DevOps and Platform Engineering Readiness Checklist: Everything Needed for a Scalable, Secure, High-Velocity Delivery Platform
A practical checklist for platform engineering teams to improve DevOps, golden paths, reliability, governance, and developer experience at scale.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2026 Trend Report, Platform Engineering and DevOps: How Internal Platforms, Developer Experience, and Modern DevOps Practices Accelerate Software Delivery.
High-performing engineering organizations don’t scale through heroics. They scale through repeatable platform capabilities backed by evidence. This checklist reflects the shift from tool‑centric DevOps to product‑oriented platform engineering, focused on scale, reliability, and developer outcomes. It is intended for platform teams, cloud architects, and engineering leaders building internal developer platforms (IDPs) that deliver consistency, velocity, and control.
Architecture and Platform Foundations
Establishing standardized, versioned platform foundations makes workloads deployable, observable, and scalable by default while preventing drift and reducing risk.
- Core platform primitives are standardized: identity, networking, compute, storage, and secrets
- Standard blueprints exist and are version-controlled for common workloads with clear evolution paths
- Infrastructure is provisioned via reusable IaC modules with policy validation
- Environments and clusters follow consistent topology and access models
- Networking and service communication follow secure, consistent patterns
- Secrets and configurations are centrally managed and injected securely
- Architectures define scalability mechanisms and fault boundaries
- Resilience is built in through redundancy and failover
- Shared services are centrally managed with defined ownership and SLAs
- Platform capabilities are versioned for backward compatibility
Platform Ownership and Operating Model
A product‑oriented operating model enables scale without slowing teams. Define clear ownership, interfaces, and governance so the platform evolves without becoming a delivery bottleneck.
- A dedicated platform team owns roadmap, usability, reliability, and adoption
- Ownership boundaries are defined (platform standardizes; app teams own service logic)
- Platform capabilities are easy to discover and use (e.g., templates, workflows, golden paths)
- A structured intake and support model exists (e.g., requests, issues, exceptions)
- Standards are enforced with governed exceptions
- Platform success is measured through adoption and delivery outcomes
- Usage data and feedback drive continuous improvement
- Capabilities are versioned and evolved predictably
Environments and Golden Paths
Translate platform architecture into opinionated, self-service workflows driven by organizational standards that reduce complexity and enforce best practices by default. Golden paths are effective only when they are widely adopted.
- Environment conventions are standardized across naming, configuration, and access
- Environment state is enforced through IaC/GitOps to prevent drift
- Golden paths provide curated, reusable templates for common workloads
- Security, observability, and policy defaults are built into golden paths
- Golden paths balance strong defaults with controlled flexibility
- Self-service workflows enable scaffolding, provisioning, and deployment
- Environment lifecycle is automated across provisioning, promotion, and teardown
- Documentation and onboarding are well integrated into workflows
- Adoption is measured through usage and coverage
- Feedback and production learnings drive continuous evolution
Pipelines and Release Reliability
Standardize delivery pipelines so every change is validated, traceable, and safely releasable, making delivery more predictable and recoverable, not just faster.
- Pipelines follow a standardized flow: build, test, package, deploy, and promote
- Quality, security, and policy checks are embedded
- Artifact promotion across environments is controlled and consistent
- Each release produces traceable, auditable evidence
- Rollback and recovery paths are implemented and tested
- Failures provide fast, actionable diagnostics
- Reliability metrics are tracked (e.g., success rate, change failure, rollbacks)
- Release ownership and escalation paths are clearly defined
Toolchain and Self-Service Automation
Provide consistent self‑service automation through curated tools and embedded guardrails that reduce fragmentation, risk, and operational complexity.
- A unified developer point of entry exists through an IDP or developer portal
- Standard workflows exist for deployment, environment setup, and access
- Reusable modules and templates prevent copy-paste sprawl and reduce cognitive load
- Provisioning and deployments are automated with guardrails
- RBAC and approvals are embedded into automation
- High-risk actions require audited approvals
- Workflow reliability, usage, and failures are measured
- Automation evolves continuously based on usage and feedback
Observability and Operability
Embed observability and operational guardrails into self-service automation so systems are consistent, measurable, diagnosable, and operable by default.
- Logs, metrics, and traces are included by default through templates and golden paths
- Minimum observability standards are enforced for promotion
- Dashboards and alerts are preconfigured and actionable
- Telemetry supports debugging, capacity planning, and optimization
- Service health targets (e.g., SLOs) guide operations
- Operational ownership is defined across on-call, escalation, and boundaries
- Runbooks guide incident response and recovery
- Incident learnings feed platform and template improvements
Reliability, Resilience, and Recovery
Design for failure up front so systems fail safely, degrade gracefully, and recover predictably, proving resilience through recovery, not uptime alone.
- Architectures isolate failures to limit blast radius
- Dependencies are evaluated for availability and fallback strategies
- Resilience patterns are built in by default (e.g., retries, timeouts, circuit breakers, degradation)
- Non-critical features degrade without impacting core functionality
- Recovery objectives are defined and validated
- Backup and recovery mechanisms are implemented and tested
- Recovery is automated to minimize manual intervention
- Game days, chaos experiments, or failure drills are conducted to validate system behavior under stress
- Reliability metrics are tracked and optimized (e.g., recovery time, failure rate)
Security Guardrails and Governance
Enforce security and compliance through codified guardrails embedded in delivery workflows, with continuous monitoring to improve security posture over time.
- Access follows least-privilege principles
- Secrets are centrally managed and securely injected
- Policies are codified and enforced consistently through Policy as Code
- Security controls are embedded in pipelines, including scanning and config checks
- High-risk actions require controlled approvals
- Exceptions are time-bound, tracked, and reviewed
- All changes are auditable and traceable
- Compliance requirements map to enforceable controls
Developer Experience, Adoption, and ROI
Improve DevEx by reducing friction, driving platform adoption, and linking usage to measurable delivery outcomes and business impact.
- Developer experience is consistent across services and environments
- Platform abstracts common concerns (e.g., infra, security, observability) through standardized defaults
- Onboarding to first deploy is fast and frictionless
- Documentation, examples, and enablement drive consistent adoption
- Platform and golden path adoption are measured through usage, onboarding, and coverage
- Key DevEx metrics are tracked (e.g., lead time, change failure rate, MTTR, time to first deploy)
- Workflow usability and reliability are continuously optimized
- Feedback and usage data drive platform improvements
- ROI is measured through delivery outcomes (e.g., reduced toil, incidents, faster releases)
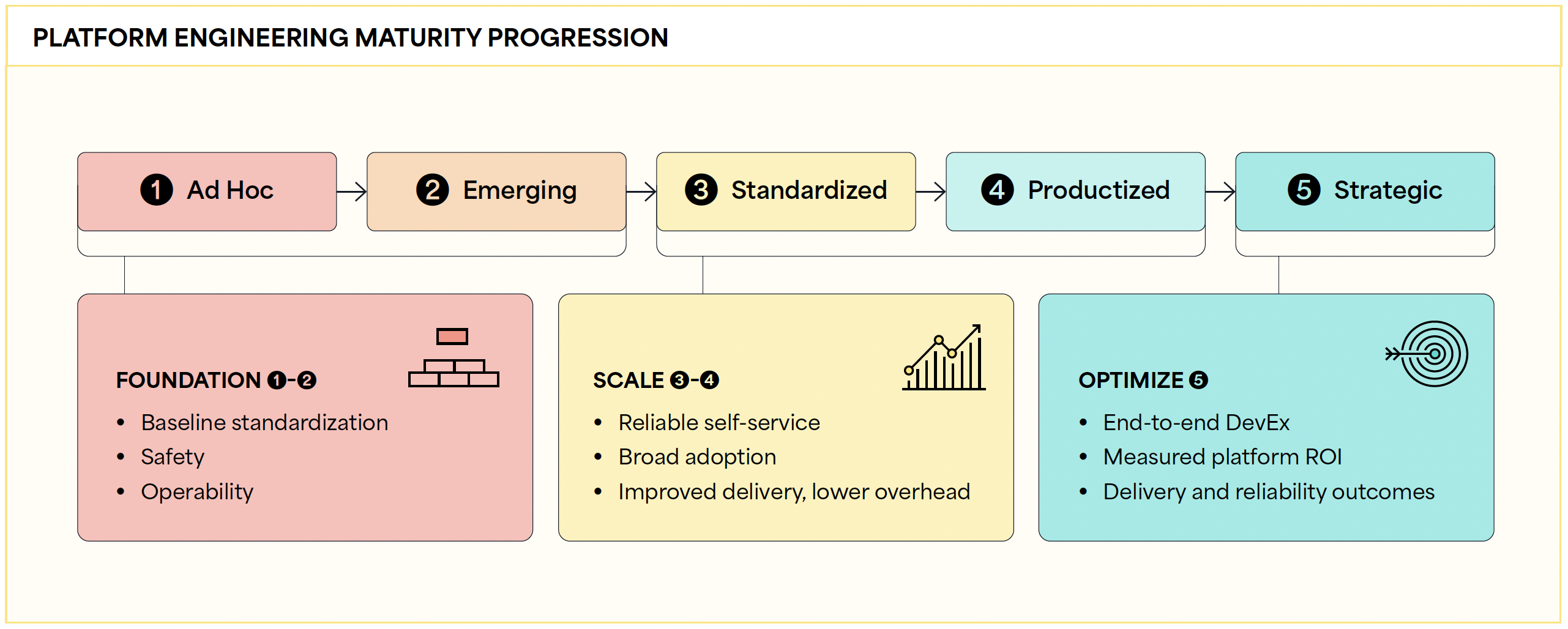
Platform Engineering Maturity and Assessment
Platform engineering maturity can be assessed across three practical stages that reflect the consistent application, adoption, and improvement of platform capabilities:
- Foundation focuses on baseline standardization, safety, and operability, with reusable capabilities in place but adoption still uneven.
- Scale enables reliable self‑service through guardrailed golden paths, improving delivery without increasing operational overhead.
- Optimize treats platform engineering as a strategic differentiator, using data‑driven decisions to continuously improve resilience, developer experience, cost efficiency, and measurable ROI.
Use the Maturity Scoring Matrix to assess maturity across core platform engineering capabilities. Rate each category once, on a scale of 1–5, based on available evidence rather than aspiration. Overall maturity is determined by the dominant scoring pattern across the matrix, with higher maturity requiring consistent strength across Foundation, Scale, and Optimize.
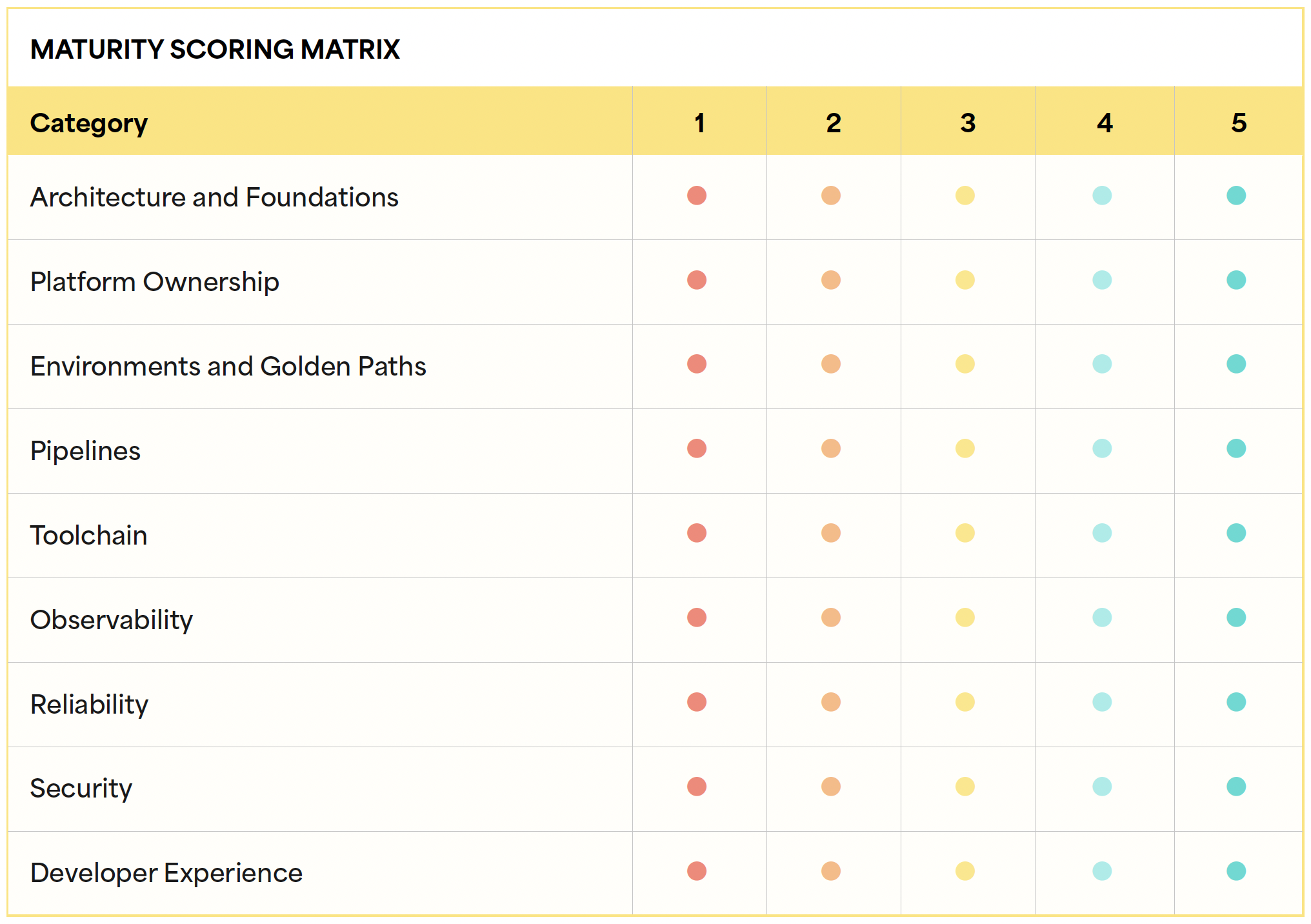
The progression bar maps scores from Ad Hoc to Strategic and groups them across the Foundation, Scale, and Optimize stages. Repeat the assessment periodically to identify gaps, track progress, and guide platform roadmap priorities.
Conclusion
Treat this checklist as a baseline gate and a recurring review mechanism, not a one-time exercise. High-performing platforms evolve through continuous refinement of architecture, automation, governance, and developer experience. Use it to identify gaps, strengthen golden paths, and align platform capabilities with measurable delivery outcomes.
This is an excerpt from DZone’s 2026 Trend Report, Platform Engineering and DevOps: How Internal Platforms, Developer Experience, and Modern DevOps Practices Accelerate Software Delivery.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments