From Runtime Fires to Pre‑Flight Control: A Gatekeeper Model for Spark SQL
Teams racing for speed and savings won’t win with bigger clusters — they’ll win by rejecting bad queries before Spark spins up a single core.
Join the DZone community and get the full member experience.
Join For FreeA Quick Back‑Story
It was 2 a.m., the cluster dashboard was glowing red, and the only thing separating me from a full night’s sleep was a stray comma in a user‑supplied query. Spark had happily fired up a handful of executors before realising the SQL was garbage. Cue wasted compute, angry Slack pings, and a small dent in our budget.
After the third “why is the job queue jammed again?” post‑mortem, I decided to build a gatekeeper: something that could shout “Stop!” the moment a query looked fishy — before Spark touched a single core.
Enter Google’s Agent Development Kit (ADK) and a no‑nonsense parser called SQLGlot.
False Starts: Approaches I Tried First
Before landing on ADK + SQLGlot, I ran down a short list of “obvious” options — each promising a quick win, each ultimately coming up short:
| Attempt | What I liked | Why it fizzled |
|---|---|---|
| SQLGlot solo | Fast parse, Spark dialect support | Great at brute‑force syntax, terrible UX—its raw errors read like regex soup. Needed a translator. |
| JSQLParser | Mature Java library; easy to call from JVM services | Didn’t understand Spark‑specific extensions (LATERAL VIEW, back‑ticks, map types). Too many false negatives. |
Generic linters (sqlfluff, sqlint) |
Zero‑setup CLI tools | Targeted ANSI SQL; flagged valid Spark queries as broken and missed Spark‑only mistakes. |
| Spark Connect + Spring Boot interceptor | Caught queries at the service layer | Added network hop + brittle code to maintain; still produced Spark’s cryptic errors. |
Each attempt solved part of the problem but left either poor error messages or blind spots in edge cases. That’s when I realised I needed a hybrid: deterministic parsing plus a small dose of LLM smarts.
Why Spark’s Native Parser Isn’t Enough
Spark’s Catalyst engine doesn’t fully validate a query when you submit it. It defers most checks until an action (collect, write, etc.) forces physical‑plan generation. That lazy design keeps the API flexible, but it opens a few traps:
| Pain Point | What happens | Real‑world fallout |
|---|---|---|
| Early compute allocation | Spark allocates executors and starts building the DAG before the analyzer resolves every column and function. | A single typo can spin up a 100‑node cluster that dies 30 s later—burning money and swamping logs. |
| Late‑stage failures | Errors often surface after the first shuffle, when Spark realises a column doesn’t exist. | Partial jobs litter S3/HDFS with temp files and leave confused developers hunting through stack traces. |
Cryptic AnalysisExceptions |
Messages reference logical‑plan nodes, not the user’s SQL. | “Unable to resolve field xyz” at 4 a.m. ≠ , actionable feedback for end users. |
| Slow feedback loops | Users wait several minutes for a failure that a parser could have caught in milliseconds. | Iteration velocity plummets |
| Auto‑scaling whiplash | Invalid queries trigger rapid scale‑up followed by scale‑down cycles. | Costs swing wildly—hard to defend. “It was a misplaced comma.” |
If your platform lets analysts or SaaS users fire SQL at Spark, you need an earlier trip wire — something that blocks bad queries before Catalyst gets involved.
The Idea in Plain English
- Ask a deterministic tool first. SQLGlot parses the query in a few milliseconds.
- If the tool screams, hand its cryptic message to a small LLM agent that can translate it into something a human understands.
- If the tool smiles, run a second LLM pass that looks for sneakier semantic issues—things a pure parser can’t spot.
- Return one tidy JSON blob to the caller.
That’s it. No mystery boxes, no hidden side effects.
An Overview of the Flow
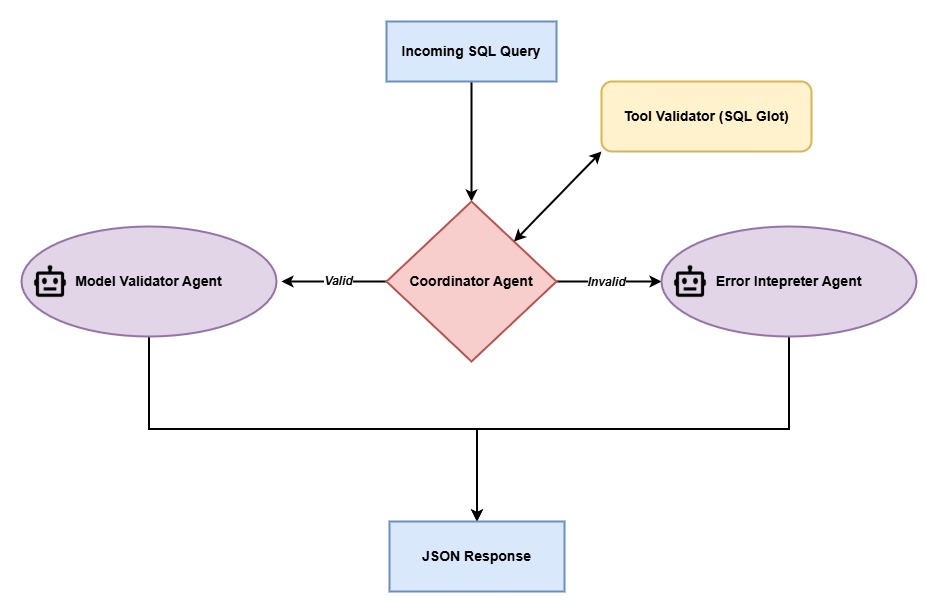
The Cast
- Tool validator – A tool that performs fast syntax checks using a third-party library, SQLGlot.
- Error interpreter agent – LLM agent that turns “Expected ) at line 1 col 43” into “You forgot a closing parenthesis after the WHERE clause.”
- Model validator agent – Second LLM pass for ambiguous aliases, misuse of window functions, etc.
- Coordinator agent– A few lines of glue code that decide which agent runs next.
Code You Can Squint At
Why a custom agent? The workflow branches: If the parser passes, we call a model validator; if it fails, we call an error interpreter. That conditional logic is awkward in a straight sequential/composite chain, so I wrote a dozen‑line CoordinatorAgent to handle the if/else cleanly.
class CoordinatorAgent(BaseAgent):
"""
Custom agent for a sql validation workflow.
This agent orchestrates a sequence of LLM agents to perform syntax validation on sql query.
"""
# # --- Field Declarations for Pydantic ---
# # Declare the agents passed during initialization as class attributes with type hints
model_validator_agent: LlmAgent = Field(...)
error_intepreter_agent: LlmAgent = Field(...)
# model_config allows setting Pydantic configurations if needed, e.g., arbitrary_types_allowed
model_config = {"arbitrary_types_allowed": True}
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
"""
Implements the custom orchestration logic for the sql validation.
Uses the instance attributes assigned by Pydantic (e.g., self.model_validator_agent).
"""
# Ensure session state is initialized
print("-----------------------------Session Start---------------------------------")
print("Session state:", ctx.session.state)
print("Context:", ctx.user_content)
sql_query = ctx.user_content.parts[0].text
print(sql_query)
if not sql_query:
yield Event.text("No SQL input found in session state under key 'input'.")
return
print(sql_query)
ctx.session.state.clear()
output = validate_sql_syntax(sql_query)
yield Event(
author=self.name,
content=types.Content(
role="assistant",
parts=[types.Part(text=f"Tool Validation Result:\n```json\n{json.dumps(output, indent=2)}\n```")]
),
partial=True)
ctx.session.state["sql_to_validate"] = sql_query
if output["valid"] and output["valid"] is True:
ctx.session.state["error"] = ""
ctx.session.state["model_agent_result"] = ""
yield Event(
author=self.name,
content=types.Content(
role="assistant",
parts=[types.Part(text="SQL syntax is valid according to tool. Proceeding with model validation...")]
),
partial=True
)
async for event in self.model_validator_agent.run_async(ctx):
yield event
else:
ctx.session.state["error"] = output["message"]
ctx.session.state["model_agent_result"] = ""
yield Event(
author=self.name,
content=types.Content(
role="assistant",
parts=[types.Part(text="SQL syntax is invalid according to tool. Proceeding with error interpretion")]
),
partial=True
)
print("State after error:", ctx.session.state)
async for event in self.error_intepreter_agent.run_async(ctx):
yield event
# After tool_validator_agent finishes, clear its specific state if needed
if "error" in ctx.session.state:
del ctx.session.state["error"]
if "sql_to_validate" in ctx.session.state:
del ctx.session.state["sql_to_validate"] # Clear once it's been handled
if "model_agent_result" in ctx.session.state:
del ctx.session.state["model_agent_result"]The tool itself is tiny:
def validate_sql_syntax(sql: str) -> dict:
"""
Validate the syntax of a SQL query using SQLGlot.
Parameters:
sql (str): The SQL query string to validate.
Returns:
dict: A dictionary with the following structure:
{
"valid": bool, # True if syntax is valid, False if error found
"message": str # Validation result or error message
}
"""
try:
print("Input to tool -->" + sql)
dialect: str = "spark"
expr = sqlglot.parse_one(sql, read=dialect)
return {
"valid": True,
"message": "SQL syntax is valid."
}
except ParseError as e:
return {
"valid": False,
"message": f"Syntax error: {str(e)}"
}
Why the Prompt Matters (Spoiler: It’s Everything)
The model validator lives or dies by its prompt. Two rules boosted accuracy dramatically:
-
Be brutally explicit. The prompt starts with a non‑negotiable JSON schema and a zero‑temperature setting. No suggestions, no guessing — the LLM must reply exactly:
JSON{"isValidSQL": true/false, "summary": "<one‑sentence explanation>"} -
Show, don’t tell. After the instructions, I appended examples — one valid and one invalid query for every Spark SQL function. I scraped the official docs and auto‑generated pairs like:
JSON{ "isValidSQL": false, "summary": "COUNT is a function and requires arguments, e.g., COUNT(*), COUNT(column_name)." }The LLM now sees exactly how each function should (and shouldn’t) look, which slashes false positives.
With those two tweaks, plus a locked‑down GenerationConfig, the model went from “meh” to surprisingly reliable, catching ambiguous columns, misused window functions, and even subtle type mismatches.
validation_generation_config = GenerationConfig(
temperature=0.0, # deterministic
top_p=0.9, # curb randomness
top_k=1, # further tighten
response_mime_type="application/json" # enforce schema
)
Setting the same config on both LLM agents pins their output to the exact JSON format.
The error‑interpreter agent uses the same playbook: a strict one‑sentence schema, followed by a small set of raw‑error -> human‑message pairs. That mirror structure keeps both agents predictable without duplicating prompt engineering effort.
Does It Work?
| Query | Tool Validator | Validator (human‑friendly) |
|---|---|---|
SELECT FROM table |
{ "valid": true, "message": "SQL syntax is valid." } |
|
SELECT * FROM orders JOIN customers |
|
|
SELECT name, SUM(sales) WHERE region = 'US' FROM revenue |
|
|
SELECT COUNT FROM orders |
|
|
Time to verdict: ≈ 400 ms on my laptop. Most of that latency is the LLM layer, first translating tool errors and catching semantic issues that SQLGlot can’t see.
Lessons Learned (a.k.a. Scars)
- Parsers are blunt instruments. Great at commas and parentheses, clueless about business rules.
- LLMs are moody. Set
temperature=0, log everything, and be ready for the odd surprise. - Watch for session bleed. Re‑using the same
InvocationContext(or any shared memory) Across users, data can leak and skew later validations—constantly reset or isolate session data between runs.
What’s Next
- Plug in the Hive Metastore so we can flag unknown tables before runtime.
- Emit Prometheus counters to quantify dollars saved.
- Fine-tune the validator LLM on Spark docs and our query corpus to enhance accuracy further.
Parting Thoughts
A forgotten comma at two in the morning pushed me down this rabbit hole. A few evenings later, the same typo now hits a 400 ms gatekeeper and never even spins up Spark — no drama, no bill shock, no lost sleep.
So far, ≈ 90 % of malformed queries are blocked upfront — already a massive leap from “zero validation.”
As we feed the agents more schema-aware context (tables, columns, data types) and eventually fine-tune the model on Spark SQL documentation and our query corpus, both the block-rate and the clarity of the explanations should continue to improve.
Because the logic sits before Spark, we can also bolt on platform-specific rules — such as size limits, cost guards, and RBAC filters — without touching the cluster at all.
Source Code
Get the complete source here. The code is short, but the gain is significant. Grab it, tweak it, and let me know what you build on top of it.
Opinions expressed by DZone contributors are their own.
Comments