Self-Healing Data Pipelines: The Next Big Thing in Data Engineering?
Build self-healing data pipelines on GCP using AI-powered tools like GPT-4 and Python to detect and fix errors automatically.
Join the DZone community and get the full member experience.
Join For FreeI'm an enthusiastic data engineer who always looks out for various challenging problems and tries to solve them with a simple POC that everyone can relate to. Recently, I have thought about an issue that most data engineers face daily. I have set alerts on all the batch and streaming data pipelines. When the errors reach a threshold limit or if the data pipeline fails, we get failure notifications immediately in the email inbox.
Everything seemed fine until I noticed one of our critical datasets could not be loaded into BigQuery. After investigating the error logs, I found several messages with "missing required data." I felt ‘lost’ seeing these frequent raw data issues from a user-inputted file.
Handling data inconsistencies, notably missing or formatting data issues, can cause significant problems downstream in analytics and operational workflows. There is a downstream report that relies on this ingested data. This report is extensively used for daily reporting on the key metrics of how business reflects in several areas and gives crucial data points to decide how to navigate. In this critical report, all C-level stakeholders rely on presenting metrics and discussing challenges and the go-forward plan.
I spent hours manually inspecting the source CSV files, as this vast file consists of an enormous volume of transactions sourced from another upstream application. Identifying the problematic rows and correcting them is vital. By the time I solved the issues, the deadline had passed, and the stakeholders were understandably frustrated. That day, I realized how fragile traditional data pipelines can be. They break easily, and fixing them multiple times requires manual intervention, which is time-consuming and error-prone.
Have you ever faced a similar situation? Have you spent countless hours debugging data pipelines, only to realize the root cause was a simple formatting error or missing required field? If so, you're not alone. Data engineers worldwide struggle with these challenges daily. But what if there was a way to build pipelines that could "heal" themselves? That's precisely what I set out to achieve.
How Self-Healing Data Pipeline Works
The idea of a self-healing pipeline is simple: When errors occur during data processing, the pipeline should automatically detect, analyze, and correct them without human intervention. Traditionally, fixing these issues requires manual intervention, which is time-consuming and prone to errors.
There are several ways to idealize this, but using AI agents is the best method and a futuristic approach for data engineers to self-heal failed pipelines and auto-correct them dynamically. In this article, I will show a basic implementation of how to use LLMs like the GPT-4/DeepSeek R1 model to self-heal data pipelines by using LLM’s recommendation on failed records and applying the fix through the pipeline while it is still running. The provided solution can be scaled to large data pipelines and extended to more functionalities by using the proposed method.
Here's how I built a practical pipeline leveraging OpenAI API that uses the GPT-4 model in a cloud environment. The basic steps followed are:
- Upload a source file into Google Cloud Storage Bucket. You can use any local or any other cloud storage if you don't have access to the GCP cloud.
- Create the data model for ingesting the original data into the BigQuery table and error records into the Error table.
- Read the source file from the CSV and identify the
Cleandataset and invalid records (error rows) dataset from the input data. - Ingest the
Cleandataset into BigQuery and pass theError Rowsdataset to LLM using the Prompt. - For each Error Row, OpenAI’s GPT API analyzes and provides an intelligent product ID assignment.
- Google BigQuery to store and retrieve product information dynamically.
- Python-based automation for seamless integration.
Here is the complete codebase on my GitHub.
1. Reading Input Data from Cloud Storage
The pipeline starts by reading a CSV file uploaded by clients stored in Cloud Storage. We can leverage a Cloud Function — serverless execution of pipeline steps — to trigger whenever a new file is uploaded to the bucket. The function reads the file using the google-cloud-storage library and parses it into a Pandas DataFrame for further processing.
You can write some data quality checks before passing on to the next step, where the data gets ingested into the BigQuery table. However, data issues are dynamic in real-world scenarios, and you can't predict and write all test cases, which makes the code complex and unreadable.
In our use case, the CSV file contains fields ProductID, Price, name, saleAmount. Below is the sample file with data (also missing data in both ProductID and Price fields).
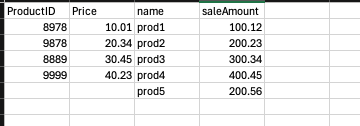
# Read CSV from GCS
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(file_name)
data = blob.download_as_text()
df = pd.read_csv(io.StringIO(data))
2. Ingesting Data into BigQuery
Next, the pipeline attempts to load the data into BigQuery. If any rows fail due to schema mismatches, data type errors, or missing fields, they are captured and logged for further analysis. This step is essential to detect the underlying error information that will be used to identify a possible solution by OpenAI API.
# Function to clean and preprocess data
def clean_data(df):
avg_price = get_average_price()
df["Price"] = df["Price"].fillna(avg_price)
# Log and remove rows with issues
error_rows = df[df["ProductID"].isna()]
clean_df = df.dropna(subset=["ProductID"])
return clean_df, error_rows
# Function to query BigQuery for an average price
def get_average_price():
client = bigquery.Client()
query = f"SELECT AVG(Price) AS avg_price FROM `{BQ_PROJECT_ID}.{BQ_DATASET_ID}.Product_Info`"
try:
df = client.query(query).to_dataframe()
avg_price = df["avg_price"][0]
print(f"Fetched Average Price: {avg_price}")
return avg_price
except Exception as e:
print(f"Error fetching average price: {e}")
return None
Notice that avg_price = get_average_price() is getting it from BigQuery lookup.
After the clean dataset insert:
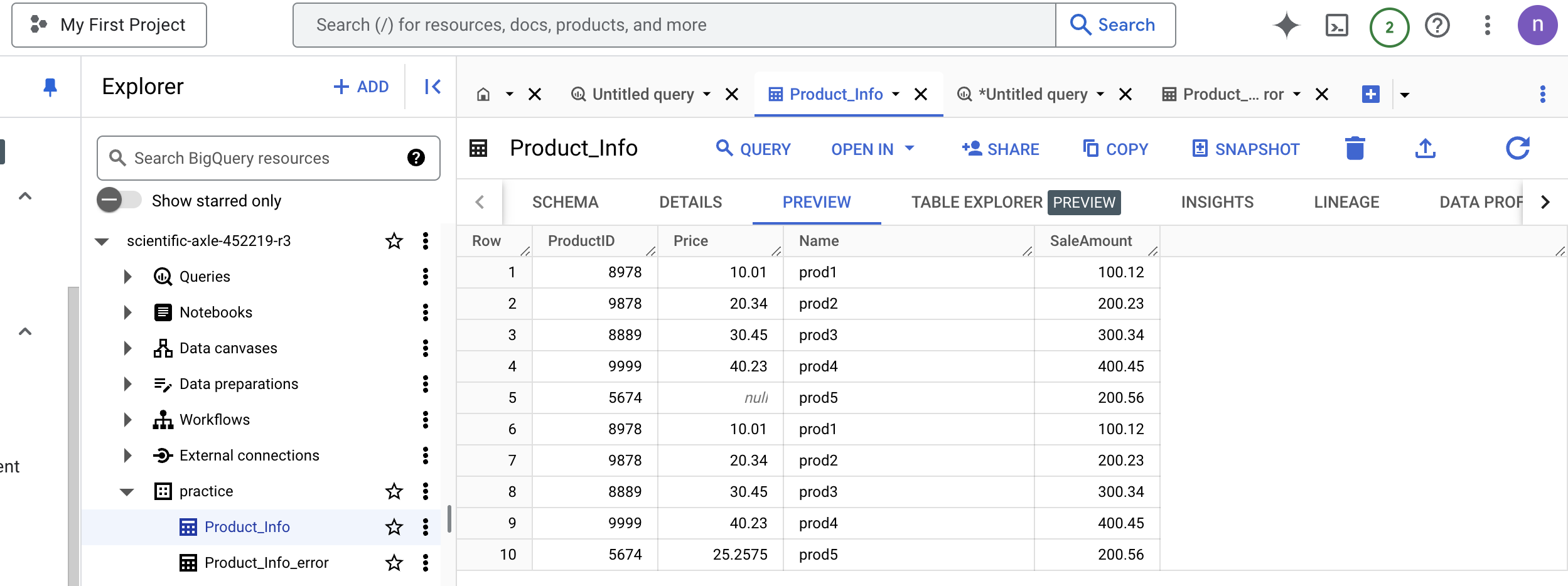
3. Analyzing Errors With LLMs
Analyzing errors is the key step in the entire pipeline, and this is where the magic happens. The failed records were sent to a large language model (LLM) like GPT-4 or DeepSeek R1 for analysis. The LLM examines the errors and suggests corrections and a fixed record.
For example, suppose a date field is formatted incorrectly. In that case, the LLM might suggest the correct formatted record from a String to an Integer conversion or String to Date/Timestamp conversion and vice versa. In cases where the data is expected but found null, based on the rules enforced by our code, missing values with 'Average' or Default values are fixed to ensure data ingestion is successful.
Implementing the ChatCompletion Request With Retry Mechanism
To ensure resilience, we implement a retry mechanism using tenacity. The function sends error details to GPT and retrieves suggested fixes. In our case, the 'functions' list was created and passed to the JSON payload using the ChatCompletion Request.
Note that the 'functions' list is the list of all functions available to fix the known or possible issues using the Python functions we have created in our pipeline code. GPT analyzes the input prompt and the error message to determine if it is best to invoke a specific function listed on the 'functions' list to fix the issue.
Accordingly, GPT’s response provides structured data indicating which function should be called. GPT does not execute the function directly. Instead, the pipeline will execute it.
@retry(wait=wait_random_exponential(min=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, functions=None, model=GPT_MODEL):
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + openai.api_key,
}
json_data = {"model": model, "messages": messages}
if functions is not None:
json_data.update({"functions": functions})
try:
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json=json_data,
)
return response.json()
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
# Function to send ChatCompletion request to OpenAI API
functions = [
{
"name": "assign_product_id",
"description": "assigning a unique ProductID",
"parameters": {
"type": "object",
"properties": {
"ProductID": {
"type": "integer",
"description": "The product ID to assign."
},
}
},
}
]
assign_product_id is the function listed on the 'functions' list that GPT can call if required. In our case, the ProductID is missing for the last two rows in the CSV file. Hence, the GPT called the specific assign_product_id function to determine the ProductID value.
The function assign_product_id fetches the highest assigned ProductID from BigQuery and increments it for subsequent use. If it runs for the first time or no data is available in the BigQuery table, it will assign the default 99999 as ProductID.
def assign_product_id():
client = bigquery.Client()
# table_ref = client.dataset(BQ_DATASET_ID).table(BQ_TABLE_ID)
query = f"""
Select max(ProductID) as max_id from `{BQ_PROJECT_ID}.{BQ_DATASET_ID}.{BQ_TABLE_ID}` WHERE ProductID < 99999
"""
df = client
try:
df = client.query(query).to_dataframe()
except Exception as e:
print(f"Error fetching max ProductID: {e}")
return None
return df["max_id"][0] + 1 if not df.empty else 99999
4. Applying Automatic Corrections
The pipeline applies the GPT’s suggestions to the failed records and re-attempts to ingest them into BigQuery. The data is stored in the main table if the corrections are successful. If not, the irreparable records are logged into a separate error table for manual review.
In instances where the field is required and unique, GPT can get the unique ProductID value from BigQuery and add a plus 1 to it to maintain the uniqueness. Consider cases where there were multiple error rows in the pipeline; each record is processed sequentially with the fix offered by the GPT’s response and updates the Error Record with SUGGESTED values.
In the below code, ProductID gets replaced by the value fetched from assign_product_id() BigQuery table. When there are multiple error rows, each receives a unique number by incrementing the ProductID.
# Function to send error data to GPT-4 for analysis
def analyze_errors_with_gpt(error_rows):
if error_rows.empty:
return error_rows
new_product_id = assign_product_id()
for index, row in error_rows.iterrows():
prompt = f"""
Fix the following ProductID by assigning a unique ProductID from the bigquery table Product_Info:
{row.to_json()}
"""
chat_response = chat_completion_request(
model=GPT_MODEL,
messages=[{"role": "user", "content": prompt}],
functions=functions
)
if chat_response is not None:
try:
if chat_response["choices"][0]["message"]:
response_content = chat_response["choices"][0]["message"]
else:
print("Chat response content is None")
continue
except json.JSONDecodeError as e:
print(f"Error decoding JSON response: {e}")
continue
if 'function_call' in response_content:
if response_content['function_call']['name'] == 'assign_product_id':
res = json.loads(response_content['function_call']['arguments'])
res['product_id'] = new_product_id
error_rows.at[index, "ProductID"] = res['product_id']
new_product_id += 1 # Increment the ProductID for the next row
print(f"Assigned ProductID: {res['product_id']}")
else:
print("Function not supported")
else:
chat.add_prompt('assistant', response_content['content'])
else:
print("ChatCompletion request failed. Retrying...")
return error_rows
5. Ingesting the Fixed Rows into BigQuery Table
The main function reads data from Google Cloud Storage (GCS), cleans it, and loads valid data into BigQuery while fixing errors dynamically.
# Main function to execute the pipeline
def main():
bucket_name = "self-healing-91"
file_name = "query_results.csv"
# Read CSV from GCS
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(file_name)
data = blob.download_as_text()
df = pd.read_csv(io.StringIO(data))
# Clean data and identify errors
clean_df, error_rows = clean_data(df)
# Load valid data into BigQuery
load_to_bigquery(clean_df, BQ_TABLE_ID)
# Process errors if any
if not error_rows.empty:
# Analyze errors with GPT-4
error_rows = analyze_errors_with_gpt(error_rows)
load_to_bigquery(error_rows, BQ_TABLE_ID)
print("Fixed Errors loaded successfully into BigQuery original table.")
Post error fix data, particularly check rows from 66-68. After fetching the max value as 10000 ProductID from the BigQuery table, they're incremented by one. Also, the Price field with missing information in the error rows was replaced by Avg(Price) from the BigQuery table.

6. Logging and Monitoring
Throughout the process, errors and pipeline activities are logged using Cloud Logging. This ensures that engineers can monitor the pipeline's health and troubleshoot issues.
Tools and Technologies Used
Here are the key tools and technologies I used to build and test this pipeline:
- Cloud storage: This is for storing input CSV files.
- Cloud functions: For serverless execution of pipeline steps.
- BigQuery: This is used to store cleaned data and error logs.
- GPT-4/DeepSeek R1: For analyzing and suggesting corrections for failed records.
- Cloud logging: This is for monitoring and troubleshooting.
- Cloud composer: This is used to orchestrate the pipeline using Apache Airflow.
Challenges Faced
1. LLM Integration
Integrating an LLM into the pipeline was tricky. I had to ensure that the API calls were efficient and that the LLM’s responses were accurate. Additionally, there were cost considerations, as LLM APIs can be expensive for large datasets. Just know that you must set up an API key for this service.
For example, for OpenAI, you must visit https://platform.openai.com/ to register and generate the new API key and use it in the pipeline when sending the API call with a prompt.
2. Error Handling
Designing a robust error-handling mechanism was challenging. I had to account for various errors, from schema mismatches to network issues, and ensure that the pipeline could handle them gracefully. A pipeline could face numerous problems, and all issues can't be solved dynamically. Examples are File is Empty, and BigQuery Table doesn’t exist.
3. Scalability
As the volume of data grew, I had to optimize the pipeline for scalability. This involved partitioning data in BigQuery and using Dataflow for large-scale processing.
4. Cost Management
While GCP offers powerful tools, they come at a cost. I had to carefully monitor usage and optimize the pipeline to avoid unexpected bills. OpenAI API cost is another factor that you need to monitor carefully.
Final Thoughts and Key Notes
Building a self-healing pipeline is a game-changer for data engineers. It reduces manual intervention, improves efficiency, and ensures data quality. However, it’s not a silver bullet. While self-healing pipelines can save time, they come with additional costs, such as LLM API fees and increased Cloud Function usage. It’s essential to weigh these costs against the benefits.
If you're new to self-healing pipelines, start with a small project — experiment with LLM integration and error handling before scaling up. Regularly monitor your pipeline’s performance and costs. Use tools like Cloud Monitoring and Cloud Logging to identify bottlenecks and optimize accordingly. Finally, work closely with data scientists, analysts, and business stakeholders to understand their needs and ensure the pipeline delivers value when business requirements change.
In conclusion, self-healing pipelines represent the future of data engineering. We can build robust, efficient, intelligent pipelines that minimize downtime and maximize productivity by leveraging tools like GCP and LLMs. Please explore this approach if you've ever struggled with fragile data pipelines. The initial effort is worth the long-term benefits.
What are your thoughts on self-healing pipelines? Have you tried building one? Share your experiences in the comments below.
Opinions expressed by DZone contributors are their own.
Comments