Building Your Own Web Scraper with CasperJS
While Python and Ruby are the proven languages for this task, there's no reason we can't do this in JavaScript right?
Join the DZone community and get the full member experience.
Join For FreeSometimes it can be difficult and laborious to collect data for your applications. A much needed API might be missing, or there just might be too much data to cope with. Sometimes, and only sometimes, you need to resort to web scraping.
Needless to say, this can be a legal minefield, so you should make sure to stay within the bounds of copyright law.
There are lots of tools out there to help you with scraping content, such as Import.io but there are times that these utilities just don't get you all the way there. Or maybe, like me, you're just curious and want to see how easy it really is.
The Challenge
Let's start with a simple challenge - a web scraper to go to Techmeme and get a list of the top stories of the day!
Note: I would have used DZone here, but I was having issues capturing the page. More about that later
Setting Up Your Machine
There's a little bit of installation that you're going to need to do first. I'll assume you already have Node.js installed (I mean, who doesn't!). Even though we're not using PhantomJS directly, you'll still need to install that. Version 2.0.1 is available now - you can either download it from the website, or use homebrew or an equivalent package manager.
If you're using a Mac with homebrew, you can install PhantomJS using
brew install phantomjsOnce that is downloaded, you'll need to install CasperJS in a similar fashion. You can think of CasperJS as a companion to PhantomJS. It actually gives you a much simpler API to work with web pages. Although it has been designed for testing web pages, just like PhantomJS, there are plenty capabilities that make it suitable for scraping content too.
CasperJS will allow us to write our script in JavaScript. You can test that it has correctly installed, and that it is on your PATH by typing casperjs on your terminal.
Writing Your Script
Next create a new JavaScript file to contain your script. In my example, I called it index.js. The first thing you need to do is create a casper instance in your code but requiring the module and passing in some basic parameters
var casper = require("casper").create({
waitTimeout: 10000,
stepTimeout: 10000,
verbose: true,
pageSettings: {
webSecurityEnabled: false
},
onWaitTimeout: function() {
this.echo('** Wait-TimeOut **');
},
onStepTimeout: function() {
this.echo('** Step-TimeOut **');
}
});
The onWaitTimeout callback above will be invoked when you are waiting for an element to be visible, after clicking a button for example, and the waitTimeout has been exceeded.
Now you can start up the casper instance and point it at the page that we want to inspect.
casper.start();
casper.open("http://techmeme.com");
Casper uses a promise framework to help you run everything in an ordered step-by-step manner. For the first step, you'll want to use the then function.
casper.then(function() {
//logic here
});
//start your script
casper.run();To get casper to open the webpage and run your logic, you'll need to make a call to the run function.
Checking the Web Page for Expected Elements
When scraping a webpage you are assuming that there is a particular structure in place. Before writing your script you will already have viewed the page source, or perhaps you'll have used developer tools to watch how the page changes based on certain actions.
So, let's start with a simple piece of logic; using the CasperJS assert system to make sure that a certain element is in place before continuing. If the element is not present, the script will simply fail, but at least you'll know why. This assertion behaviour is invaluable to watching out for changes in a page that you scraped successfully in the past, but may have a new structure since the last time you looked.
If you inspect the elements on the Techmeme front page, you'll notice that the Top News section is in a div with the id topcol1
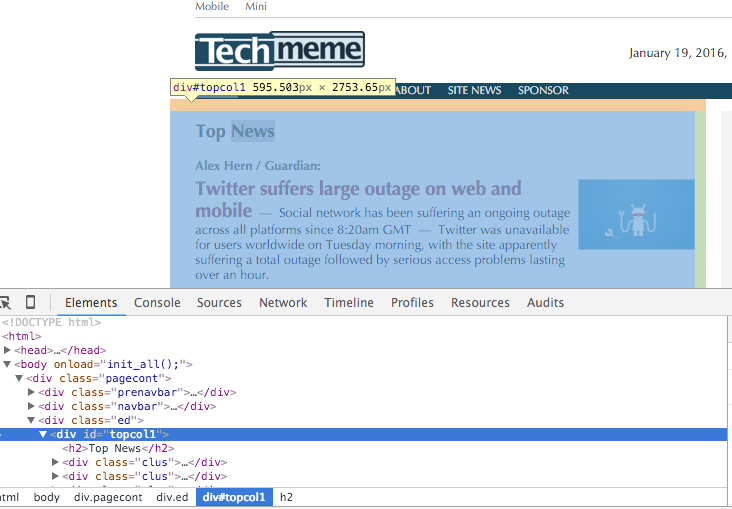
Let's use the assertion functionality to ensure that this element is present:
casper.then(function() {
this.test.assertExists("#topcol1");
If the element does not exist, the test (i.e. our script) will fail, otherwise it will simply continue.
You can also achieve the same results in a more verbose manner using the waitForSelector function:
this.waitForSelector("#topcol1",
function pass () {
console.log("Continue");
},
function fail () {
this.die("Did not load element... something is wrong");
}
);The benefit to using this function is that it allows the page to load up elements and waits before executing. The waitTimeout that you specified in the initial configuration will be used to decide how long to wait before failing.
Note: Sometimes you may have trouble finding elements with CasperJS. To get a picture (literally!) of what CasperJS can see, use the capture() function to save a screenshot
this.capture('screener.png');
Extracting the Content From the Page
Next let's take a look at how we can find the headlines from this page, along with the links to the articles. First, find the element that contains the content you're looking for. In our case, it's the div with the class ii.
CasperJS comes with an evaluate function that allows you to run JavaScript from within the page, and you can have the function return a variable for further processing.
There's nothing special in how we write this JavaScript. You will notice that I'm using plain old DOM methods rather than jQuery in this example, although you can use jQuery if you wish within the evaluate function:
var links = this.evaluate(function(){
var results = [];
var elts = document.getElementsByClassName("ii");
for(var i = 0; i < elts.length; i++){
var link = elts[i].getElementsByTagName("a")[0].getAttribute("href");
var headline = elts[i].firstChild.textContent;
results.push({link: link, headline: headline});
}
return results;
});If you were to use console.log statements inside the evaluate function, they would get printed to your own console though the remote.message handler, described in the next section.
Once the evaluation is complete, the results will be returned for you to do with as you will. You might write them to the file system, or just print them out to the screen:
console.log("There were " + links.length + " stories");
for(var i = 0; i < links.length; i++){
console.log(links[i].headline);
}Which will result in output like this:

Catching Errors When Scraping
Sometimes you may have errors in the JavaScript you are executing or there may be issues with the page that you are scraping. In these cases, you can catch the errors and print them to console using the 'remote.message' and 'page.error' events
casper.on('remote.message', function(msg) {
this.echo('remote message caught: ' + msg);
});
casper.on('page.error', function(msg, trace) {
this.echo('Error: ' + msg, 'ERROR');
});You can also watch for the resources that are being requested, and those that get loaded using the resource.error and resource.received events:
casper.on('resource.error', function(msg) {
this.echo('resource error: ' + msg);
});
casper.on('resource.received', function(resource) {
console.log(resource.url);
});Lots More to See
This article only scrapes the surface of what you can do with CasperJS. The documentation for the project is faultless, so make sure to check out the API to see what else you can do.
In the next article in this series I'll be looking at how to download images from a web page, and I'll also discuss how to use the file system functions built into CasperJS, which are more limited than what you will be used to from Node.js.
Opinions expressed by DZone contributors are their own.
Comments