C++11 Performance Tip: Update on When to Use std::pow
Take a look at this benchmark to see when to use std::pow in C++, comparing the performance of std::pow against direct multiplications
Join the DZone community and get the full member experience.
Join For FreeA few days ago, I published a post comparing the performance of std::pow against direct multiplications. When not compiling with -ffast-math, direct multiplication was significantly faster than std::pow, around two orders of magnitude faster when comparing x * x * x and code:std::pow(x, 3). One comment that I've got was to test for which n is code:std::pow(x, n) becoming faster than multiplying in a loop. Since std::pow is using a special algorithm to perform the computation rather than be simply loop-based multiplications, there may be a point after which it's more interesting to use the algorithm rather than a loop. So I decided to do the tests. You can also find the result in the original article, which I've updated.
First, our pow function:
double my_pow(double x, size_t n){
double r = 1.0;
while(n > 0){
r *= x;
--n;
}
return r;
}And now, let's see the performance. I've compiled my benchmark with GCC 4.9.3 and running on my old Sandy Bridge processor. Here are the results for 1000 calls to each functions:
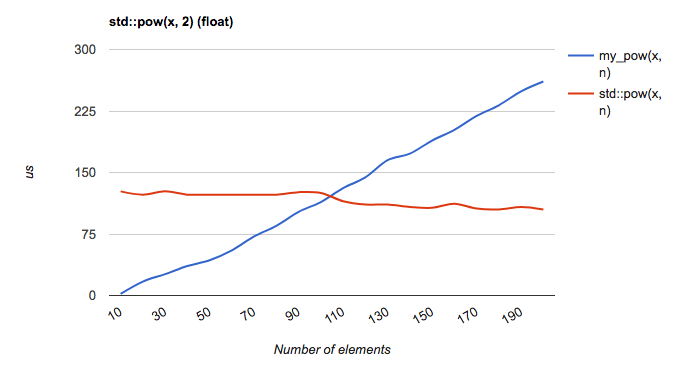
We can see that between n=100 and n=110, std::pow(x, n) starts to be faster than my_pow(x, n). At this point, you should only use std::pow(x, n). Interestingly too, the time for std::pow(x, n) is decreasing. Let's see how is the performance with a higher range of n:
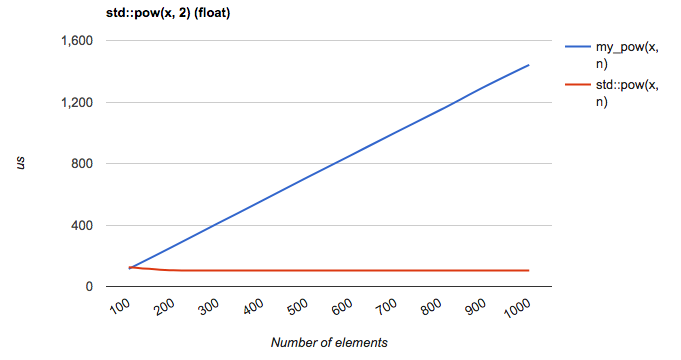
We can see that the pow function time still remains stable while our loop-based pow function still increases linearly. At n=1000, std::pow is one order of magnitude faster than my_pow.
Overall, if you do not care much about extreme accuracy, you may consider using you own pow function for small-ish (integer) n values. After n=100, it becomes more interesting to use std::pow.
If you want more results on the subject, you take a look at the original article.
If you are interested in the code of this benchmark, it's available online: bench_pow_my_pow.cpp
Published at DZone with permission of Baptiste Wicht. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments