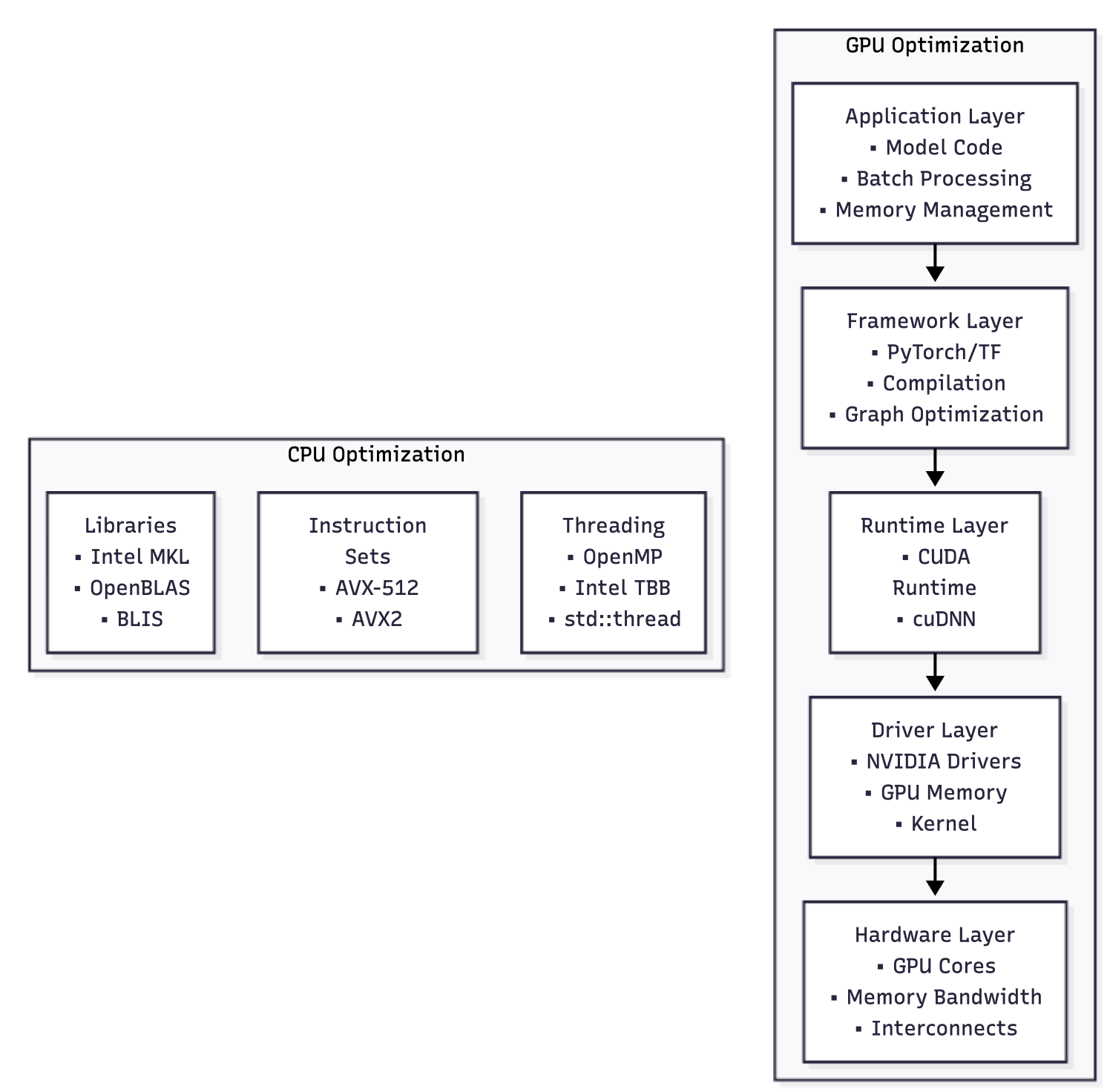
GPU memory optimization: GPU memory management is critical for AI workloads due to the large memory requirements of modern models. Effective strategies include:
Memory pooling: Pre-allocating large memory pools and managing allocation within the application reduces memory fragmentation and allocation overhead.
Gradient checkpointing: Trading computation for memory by recomputing intermediate activations during backward passes instead of storing them.
Model parallelism: Distributing model weights across multiple GPUs when models exceed single-GPU memory capacity.
GPU optimization example:
import torch
from torch.utils.checkpoint import checkpoint
class OptimizedModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layers = torch.nn.ModuleList([
TransformerBlock() for _ in range(32)
])
def forward(self, x):
# Use gradient checkpointing for memory efficiency
for layer in self.layers:
x = checkpoint(layer, x, use_reentrant=False)
return x
# Configure memory management
torch.cuda.empty_cache() # Clear cache
torch.backends.cuda.matmul.allow_tf32 = True # Enable TF32
torch.backends.cudnn.benchmark = True # Optimize for fixed input sizesCPU optimization strategies: While GPUs handle most AI inference workloads, CPUs remain important for preprocessing, postprocessing, and serving smaller models. Modern CPUs offer sophisticated instruction sets and parallel processing capabilities that can be leveraged for AI workloads.
Security and Compliance Framework
AI systems present unique security challenges that require specialized approaches beyond traditional application security. The combination of valuable intellectual property (models), sensitive user data, and complex attack surfaces requires comprehensive security strategies.
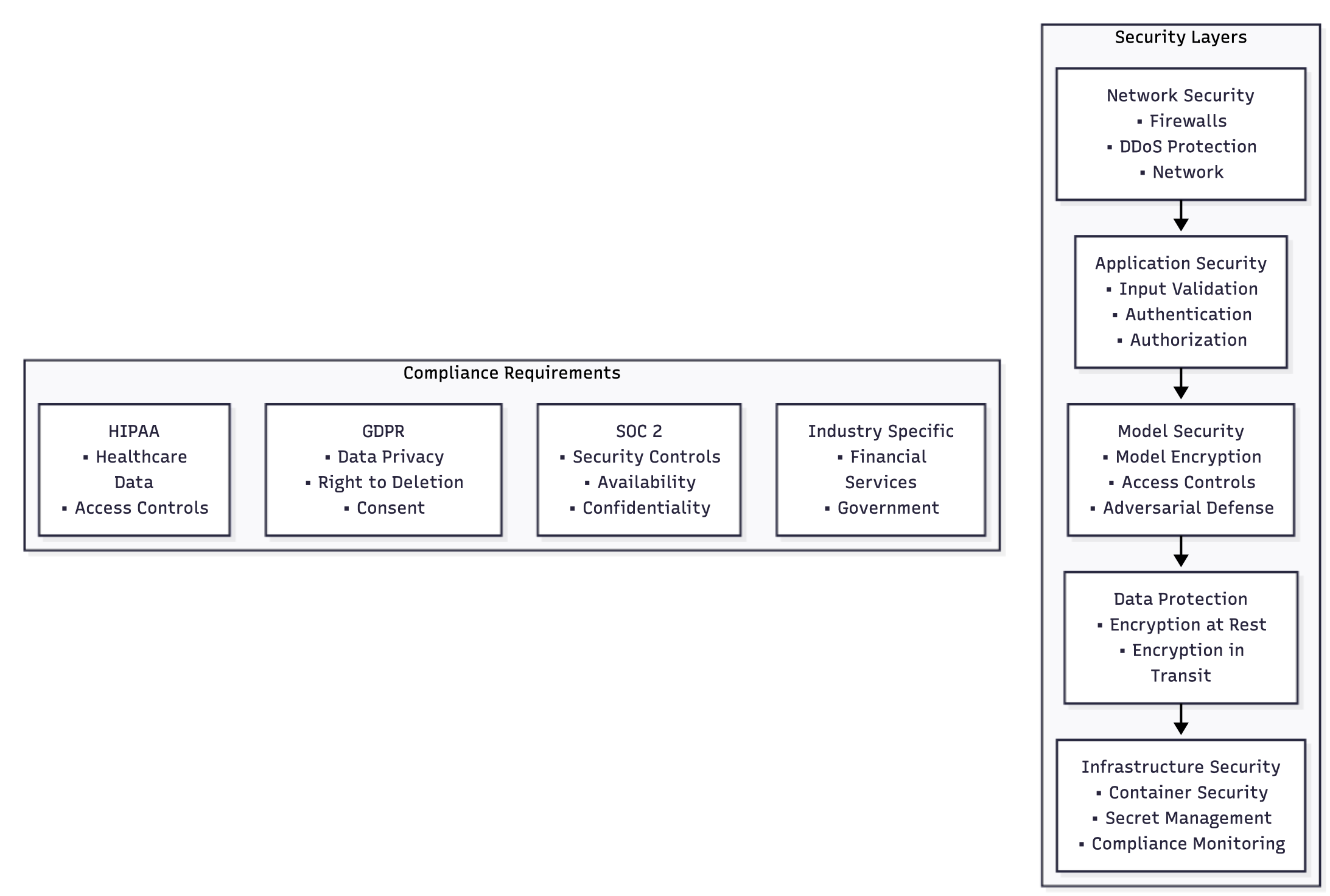
AI-Specific Security Considerations
Model protection: AI models represent significant intellectual property that must be protected from theft or unauthorized access. Protection strategies include:
Model encryption: Encrypting model weights both at rest and in transit prevents unauthorized access to model parameters. Hardware-based encryption using TPMs or HSMs provides additional security for high-value models.
Model watermarking: Embedding invisible watermarks in model outputs enables detection of unauthorized model usage or data extraction attacks.
Access controls: Implementing fine-grained access controls that limit model access based on user roles, API quotas, and usage patterns.
Adversarial attack defense: AI models are vulnerable to adversarial attacks, where maliciously crafted inputs can cause models to produce incorrect outputs. Defense strategies include:
Input sanitization: Implementing robust input validation that detects and filters potentially malicious inputs before they reach the model.
Adversarial training: Training models with adversarial examples to improve robustness against attack attempts.
Output monitoring: Implementing real-time monitoring of model outputs to detect unusual patterns that might indicate ongoing attacks.
Compliance and Governance
Data governance: AI systems must comply with various data protection regulations depending on their geographic scope and industry vertical. Key requirements include:
Data minimization: Collecting and processing only the minimum data necessary for the AI system to function effectively.
Purpose limitation: Ensuring that data is used only for the stated purposes and not for secondary uses without explicit consent.
Data retention: Implementing automated data lifecycle management that deletes personal data according to retention policies.
Production Deployment Patterns
Deploying AI systems in production requires sophisticated deployment strategies that handle the unique challenges of AI workloads: large model sizes, long startup times, and dynamic resource requirements.
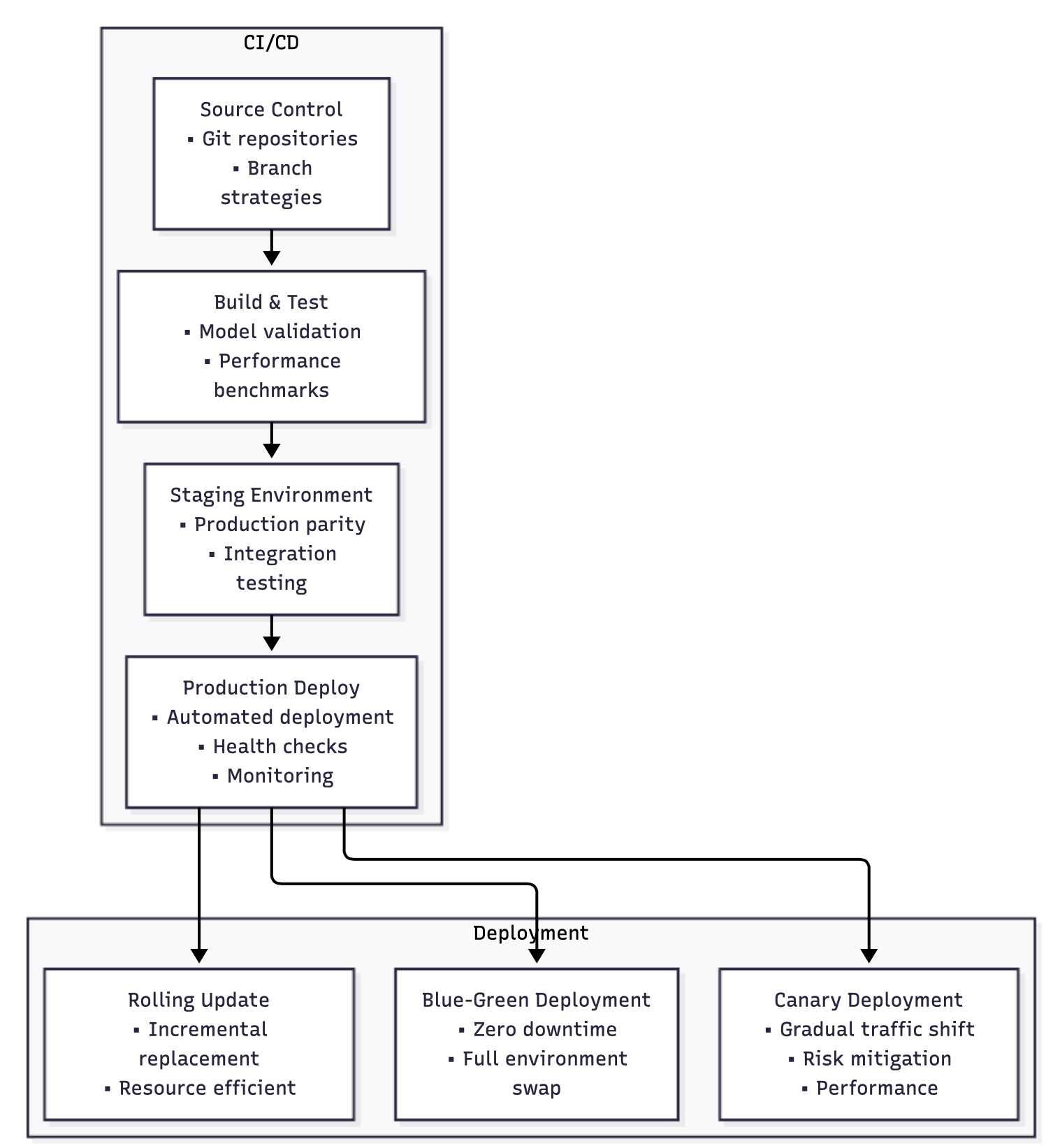
Advanced Deployment Strategies
Blue-green deployment for AI: Blue-green deployments are particularly valuable for AI applications because they enable testing of new models in production-like environments before switching traffic. However, AI applications require modifications to traditional blue-green patterns due to resource constraints and model loading times.
Model preloading: Ensuring that models are fully loaded and warmed up in the green environment before traffic switches to prevent cold start delays.
Gradual traffic migration: Instead of instant traffic switching, implementing gradual migration that monitors model performance and automatically rolls back if performance degrades.
Canary deployments with A/B testing: Canary deployments enable gradual rollout of new models while comparing performance against existing versions. For AI applications, this includes not just technical metrics but also quality metrics like response relevance and user satisfaction.
Multi-armed bandit: Implementing intelligent traffic distribution that automatically adjusts the percentage of traffic sent to different model versions based on performance feedback.
Quality monitoring: Real-time monitoring of model quality metrics during canary deployments, with automatic rollback if quality metrics fall below acceptable thresholds.
Model Version Management
Model registry integration: Production AI deployments require sophisticated model version management that tracks model lineage, performance metrics, and deployment history.
MLflow integration: Using MLflow Model Registry to manage model versions, stage transitions, and deployment approvals.
Future-Proofing Your AI Infrastructure
Along with compute, storage, observability, optimization, security, and deployment, as AI technology continues to evolve rapidly, building infrastructure that can adapt to new technologies and requirements is crucial for long-term success. This section explores emerging trends and architectural patterns that will shape the future of AI infrastructure.
Emerging Architecture Patterns
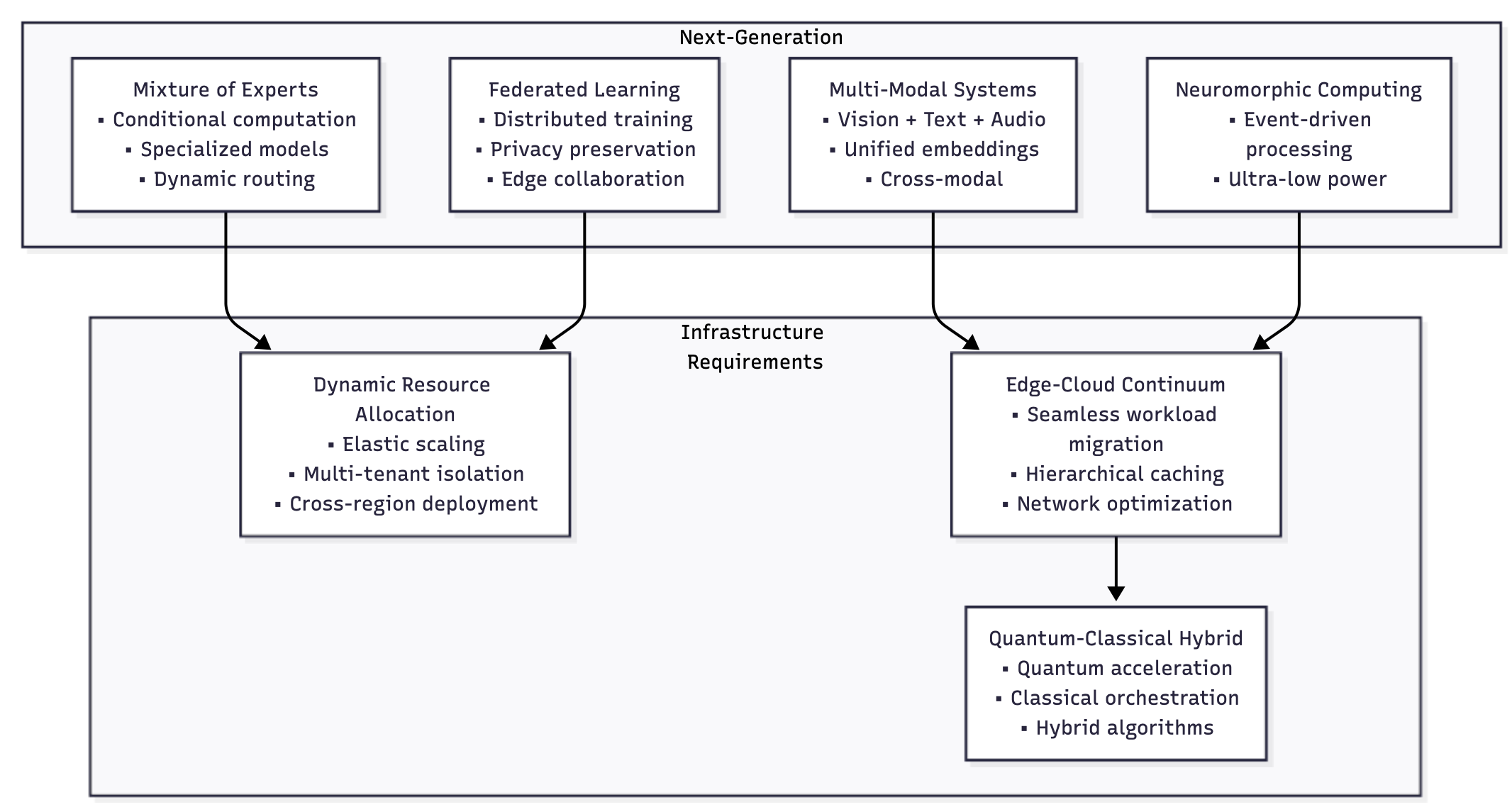
Mixture of Experts (MoE) infrastructure: MoE models require sophisticated routing and load balancing to efficiently distribute computations across different expert models. Infrastructure considerations include:
Expert load balancing: Ensuring that computational load is evenly distributed across different experts while maintaining the quality of expert selection.
Dynamic expert scaling: Scaling individual experts based on demand patterns and computational requirements without affecting the overall model performance.
Cross-expert communication: Managing the complex communication patterns between different experts while maintaining low latency and high throughput.
Technology Evolution and Adaptation
Quantum-classical integration: As quantum computing becomes more accessible, AI infrastructure will need to support hybrid quantum-classical workflows for specific optimization and machine learning tasks.
Neuromorphic computing integration: Event-driven neuromorphic processors offer ultra-low power consumption for inference workloads, particularly valuable for edge deployments and real-time applications.
Conclusion
The AI infrastructure landscape will continue to evolve rapidly, with new tools, frameworks, and architectural patterns emerging regularly. Success requires building systems that are both robust enough to handle production workloads and flexible enough to adapt to new requirements.
Focus on building strong foundations with proven open-source tools, implement comprehensive observability, and maintain a culture of continuous learning and improvement. The investment in solid infrastructure will enable your organization to take advantage of AI advances while maintaining reliable, scalable, and cost-effective operations.
Remember that the best AI infrastructure is the one that reliably serves your users while enabling your team to innovate and adapt to the rapidly evolving AI landscape. Start with your specific requirements, choose tools that match your team's capabilities, and build incrementally toward more sophisticated architectures as your needs and expertise grow.
This guide provides the roadmap, but your specific journey will depend on your unique requirements, constraints, and opportunities. Use this foundation to make informed decisions and build AI infrastructure that drives real business value while maintaining operational excellence.
Opinions expressed by DZone contributors are their own.
Comments