Building RAG Apps With Apache Cassandra, Python, and Ollama
A brief introduction to Apache Cassandra for retrieval-augmented generation using Python and Ollama for developing applications free of cost locally or on a server.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) is the most popular approach for obtaining real-time data or updated data from a data source based on text input by users. Thus empowering all our search applications with state-of-the-art neural search.
In RAG search systems, each user request is converted into a vector representation by embedding model, and this vector comparison is performed using various algorithms such as cosine similarity, longest common sub-sequence, etc., with existing vector representations stored in our vector-supporting database.
The existing vectors stored in the vector database are also generated or updated asynchronously by a separate background process.
 This diagram provides a conceptual overview of vector comparison
This diagram provides a conceptual overview of vector comparison
To use RAG, we need at least an embedding model and a vector storage database to be used by the application. Contributions from community and open-source projects provide us with an amazing set of tools that help us build effective and efficient RAG applications.
In this article, we will implement the usage of a vector database and embedding generation model in a Python application. If you are reading this concept for the first time or nth time, you only need tools to work, and no subscription is needed for any tool. You can simply download tools and get started.
Our tech stack consists of the following open-source and free-to-use tools:
- Operating system – Ubuntu Linux
- Vector database – Apache Cassandra
- Embedding model – nomic-embed-text
- Programming language – Python
Key Benefits of this Stack
- Open-source
- Isolated data to meet data compliance standards
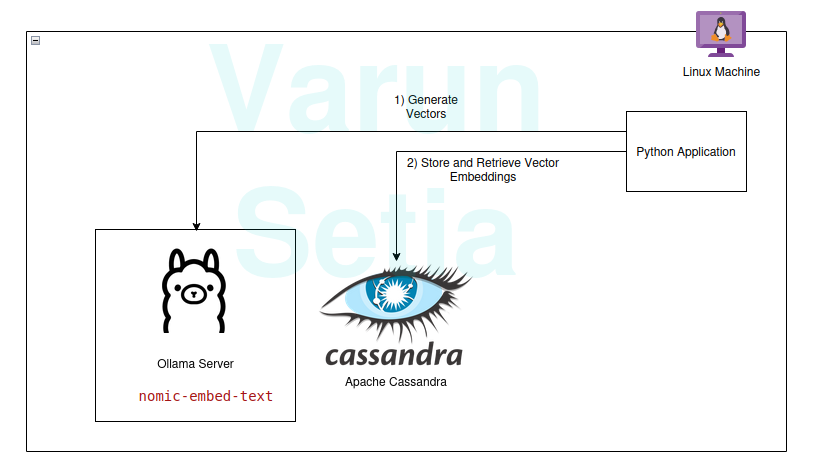
Implementation Walkthrough
You may implement and follow along if prerequisites are fulfilled; otherwise, read to the end to understand the concepts.
Prerequisites
- Linux (In my case, it's Ubuntu 24.04.1 LTS)
- Java Setup (OpenJDK 17.0.2)
- Python (3.11.11)
- Ollama
Ollama Model Setup
Ollama is an open-source middleware server that acts as an abstraction between generative AI and applications by installing all the necessary tools to make generative AI models available to consume as CLI and API in a machine. It has most of the openly available models like llama, phi, mistral, snowflake-arctic-embed, etc. It is cross-platform and can be easily configured in OS.
In Ollama, we will pull the nomic-embed-text model to generate embeddings.
Run in command line:
ollama pull nomic-embed-textThis model generates embeddings of size 768 vectors.
Apache Cassandra Setup and Scripts
Cassandra is an open-source NoSQL database designed to work with a high amount of workloads that require high scaling as per industry needs. Recently, it has added support for Vector search in version 5.0 that will facilitate our RAG use case.
Note: Cassandra requires Linux OS to work; it can also be installed as a docker image.
Installation
Download Apache Cassandra from https://cassandra.apache.org/_/download.html.
Configure Cassandra in your PATH.
Start the server by running the following command in the command line:
cassandraTable
Open a new Linux terminal and write cqlsh; this will open the shell for Cassandra Query Language. Now, execute the below scripts to create the embeddings keyspace, document_vectors table, and necessary index edv_ann_index to perform a vector search.
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';Note: content_vector VECTOR <FLOAT, 768> is responsible for storing vectors of 768 length that are generated by the model.
Milestone 1: We are ready with database setup to store vectors.
Python Code
This programming language certainly needs no introduction; it is easy to use and loved by the industry with strong community support.
Virtual Environment
Set up virtual environment:
sudo apt install python3-virtualenv && python3 -m venv myvenvActivate virtual environment:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activatePackages
Download Datastax Cassandra package:
pip install cassandra-driverDownload requests package:
pip install requestsFile
Create a file named app.py.
Now, write the code below to insert sample documents in Cassandra. This is the first step always to insert data in the database; it can be done by a separate process asynchronously. For demo purposes, I have written a method that will insert documents first in the database. Later on, we can comment on this method once the insertion of documents is successful.
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
Now, run this file using the commandline in the virtual environment:
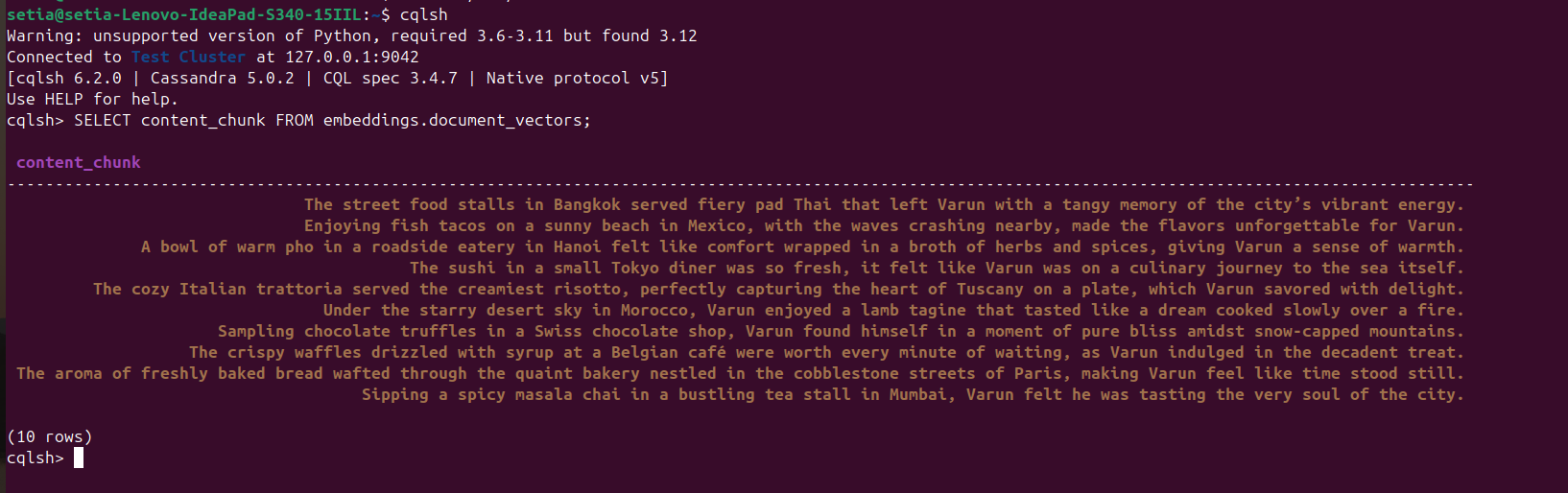
python app.pyOnce the file is executed and documents are inserted, this can be verified by querying the Cassandra database from the cqlsh console. For this, open cqlsh and execute:
SELECT content_chunk FROM embeddings.document_vectors;This will return 10 documents inserted in the database, as seen in the screenshot below.
Milestone 2: We are done with data setup in our vector database.
Now, we will write code to query documents based on cosine similarity. Cosine similarity is the dot product of two vector values. Its formula is A.B / |A||B|. This cosine similarity is internally supported by Apache Cassandra, helping us to compute everything in the database and handle large data efficiently.
The code below is self-explanatory; it fetches the top three results based on cosine similarity using ORDER BY <column name> ANN OF <text_vector> and also returns cosine similarity values. To execute this code, we need to ensure that indexing is applied to this vector column.
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')Remember to comment insertion code:
#insert_sample_data_in_cassandra()Now, execute the Python code by using python app.py.
We will get the output below:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204 You can see the cosine similarity of "The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy." is 0.8205469250679016, which is the closest match.
Final Milestone: We have implemented the RAG search.
Enterprise Applications
Apache Cassandra
For enterprises, we can use Apache Cassandra 5.0 from popular cloud vendors such as Microsoft Azure, AWS, GCP, etc.
Ollama
This middleware requires a VM compatible with Nvidia-powered GPU for running high-performance models, but we don't need high-end VMs for models used for generating vectors. Depending upon traffic requirements, multiple VMs can be used, or any generative AI service like Open AI, Anthropy, etc, whichever Total Cost of Ownership is lower for scaling needs or Data Governance needs.
Linux VM
Apache Cassandra and Ollama can be combined and hosted in a single Linux VM if the use case doesn't require high usage to lower the Total Cost of Ownership or to address Data Governance needs.
Conclusion
We can easily build RAG applications by using Linux OS, Apache Cassandra, embedding models (nomic-embed-text) used via Ollama, and Python with good performance without needing any additional cloud subscription or services in the comfort of our machines/servers.
However, hosting a VM in server(s) or opt for a cloud subscription for scaling as an enterprise application compliant with scalable architectures is recommended. In this Apache, Cassandra is a key component to do the heavy lifting of our vector storage and vector comparison and Ollama server for generating vector embeddings.
That's it! Thanks for reading 'til the end.
Opinions expressed by DZone contributors are their own.
Comments