Bridging Cloud and On-Premises Log Processing
This article emphasizes on the feasibility of ingesting logs from public cloud platforms into on-premises services by highlighting key points.
Join the DZone community and get the full member experience.
Join For FreeModern cloud-native architectures require robust, scalable, and secure log processing solutions to monitor distributed applications. This study presents a hybrid solution for log collection, aggregation, and analysis using Azure Kubernetes Service (AKS) for log generation, Fluent Bit for log collection, Azure EventHub for intermediary aggregation, and Splunk deployed on an on-premises Apache CloudStack cluster for comprehensive log indexing and visualization.
We detail the system’s design, implementation, and evaluation, demonstrating how this architecture supports reliable and scalable log processing for cloud-native workloads while retaining control over data on-premises.
Introduction
Centralized logging solutions have become indispensable. Modern applications, particularly those built on microservices architectures, generate huge amounts of logs, often in diverse formats and from multiple sources. These logs are the key source in monitoring application performance, diagnosing issues, and ensuring the overall reliability of the system. However, managing such high volumes of log data poses significant challenges, especially in hybrid cloud environments that span both on-premises and cloud-based infrastructure.
Traditional logging solutions, while effective for monolithic applications, struggle to scale under the demands of microservices-based architectures. The dynamic nature of microservices, characterized by independent deployments and frequent updates, produces a continuous stream of logs, each varying in format and structure. These logs must be ingested, processed, and analyzed in real-time to provide actionable insights. Furthermore, as applications increasingly operate across hybrid environments, ensuring the security and PII data becomes paramount, given the varied compliance and regulatory requirements.
This paper introduces a comprehensive solution that addresses these challenges by leveraging the combined capabilities of Azure and Apache CloudStack resources. By integrating the scalability and analytics capabilities of Azure with the flexibility and cost-effectiveness of CloudStack’s on-premises infrastructure, this solution offers a robust, unified approach to centralized logging.
Literature Review
Centralized log collection in microservices faces challenges like network latency, diverse data formats, and security across multiple layers. While lightweight agents like Fluent Bit and FluentD are widely used, efficient log transport remains a challenge.
Solutions such as the ELK stack and Azure Monitor offer centralized log processing but typically involve either cloud-only or on-premises-only implementations, limiting flexibility in hybrid deployments. Hybrid cloud solutions allow organizations to leverage the scalability of the cloud while retaining control over sensitive data in on-premises environments. Hybrid log processing pipelines, especially those using event streaming technologies, address the need for scalable log transport and aggregation.
System Architecture
The architecture, illustrated below, integrates Azure EventHub and AKS with on-premises Apache CloudStack and Splunk. Each component is optimized for efficient log processing and secure data transfer across environments.
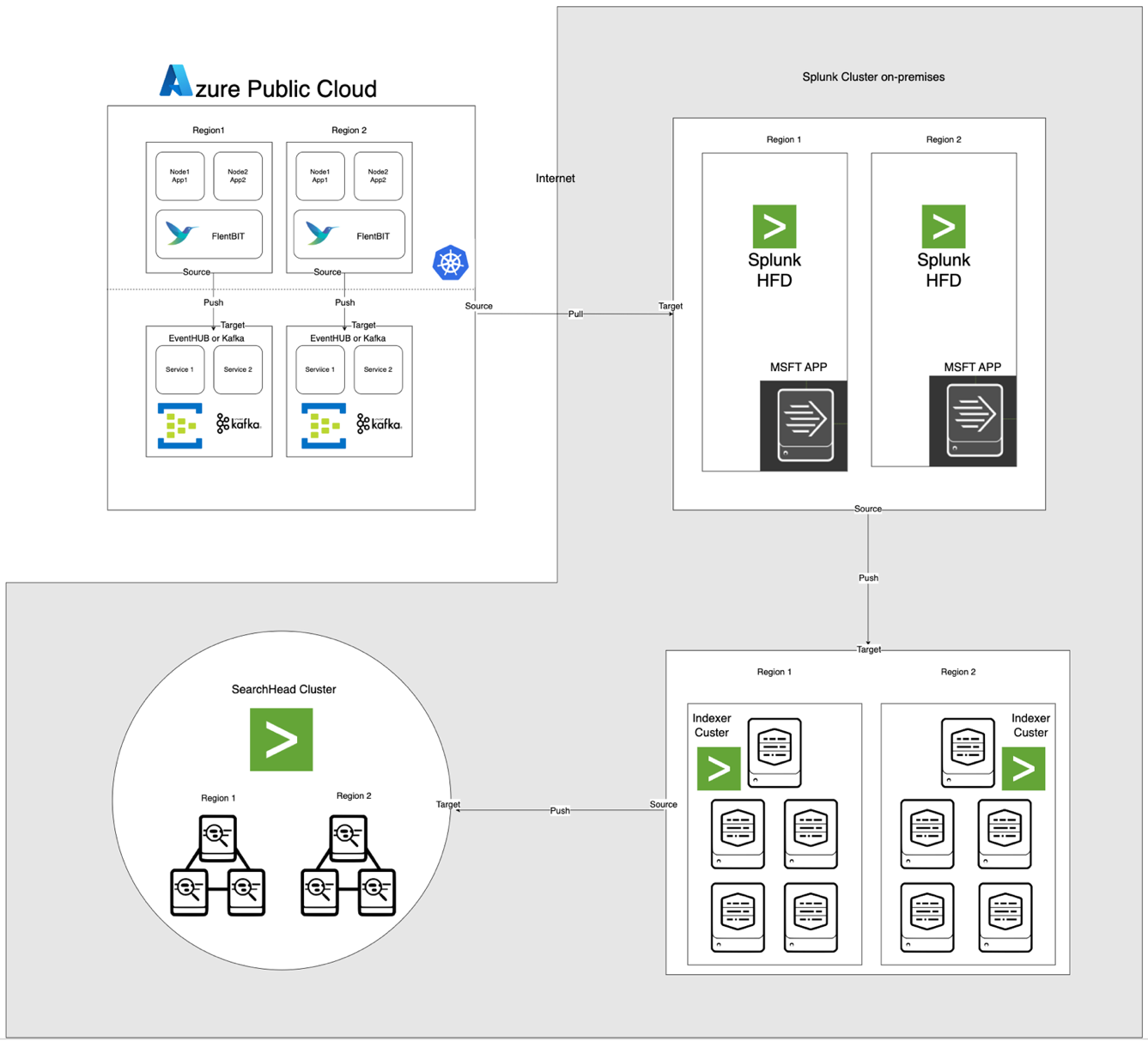
Component Descriptions
- AKS: Hosts containerized applications and generates logs accessible through Kubernetes' log aggregation layer.
- Fluent Bit: Deployed as a DaemonSet, collects logs from AKS nodes. Each Fluent Bit instance captures logs from /var/log/containers, filters them, and forwards them in JSON format to EventHub.
- Azure EventHub: Serves as a high-throughput message broker, aggregating logs from Fluent Bit and temporarily storing them until pulled by the Splunk Heavy Forwarder.
- Apache Kafka: Acts as a reliable bridge between Fluent Bit and Splunk. Fluent Bit forwards logs to Kafka using its Kafka output plugin, where logs are stored and processed temporarily. Splunk then consumes the logs from Kafka using connectors like the Kafka Connect Splunk Sink or custom scripts, ensuring a scalable and decoupled architecture.
- Splunk Heavy Forwarder (HF): Installed in Apache CloudStack, the Heavy Forwarder retrieves logs from Azure EventHub using the Splunk Add-on for Microsoft Cloud Services. This add-on provides a seamless integration, enabling the Heavy Forwarder to connect securely to EventHub, retrieve logs in near real-time, and transform them as needed before forwarding to Splunk’s indexer for storage and processing
- Splunk on Apache CloudStack: Provides log indexing, search, visualization, and alerting.
Data Flow
- Log collection in AKS: Fluent Bit tails log files in /var/log/containers, filtering out unnecessary logs and tagging each log with metadata (e.g., container name, namespace).
- Forwarding to EventHub: Logs are sent to EventHub over HTTPS using Fluent Bit’s azure_eventhub output plugin, ensuring secure data transmission.
- Apache Kafka: Logs from AKS are collected by Fluent Bit, running as a DaemonSet, which parses and forwards them to Apache Kafka via its Kafka output plugin. Kafka acts as a high-throughput buffer, storing and partitioning logs for scalability. Splunk ingests these logs from Kafka using connectors or scripts, enabling indexing, analysis, and real-time monitoring.
- Pulling logs with Splunk Heavy Forwarder: The Heavy Forwarder in Apache CloudStack connects to EventHub using EventHubs SDK and pulls logs, forwarding them to the local Splunk indexer for storage and processing.
- Storage and analysis in Splunk: Logs are indexed in Splunk, allowing real-time searches, dashboard visualizations, and alerts based on log patterns.
Methodology
Fluent Bit DaemonSet Deployment in AKS
Fluent Bit’s configuration is stored in a ConfigMap and deployed as a DaemonSet. Below is the expanded configuration for the Fluent Bit DaemonSet:
Name: fluentbit-cm
Namespace: fluentbit
Labels: k8s-app=fluentbit
Annotations: <none>
Data
crio-logtag.lua:
local reassemble_state = {}
function reassemble_cri_logs(tag, timestamp, record)
-- Validate the incoming record
if not record or not record.logtag or not record.log or type(record.log) == 'table' then
return 0, timestamp, record
end
-- Generate a unique key for reassembly based on stream and tag
local reassemble_key = (record.stream or "unknown_stream") .. "::" .. tag
-- Handle log fragments (logtag == 'P')
if record.logtag == 'P' then
-- Store the fragment in the reassemble state
reassemble_state[reassemble_key] = (reassemble_state[reassemble_key] or "") .. record.log
return -1, 0, 0 -- Do not forward this fragment
end
-- Handle the end of a fragmented log
if reassemble_state[reassemble_key] then
-- Combine stored fragments with the current log
record.log = (reassemble_state[reassemble_key] or "") .. (record.log or "")
-- Clear the stored state for this key
reassemble_state[reassemble_key] = nil
return 1, timestamp, record -- Forward the reassembled log
end
-- If no reassembly is needed, forward the log as-is
return 0, timestamp, record
end
INCLUDE filter-kubernetes.conf
filter-kubernetes.conf:
[FILTER]
Name kubernetes
Match test.app.splunk.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix test.app.splunk.var.log.containers
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude On
Labels Off
Annotations Off
Keep_Log Off
fluentbit.conf:
[SERVICE]
Flush 1
Log_Level info
Daemon on
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
HC_Errors_Count 1
HC_Retry_Failure_Count 1
HC_Period 5
INCLUDE input-kubernetes.conf
INCLUDE output-kafka.conf
input-kubernetes.conf:
[INPUT]
Name tail
Tag test.app.splunk*
Alias test.app.splunk-input
Path /var/log/containers/*test.app.splunk.log
Parser cri
DB /var/log/flb_kube.db
Buffer_Chunk_Size 256K
Buffer_Max_Size 24MB
Mem_Buf_Limit 1GB
Skip_Long_Lines On
Refresh_Interval 5
output-kafka.conf:
[OUTPUT]
Name kafka
Alias test.app.splunk-output
Match test.app.splunk.*
Brokers prod-region-logs-premium.servicebus.windows.net:9094
Topics test.app.splunk
Retry_Limit 5
rdkafka.security.protocol SASL_SSL
rdkafka.sasl.mechanism PLAIN
rdkafka.sasl.username $ConnectionString
rdkafka.sasl.password Endpoint=sb://prod-region-logs-premium.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=***********************************************=
[OUTPUT]
parsers.conf:
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[PARSER]
Name nginx
Format regex
Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name json
Format json
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep On
Decode_Field_As json log do_next
Decode_Field_As escaped message
[PARSER]
Name syslog
Format regex
Regex ^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$
Time_Key time
Time_Format %b %d %H:%M:%S
BinaryData
Events: <none>- [INPUT] section specifies log collection from the /var/log/containers directory.
- [FILTER] section enriches logs with Kubernetes metadata.
- [OUTPUT] section configures Fluent Bit to forward logs to EventHub in JSON format.
Azure EventHub Configuration
EventHub requires a namespace, a specific EventHub instance, and access control through shared access policies.
- Namespace and EventHub setup: Create a namespace and EventHub instance in Azure, set a Send policy, and retrieve the connection string.
- Configuration for high throughput: EventHub is configured with a high partition count to support scalability, buffering, and concurrent data streams from Fluent Bit.
Splunk Heavy Forwarder Configuration in Apache CloudStack
Splunk Heavy Forwarder retrieves logs from EventHub and forwards them to Splunk’s indexer.
- Add-on for Microsoft Cloud Services: Install the add-on to enable EventHub connectivity. Configure the input in
inputs.conf:
[azure_eventhub://eventhub_name]
index = <index_name>
eventhub_namespace = <namespace>
shared_access_key_name = <access_key_name>
shared_access_key = <access_key>
batch_size = 500
interval = 30
sourcetype = _json
disabled = 0- Batch processing: Set batch_size to 500 and interval to 30 seconds to optimize data ingestion and reduce the frequency of network calls.
Splunk Indexing and Visualization
- Data enrichment: Logs are enriched with additional metadata in Splunk using field extractions.
- Searches and dashboards: SPL queries enable real-time searches, and custom dashboards provide visualization of log patterns.
- Alerting: Alerts are configured to trigger on specific log patterns, such as high error rates or repeated warnings from specific containers.
Performance and Scalability
Tests show that the system can handle high-throughput log ingestion, with EventHub’s buffering capabilities preventing data loss during network interruptions. Fluent Bit resource usage on AKS nodes remains minimal, and Splunk’s indexer handles the log volume efficiently with appropriate indexing and filtering configurations.
Security
HTTPS is used to secure communication between AKS and EventHub, while Splunk HF uses secure keys to authenticate with EventHub. Each component in the pipeline implements retry mechanisms to maintain data integrity.
Resource Utilization
- Fluent Bit averages 100-150 MiB of memory and 0.2-0.3 CPU on AKS nodes.
- EventHub’s resource usage is dynamically adjusted based on partition and throughput configurations.
- Splunk HF’s load is balanced through batch processing, optimizing data transfer without overloading Apache CloudStack resources.
Reliability and Fault Tolerance
The solution uses EventHub’s buffering to ensure log retention in case of downstream failures. EventHub also supports retry policies, further enhancing data integrity and reliability.
Discussion
Advantages of Hybrid Cloud Architecture
This architecture provides flexibility, scalability, and security by combining Azure services with on-premises control. It also leverages cloud-based streaming and buffering capabilities without compromising data sovereignty.
Limitations
While EventHub offers reliable data aggregation, costs increase with throughput units, making it essential to optimize log forwarding configurations. Additionally, data transfer between cloud and on-premises environments introduces potential latency.
Future Applications
This architecture could be extended by integrating machine learning for anomaly detection in logs or adding support for multiple cloud providers to further scale log processing and multi-cloud resilience.
Conclusion
This study demonstrates the effectiveness of a hybrid log processing pipeline leveraging cloud and on-premises resources. By integrating Azure Kubernetes Service (AKS), Azure EventHub, and Splunk on Apache CloudStack, we create a scalable and resilient solution for centralized log management and analysis. The architecture addresses key challenges in distributed logging, including high data throughput, security, and fault tolerance.
The use of Fluent Bit as a lightweight log collector in AKS ensures efficient data gathering with minimal resource overhead. Azure EventHub’s buffering capabilities allow for reliable log aggregation and temporary storage, making it well-suited to handle variable log traffic and maintain data integrity in the event of connectivity issues. The Splunk Heavy Forwarder and Splunk deployment in Apache CloudStack enable organizations to retain control over log storage and analytics while benefiting from the scalability and flexibility of cloud resources.
This approach offers significant advantages for organizations requiring a hybrid cloud setup, such as enhanced control over data, compliance with data residency requirements, and the flexibility to scale with demand. Future work can explore the integration of machine learning to enhance log analysis, automated anomaly detection, and expansion to a multi-cloud setup to increase resilience and versatility. This research provides a foundational architecture adaptable to the evolving needs of modern, distributed systems in enterprise environments.
References
Azure Event Hubs and Kafka
Hybrid Monitoring and Logging
- Hybrid and Multi-Cloud Monitoring Patterns
- Hybrid Cloud Monitoring Strategies
Splunk Integration
- Splunking Azure Event Hubs
- Azure Data into Splunk Platform
AKS Deployment
Opinions expressed by DZone contributors are their own.
Comments