How Did I Process Half a Million Transactions in AWS Lambda Within Minutes?
In this article, I’ll walk you through the architecture of processing big records files within AWS services.
Join the DZone community and get the full member experience.
Join For FreeProcessing data could be an intensive task, especially on the computing units as the read and write operations takes a lot of resources. Luckily, if you have the right tools, you can achieve it easily. But, is it worth it? Let’s find out.
In this article, I will share my experience with you on how did I achieved that. It is really simple and complicated at the same time. Why? Because of how Lambda works and what you have to think of when you “Code” because that really makes a difference.
Why did I think about it?
A few years ago, my manager told me to think about a processing architecture to process BIG volumes of records but not that heavy operations. Like 800k rows of data, with 16 columns, the amount of work required over each row isn’t complicated. So, Event-Driven Architecture!!
I went through a lot of issues on how to deal with the limited resources in Lambda and how to deal with my records dropping because of timing out and OS errors. S3 was another story also to learn how to tune it for my use case. A dear friend who works as a senior consultant in AWS Bahrain helped me get some tools to achieve this promising idea. It was one of the best experiences I ever got dealing with AWS resources.
Enough talking let's get some diagrams in place...
Solution Diagram:
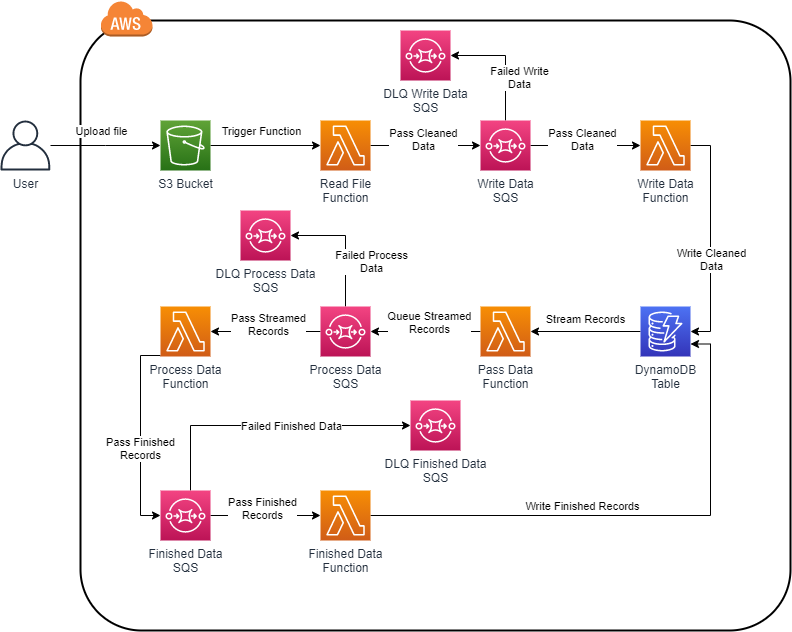
Diagram looks scary? Trust me, it isn’t.
Let me break it down for you in some steps:
1. Initiate the Process:
Because I’m adopting Serverless architecture, it means Event-Driven events that if something happened, things will act based on it and the results will trigger another action, till the end of the process.
So, in our case is an S3 Put request. When we upload the file into S3, it will put the file inside a bucket and when the file is fully uploaded into it, Lambda will get triggered with S3 payload. Our first step just got finished. What's next?
2. Clean Data:
Because we got a CSV file, some columns and rows could contain spaces, some special characters that MIGHT break your code. So, clean it up.
Cleaning these records will prepare them to be ready for insertion. But, since we have a lot of records and the function might fail, how to track what was added and what was leftover?
3. Add Clean Data Into a Queue:
We will add the cleaned records into a queue. The reason is to track what has been added and what did not get added. Basically, SQS will act as an organizer. It will send small batches into Lambda, Lambda will add it into DynamoDB, then it will return a success message to SQS to remove it from the queue.
In case of failed record, SQS will retry 3 times, as per my configuration, to try insert operation. If these 3 tries failed, then it will move it into Dead Letter Queue (DLQ) which is another SQS queue that has the failed records. Then, you can debug why these records never make it into DynamoDB and can be processed again or even reject.
4. DynamoDB:
Because we are trying to process massive chunks of data, we need some sort of Database that can handle the extreme load or records. DynamoDB solves this issue. There were a lot of experiments on how to handle the number of records and how to behave with the limited read/write throughput as write can handle 1kb data per unit. So, DynamoDB on-demand solves the issue.
As per AWS documentation, using on-demand DynamoDB throughput is the option when you cannot predict your workload. Because it will prepare the max throughput just in case it's needed.
We moved the records from CSV to DynamoDB, then what?
5. Stream Records to SQS:
DynamoDB is really good event executer for Lambda. When you enable Stream, you can specify a Lambda function that reacts to your passed payloads from it. The good thing is you need to act based on the type of record. We are dealing now with the newly added records. So, when we verify the tag, we add the record into another SQS.
The reason for this queue is the consistency of records delivery. You are adding the record once, capture it, and add it into the queue so you can deal with it. If not, then you have to scan the table to get unprocessed records and process them. Why the hassle? Let the queue deal with it.
6. Process Data:
We reached the latest stages of the record lifecycle in this architecture. When it reaches the Process Queue, it passes the records in batches, processes them, and then passes them to another queue. As I clarified earlier, for consistency purposes.
7. Update the Processed Record:
Finally, the record will be grabbed from the Finished queue and passed into the Lambda function that will update the record with the processed information. If records failed to be passed, DLQ will gather them for your further debugging and actions.
Challenges:
These points seem to be a straightforward scenario, BUT, it is not. Let me walk you through some problems and how they got solved.
1. Lambda Lambda Lambda:
Lambda is the key player here, we have limited time to execute the logic in your code. How can you ensure the records were read from the file, cleaned, and added to the queue? It's hard but what you will need is speed. I code in Python and I used the Multiprocessing library to speed things up. I used the Multiprocessing Process function to use every single possible processing unit in Lambda. This action made my process clean (in some tests) 558k transactions in 1:30 min! It was really fast. Again, it is not a straightforward scenario. Lambda can handle around 500 processes when you allocate the max memory. Any other process will raise “OS Error 38: too many files open”. Why did I face this issue? Because I joined all running processes and it was not closing finished processes. So, I run half the batch and loop over the running processes. If it is finished, I force it to close. Problem solved…
2. Keep an Eye on CloudWatch:
I made a big mistake by, passing the event variable into CloudWatch even when I was running the big batches. This resulted to write 6.6TB of data because of my many tests. The price of CloudWatch put log action is expensive so use it wisely. I made a big mistake by, passing the event variable into CloudWatch even when I was running the big batches. This resulted to write 6.6TB of data because of my many tests. The price of CloudWatch put log action is expensive so use it wisely.
3. DynamoDB on-Demand Is the Keyword:
I started my configuration by making my DynamoDB provisioned, which is something for the predicted workload. I made it 5 reads and write throughput and that was an issue. I faced the issue that out of 558k records, only 1k was inserted into my table. I raised it into 100 throughputs and still at least 60% out of the file gets lost and not added! Then I reread the documentation and noticed my issue, DynamoDB on-demand is the solution for the unpredicted load. I added all the 558k+ records within 5 min! Pretty FAST!
4. SQS Can Be Tricky:
SQS is a great service and has a lot of options and opportunities. But, you need to know what is the size of the batch you’re passing every time and what is the predicted time for your batch to finish. The reason for that is when you tell SQS to wait x seconds before making this batch available again, it might get processed multiple times. Know your code and your data, test test test, and then configure it for a heavy workload.
These points were my top concerns, S3 was interesting but not that complicated as I expected. But the main question is, does it worth it?
Everything in this life depends on conditions, if you don’t want to manage instances or you want it with minimal effort then yes, this scenario is valid for you. Keep in mind that debugging these use-cases can be tense because of how connected and how one mistake in one step can affect the coming steps.
Stay Safe.
Opinions expressed by DZone contributors are their own.
Comments