The Foundations for Building an Apache Flink Application
Join the DZone community and get the full member experience.
Join For FreeIn this article, we'll work to give you a better understanding of stream processing using Flink from the bottom-up; cloud services and other platforms provide stream processing solutions (for some, Flink is integrated under the hood). If you miss the basics, this guide is for you.
Our monolith solution does not cope with the increased load of incoming data, and thus it has to evolve. This is the time for the next generation of our product. Stream processing is the new data ingestion paradigm, as compared to the batch processing we’ve implemented so far.
So, my team embarked on processing information using Flink. There is an abundance of articles about Flink’s features and benefits. Cloudera shared an excellent slide about Flink; this article is a practical hands-on guide on how to build a simple stream processing application starting from the basics.
Apache Flink in Short
Apache Flink is a scalable, distributed stream-processing framework, meaning it is able to process continuous streams of data. This framework provides a variety of functionalities: sources, stream transformations, parallel processing, scheduling, resource assignments, and a wide range of destinations. Some of its connectors are HDFS, Kafka, Amazon Kinesis, RabbitMQ, and Cassandra.
Flink is known for its high throughput and low latency, supporting exactly-one consistency (all data is processed once without duplications), and it also supports high availability. Like any other successful open-source product, it has a broad community that cultivates and extends its features.
Flink can process indefinite data streams or definite data sets. This blog will focus on the former (working with DataStream objects).
Streams Processing : The Challenges
Nowadays, when IoT devices and other sensors are ubiquitous, data is flowing endlessly from many sources. This endless flow of data forces the traditional batch computation to adapt.
- This data is unbounded; there is no start and end.
- Unpredictable and inconsistent intervals of new data.
- Data can be out of order, with various timestamps.
Due to these unique characteristics, processing and querying data are intricate tasks. Results change rapidly, and it is almost impossible to obtain definite conclusions; at times, the computation may be hindered when trying to produce valid results. Moreover, the results are not repeatable, since the data keeps on changing. Lastly, the latency is a factor, as it impacts the accuracy of the results.
Apache Flink copes with these problems by processing based on timestamps in the source of the incoming data. It has a mechanism to accumulate events based on their timestamp before applying the processing execution. It eliminates the use of micro-batches, and with that, it improves the accuracy of the results.
Flink implements exactly once consistency, which ensures the correctness of computations without the developer programming for it.
The Foundations : Flink Packages Building Blocks
Flink predominantly ingests streams from various sources. The basic object is DataStream<T> , which represents a stream of elements of the same type; its elements’ type is defined in compile time by setting the generic type T (read here about the DataStream object).
The DataStream object contains many useful methods to transform, split, and filter its data[1]. Familiarity with the methods map, reduce, and filter is a good start; these are the main transformation methods:
Map: receives T object and returns a result of an object of type R; the MapFunction is applied exactly once on each element of the DataStream object.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce: receives two consecutive values and returns one object after combining them into the same object type; this method runs on all values in the group until only a single value remains.
T reduce(T value1, T value2)
Filter: receives T object and returns a stream of T objects; this method runs on each element in the DataStream but returns only those in which the function returns true.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Data Sink
Besides transforming the data, Flink’s main purpose is to steer streams after processing them into different destinations. These destinations are called “sinks”. Flink has built-in sinks (text, CSV, socket), as well as out-of-the-box connectors to other systems (such as Apache Kafka)[2].
Flink Event Timestamps
The notion of time is paramount for processing data streams. There are three options to define a timestamp:
Processing time (the default option): refers to the system time of the machine that executes the stream processing operation, and thus it is the simplest notion of time; it does not require any coordination between streams and machines. Since it is based on the machine’s time, it provides the best performance and the lowest latency.
The drawback of using processing time is significant in distributed and asynchronous environments since it is not a deterministic method. The timestamp of the stream’s events can go out of sync if there’s a gap between machines’ clocks; network latency can also create a gap between the time an event left one machine and arrived at the other.
xxxxxxxxxx
// Setting the Processing Time attribute of StreamExecutionEnvironment object
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Event time: refers to the time that each individual event received on its producing source, before entering Flink. The event time is embedded in the event itself and can be extracted so Flink can process it properly.
Since the timestamp is not set by Flink, there should be a mechanism to signal the event should be processed or not; this mechanism is called Watermark.
This topic is beyond the scope of this blog-post (since I wanted to keep it concise); you can find more information in Flink documentation.
xxxxxxxxxx
// Defining the Event Time as the timestamp method
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<String> dataStream
= streamEnv.readFile(auditFormat,
dataDir, // the progon of the events
FileProcessingMode.PROCESS_CONTINUOUSLY,
1000).
assignTimestampsAndWatermarks(
new TimestampExtractor());
// ... more code ...
// Defining a class to extract the timestamp from the stream events
public class TimestampExtractor implements
AssignerWithPeriodicWatermarks<String>{
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis()-maxTimeFrame);
}
public long extractTimestamp(String str, long l) {
return InputData.getDataObject(str).timestamp;
}
}
Ingestion time: refers to the time that the event enters Flink; it is assigned once at the source, and thus is considered as more stable than processing time, which is assigned upon commencing the process.
Ingestion time cannot handle out-of-order events or late data, since the timestamp is set once the ingestion starts, as opposed to event time that has the feature to identify delayed events and handle them based on the watermarking mechanism.
xxxxxxxxxx
// Setting the Ingestion Time attribute of StreamExecutionEnvironment object
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
You can read more about timestamp and how it affects the stream processing in the following link.
Windowing
By definition, a stream is endless; therefore, the mechanism for processing is by defining frames (a time-based window, for example). With that, the stream is divided into buckets for aggregation and analysis. The window definition is an operation on a DataStream object or one of its inheritors.
There are several time-based windows:
Tumbling Window (the Default Configuration)
The stream is divided into equivalent-sized windows, without any overlapping. As long as the stream flows, Flink calculates the data based on this fixed time-frame continuously.
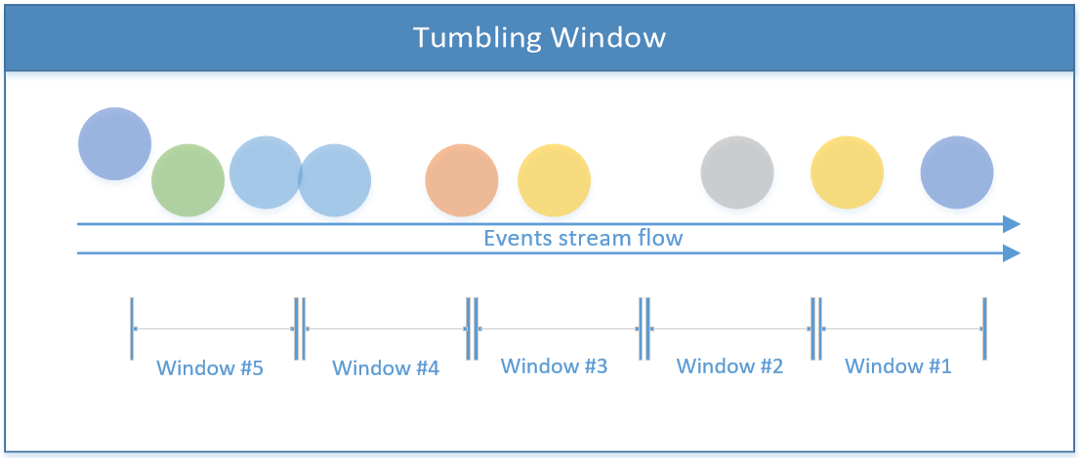
Code implementation:
xxxxxxxxxx
// To be used for a non-keyed stream
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// Tumbling window for a key-based stream
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Sliding Window
An overlapping window that is composed of window size and an offset (when to start the next window). With that, events can be processed in more than one window in a given time.
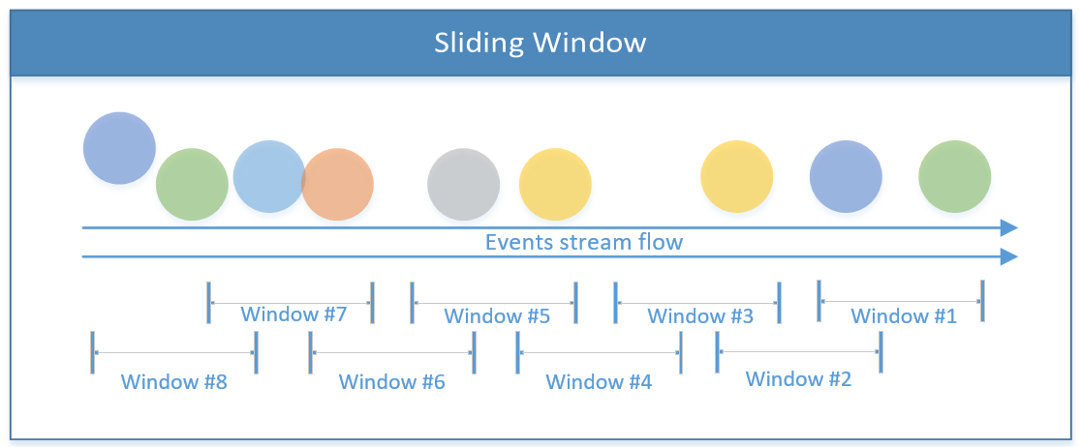
and this is how it looks in the code:
xxxxxxxxxx
// sliding time window of 1 minute length and 30 secs trigger interval
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30));
Session Window
Includes all events under the session’s boundary. A session ends when there is no activity or no events after a defined time-frame. This time-frame can be fixed or dynamic, based on the processed events. Theoretically, if the session’s gap between events is smaller than the size of the window, the session can never end.
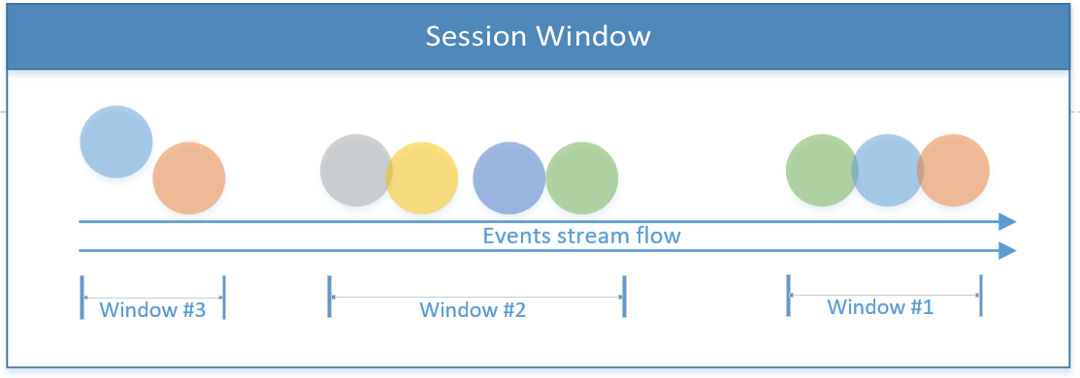
The first code snippet below exemplifies a fixed time-based session (2 seconds). The second session window implements a dynamic window, base on the stream’s events.
xxxxxxxxxx
// Defining a fixed session window of 2 seconds
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)));
// Defining a dynamic window session, which can be set by the stream elements
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// return the session gap, which can be based on the stream's events
}));
Global Window
Treats the entire stream as one single window.
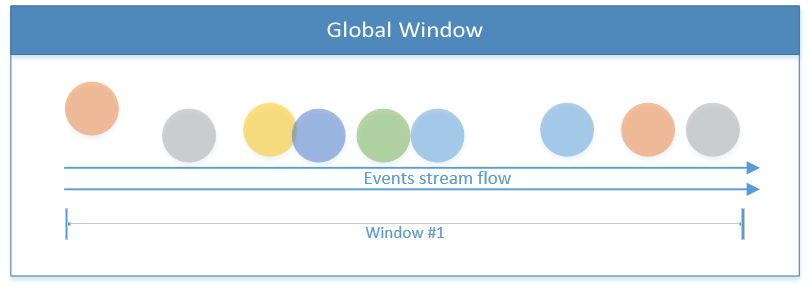
Flink also enables the implementation of custom windows with user-defined logic, which will be a topic for another blog-post.
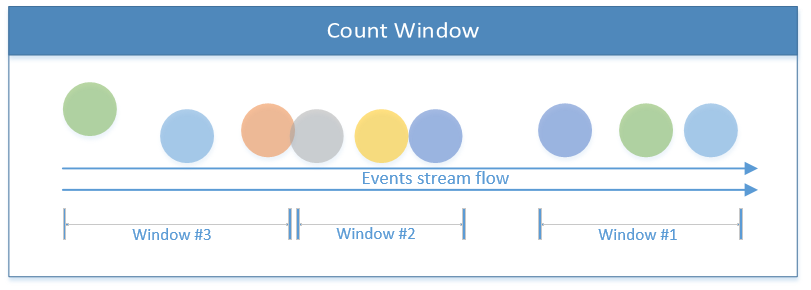
Other than time-based windows, there are other windows such as Count Window, which verges the limits by the number of the incoming events; once an X threshold has reached, Flink processes X events. The illustration below describes a count window of three elements:
After the theoretical introduction, let’s dive into a practical data flow. You can find more information about Apache Flink and stream processes on the official website.
Steaming Flow Description
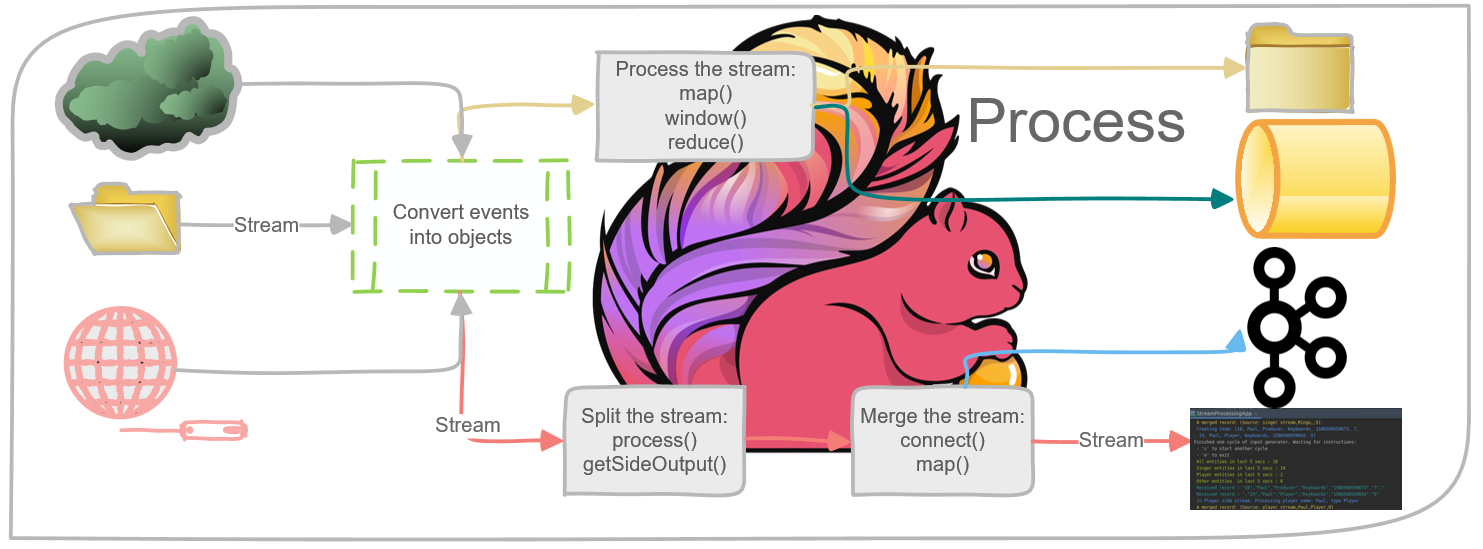
To recap the theoretical part, the below diagram portrays the main data flow of the codes samples in this blog-post. The flow below starts from a source (files are written into a folder) and continues with processing the events into objects.
The depicted implementation below is composed of two processing tracks. The one on the tops splits a stream into two side streams and then merges them to form a third type of stream. The scenario in the bottom processes a stream and then transfers the results into a sink.
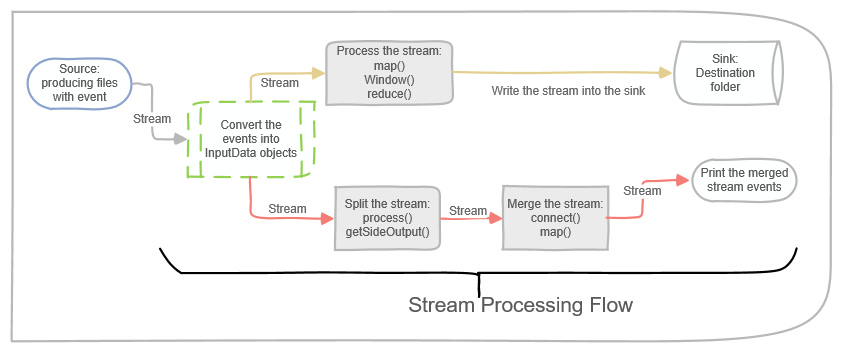
The next part aims to convert the theoretical stream processing into tangible practice; you can find the full source code on GitHub.
Basic Stream Handling (Example #1)
Starting with a basic application is much easier to grasp the concepts of Flink. In this application, the producer writes files into a folder, which simulates a flowing stream. Flink reads files from this folder, processes them, and writes a summary into a destination folder; this is the sink.
Now, let’s focus on the process part:
1. Converting the raw data into an object:xxxxxxxxxx
// Convert each record to an InputData object; each new line is considered a new record
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
//pring the raw data before onverting to an object
System.out.println("--- Received event : " + inputStr);
return InputData.getDataObject(inputStr);
});
2. The code sample below converts the stream object (InputData) into a Tuple of string and integer. It extracts only certain fields from a stream of objects, grouping them by one field in quants of two seconds.
xxxxxxxxxx
// Convert each record to a Tuple with name and score
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // returns KeyedStream<T, Tuple> based on the first item ('name' fields)
//.timeWindowAll(Time.seconds(windowInterval)) // DO NOT use timeWindowAll for a key-based stream
.timeWindow(Time.seconds(2)) // return WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
xxxxxxxxxx
// Define a time window and count the number of records
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) // a tunbmling window
.reduce((x,y) -> // sum the numbers, until reaching a single result
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
// Setup a streaming file sink to the output directory
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// Add the sink file stream to the DataStream; with that, the inputCountSummary will be written into the countSink path
inputCountSummary.addSink(countSink);
Splitting Streams (Example #2)
In this example, we demonstrate how to split the main stream while using the side output streams. Flink enables producing multiple side streams from the main DataStream . The type of data resides in each side stream can vary from the main stream and from each side stream as well.
So, using a side output stream can kill two birds in one shot: splitting the stream and converting the stream type into multiple data types (can be unique for each side output stream).
The code sample below calls the ProcessFunction that splits a stream into two side stream based on a property of the input. To obtain the same result, we should have been using the function filter more than once.
The ProcessFunction collects certain objects (based on criteria) to the main output collector (captures in the SingleOutputStreamOperator), while adding other events to side outputs. The DataStream is vertically split and publish different formats.
Notice the side output stream definition is based on a unique output tag (OutputTag object).
xxxxxxxxxx
// Define a separate stream for Players
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
// Define a separate stream for Singers
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// Convert each record to an InputData object and split the main stream into two side streams.
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// Convert a String to an InputData Object
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//Create output tuple with name and count
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// Create output tuple with name and type;
// if the newly created tuple doesn't match the playerTag type then a compilation error is raised ("method output cannot be applied to given types")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// Collect main output as InputData objects
collInputData.collect(inputData);
break;
}
}
});
Merging Streams (Example #3)
The last operation in this blog-post demonstrates the operation of merging stream. The idea is to combine two different streams, which can differ in their data format, and produce one stream with a unified data structure. As opposed to an SQL merge operation, which merges data horizontally. The operation of the merging stream is vertical since the events continue to flow without any bounded time frame.
Merging streams is done by calling the method connect and then defining the map operation on each element in each individual stream. The result is a merged stream.
xxxxxxxxxx
// The returned stream definition includes both streams data type
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, //Stream 1
Tuple2<String, String>, //Stream 2
Tuple4<String, String, String, Integer> //Output
>() {
public Tuple4<String, String, String, Integer> //Process Stream 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
public Tuple4<String, String, String, Integer> //Process Stream 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Building a Workable Project
Bringing it all together: I uploaded a demo project to GitHub. You can follow the instructions on how to build and compile it. This is a good start to play with Flink.
I hope you find this repo useful. Do not hesitate to contact me if you have any issues.
The Takeaways
This article focused on the essential foundations to build a working stream processing application based on Flink. Its purpose is to provide a basic understanding of stream processing challenges and set the foundations for building a stand-alone Flink application.
Since stream processing has many aspects and complexities, many topics were not covered. For example, Flink execution and task management, using watermarks to set Event time into the stream events, planting states in the stream’s events, running stream iterations, executing SQL-like queries on streams, and much more. I hope to cover some of these topics in subsequent articles.
Nevertheless, I hope this blog equipped you with essential information to start using Flink.
Keep on coding!
— Lior
Resources
[1] DataStream operations: https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/index.html
[2] Data sinks: https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html#data-sinks
Opinions expressed by DZone contributors are their own.
Comments