Building A Log Analytics Solution 10 Times More Cost-Effective Than Elasticsearch
Inverted indexing in Apache Doris 2.0.0 realizes two times faster log query performance than Elasticsearch with 1/5 of the storage space it uses.
Join the DZone community and get the full member experience.
Join For FreeLogs often take up the majority of a company's data assets. Examples of logs include business logs (such as user activity logs) and Operation and Maintenance logs of servers, databases, and network or IoT devices.
Logs are the guardian angel of business. On the one hand, they provide system risk alerts and help engineers quickly locate root causes in troubleshooting. On the other hand, if you zoom them out by time range, you might identify some helpful trends and patterns, not to mention that business logs are the cornerstone of user insights.
However, logs can be a handful because:
- They flow in like crazy. Every system event or click from the user generates a log. A company often produces tens of billions of new logs per day.
- They are bulky. Logs are supposed to stay. They might not be useful until they are. So a company can accumulate up to PBs of log data, many of which are seldom visited but take up huge storage space.
- They must be quick to load and find. Locating the target log for troubleshooting is literally like looking for a needle in a haystack. People long for real-time log writing and real-time responses to log queries.
Now you can see a clear picture of what an ideal log processing system is like. It should support the following:
- High-throughput real-time data ingestion: It should be able to write blogs in bulk and make them visible immediately.
- Low-cost storage: It should be able to store substantial amounts of logs without costing too many resources.
- Real-time text search: It should be capable of quick text search.
Common Solutions: Elasticsearch and Grafana Loki
There exist two common log processing solutions within the industry, exemplified by Elasticsearch and Grafana Loki, respectively.
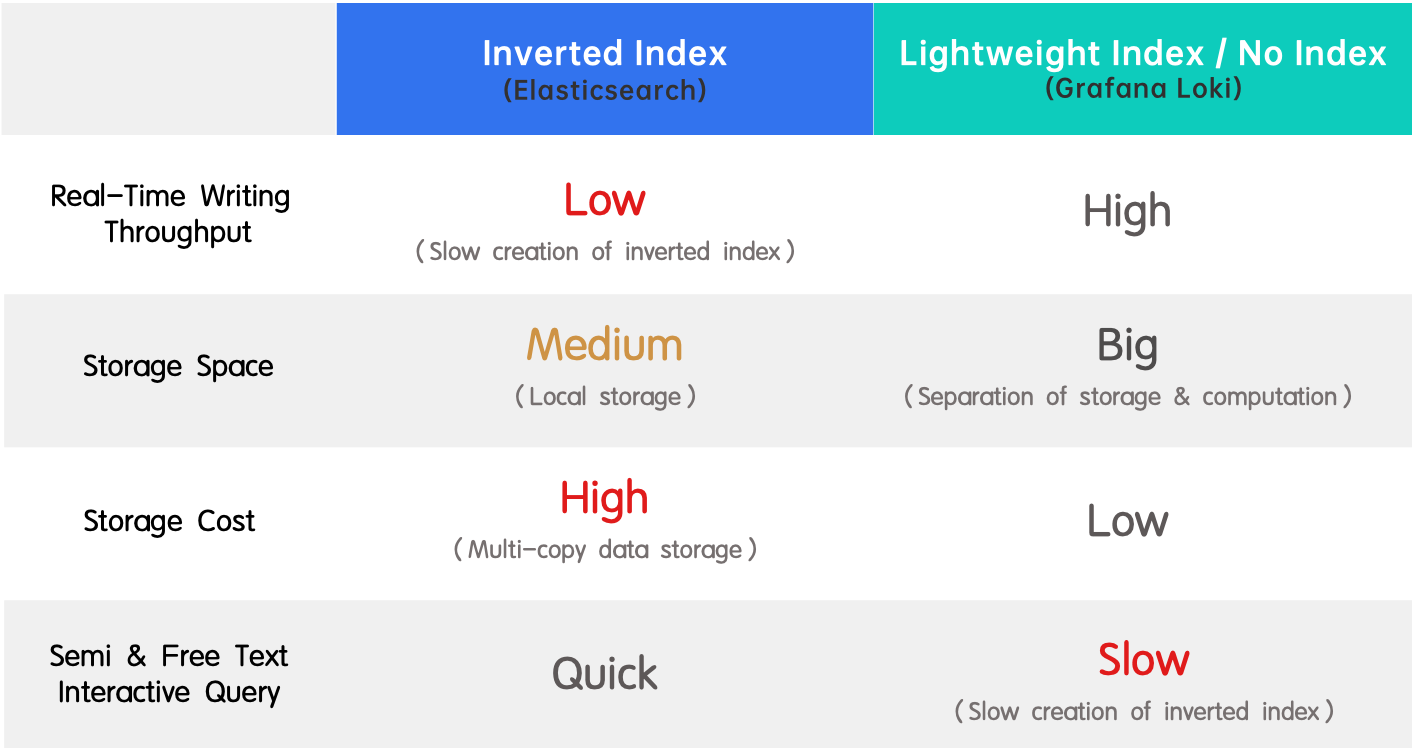
- Inverted index (Elasticsearch): It is well-embraced due to its support for full-text search and high performance. The downside is the low throughput in real-time writing and the huge resource consumption in index creation.
- Lightweight index / no index (Grafana Loki): It is the opposite of an inverted index because it boasts high real-time write throughput and low storage cost but delivers slow queries.
Introduction to Inverted Index
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
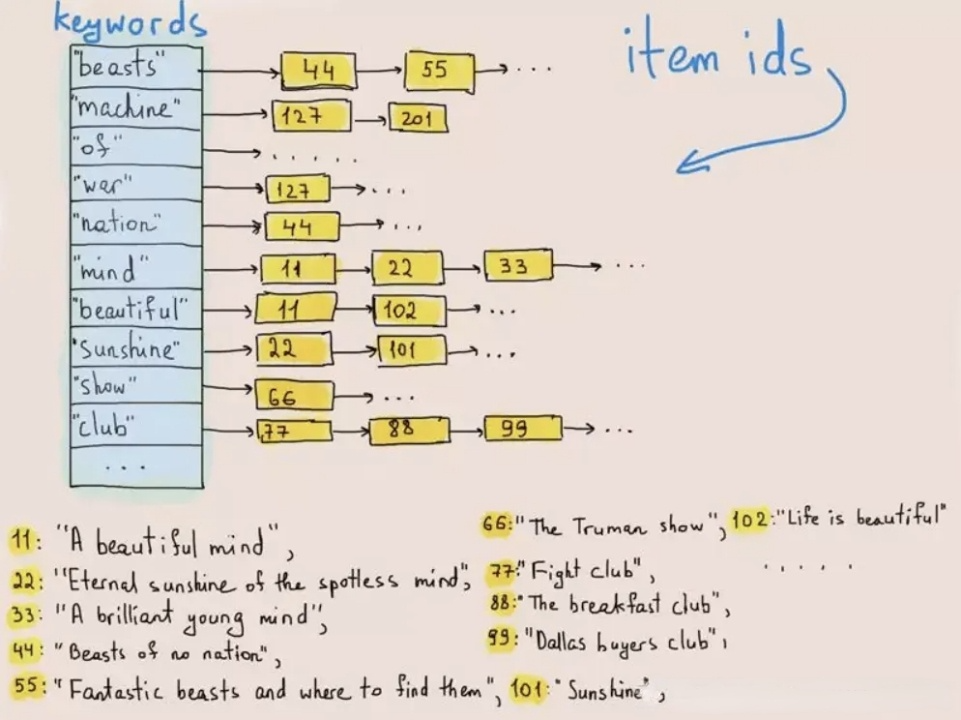
Inverted indexing was originally used to retrieve words or phrases in texts. The figure below illustrates how it works:
Upon data writing, the system tokenizes texts into terms and stores these terms in a posting list which maps terms to the ID of the row where they exist. In text queries, the database finds the corresponding row ID of the keyword (term) in the posting list and fetches the target row based on the row ID. By doing so, the system won't have to traverse the whole dataset and thus improves query speeds by orders of magnitudes.
In the inverted indexing of Elasticsearch, quick retrieval comes at the cost of writing speed, writing throughput, and storage space. Why? Firstly, tokenization, dictionary sorting, and inverted index creation are all CPU- and memory-intensive operations. Secondly, Elasticssearch has to store the original data, the inverted index, and an extra copy of data stored in columns for query acceleration. That's triple redundancy.
But without an inverted index, Grafana Loki, for example, is hurting user experience with its slow queries, which is the biggest pain point for engineers in log analysis.
Simply put, Elasticsearch and Grafana Loki represent different tradeoffs between high writing throughput, low storage cost, and fast query performance. What if I tell you there is a way to have them all? We have introduced inverted indexes in Apache Doris 2.0.0 and further optimized it to realize two times faster log query performance than Elasticsearch with 1/5 of the storage space it uses. Both factors combined, it is a 10 times better solution.
Inverted Index in Apache Doris
Generally, there are two ways to implement indexes: external indexing system or built-in indexes.
External indexing system: You connect an external indexing system to your database. In data ingestion, data is imported to both systems. After the indexing system creates indexes, it deletes the original data within itself. When data users input a query, the indexing system provides the IDs of the relevant data, and then the database looks up the target data based on the IDs.
Building an external indexing system is easier and less intrusive to the database, but it comes with some annoying flaws:
- The need to write data into two systems can result in data inconsistency and storage redundancy.
- Interaction between the database and the indexing system brings overheads, so when the target data is huge, the query across the two systems can be slow.
- It is exhausting to maintain two systems.
In Apache Doris, we opt for the other way. Built-in inverted indexes are more difficult to make, but once it is done, it is faster, more user-friendly, and trouble-free to maintain.
In Apache Doris, data is arranged in the following format. Indexes are stored in the Index Region:
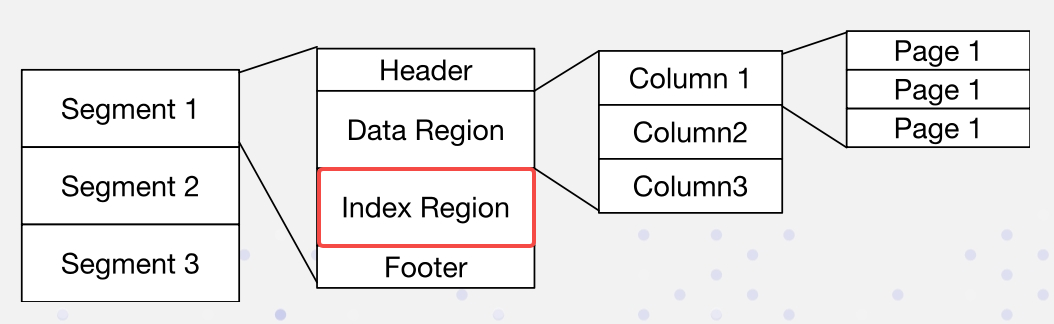
We implement inverted indexes in a non-intrusive manner:
- Data ingestion and compaction: As a segment file is written into Doris, an inverted index file will be written, too. The index file path is determined by the segment ID and the index ID. Rows in segments correspond to the docs in indexes, so are the RowID and the DocID.
- Query: If the
whereclause includes a column with inverted index, the system will look up in the index file, return a DocID list, and convert the DocID list into a RowID Bitmap. Under the RowID filtering mechanism of Apache Doris, only the target rows will be read. This is how queries are accelerated.
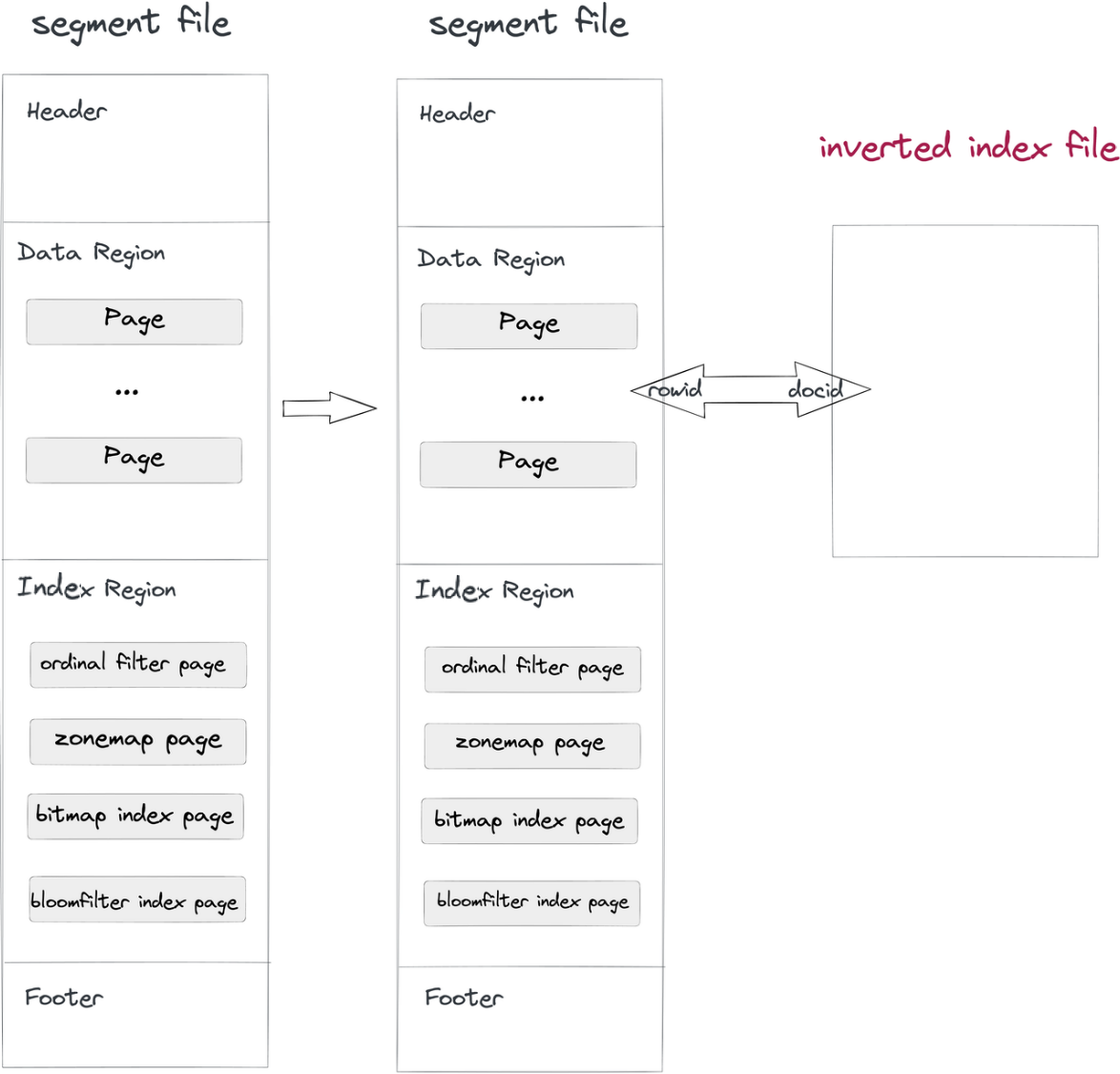
Such a non-intrusive method separates the index file from the data files, so you can make any changes to the inverted indexes without worrying about affecting the data files themselves or other indexes.
Optimizations for Inverted Index
General Optimizations
C++ Implementation and Vectorization
Different from Elasticsearch, which uses Java, Apache Doris implements C++ in its storage modules, query execution engine, and inverted indexes. Compared to Java, C++ provides better performance, allows easier vectorization, and produces no JVM GC overheads. We have vectorized every step of inverted indexing in Apache Doris, such as tokenization, index creation, and queries. To provide you with a perspective, in inverted indexing, Apache Doris writes data at a speed of 20MB/s per core, which is four times that of Elasticsearch (5MB/s).
Columnar Storage and Compression
Apache Lucene lays the foundation for inverted indexes in Elasticsearch. As Lucene itself is built to support file storage, it stores data in a row-oriented format.
In Apache Doris, inverted indexes for different columns are isolated from each other, and the inverted index files adopt columnar storage to facilitate vectorization and data compression.
By utilizing Zstandard compression, Apache Doris realizes a compression ratio ranging from 5:1 to 10:1, faster compression speeds, and 50% less space usage than GZIP compression.
BKD Trees for Numeric / Datetime Columns
Apache Doris implements BKD trees for numeric and datetime columns. This not only increases the performance of range queries but is a more space-saving method than converting those columns to fixed-length strings. Other benefits of it include:
- Efficient range queries: It is able to quickly locate the target data range in numeric and datetime columns.
- Less storage space: It aggregates and compresses adjacent data blocks to reduce storage costs.
- Support for multi-dimensional data: BKD trees are scalable and adaptive to multi-dimensional data types, such as GEO points and ranges.
In addition to BKD trees, we have further optimized the queries on numeric and datetime columns.
- Optimization for low-cardinality scenarios: We have fine-tuned the compression algorithm for low-cardinality scenarios, so decompressing and de-serializing large amounts of inverted lists will consume fewer CPU resources.
- Pre-fetching: For high-hit-rate scenarios, we adopt pre-fetching. If the hit rate exceeds a certain threshold, Doris will skip the indexing process and start data filtering.
Tailored Optimizations to OLAP
Usually, log analysis is a simple kind of query with no need for advanced features (e.g., relevance scoring in Apache Lucene). The bread and butter capability of a log processing tool is quick queries and low storage costs. Therefore, in Apache Doris, we have streamlined the inverted index structure to meet the needs of an OLAP database.
- In data ingestion, we prevent multiple threads from writing data into the same index and thus avoid overheads brought by lock contention.
- We discard forward index files and Norm files to clear storage space and reduce I/O overheads.
- We simplify the computation logic of relevance scoring and ranking to further reduce overheads and increase performance.
In light of the fact that logs are partitioned by time range and historical logs are visited less frequently, we plan to provide more granular and flexible index management in future versions of Apache Doris:
- Create an inverted index for a specified data partition: create an index for logs of the past seven days, etc.
- Delete inverted index for a specified data partition: delete index for logs from over one month ago, etc. (so as to clear out index space).
Benchmarking
We tested Apache Doris on publicly available datasets against Elasticsearch and ClickHouse.
For a fair comparison, we ensure uniformity of testing conditions, including benchmarking tool, datasets, and hardware.
Apache Doris vs. Elasticsearch
- Benchmarking tool: ES Rally, the official testing tool for Elasticsearch
- Dataset: 1998 World Cup HTTP Server Logs (self-contained dataset in ES Rally)
- Data Size (Before Compression): 32G, 247 million rows, 134 bytes per row (on average)
- Query: 11 queries, including keyword search, range query, aggregation, and ranking; Each query is serially executed 100 times.
- Environment: 3 × 16C 64G cloud virtual machines
Results of Apache Doris:
- Writing Speed: 550 MB/s, 4.2 times that of Elasticsearch
- Compression Ratio: 10:1
- Storage Usage: 20% that of Elasticsearch
- Response Time: 43% that of Elasticsearch

Apache Doris vs. ClickHouse
As ClickHouse launched an inverted index as an experimental feature in v23.1, we tested Apache Doris with the same dataset and SQL as described in the ClickHouse blog and compared the performance of the two under the same testing resource, case, and tool.
- Data: 6.7G, 28.73 million rows, the Hacker News dataset, Parquet format
- Query: 3 keyword searches, counting a number of occurrences of the keywords "ClickHouse," "OLAP," OR "OLTP," and "avx" AND "sve".
- Environment: 1 × 16C 64G cloud virtual machine
Result: Apache Doris was 4.7 times, 18.5 times, and 12 times faster than ClickHouse in the three queries, respectively.

Usage and Example
- Dataset: one million comment records from Hacker News
Step 1: Specify the inverted index to the data table upon table creation.
Parameters:
- INDEX idx_comment (
comment): create an index named "idx_comment" comment for the "comment" column - USING INVERTED: specify inverted index for the table
- PROPERTIES("parser" = "english"): specify the tokenization language to English
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Note: You can add an index to an existing table via ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). Different from that of the smart index and secondary index, the creation of an inverted index only involves the reading of the comment column, so it can be much faster.)
Step 2: Retrieve the words"OLAP" and "OLTP" in the comment column with MATCH_ALL. The response time here was 1/10 of that in hard matching with like. (The performance gap widens as data volume increases.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
For more feature introduction and usage guide, see documentation: Inverted Index
Wrap-up
In a word, what contributes to Apache Doris' 10-time higher cost-effectiveness than Elasticsearch is its OLAP-tailored optimizations for inverted indexing, supported by the columnar storage engine, massively parallel processing framework, vectorized query engine, and cost-based optimizer of Apache Doris.
As proud as we are about our own inverted indexing solution, we understand that self-published benchmarks can be controversial, so we are open to feedback from any third-party testers and see how Apache Doris works in real-world cases.
Published at DZone with permission of Frank Z. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments