Building Scalable Disaster Recovery Platforms for Microservices
Declarative YAML-driven disaster recovery using a state machine orchestrator and agents enables scalable and observable disaster recovery workflows.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Disaster recovery is the process of restoring a business's IT infrastructure — including critical data, applications, and systems — after a catastrophic event to minimize downtime and resume normal operations. There is a common misconception that disaster recovery is just about database snapshot. In reality, it includes restoring application state, database, cache, traffic management, and infrastructure orchestration.
Today’s cloud-native environment, which consists of thousands of microservices, makes disaster recovery complex because it requires coordination across services, infrastructure, and dependencies. In large organizations, there are thousands of services to manage with varied technologies. Using a non-standard disaster recovery static script leads to inconsistent and error-prone disaster recovery execution.
This article explores the approach of building a scalable disaster recovery platform where disaster recovery intent is expressed as a YAML file that is processed by the orchestration layer, and disaster recovery agents execute consistent and repeatable disaster recovery.
Building scalable disaster recovery platforms
a. Disaster recovery intent: Why YAML?
Instead of hardcoding disaster recovery scripts, you can define disaster recovery workflows declaratively. Each workflow consists of multiple stages, each associated with a specific disaster recovery agent responsible for managing a particular resource, such as compute, database, and route53. This approach enables granular control over execution, with each stage tailored to the service's specific needs.
Let’s take an example of an Active/Passive microservice application running on Kubernetes that uses a PostgreSQL database. A typical disaster recovery flow would look something like:
-
Prescale compute in passive region (A)
-
Promote read replica in passive region (A) to become writer
-
Demote writer in active region (B) to read-only
-
Update DNS endpoint to route traffic to passive region (A)
Here’s an example of disaster recovery intent expressed as YAML:
stages:
prescale:
agent: "capacity"
spec:
cluster: "my-k8s-cluster-region-a"
namespace: "petstore-region-a"
region: "region-a"
promote-database:
agent: "database"
spec:
cluster: "petstore-region-a"
role: "writer"
demote-database:
agent: "database"
spec:
cluster: "petstore-region-b"
role: "reader"
dial:
agent: "dial"
spec:
endpoint: "petstore-region-a.com"
region: "region-a"
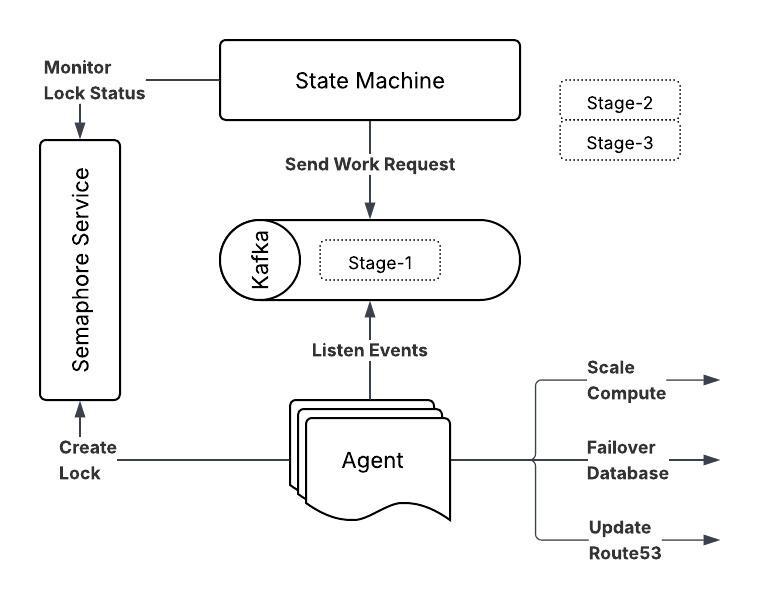
b. Orchestrator: Brain of disaster recovery
A state machine-based orchestrator is responsible for processing the YAML workflow and coordinating disaster recovery stages by executing long-running tasks in a serverless architecture. Orchestrator responsibility includes:
1. Parsing disaster recovery workflow YAML
It simply parses disaster recovery workflow YAML stages and converts them into an array of tasks that can be fed into the state machine.
2. Sending work requests to disaster recovery agents
State machine processes individual tasks and sends work requests to the disaster recovery agent by sending events to the Kafka message bus. Disaster recovery agents are listening to specific events in the Kafka message bus. When an event is detected by an agent, it performs the necessary tasks. By using event-driven architecture, it introduces loose coupling between system components and makes it easier to introduce a new disaster recovery agent capable of performing different tasks.
3. Scheduling disaster recovery stages in expected order
It is critical to execute the disaster recovery stages in the expected order. The disaster recovery agent creates a lock in an external semaphore service. State machine monitors for semaphore lock status (success or failure) set by the agent on completion of the task. Once the semaphore lock is released successfully, the state machine sends another work request to the Kafka message bus. This approach ensures workflows are executed in the correct sequence by managing access to critical resources and preventing race conditions. This semaphore service is particularly important in environments with multiple interdependent resources, where the order of operations can significantly impact the success of the disaster recovery process.
4. Handling any retries, failures, and notifications
The orchestrator must handle any transient failures, such as network timeouts and API throttling by enabling exponential back-off based retries. It reduces the need for re-triggering disaster recovery from scratch. In order to improve operational visibility, the orchestrator must notify users about task completions, or failures, in real time.
c. Agent: Disaster recovery executor
Disaster recovery agents execute the tasks defined in their respective stages. These tasks may include adjusting compute capacity resources, managing DNS failover, performing database role-switch operations, or other critical operations required during a disaster recovery event. These agents are highly configurable, allowing them to be tailored to the specific needs of each service. This configurability ensures that the workflow can be adapted to a wide range of disaster recovery scenarios.
Additional considerations
Here are some additional considerations to keep in mind while building a scalable disaster recovery platform.
-
Parallel execution of stages: A lot of times, independent disaster recovery stages can be executed simultaneously — like promoting database in passive region to primary and scaling compute in passive region. Executing these stages simultaneously reduces the total recovery time (RTO), which is very important for restoring normal operations quickly after an outage.
-
Dial group of microservices: Many service owners would like to perform a disaster recovery operation on a group of microservices that enable the customer experience.
-
Automated disaster recovery based on alert: The disaster recovery platform must be capable of triggering disaster recovery based on alerts to avoid any manual intervention.
-
Pre-baked and customizable stages: The disaster recovery platform must include a range of pre-baked stages for standard tasks, such as database role-switching, DNS failover, and resource pre-provisioning. These stages are designed to cover the most common disaster recovery scenarios. Users also have the option to customize these stages or create entirely new ones, providing the flexibility needed to meet specific service requirements.
Conclusion
A scalable disaster recovery platform does not just replicate data; it automates disaster recovery using an intent-driven workflow. By combining a YAML-driven disaster recovery plan, a state machine orchestrator, and disaster recovery agents responsible for executing disaster recovery, large organizations can build a highly scalable and observable disaster recovery platform.
Opinions expressed by DZone contributors are their own.
Comments