Bulk Operations in MongoDB
By failing to take advantage of array inserts, you're essentially sending network packets that could take hundreds of documents over with only a single document in each packet.
Join the DZone community and get the full member experience.
Join For FreeLike most database systems, MongoDB provides API calls that allow multiple documents to be inserted or retrieved in a single operation.
These “Array” or “Bulk” interfaces improve database performance markedly by reducing the number of round trips between the client and the databases – dramatically. To realize how fundamental an optimisation this is, consider that you have a bunch of people that you are going to take across a river. You have a boat that can take 100 people at a time, but for some reason, you are only taking one person across on each trip — not smart, right? Failing to take advantage of array inserts is very similar: you are essentially sending network packets that could take hundreds of documents over with only a single document in each packet.
Optimizing Bulk Reads Using .batchsize()
When retrieving data using a cursor, you can specify the number of rows fetched in each operation using the batchSize clause. For instance, below we have a cursor where limit controls the total number of rows we will process, while and arraySize controls the number of documents retrieved from the mongoDB database in each network request.
cursor = useDb.collection('millions').find().limit(limit).batchSize(arraySize);
for (let doc = await cursor.next(); doc != null; doc = await cursor.next()) {
counter++;
}Note that the batchSize operator doesn’t actually return an array to the program — it just controls the number of documents retrieved in each network round trip. This all happens “under the hood” from your programs point of view.
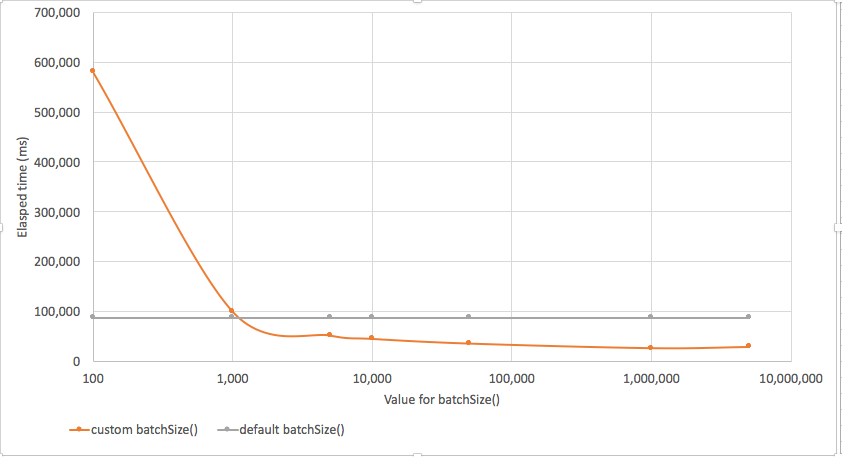
By default, MongoDB sets a pretty high-value for .batchSize, and you might easily degrade your performance if you fiddle with it. However, if you are fetching lots of small rows from a remote table you can get a significant improvement in throughput by upping the setting. Below we see the effect of manipulating batchSize(). Settings of batchSize below 1,000 made performance worse - sometimes much worse! However, settings above 1,000 resulted in significant performance improvements (note the logarithmic scale).
Avoiding Excessive Network Round Trips in Code
batchSize() helps us reduce network overhead transparently in the MongoDB driver. But sometimes the only way to optimize your network round trips is to tweak your application logic. For instance, consider this logic:
for (i = 1; i < max; i++) {
//console.log(i);
if ((i % 100) == 0) {
cursor = useDb.collection(mycollection).find({
_id: i
});
const doc = await cursor.next();
counter++;
}
}We are pulling out every hundredth document from a MongoDB collection. If the collection is large that is a lot of network round trips. In addition, each of these requests will be satisfied by an index lookup and the sum of all those index lookups will be high.
Alternatively, we could pull the entire collection across in one operation and then extract the documents we want.
const cursor = useDb.collection(mycollection).find().batchSize(10000);
for (let doc = await cursor.next(); doc != null; doc = await cursor.next()) {
if (doc._id % divisor === 0) {
counter++;
}
}Intuitively, you might think that the second approach would take would take much longer. After all, we are now retrieving 100 times more documents from MongoDB, right? But because the cursor pulls across thousands of documents in each batch (under the hood), the second approach is actually a lot less network intensive. If the database is located across a slow network, then the second approach will be much faster.
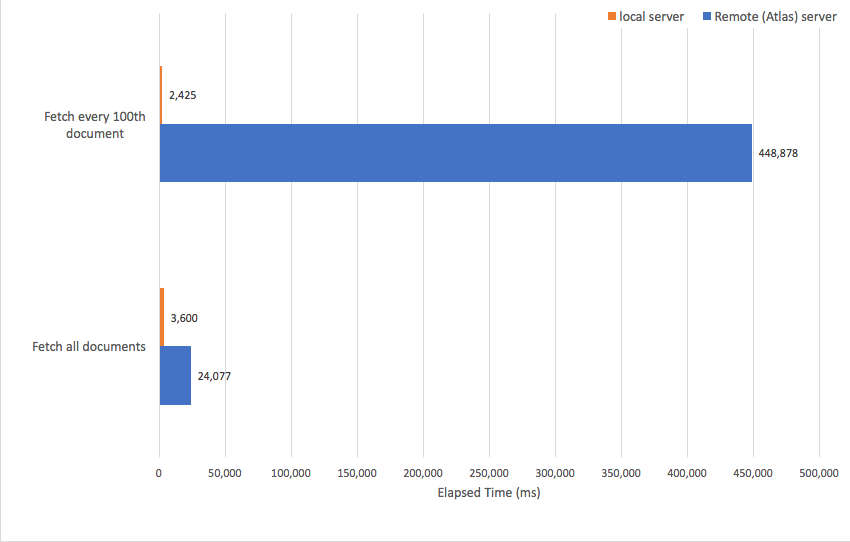
Below we see the performance of the two approaches for a local server (for example, on my laptop) versus a remote (Altas) server. When the data was on my laptop the first approach was a little faster. But when the server was remote, pulling all the data across in a single operation was far faster.
Bulk Inserts
Just as we want to pull data out of MongoDB in batches, we also want to insert in batches - at least if we have lots of data to insert. The code for batch insert is a bit more complicated than for the find() example. Here’s an example of inserting data in batches.
if (orderedFlag == 1)
bulk = db.bulkTest.initializeOrderedBulkOp();
else
bulk = db.bulkTest.initializeUnorderedBulkOp();
for (i = 1; i <= NumberOfDocuments; i++) {
//Insert a row into the bulk batch
var doc = {
_id: i,
i: i,
zz: zz
};
bulk.insert(doc);
// Execute the batch if batchsize reached
if (i % batchSize == 0) {
bulk.execute();
if (orderedFlag == 1)
bulk = db.bulkTest.initializeOrderedBulkOp();
else
bulk = db.bulkTest.initializeUnorderedBulkOp();
}
}
bulk.execute();On lines 2 or 4 we initialize a bulk object for the bulkTest collection. There are two ways to do this – we can create it ordered or non-ordered. Ordered guarantees that the collections are inserted in the order they are presented to the bulk object. Otherwise, MongoDB can optimize the inserts into multiple streams which may not insert in order.
On line 9, we add documents to the “bulk” object. When we hit an appropriate batch size (line 11), we execute the batch (line 12) and reinitialize the bulk object (lines 14 or 16). We do a further execute at the end (line 19) to make sure all documents are inserted.
I inserted 100,000 documents into a collection on my laptop, using various “batch” sizes (for example, the number of documents inserted between execute() calls). I tried both ordered and unordered bulk operations. The results are charted below:
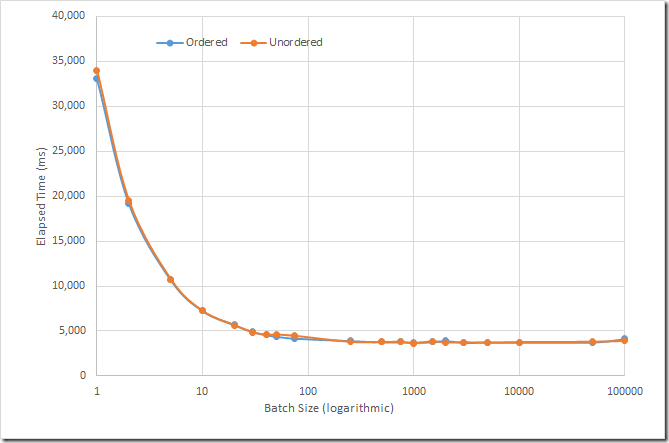
The results are pretty clear — inserting in batches improves performance dramatically. Initially, every increase in batchsize reduces performance but eventually the improvement levels off. I believe MongoDB transparently limits batches to 1000 per operation anyway, but even before then, the chances are your network packets will be filled up and you won’t see any reduction in elapsed time by increasing the batch size. To use the analogy we used at the beginning of this post, the rowboat is full!
Summary
A lot of the time in MongoDB we perform single document operations. But just as often, we deal with batches of documents. The best practice coding techniques outlined in this post can result in huge performance improvements for these scenarios.
Published at DZone with permission of Guy Harrison. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments