Common API Mistakes
A lot about API design and management can trip you up. Keeping these points in mind will help you take a design-first approach and avoid the most common mistakes.
Join the DZone community and get the full member experience.
Join For FreeDo you know if you are doing it right?
This is the question that many of us are faced with when starting with APIs, and quite invariably, there would be either of two broad scenarios that we generally find ourselves in. We are either starting green field under the clear blue sky with every little thing to elicit, introspect, and design; or else we are in a continuum, trying to understand the current system, and slice and dice what is otherwise called a monolith into smaller more manageable APIs.
I would say that in either of the two scenarios, it is important to go design-first.
Bear in mind that designing an API is all about keeping it simple, intuitive, loosely-coupled, and scalable. And this is where people are likely to make mistakes. I will list out some common mistakes that we generally make either as architects, designers, or developers. Accordingly, the order of these items has been kept in terms of the increasing level of granularity or decreasing level of impact – whichever way you want to look at it – starting from architectural concerns and then getting into the weeds.
API Anarchy

Thinking at the enterprise level, managing APIs cannot happen without appropriate governance in place. API governance takes into perspective the key aspects of managing APIs, including aspects like asset management, configuration management, change management, quality assurance, and security. A good source reference can be found here.
Ignoring DDD
Consider a scenario when API specs are written in silos and involve overlapping domain entities. It may cause redundancy of effort, confusion, and eventually maintenance hazards and rework. Imagine within a banking enterprise, if two lines of business – say retail and commercial – come up with their own version of API specs for processing payments; it will cause unnecessary redundancy at all levels.
Django Unbound
This concept of identifying bounded contexts is very much borrowed from the microservices architecture style, but bear in mind that APIs are merely one implementation of the microservices architecture style, and the end objectives of writing APIs are no different. A domain model, once defined, should give rise to an object model with bounded contexts identified, and that should serve as the foundation for defining the responsibility or boundary and request-response model of an API.
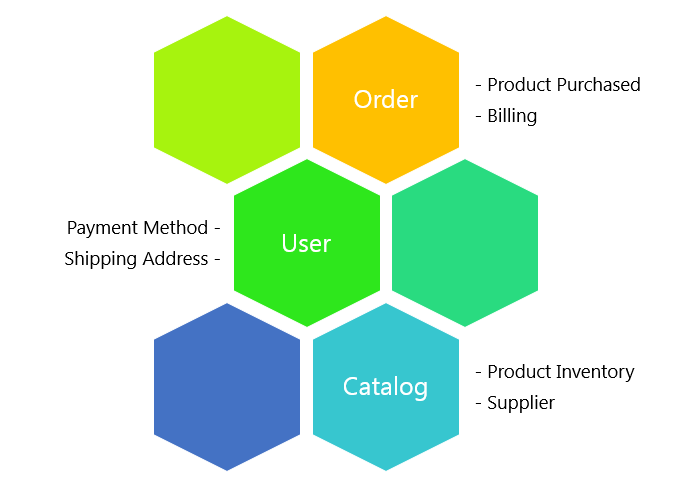
Note that definition of the domain model is where the business context plays heavily and is inculcated in the definition of an API.
Divide and Conquer
It's quite a common scenario: you are splintering a monolith one piece at a time, but without a good overall design behind it, the effort may go waste. Use of an anti-corruption layer is advised.
Modeling-Shy: the Tendency to Get Into Code and Skip Modeling YAML or RAML
It is important to go model-first and then maintain the model during the course of API implementation. Tools like Swagger (for YAML) or Mulesoft API designer (for RAML) help in getting to the details up-front. Besides early design granularity, the benefits are multiple:
YAML/RAML models serve as scaffolding for the initial version of APIs that could be generated from them.
They serve as a template and a means for sharing API specification documentation with the audience.
They serve as a template for generating API mocks and unit test cases.
They help in identifying and defining generic types that form the building blocks of the object model.
Not Enough Layers in the Cake: Missing API Strategy
Keeping the icing too thick or the cake too dense, or in other words, not identifying the layers needed for the APIs to be meaningful, reusable, and loosely-coupled, could be ominous.
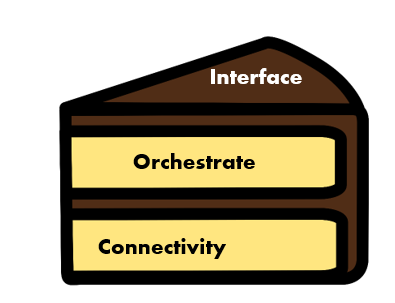
Following API-led-connectivity, as recommended here, is a way to keep APIs pertinent to the respective bounded context and coupled loosely enough so as to derive a good trade-off between reuse and API ownership.
Letting REST Principles Rest in Peace
Not proactively injecting something like a correlation identifier in the logs is one common mistake that generally goes undiscovered until integration testing really commences. This is something that should be part of the underlying API framework that every API must inherit from so that consistency in transaction traceability is ensured.
We all know that Murphy’s Law is for real and there will always be a wide variety of things that could go kaput in a given implementation. However, arming yourself with the right design principles and knowhow of potential pitfalls is what could hopefully help fellow developers circumvent common API mistakes.
Opinions expressed by DZone contributors are their own.
Comments