Building High-Performance Big Data and Analytics Systems
This article covers some of the critical performance considerations when working with Big Data and Analytics Systems.
Join the DZone community and get the full member experience.
Join For FreeBig Data and Analytics systems are fast emerging as one of the most critical system in an organization’s IT environment. But with such a huge amount of data, there come many performance challenges. If Big Data systems cannot be used to make or forecast critical business decisions, or provide insights into business values hidden under huge amounts of data at the right time, then these systems lose their relevance. This article talks about some of the critical performance considerations in a technology-agnostic way. These should be read as generic guidelines, which can be used by any Big Data professional to ensure that the final system meets all performance requirements.
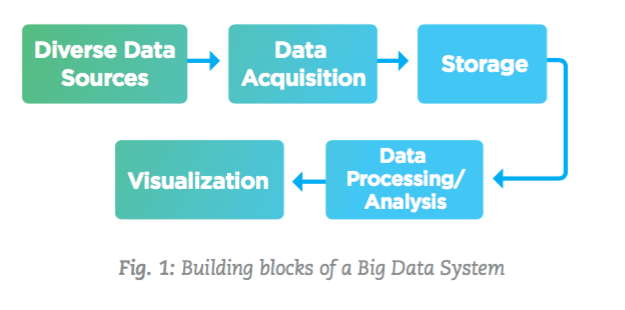
Building Blocks of a Big Data System
A Big Data system is comprised of a number of functional blocks that provide the system the capability for acquiring data from diverse sources, pre-processing (e.g. cleansing and validating) this data, storing the data, processing and analyzing this stored data, and finally presenting and visualizing the summarized and aggregated results.
The rest of this article describes various performance considerations for each of the components shown in Figure 1.
Performance Considerations for Data Acquisition
Data acquisition is the step where data from diverse sources enters the Big Data system. The performance of this component directly impacts how much data a Big Data system can receive at any given point of time.
Some of the logical steps involved in the data acquisition process are shown in the figure below:
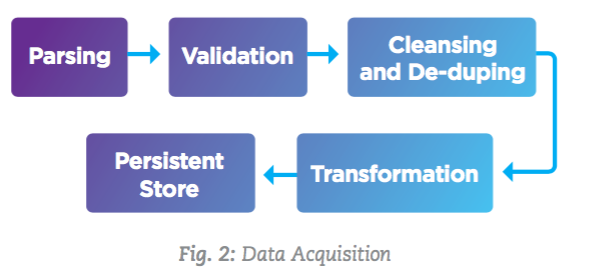
The following list includes some of the performance considerations, which should be followed to ensure a well performing data acquisition component.
- Data transfer from diverse sources should be asynchronous. Some of the ways to achieve this are to either use le-feed transfers at regular time intervals or by using Message-Oriented-Middleware (MoM). This will allow data from multiple sources to be pumped in at a much faster rate than what a Big Data system can process at a given time.
- If data is being parsed from a feed file, make sure to use appropriate parsers. For example, if reading from an XML le, there are different parsers like JDOM, SAX, DOM, and so on. Similarly for CSV, JSON, and other such formats, multiple parsers and APIs are available.
- Always prefer to see built-in or out-of-the-box validation solutions. Most parsing/validation work flows generally run in a server environment (ESB/ AppServer). These have standard validators available for almost all scenarios. Under most circumstances, these will generally perform much faster than any custom validator you may develop.
- Identify and filter out invalid data as early as possible, so that all the processing after validation will work only on legitimate sets of data.
- Transformation is generally the most complex and the most time- and resource-consuming step of data acquisition, so make sure to achieve as much parallelization in this step as possible.
Performance Considerations for Storage
In this section, some of the important performance guidelines for storing data will be discussed. Both storage options—logical data storage (and model) and physical storage—will be discussed.
- Always consider the level of normalization/de- normalization you choose. The way you model your data has a direct impact on performance, as well as data redundancy, disk storage capacity, and so on.
- Different databases have different capabilities: some are good for faster reads, some are good for faster inserts, updates, and so on.
- Database configurations and properties like level of replication, level of consistency, etc., have a direct impact on the performance of the database.
- Sharding and partitioning is another very important functionality of these databases. The way sharding is configured can have a drastic impact on the performance of the system.
- NoSQL databases come with built-in compressors, codecs, and transformers. If these can be utilized to meet some of the requirements, use them. These can perform various tasks like formatting conversions, zipping data, etc. This will not only make later processing faster, but also reduce network transfer.
- Data models of a Big Data system are generally modeled on the use cases these systems are serving. This is in stark contrast to RDMBS data modeling techniques, where the database model is designed to be a generic model, and foreign keys and table relationships are used to depict real world interactions among entities.
Performance Considerations for Data Processing
This section talks about performance tips for data processing. Note that depending upon the requirements, the Big Data system’s architecture may have some components for both real-time stream processing and batch processing. This section covers all aspects of data processing, without necessarily categorizing them to any particular processing model.
- Choose an appropriate data processing framework after a detailed evaluation of the framework and the requirements of the system (batch/real-time, in- memory or disk-based, etc.).
Some of these frameworks divide data into smaller chunks. These smaller chunks of data are then processed independently by individual jobs.
- Always keep an eye on the size of data transfers for job processing. Data locality will give the best performance because data is always available locally for a job, but achieving a higher level of data locality means that data needs to be replicated at multiple locations.
- Many times, re-processing needs to happen on the same set of data. This could be because of an error/ exception in initial processing, or a change in some business process where the business wants to see the impact on old data as well. Design your system to handle these scenarios.
- The final output of processing jobs should be stored in a format/model, which is based on the end results expected from the Big Data system. For example, if the expected end result is that a business user should see the aggregated output in weekly time-series intervals, make sure results are stored in a weekly aggregated form.
- Always monitor and measure the performance using tools provided by different frameworks. This will give you an idea of how long it is taking to finish a given job.
Performance Considerations for Visualization
This section will present generic guidelines that should be followed while designing a visualization layer.
- Make sure that the visualization layer displays the data from the final summarized output tables. These summarized tables could be aggregations based on time-period recommendations, based on category, or any other use-case-based summarized tables.
- Maximize the use of caching in the visualization tool. Caching can have a very positive impact on the overall performance of the visualization layer.
- Materialized views can be another important technique to improve performance.
- Most visualization tools allow configurations to increase the number of works (threads) to handle the reporting requests. If capacity is available, and the system is receiving a high number of requests, this could be one option for better performance.
- Keep the pre-computed values in the summarized tables. If some calculations need to be done at runtime, make sure those are as minimal as possible, and work on the highest level of data possible.
- Most visualization frameworks and tools use Scalable Vector Graphics (SVG). Complex layouts using SVG can have serious performance impacts.
Big Data Security and its Impact on Performance
Like any IT system, security requirements can also have a serious impact on the performance of a Big Data system. In this section, some high-level considerations for designing security of a Big Data system without having an adverse impact on the performance will be discussed.
- Ensure that the data coming from diverse sources is properly authenticated and authorized at the entry point of the Big Data system.
- Once data is properly authenticated, try to avoid any more authentication of the same data at later points of execution. To save yourself from duplicate processing, tag this authenticated data with some kind of identifier or token to mark it as authenticated, and use this info later.
- More often than not, data needs to be compressed before sending it to a Big Data system. This makes data transfer faster, but due to the need of an additional step to un-compress data, it can slow down the processing.
- Different algorithms/formats are available for this compression, and each can provide a different level of compression. These different algorithms have different CPU requirements, so choose the algorithm carefully.
- Evaluate encryption logic/algorithms before selecting one.
- It is advisable to keep encryption limited to the required fields/information that are sensitive or confidential. If possible, avoid encrypting whole sets of data.
Conclusion
This article presented various performance considerations, which can act as guidelines to build high-performance Big Data and analytics systems. Big Data and analytics systems can be very complex for multiple reasons. To meet the performance requirements of such a system, it is necessary that the system is designed and built from the ground up to meet these performance requirements.
Opinions expressed by DZone contributors are their own.
Comments