Building Serverless on AWS Lambda
Here we see the benefits of serverless computing when deploying APIs to the cloud, focusing on AWS' offering, Lambda, working with other services.
Join the DZone community and get the full member experience.
Join For FreeServerless is now one of the hottest trends in the IT world. A more accurate name for it is Functions-as-a-Service (FaaS). Have any of you ever tried to share your APIs deployed in the cloud? Before serverless, I had to create a virtual machine with Linux on the cloud provider’s infrastructure, then deploy and run that application implemented in, for example, Node.js or Java. With serverless, you do not have to write any commands in Linux.
Serverless is different from another very popular topic – microservices. To illustrate the difference, serverless is often referred to as nanoservices. For example, if we would like to create a microservice that provides an API for CRUD operations on a database table, then our APIs had several endpoints for searching (GET/{id}), updating (PUT), removing (DELETE), inserting (POST), and maybe a few more for searching using different input criteria. According to serverless architecture, all of those endpoints would be independent functions created and deployed separately. While microservices can be built on an on-premise architecture, for example with Spring Boot, serverless is closely related to the cloud infrastructure.
Custom function implementation based on a cloud provider’s tools is really quick and easy. I’ll try to show it on sample functions deployed on AWS using AWS Lambda. Sample application source code is available on GitHub.
How it Works
Here’s the AWS Lambda solution description from Amazon site.
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume – there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
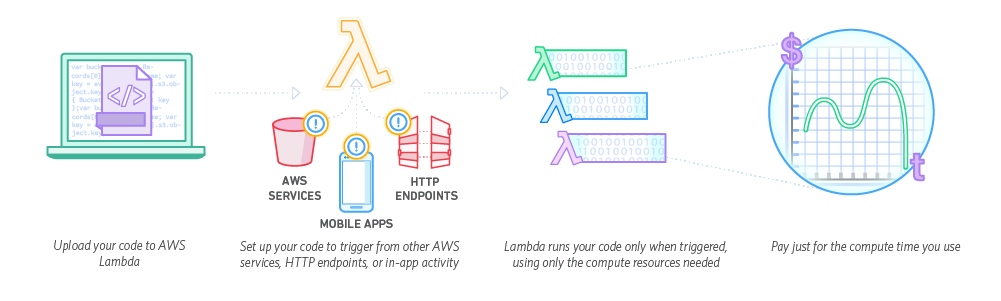
AWS Lambda is a compute platform for many application scenarios. It supports applications written in Node.js, Java, C#, and Python. On the platform, there are also some services available like DynamoDB – NoSQL database, Kinesis – streaming service, CloudWatch – provides monitoring and logs, Redshift – data warehouse solution, S3 – cloud storage, and API Gateway. Every event coming to those services can trigger the calling of your Lambda function. You can also interact with those services using the AWS Lambda SDK.
Preparation
Let’s move on from theory and into action. First of all, we need to set up an AWS account. AWS has a web management console available here, but there is also a command line client called AWS CLI, which can be downloaded here. There are also some other tools through which we can share our functions on AWS. I will tell you about them later. To be able to use them, including the command line client, we need to generate an access key. Go to the web console and select My Security Credentials on your profile, then select Continue to Security Credentials and expand Access Keys. Create your new access key and save it on a disc. There are to fields, Access Key ID and Secret Access Key. If you would like to use AWS CLI, first type aws configure and then you should provide those keys, default region, and format (for example, JSON or text).
You can use AWS CLI or even the web console to deploy your Lambda function on the cloud. However, I will present you other (in my opinion, better) solutions. If you are using Eclipse for your development, the best option is to download the AWS Toolkit plugin. Now, I’m able to upload my function to AWS Lambda or even create or modify a table on Amazon DynamoDB. After downloading the Eclipse plugin, you need to provide your Access Key ID and Secret Access Key. You have the AWS Management perspective available, where you can see through the AWS ecosystem, including lambda functions, DynamoDB tables, identity management, or other services like S3, SNS or SQS. You can create special an AWS Java project or work with a standard maven project. Just display the project menu by right-clicking on the project and then selecting Amazon Web Services and Upload function to AWS Lambda…
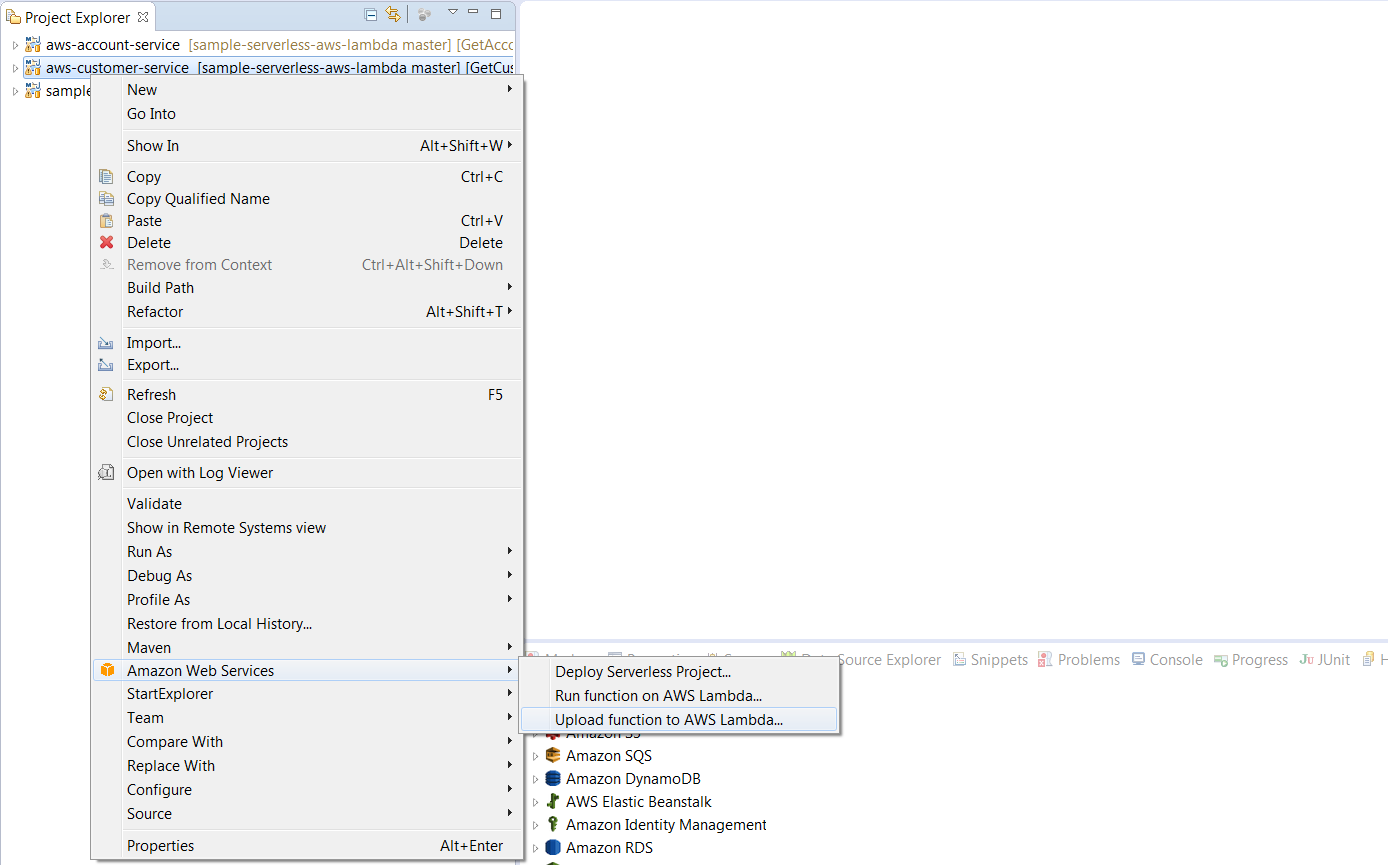
After selecting Upload function to AWS Lambda… you should see the window visible below. You can choose the region for your deployment (us-east-1 by default), IAM role, and the name of your Lambda function. We can create a new function or update the existing one.
Another interesting possibility for uploading a function into AWS Lambda is via maven plugin. With lambda-maven-plugin, we can define security credentials and all definitions of our functions in JSON format. Here’s the plugin declaration in thepom.xml. The plugin can be invoked during a maven project build: mvn clean install lambda:deploy-lambda. Dependencies should be attached to the output JAR file – that’s why maven-shade-plugin is used during build.
<plugin>
<groupId>com.github.seanroy</groupId>
<artifactId>lambda-maven-plugin</artifactId>
<version>2.2.1</version>
<configuration>
<accessKey>${aws.accessKey}</accessKey>
<secretKey>${aws.secretKey}</secretKey>
<functionCode>${project.build.directory}/${project.build.finalName}.jar</functionCode>
<version>${project.version}</version>
<lambdaRoleArn>arn:aws:iam::436521214155:role/lambda_basic_execution</lambdaRoleArn>
<s3Bucket>lambda-function-bucket-us-east-1-1498055423860</s3Bucket>
<publish>true</publish>
<forceUpdate>true</forceUpdate>
<lambdaFunctionsJSON>
[
{
"functionName": "PostAccountFunction",
"description": "POST account",
"handler": "pl.piomin.services.aws.account.add.PostAccount",
"timeout": 30,
"memorySize": 256,
"keepAlive": 10
},
{
"functionName": "GetAccountFunction",
"description": "GET account",
"handler": "pl.piomin.services.aws.account.find.GetAccount",
"timeout": 30,
"memorySize": 256,
"keepAlive": 30
},
{
"functionName": "GetAccountsByCustomerIdFunction",
"description": "GET accountsCustomerId",
"handler": "pl.piomin.services.aws.account.find.GetAccountsByCustomerId",
"timeout": 30,
"memorySize": 256,
"keepAlive": 30
}
]
</lambdaFunctionsJSON>
</configuration>
</plugin>Lambda Function Implementation
I implemented sample AWS Lambda functions in Java. Here’s a list of dependencies inside my pom.xml.
<dependencies>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-events</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-log4j</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-s3</artifactId>
<version>1.11.152</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-lambda</artifactId>
<version>1.11.152</version>
</dependency>
</dependencies>Every function connects to Amazon DynamoDB. There are two tables created for that sample: account and customer. One customer could have more than one account, and this assignment is realized through the customerId field in the account table. The AWS library for DynamoDB has ORM mapping mechanisms. Here’s the Account entity definition. By using annotations, we can declare the table name, hash key, index, and table attributes.
@DynamoDBTable(tableName = "account")
public class Account implements Serializable {
private static final long serialVersionUID = 8331074361667921244L;
private String id;
private String number;
private String customerId;
public Account() {
}
public Account(String id, String number, String customerId) {
this.id = id;
this.number = number;
this.customerId = customerId;
}
@DynamoDBHashKey(attributeName = "id")
@DynamoDBAutoGeneratedKey
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
@DynamoDBAttribute(attributeName = "number")
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
@DynamoDBIndexHashKey(attributeName = "customerId", globalSecondaryIndexName = "Customer-Index")
public String getCustomerId() {
return customerId;
}
public void setCustomerId(String customerId) {
this.customerId = customerId;
}
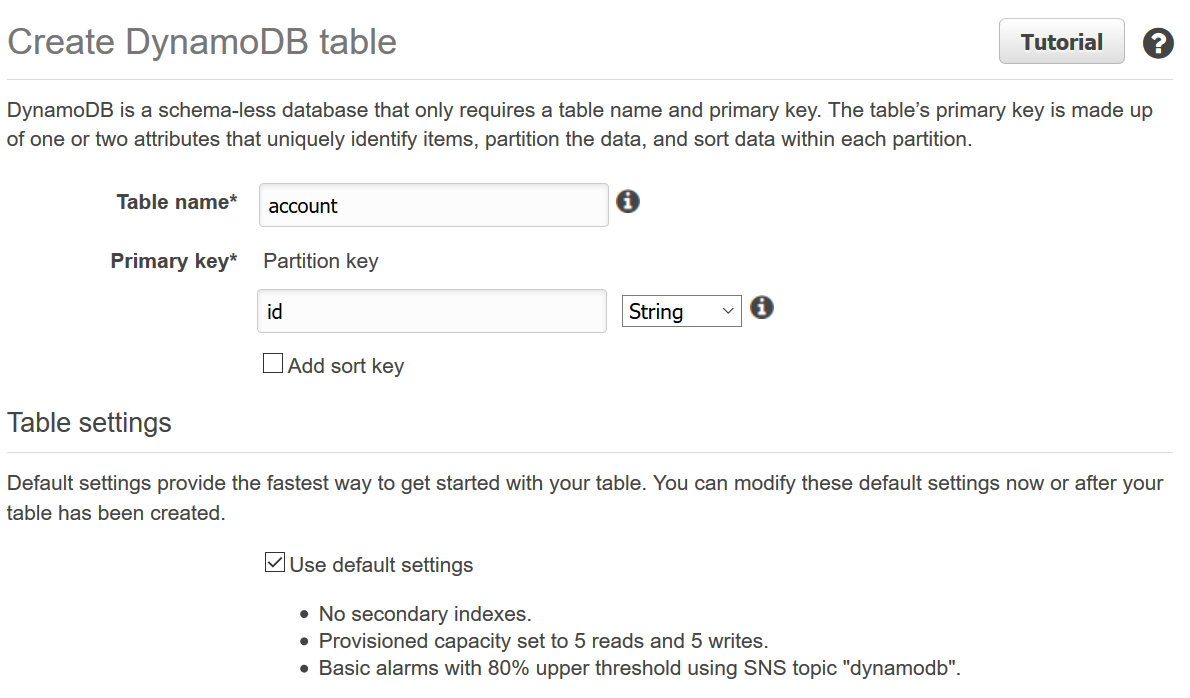
}To create table with AWS Console go to DynamoDB section and click Create table. You only have to provide table name and primary key name and type.
In the described sample application, there are five lambda functions:
PostAccountFunction: it receives an
Accountobject from a request and inserts it into the tableGetAccountFunction: find account by hash key id
GetAccountsByCustomerId: find a list of accounts by input
customerIdPostCustomerFunction: receives a
Customerobject from a request and inserts it into the tableGetCustomerFunction: find customer by hash key id
Every AWS Lambda function handler needs to implement the RequestHandler interface with one method: handleRequest. Here’s the PostAccount handler class. It connects to DynamoDB using the Amazon client and creates an ORM mapper, DynamoDBMapper, which saves the input entity in the database.
public class PostAccount implements RequestHandler<Account, Account> {
private DynamoDBMapper mapper;
public PostAccount() {
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
client.setRegion(Region.getRegion(Regions.US_EAST_1));
mapper = new DynamoDBMapper(client);
}
@Override
public Account handleRequest(Account a, Context ctx) {
LambdaLogger logger = ctx.getLogger();
mapper.save(a);
Account r = a;
logger.log("Account: " + r.getId());
return r;
}
}The GetCustomer function not only interacts with DynamoDB but also invokes the GetAccountsByCustomerId function. Maybe this is not the best example of the need to call another function — because it could directly retrieve data from the account table — but I wanted to separate the data layer from the function logic and jut show how invoking another function works in AWS Lambda.
public class GetCustomer implements RequestHandler<Customer, Customer> {
private DynamoDBMapper mapper;
private AccountService accountService;
public GetCustomer() {
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
client.setRegion(Region.getRegion(Regions.US_EAST_1));
mapper = new DynamoDBMapper(client);
accountService = LambdaInvokerFactory.builder() .lambdaClient(AWSLambdaClientBuilder.defaultClient())
.build(AccountService.class);
}
@Override
public Customer handleRequest(Customer customer, Context ctx) {
LambdaLogger logger = ctx.getLogger();
logger.log("Account: " + customer.getId());
customer = mapper.load(Customer.class, customer.getId());
List<Account> aa = accountService.getAccountsByCustomerId(new Account(customer.getId()));
customer.setAccounts(aa);
return customer;
}
}AccountService is an interface. It the uses @LambdaFunction annotation to declare the name of the invoked function in the cloud.
public interface AccountService {
@LambdaFunction(functionName = "GetAccountsByCustomerIdFunction")
List<Account> getAccountsByCustomerId(Account account);
}API Configuration
I assume that you have already uploaded your Lambda functions. Now, you can go to the AWS Web Console and see the full list of them in the AWS Lambda section. Every function can be tested by selecting the item in the functions list and calling the Test function action.
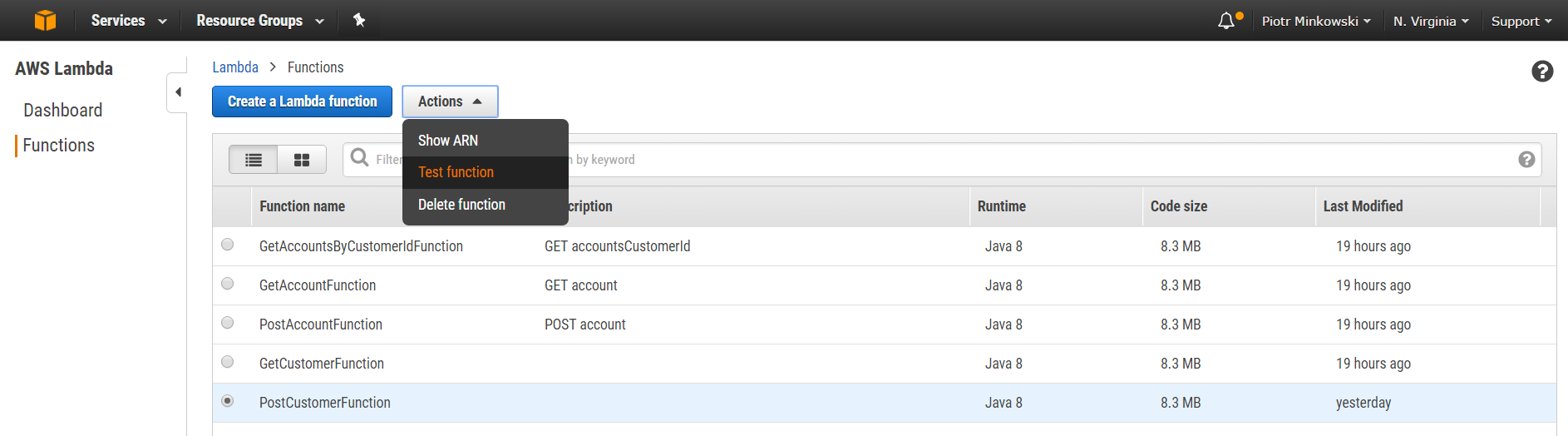
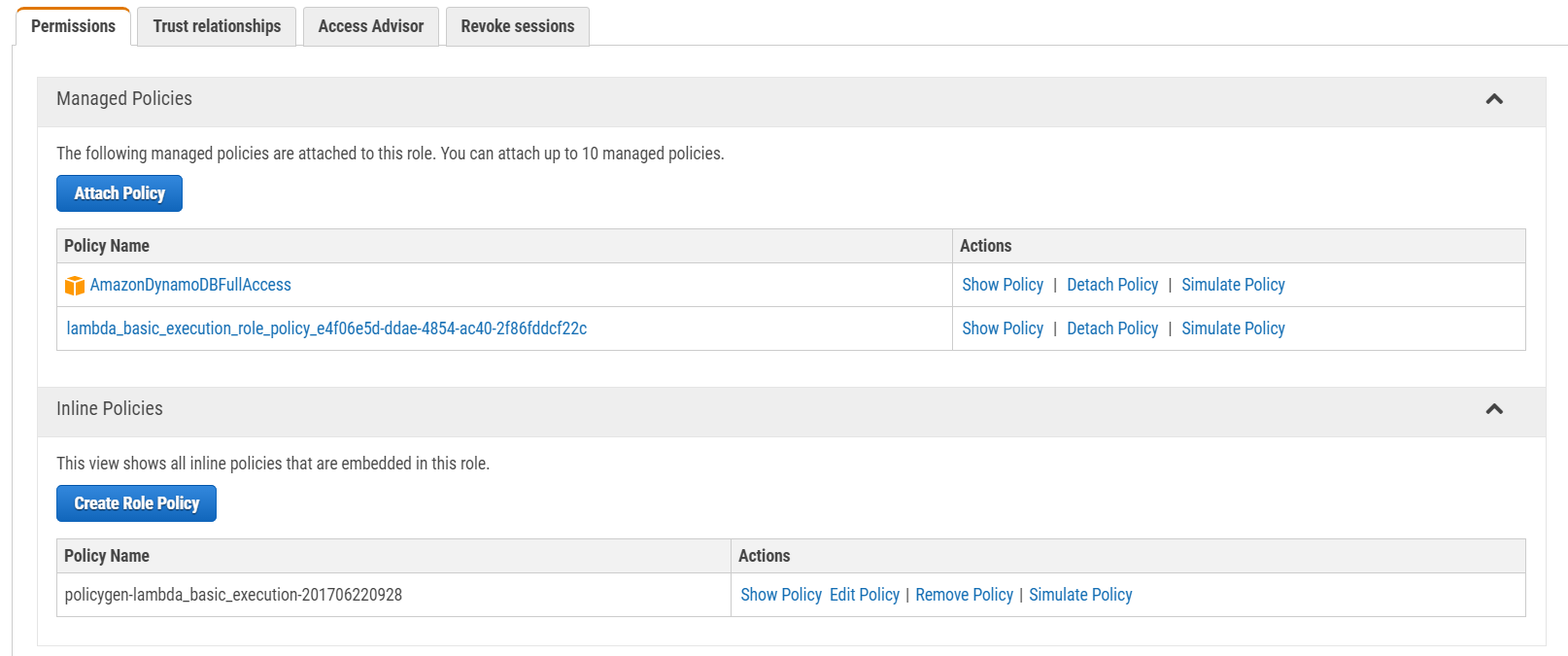
If you didn't configure role permissions, you probably got an error while trying to call your Lambda function. I attached my AmazonDynamoDBFullAccess policy to the main lambda_basic_execution role for my DynamoDB connection. Then, I created a new inline policy to enable invoking GetAccountsByCustomerIdFunction from other Lambda functions, as you can see in the figure below. If you retry your tests now, everything works fine.
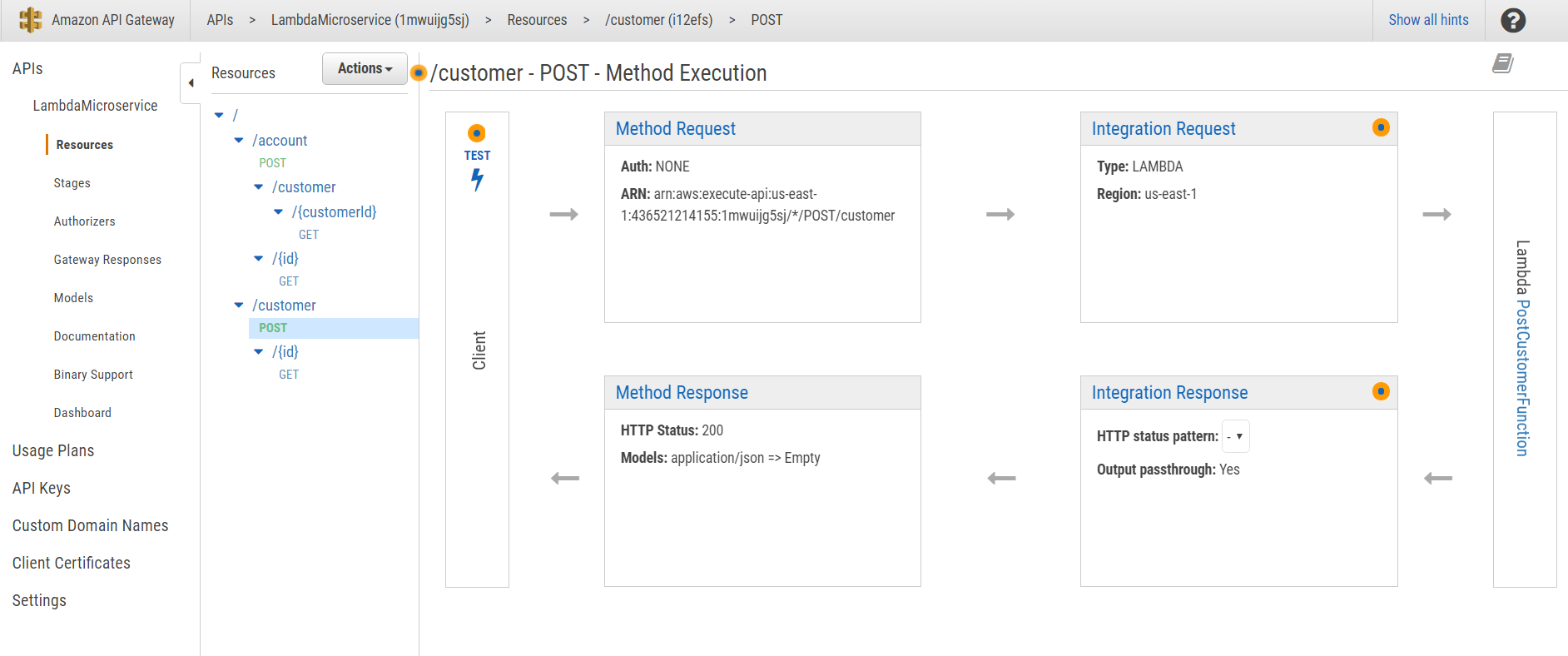
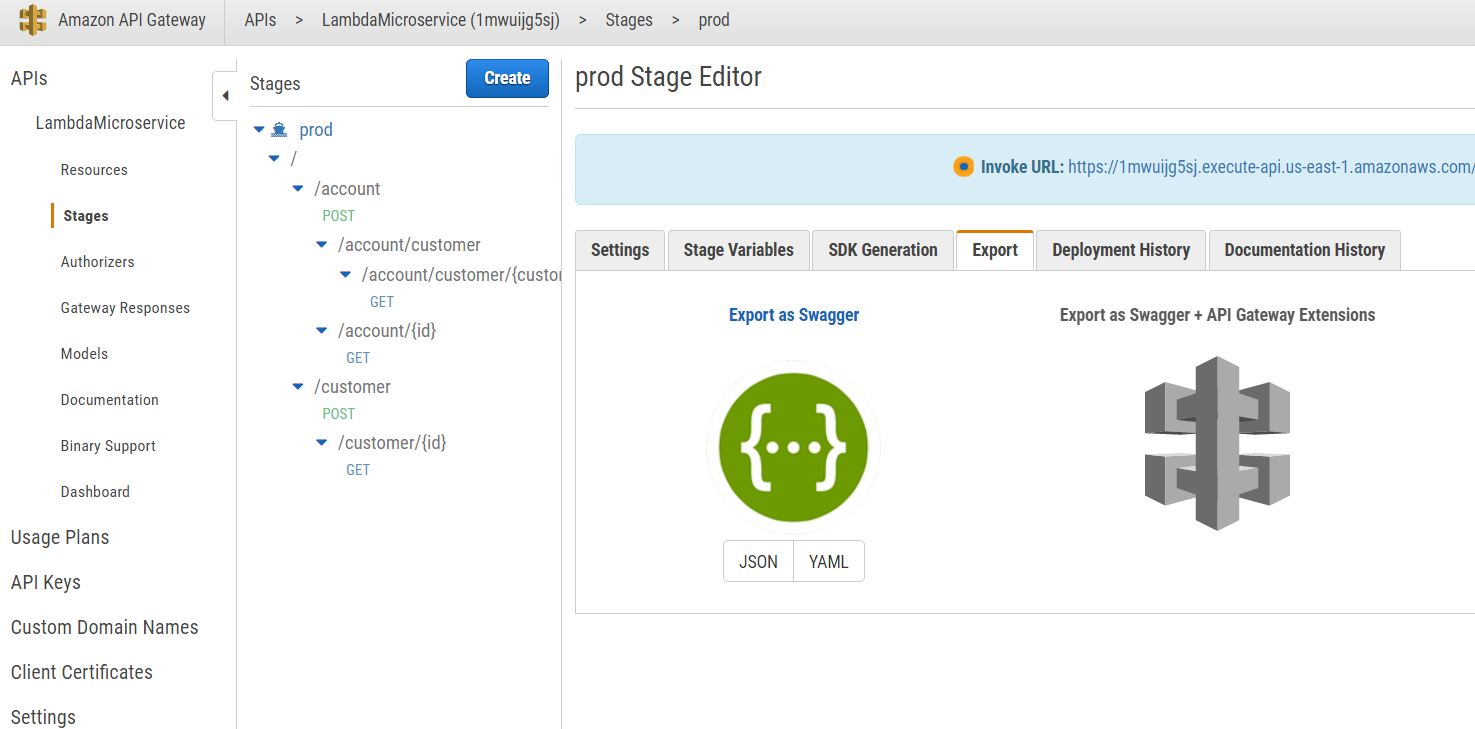
Well, now we are able to test our functions from the AWS Lambda Web Test Console. But our main goal is to invoke them from an outside client, for example a REST client. Fortunately, there is a component called API Gateway that can be configured to proxy our HTTP requests from a gateway to the Lambda functions. Here’s a figure with our API configuration. For example, POST /customer is mapped to PostCustomerFunction, GET /customer/{id} is mapped to GetCustomerFunction, etc.
You can configure Models definitions and set them as input or output types for the API.
{
"title": "Account",
"type": "object",
"properties": {
"id": {
"type": "string"
},
"number": {
"type": "string"
},
"customerId": {
"type": "string"
}
}
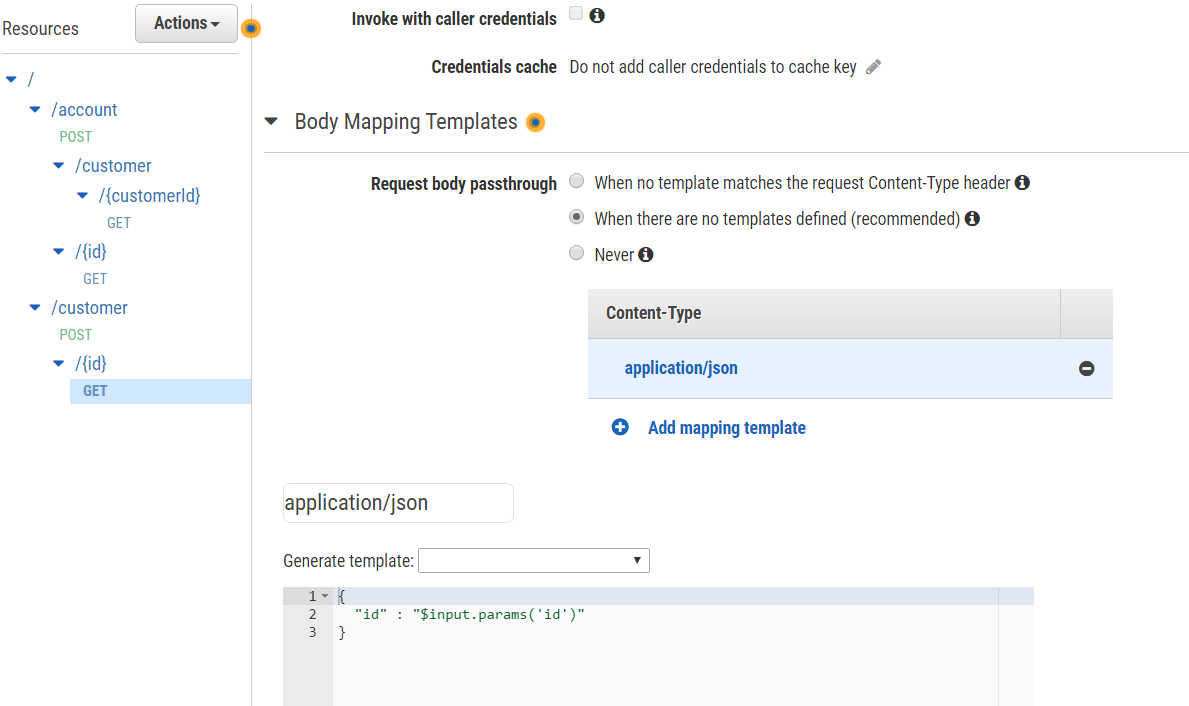
}For GET requests, configuration is a little more complicated. We have to set mapping from the path parameter into a JSON object, which is an input in Lambda functions. Select the Integration Request element and then go to the Body Mapping Templates section.
Our API can also be exported as a Swagger JSON definition. If you are not familiar with that, take a look at my previous article Microservices API Documentation with Swagger2.
Final Words
In my article, I described the steps illustrating how to create an API based on the AWS Lambda serverless solution. I showed the obvious advantages of this solution, such as no need for self-management of servers, the ability to easily deploy applications in the cloud, configuration, and monitoring fully based on the solutions provided by the AWS Web Console. You can easily extend my sample with some other services, for example with Kinesis to enable data stream processing. In my opinion, serverless is the perfect solution for exposing simple APIs in the cloud. If you were interested in the topic, you can read more about interaction with such AWS services like DynamoDB or SNS in another article about serverless Serverless on AWS with DynamoDB, SNS, and CloudWatch
Published at DZone with permission of Piotr Mińkowski. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments