Better Data Beats Better Models: The Case for Data Quality in ML
A deep dive into the importance of data quality and strategies for improvement. We also analyze some real-world examples demonstrating the importance of data quality.
Join the DZone community and get the full member experience.
Join For FreeThe phrase “Garbage in, Garbage out” is not a new one, and nowhere is this phrase more applicable than in machine learning. The most sophisticated and complex model architecture will crumble under the weight of poor data quality. Conversely, high-quality and reliable data can power even simple models to drive significant business impact.
In this post, we will deep dive into why data quality is critical, what dimensions matter most, the problems poor data creates, and how organizations can actively monitor and improve data quality. We will also examine a practical example of credit score and close with the case for treating data quality as a first-class citizen in ML workflows.
Why Data Quality Matters in ML
Machine learning models approximate the world through the patterns present in the training data. If the data is inaccurate, incomplete, or of poor quality, the model learns a distorted picture of the world. Models trained in this manner are fragile, prone to cold start problems, and can overfit on noise. Stakeholders quickly lose trust in such models as predictions often don’t align with common sense or business intuition. The consequences of poor model predictions are not just technical but also have a large impact on customer experiences, wasted resources, and, in some cases, reputational risk.
In simple terms, the machine learning model is the last mile of the ML workflow. The real foundation is the data, and without good quality data, the foundation is too weak to support building any systems on top of it.
Key Dimensions of Data Quality
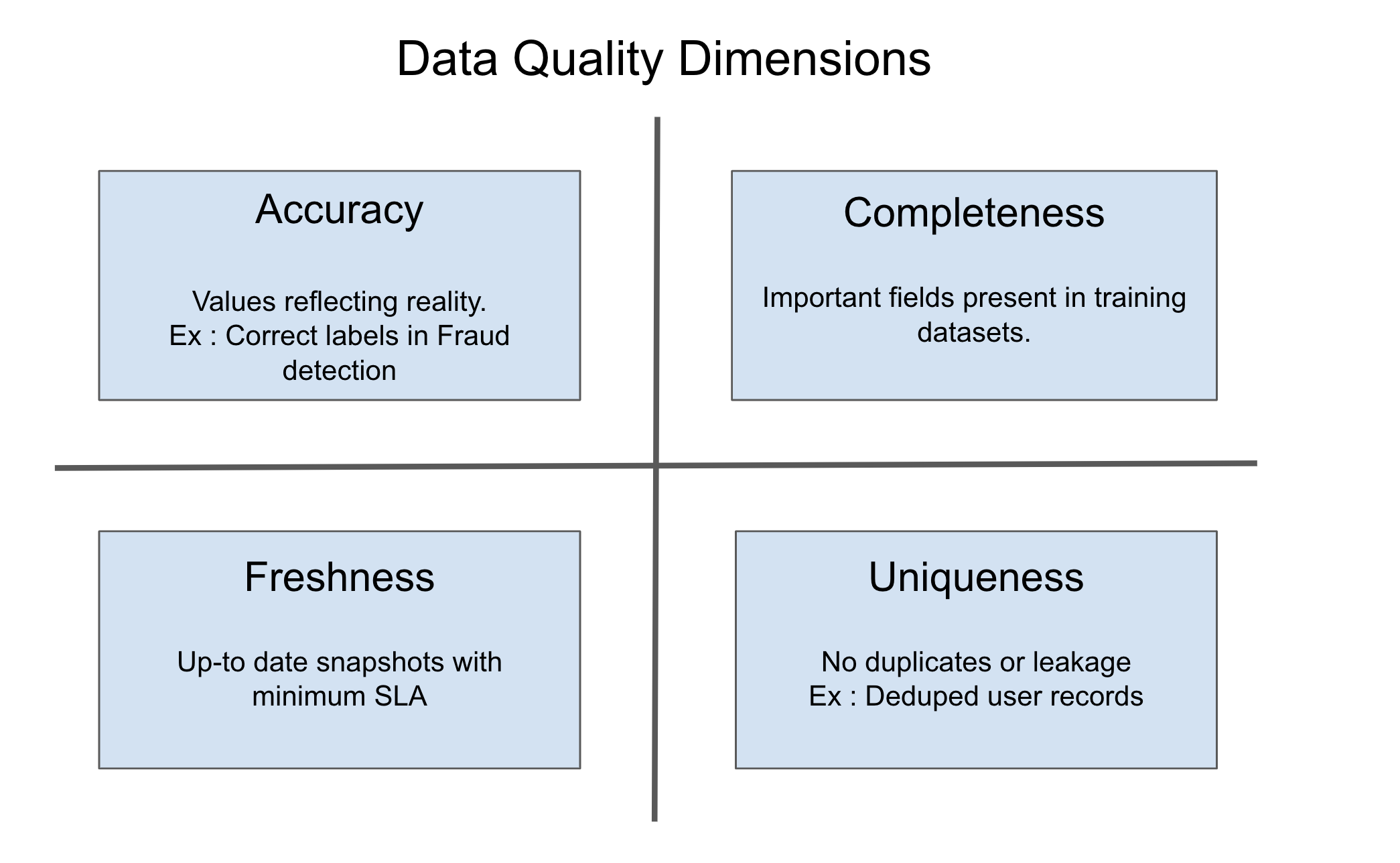
Data quality is a broad and abstract concept, but it becomes more measurable when we break it down into different dimensions. Accuracy is the most important and obvious one: If the input data is wrong (e.g., mislabeled transactions in fraud detection models), the model will simply learn incorrect patterns. Completeness is equally important. Without a high degree of coverage for important features, the model will lack context and produce weaker predictions. For example, a recommender system missing key user attributes will fail to provide personalized recommendations.
Freshness plays a subtle but powerful role in data quality. Outdated data appears correct, but does not reflect real-world conditions. Predicting user churn based on 6-month-old engagement logs is meaningless in fast-moving consumer businesses. Finally, uniqueness ensures that duplicate records do not bias models by overrepresenting certain patterns or segments. These dimensions, despite being distinct, rarely fail in isolation. In reality, they interact, amplifying the impact.
Problems Bad Data Causes in ML
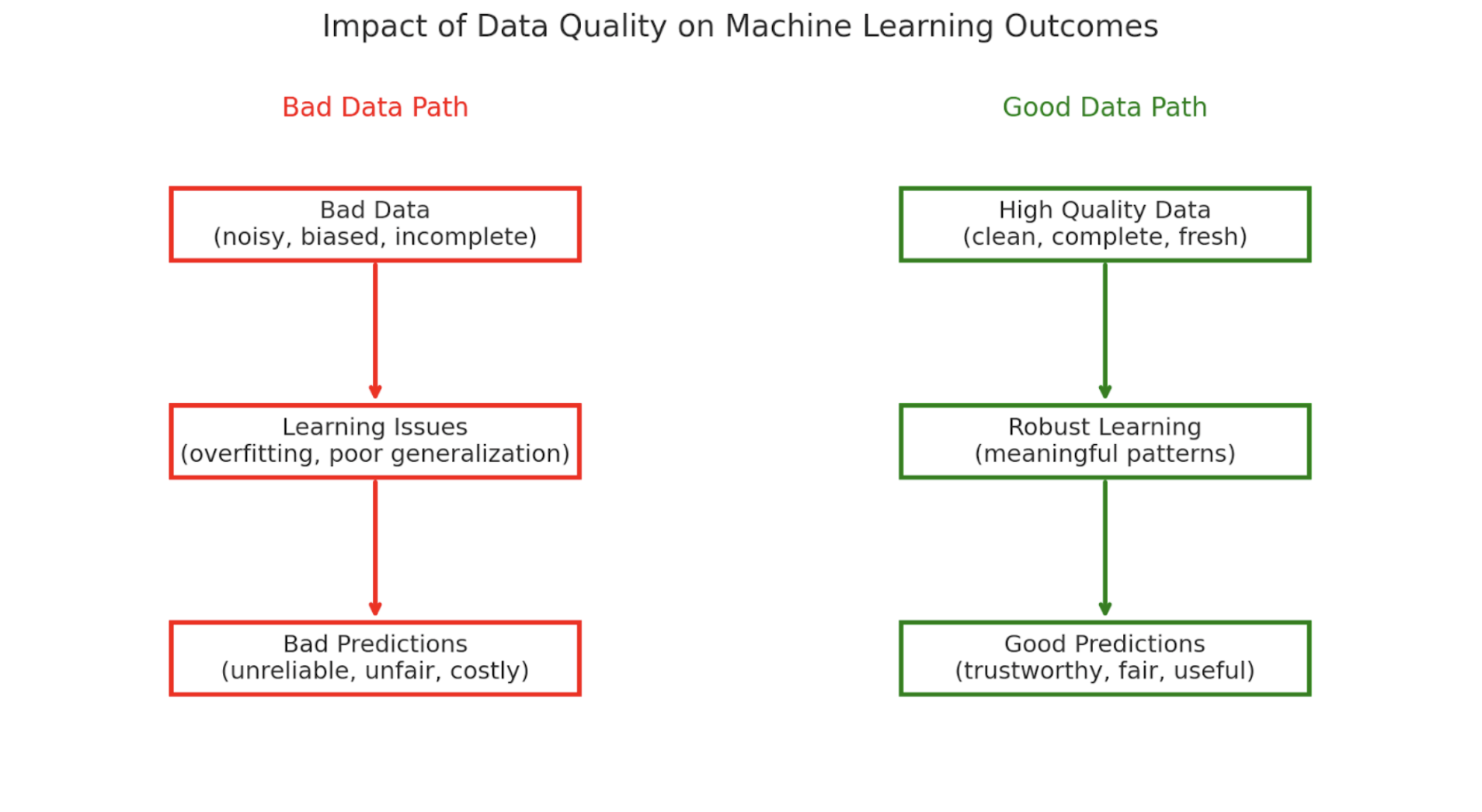
Training a model on poor-quality data leads to two major issues. The first one is a poor generalization. A model trained on flawed data learns patterns that do not extend to the real world. A simple example is a credit scoring model trained with an underrepresentation of applicants in the 18–25 age group. It may perform well in testing (since the same flawed dataset is used), but it can fail in the real world since it never learned the patterns for this age group.
The second issue is overfitting to noisy signals. The presence of errors and mislabeled data points leads to the model memorizing these quirks instead of learning the correct patterns. For example, instead of learning which users are likely to repay a loan, the model may memorize signals tied to data entry glitches. Despite performing well on training data, they can crumble on real-world examples, as what they memorized does not exist in reality.
Example: Credit Scoring Models
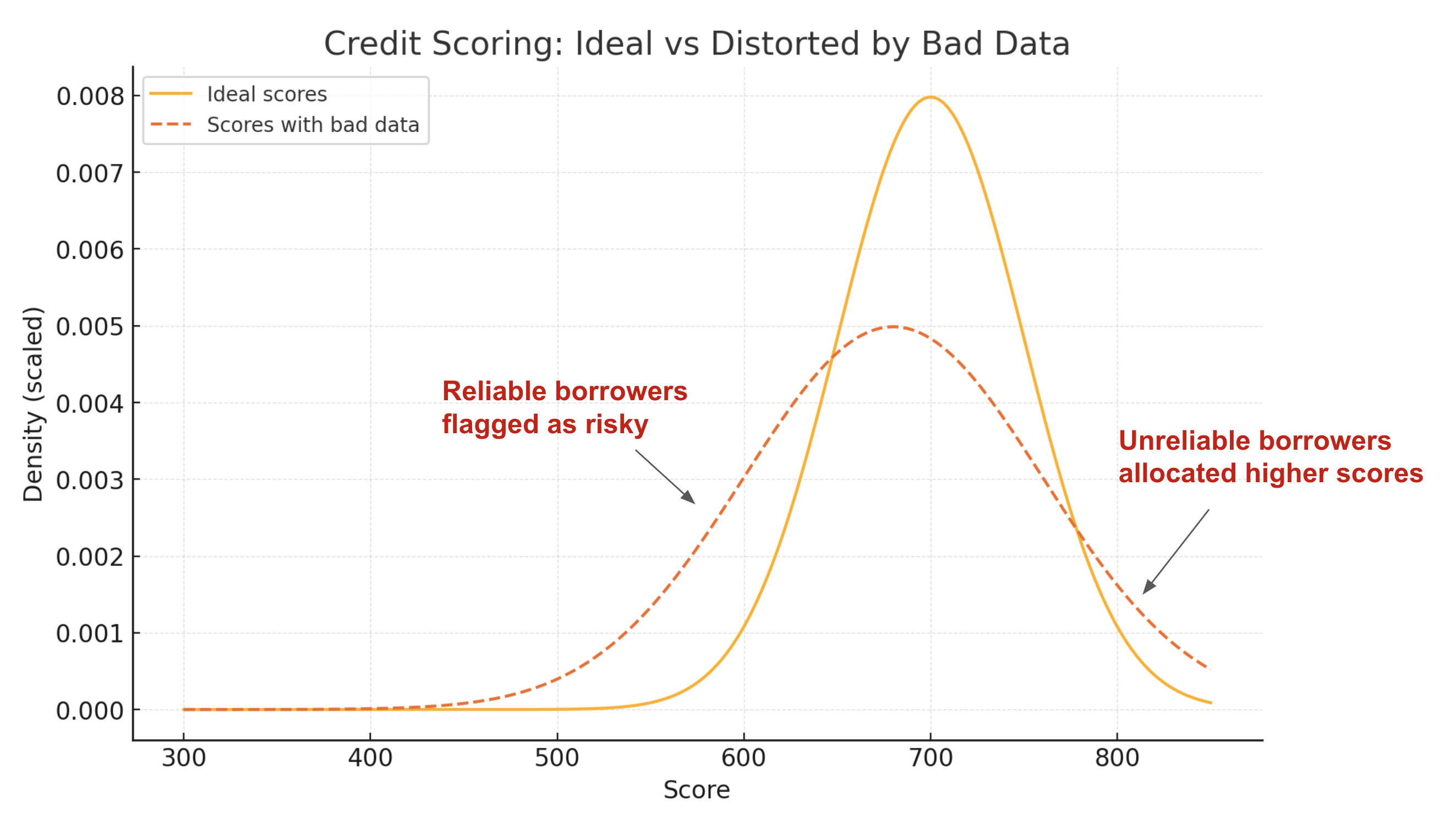
Credit scoring models provide a practical illustration of the consequences of bad data. Imagine a training dataset where repayment histories are logged incorrectly and updates from smaller banks never make it into the logs. A model built on this flawed foundation is bound to make misjudgments. Reliable borrowers can be flagged as risky, while high-risk individuals may slip through undetected.
The impact has two facets: First, lenders lose money due to misallocating credit. Secondly, customers lose trust in the system due to misclassifications and unfair results. In real-world examples, such failures have drawn regulatory scrutiny and negative press (remember the Apple Card debacle), which damages both the business and its reputation. This is not a problem of algorithms but of data quality, a lesson many organizations learned the hard way.
Detecting and Improving Data Quality
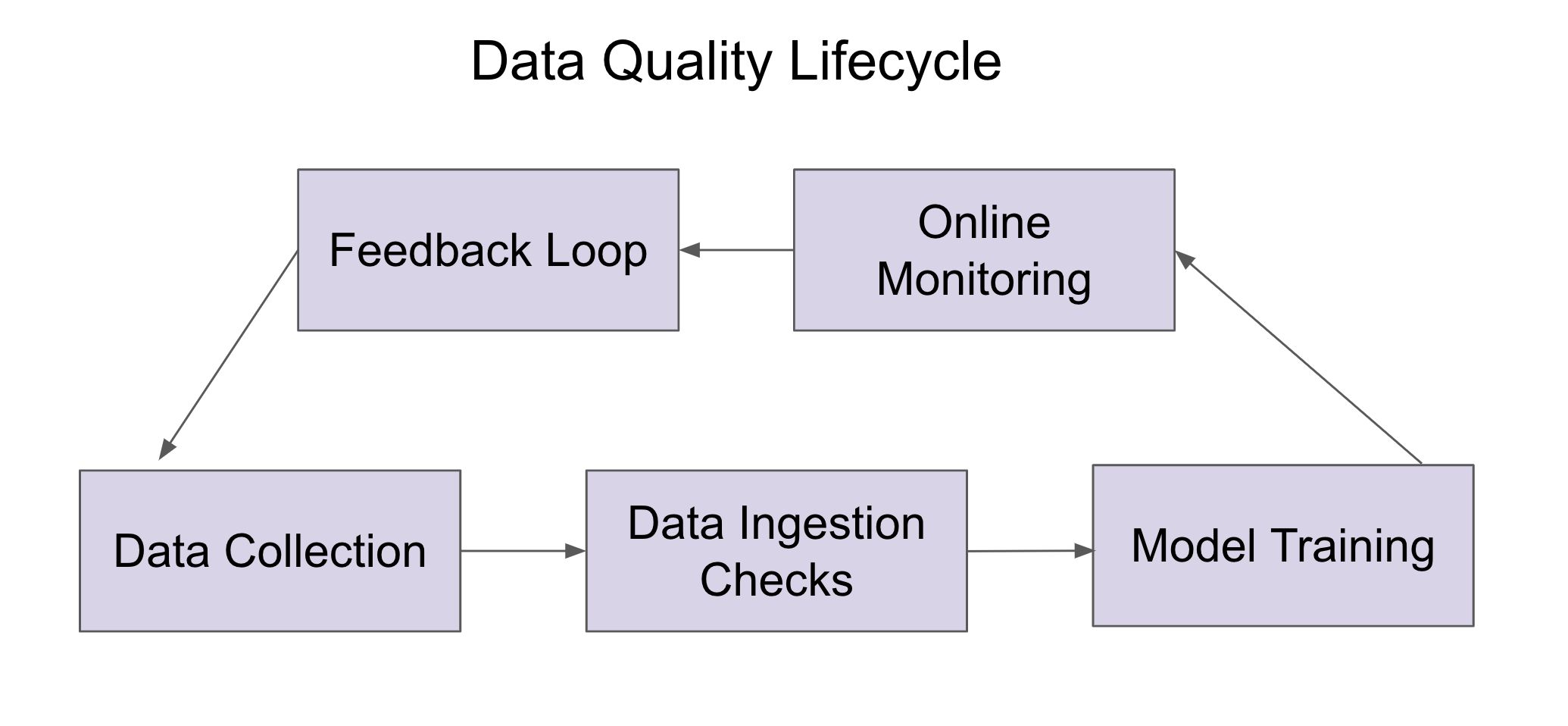
Detecting data quality issues is not just about a single check but rather about continuous monitoring. Statistical distribution checks are the first line of defense, helping detect anomalies or sudden shifts that can indicate broken data pipelines. For example, a 50% drop in the average income of applicants for a credit organization is likely to be a data ingestion issue.
Monitoring in production is an essential part of the whole workflow. Even if the training dataset is well vetted, the real world evolves. Features drift, upstream UI changes lead to funnel distribution shifts, and pipelines can break silently. By implementing continuous monitoring, these issues can be detected early before they degrade model performance.
On top of detection, prevention is also equally important. Strong processes like label validations and human-in-the-loop validations ensure that ambiguous cases are identified and flagged for expert review. This ensures continuous improvement of the validation process, as well as bad data not reaching the training data stage.
It is important to enforce these standards at the data ingestion stage. Data should not flow without proper checks into the feature store. Schema validations, distribution checks, data uniqueness, etc., should be implemented such that they act as firewalls to prevent flawed data from contaminating the pipeline. This approach transforms data quality into a first-class citizen in everyday workflows.
Business Implications
Ignoring data quality can often turn out to be very expensive. Teams spend large amounts of compute to retrain models on flawed data, to observe little to no business impact. Launch timelines get pushed back since teams spend weeks debugging data issues, a time that could have been spent otherwise on feature development. In industries that are regulated, like finance and healthcare, poor data quality can cause compliance violations and increased legal expenses.
The flip side is that a solid investment in data quality can offer one of the highest returns on investment in ML. Cleaner data will almost always improve performance, making the model stronger. It will help build trust among stakeholders when predictions align with reality. It will also reduce operational costs by reducing the amount of time the team spends fighting issues. Many seasoned ML teams have learned that the fastest path to better models is fixing the data rather than onboarding complex architectures.
Takeaway
Machine learning models rarely fail because of a lack of sophisticated model architectures. They fail because of poor data quality. High-quality and reliable data is the true foundation of sustainable ML systems. A basic model with excellent data often outperforms an advanced model with flawed data.
Data quality is not a one-time project but a continuous practice that requires rigorous monitoring, process discipline, and organizational investment. Teams must start treating data quality as a first-class citizen, similar to production code, because data is the input for ML models.
Opinions expressed by DZone contributors are their own.
Comments