Benchmarking SQS
Join the DZone community and get the full member experience.
Join For Freesqs, simple message queue , is a message-queue-as-a-service offering from amazon web services. it supports only a handful of messaging operations, far from the complexity of e.g. amqp , but thanks to the easy to understand interfaces, and the as-a-service nature, it is very useful in a number of situations.
but how fast is sqs? how does it scale? is it useful only for low-volume messaging, or can it be used for high-load applications as well?
![]()
if you know how sqs works, and want to skip the details on the testing methodology, you can jump straight to the test results .
sqs semantics
sqs exposes an http-based interface. to access it, you need aws credentials to sign the requests. but that’s usually done by a client library (there are libraries for most popular languages; we’ll use the official java sdk ).
the basic message-related operations are:
- send a message, up to 256 kb in size, encoded as a string. messages can be sent in bulks of up to 10 (but the total size is capped at 256 kb).
- receive a message. up to 10 messages can be received in bulk, if available in the queue
- long-polling of messages. the request will wait up to 20 seconds for messages, if none are available initially
- delete a message
there are also some other operations, concerning security, delaying message delivery, and changing a messages’ visibility timeout, but we won’t use them in the tests.
sqs offers at-least-once delivery guarantee. if a message is received, then it is blocked for a period called “visibility timeout”. unless the message is deleted within that period, it will become available for delivery again. hence if a node processing a message crashes, it will be delivered again. however, we also run into the risk of processing a message twice (if e.g. the network connection when deleting the message dies, or if an sqs server dies), which we have to manage on the application side.
sqs is a replicated message queue, so you can be sure that once a message is sent, it is safe and will be delivered; quoting from the website:
amazon sqs runs within amazon’s high-availability data centers, so queues will be available whenever applications need them. to prevent messages from being lost or becoming unavailable, all messages are stored redundantly across multiple servers and data centers.
testing methodology
to test how fast sqs is and how it scales, we will be running various numbers of nodes, each running various number of threads either sending or receiving simple, 100-byte messages.
each sending node is parametrised with the number of messages to send, and it tries to do so as fast as possible. messages are sent in bulk, with bulk sizes chosen randomly between 1 and 10. message sends are synchronous, that is we want to be sure that the request completed successfully before sending the next bulk. at the end the node reports the average number of messages per second that were sent.
the receiving node receives messages in maximum bulks of 10. the
amazonsqsbufferedasyncclient
is used, which pre-fetches messages to speed up delivery. after
receiving, each message is asynchronously deleted. the node assumes that
testing is complete once it didn’t receive any messages within a
minute, and reports the average number of messages per second that it
received.
each test sends from 10 000 to 50 000 messages per thread. so the tests are relatively short, 2-5 minutes. there are also longer tests, which last about 15 minutes.
the full (but still short) code is here:
sender
,
receiver
,
sqsmq
. one set of nodes runs the
mqsender
code, the other runs the
mqreceiver
code.
the sending and receiving nodes are m3.large ec2 servers in the eu-west region, hence with the following parameters:
- 2 cores
- intel xeon e5-2670 v2
- 7.5 gb rams
the queue is of course also created in the eu-west region.
minimal setup
the minimal setup consists of 1 sending node and 1 receiving node, both running a single thread. the results are, in messages/second:
| average | min | max | |
|---|---|---|---|
| sender | 429 | 365 | 466 |
| receiver | 427 | 363 | 463 |
scaling threads
how do these results scale when we add more threads (still using one sender and one receiver node)? the tests were run with 1, 5, 25, 50 and 75 threads. the numbers are an average msg/second throughput.
| number of threads: | 1 | 5 | 25 | 50 | 75 |
|---|---|---|---|---|---|
| sender per thread | 429,33 | 407,35 | 354,15 | 289,88 | 193,71 |
| sender total | 429,33 | 2 036,76 | 8 853,75 | 14 493,83 | 14 528,25 |
| receiver per thread | 427,86 | 381,55 | 166,38 | 83,92 | 47,46 |
| receiver total | 427,86 | 1 907,76 | 4 159,50 | 4 196,17 | 3 559,50 |
as you can see, on the sender side, we get near-to-linear scalability as the number of thread increases, peaking at 14k msgs/second sent (on a single node!) with 50 threads. going any further doesn’t seem to make a difference.
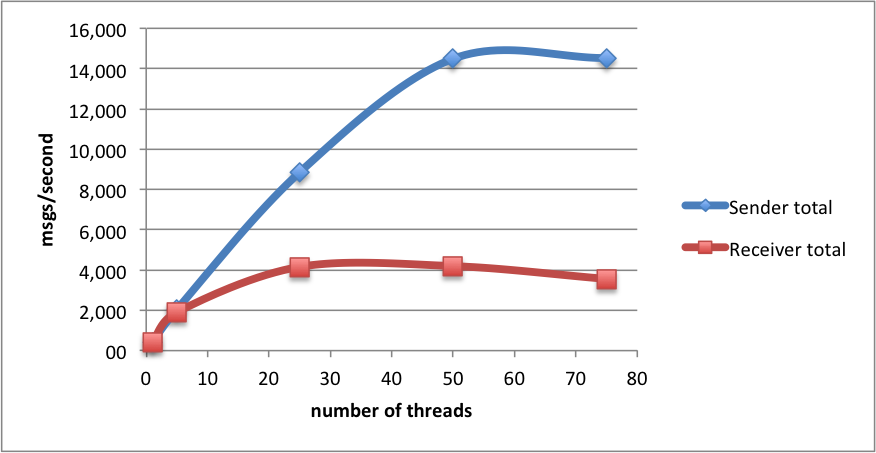
the receiving side is slower, and that is kind of expected, as receiving a single message is in fact two operations: receive + delete, while sending is a single operation. the scalability is worse, but still we can get as much as 4k msgs/second received.
scaling nodes
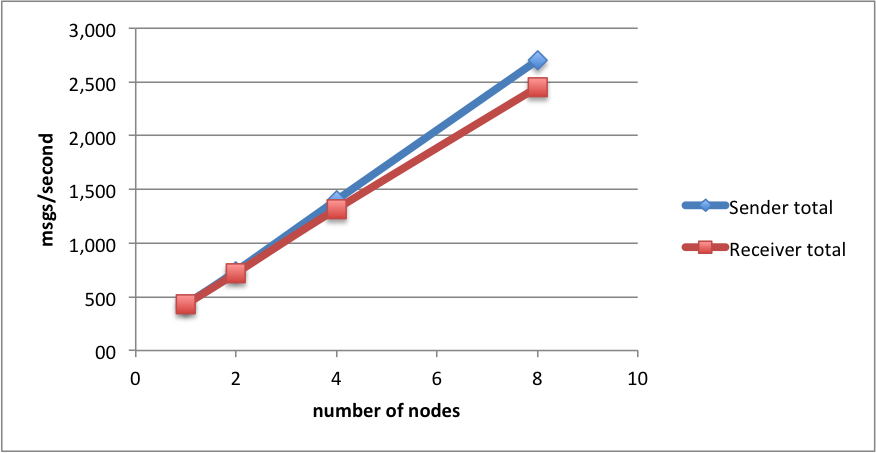
another (more promising) method of scaling is adding nodes, which is quite easy as we are “in the cloud”. the test results when running multiple nodes, each running a single thread are:
| number of nodes: | 1 | 2 | 4 | 8 |
|---|---|---|---|---|
| sender per node | 429,33 | 370,36 | 350,30 | 337,84 |
| sender total | 429,33 | 740,71 | 1 401,19 | 2 702,75 |
| receiver per node | 427,86 | 360,60 | 329,54 | 306,40 |
| receiver total | 427,86 | 721,19 | 1 318,15 | 2 451,23 |
in this case, both on the sending&receiving side, we get near-linear scalability, reaching 2.5k messages sent&received per second with 8 nodes.
scaling nodes and threads
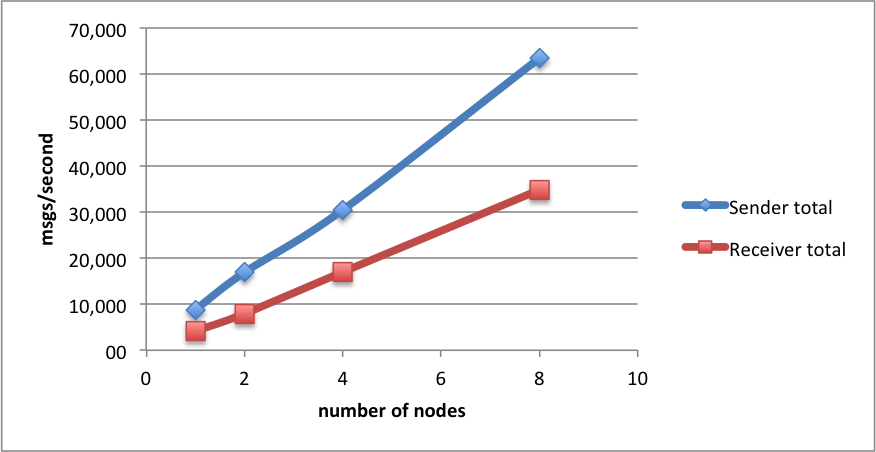
the natural next step is, of course, to scale up both the nodes, and the threads! here are the results, when using 25 threads on each node:
| number of nodes: | 1 | 2 | 4 | 8 |
|---|---|---|---|---|
| sender per node&thread | 354,15 | 338,52 | 305,03 | 317,33 |
| sender total | 8 853,75 | 16 925,83 | 30 503,33 | 63 466,00 |
| receiver per node&thread | 166,38 | 159,13 | 170,09 | 174,26 |
| receiver total | 4 159,50 | 7 956,33 | 17 008,67 | 34 851,33 |
again, we get great scalability results, with the number of receive operations about half the number of send operations per second. 34k msgs/second processed is a very nice number!
to the extreme
the highest results i managed to get are:
- 108k msgs/second sent when using 50 threads and 8 nodes
- 35k msgs/second received when using 25 threads and 8 nodes
i also tried running longer “stress” tests with 200k messages/thread, 8 nodes and 25 threads, and the results were the same as with the shorter tests.
running the tests – technically
to run the tests, i built
docker
images containing the
sender
/
receiver
binaries, pushed to docker’s hub, and downloaded on the nodes by chef.
to provision the servers, i used amazon opsworks. this enabled me to
quickly spin up and provision a lot of nodes for testing (up to 16 in
the above tests). for details on how this works, see my
“cluster-wide java/scala application deployments with docker, chef and amazon opsworks” blog
.
the
sender
/
receiver
daemons monitored (by
checking each second the last-modification date) a file on s3. if a
modification was detected, the file was downloaded – it contained the
test parameters – and the test started.
summing up
sqs has good performance and really great scalability characteristics. i wasn’t able to reach the peak of its possibilities – which would probably require more than 16 nodes in total. but once your requirements get above 35k messages per second, chances are you need custom solutions anyway; not to mention that while sqs is cheap, it may become expensive with such loads.
from the results above, i think it is clear that sqs can be safely used for high-volume messaging applications, and scaled on-demand. together with its reliability guarantees, it is a great fit both for small and large applications, which do any kind of asynchronous processing; especially if your service already resides in the amazon cloud.
as benchmarking isn’t easy, any remarks on the testing methodology, ideas how to improve the testing code are welcome!
Published at DZone with permission of Adam Warski. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments