Build an Advanced RAG App: Query Routing
This article explores what query routing is in the context of a RAG application and how to set up a query routing mechanism with a simple case study.
Join the DZone community and get the full member experience.
Join For FreeIn previous articles, we built a basic RAG application. We also learned to introduce more advanced techniques to improve a RAG application. Today, we will explore how to tie those advanced techniques together. Those techniques might do different — sometimes opposite — things. Still, sometimes we need to use all of them, to cover all possibilities. So let's see how we can link different techniques together. In this article, we will take a look at a technique called Query Routing.
The Problem With Advanced RAG Applications
When our Generative AI application receives a query, we have to decide what to do with it. For simple Generative AI applications, we send the query directly to the LLM. For simple RAG applications, we use the query to retrieve context from a single data source and then query the LLM. But, if our case is more complex, we can have multiple data sources or different queries that need different types of context. So do we build a one-size-fits-all solution, or do we make the application adapt to take different actions depending on the query?
What Is Query Routing?
Query routing is about giving our RAG app the power of decision-making. It is a technique that takes the query from the user and uses it to make a decision on the next action to take, from a list of predefined choices.
Query routing is a module in our Advanced RAG architecture. It is usually found after any query rewriting or guardrails. It analyzes the input query and it decides the best tool to use from a list of predefined actions. The actions are usually retrieving context from one or many data sources. It could also decide to use a different index for a data source (like parent-child retrieval). Or it could even decide to search for context on the Internet.
Which Are the Choices for the Query Router?
We have to define the choices that the query router can take beforehand. We must first implement each of the different strategies, and accompany each one with a nice description. It is very important that the description explains in detail what each strategy does since this description will be what our router will base its decision on.
The choices a query router takes can be the following:
Retrieval From Different Data Sources
We can catalog multiple data sources that contain information on different topics. We might have a data source that contains information about a product that the user has questions about. And another data source with information about our return policies, etc. Instead of looking for the answers to the user’s questions in all data sources, the query router can decide which data source to use based on the user query and the data source description.
Data sources can be text stored in vector databases, regular databases, graph databases, etc.
Retrieval From Different Indexes
Query routers can also choose to use a different index for the same data source.
For example, we could have an index for keyword-based search and another for semantic search using vector embeddings. The query router can decide which of the two is best for getting the relevant context for answering the question, or maybe use both of them at the same time and combine the contexts from both.
We could also have different indexes for different retrieval strategies. For example, we could have a retrieval strategy based on summaries, a sentence window retrieval strategy, or a parent-child retrieval strategy. The query router can analyze the specificity of the question and decide which strategy is best to use to get the best context.
Other Data Sources
The decision that the query router takes is not limited to databases and indexes. It can also decide to use a tool to look for the information elsewhere. For example, it can decide to use a tool to look for the answer online using a search engine. It can also use an API from a specific service (for example, weather forecasting) to get the data it needs to get the relevant context.
Types of Query Routers
An important part of our query router is how it makes the decision to choose one or another path. The decision can vary depending on each of the different types of query routers. The following are a few of the most used query router types:
LLM Selector Router
This solution gives a prompt to an LLM. The LLM completes the prompt with the solution, which is the selection of the right choice. The prompt includes all the different choices, each with its description, as well as the input query to base its decision on. The response to this query will be used to programmatically decide which path to take.
LLM Function Calling Router
This solution leverages the function-calling capabilities (or tool-using capabilities) of LLMs. Some LLMs have been trained to be able to decide to use some tools to get to an answer if they are provided for them in the prompt. Using this capability, each of the different choices is phrased like a tool in the prompt, prompting the LLM to choose which one of the tools provided is best to solve the problem of retrieving the right context for answering the query.
Semantic Router
This solution uses a similarity search on the vector embedding representation of the user query. For each choice, we will have to write a few examples of a query that would be routed to this path. When a user query arrives, an embeddings model converts it to a vector representation and it is compared to the example queries for each router choice. The example with the nearest vector representation to the user query is chosen as the path the router must route to.
Zero-Shot Classification Router
For this type of router, a small LLM is selected to act as a router. This LLM will be finetuned using a dataset of examples of user queries and the correct routing for each of them. The finetuned LLM’s sole purpose will be to classify user queries. Small LLMs are more cost-effective and more than good enough for a simple classification task.
Language Classification Router
In some cases, the purpose of the query router will be to redirect the query to a specific database or model depending on the language the user wrote the query in. Language can be detected in many ways, like using an ML classification model or a Generative AI LLM with a specific prompt.
Keyword Router
Sometimes the use case is extremely simple. In this case, the solution could be to route one way or another depending on if some keywords are present in the user query. For example, if the query contains the word “return” we could use a data source with information useful about how to return a product. For this solution, a simple code implementation is enough, and therefore, no expensive model is needed.
Single Choice Routing vs Multiple Choice Routing
Depending on the use case, it will make sense for the router to just choose one path and run it. However, in some cases, it also can make sense to use more than one choice for answering the same query. To answer a question that spans many topics, the application needs to retrieve information from many data sources. Or the response might be different based on each data source. Then, we can use all of them to answer the question and consolidate them into a single final answer.
We have to design the router taking these possibilities into account.
Example Implementation of a Query Router
Let’s get into the implementation of a query router within a RAG application. You can follow the implementation step by step and run it yourself in the Google Colab notebook.
For this example, we will showcase a RAG application with a query router. The application can decide to answer questions based on two documents. The first document is a paper about RAG and the second is a recipe for chicken gyros. Also, the application can decide to answer based on a Google search. We will implement a single-source query router using an LLM function calling router.
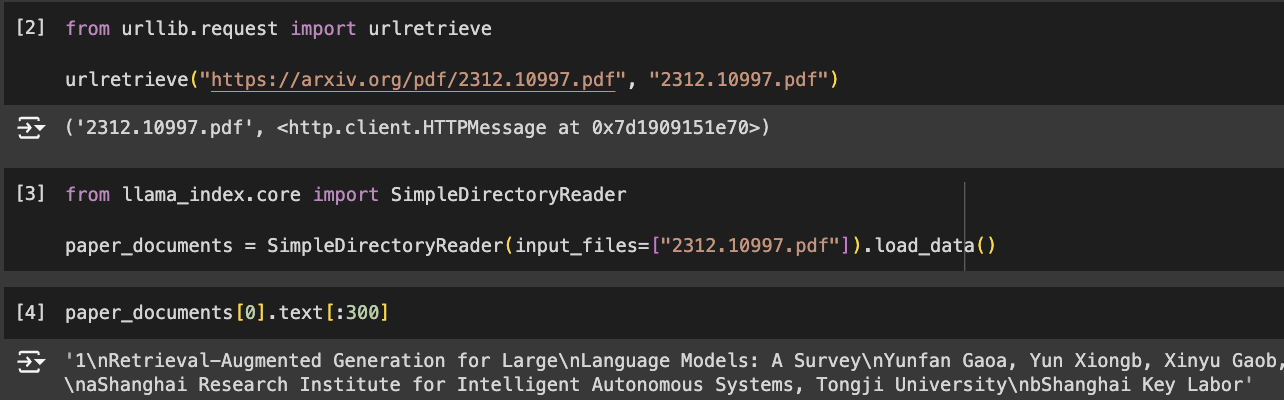
Load the Paper
First, we will prepare the two documents for retrieval. Let's first load the paper about RAG:
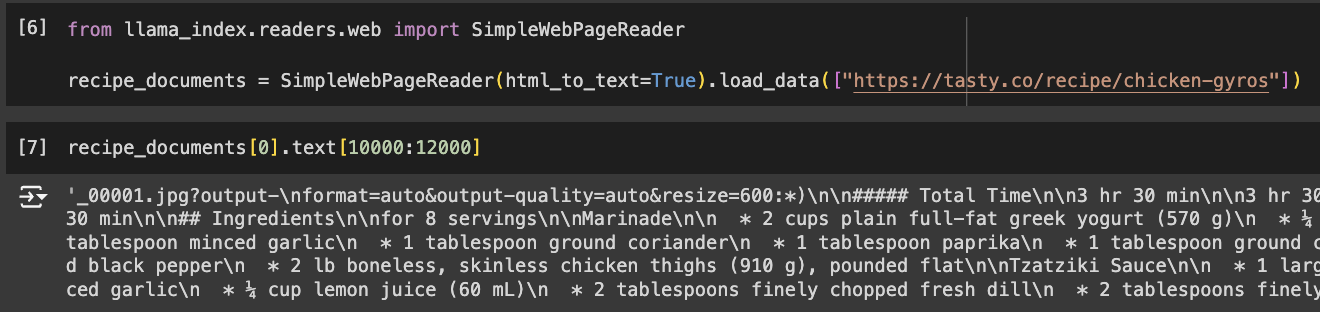
Load the Recipe
We will also load the recipe for chicken gyros. This recipe from Mike Price is hosted in tasty.co. We will use a simple web page reader to read the page and store it as text.
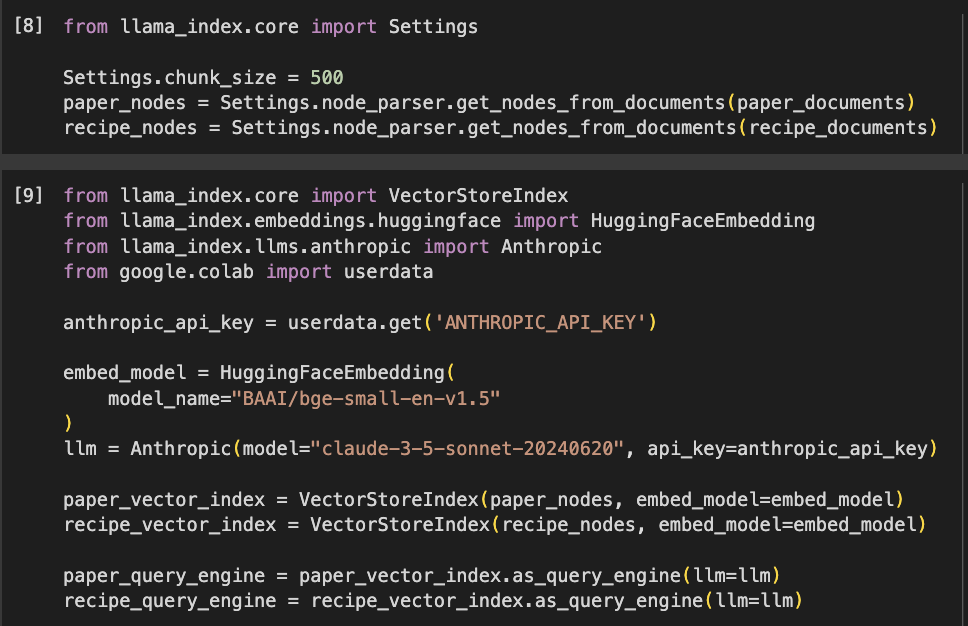
Save the Documents in a Vector Store
After getting the two documents we will use for our RAG application, we will split them into chunks and we will convert them to embeddings using BGE small, an open-source embeddings model. We will store those embeddings in two vector stores, ready to be questioned.
Search Engine Tool
Besides the two documents, the third option for our router will be to search for information using Google Search. For this example, I have created my own Google Search API keys. If you want this part to work, you should use your own API keys.
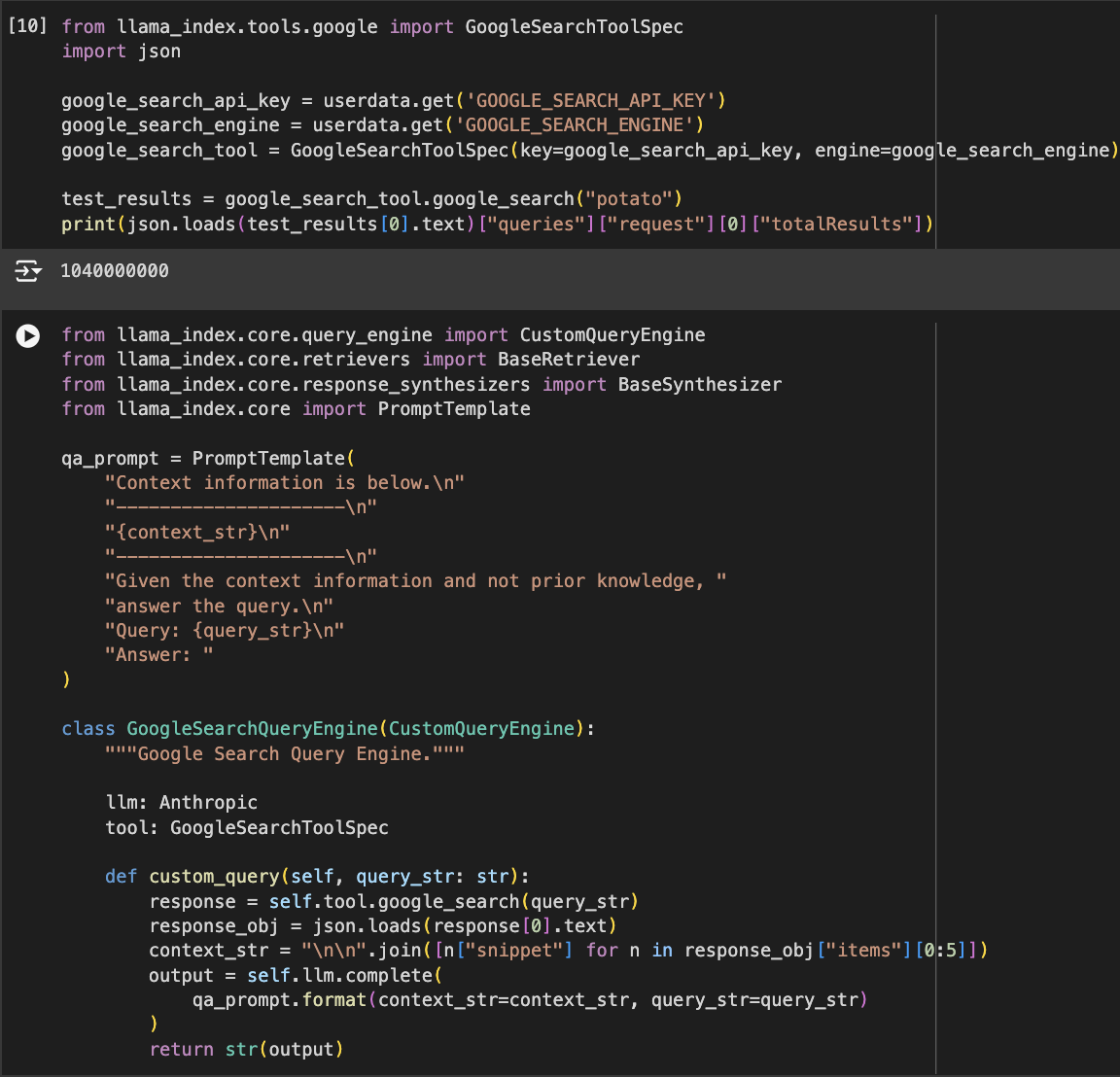
Create the Query Router
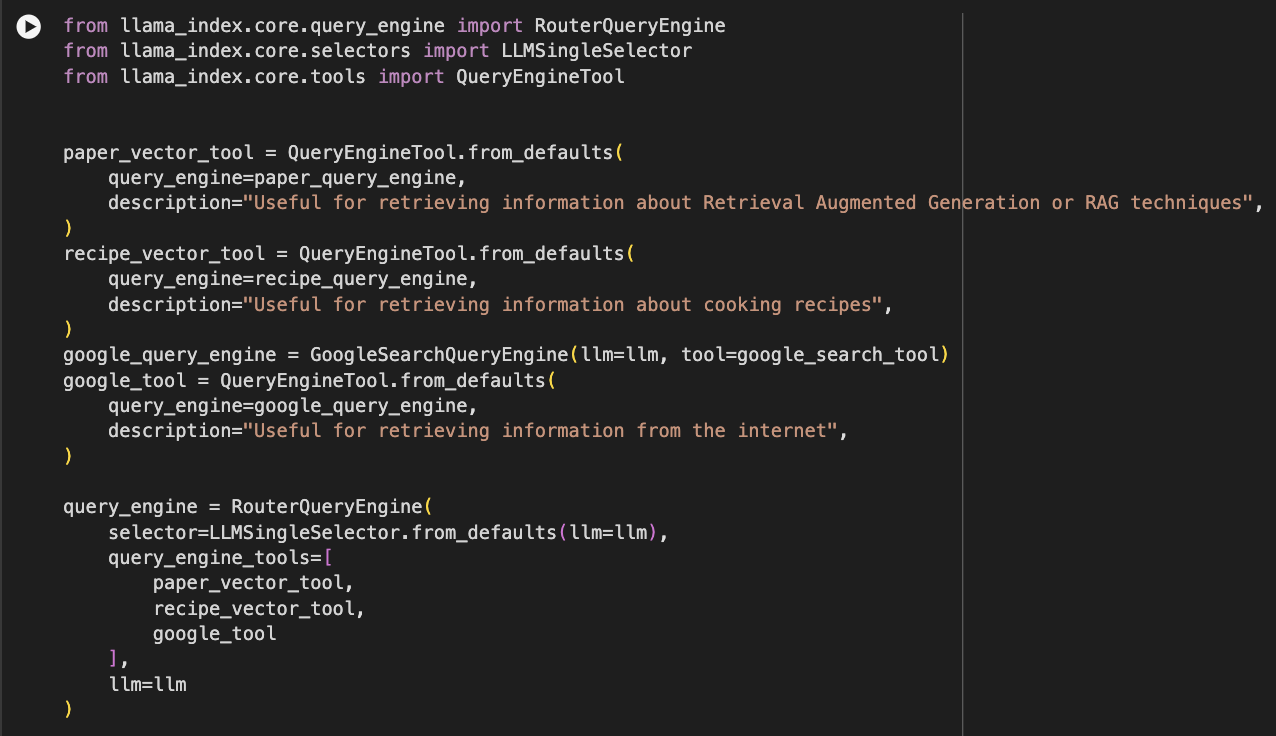
Next, using the LlamaIndex library, we create a Query Engine Tool for each of the three options that the router will choose between. We provide a description for each of the tools, explaining what it is useful for. This description is very important since it will be the basis on which the query router decides which path it chooses.
Finally, we create a Router Query Engine, also with Llama. We give the three query engine tools to this router. Also, we define the selector. This is the component that will make the choice of which tool to use. For this example, we are using an LLM Selector. It's also a single selector, meaning it will only choose one tool, never more than one, to answer the query.
Run Our RAG Application!
Our query router is now ready. Let's test it with a question about RAG. We provided a vector store loaded with information from a paper on RAG techniques. The query router should choose to retrieve context from that vector store in order to answer the question. Let's see what happens:

Our RAG application answers correctly. Along with the answer, we can see that it provides the sources from where it got the information from. As we expected, it used the vector store with the RAG paper.
We can also see an attribute "selector_result" in the result. In this attribute, we can inspect which one of the tools the query router chose, as well as the reason that the LLM gave to choose that option.

Now let's ask a culinary question. The recipe used to create the second vector store is for chicken gyros. Our application should be able to answer which are the ingredients needed for that recipe based on that source.
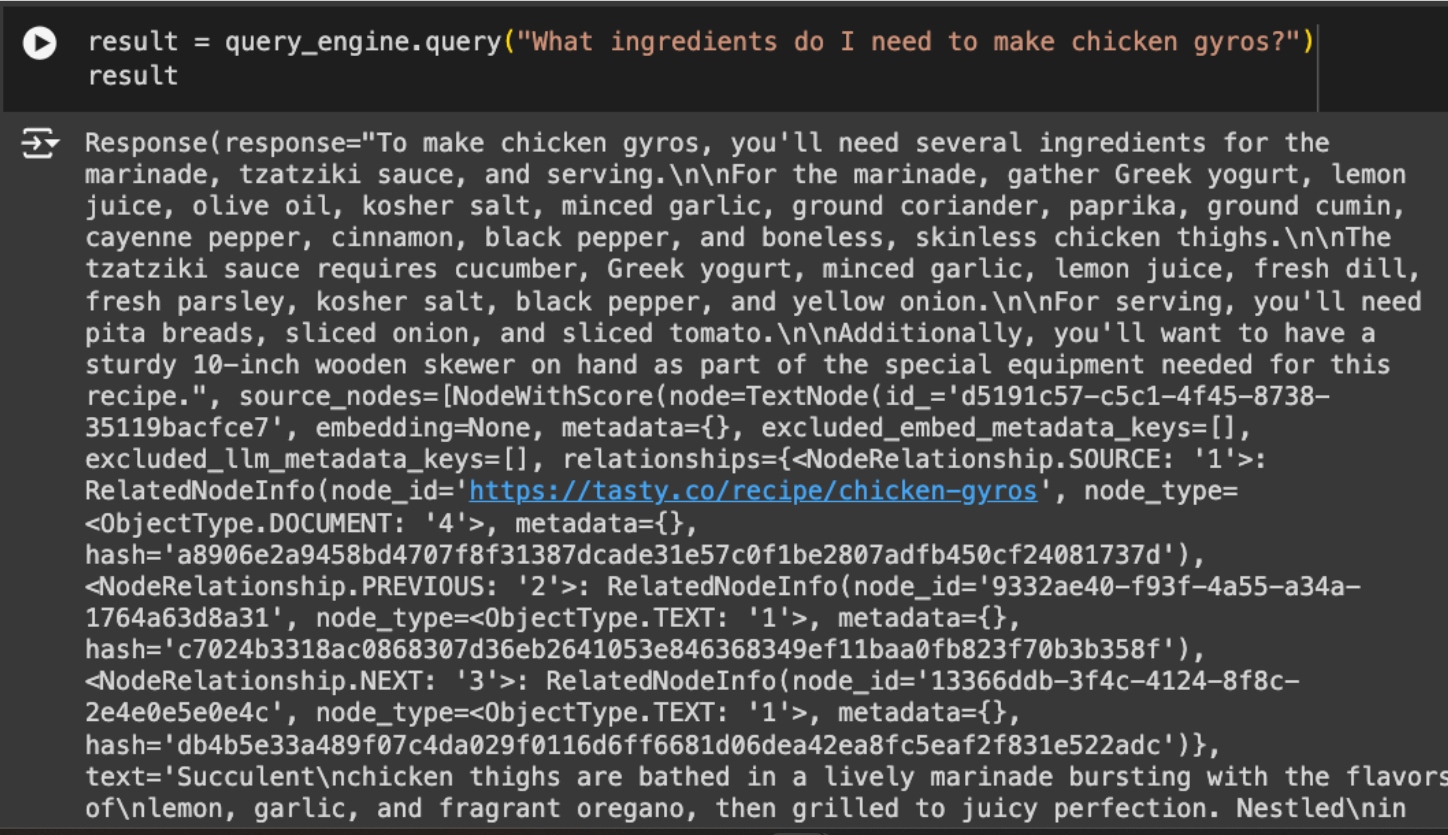
As we can see, the chicken gyros recipe vector store was correctly chosen to answer that question.

Finally, let's ask it a question that can be answered with a Google Search.

Conclusion
In conclusion, query routing is a great step towards a more advanced RAG application. It allows us to set up a base for a more complex system, where our app can better plan how to best answer questions. Also, query routing can be the glue that ties together other advanced techniques for your RAG application and makes them work together as a whole system.
However, the complexity of better RAG systems doesn't end with query routing. Query routing is just the first stepping stone for orchestration within RAG applications. The next stepping stone for making our RAG applications better reason, decide, and take actions based on the needs of the users are Agents. In later articles, we will be diving deeper into how Agents work within RAG and Generative AI applications in general.
Published at DZone with permission of Roger Oriol. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments