Caching in Mule 4: How It Works
In this article, let's see how caching in Mule 4 works.
Join the DZone community and get the full member experience.
Join For Free
Overview
Caching is the term for storing reusable responses in order to make subsequent requests faster. There are many different types of caching available, each of which has its own characteristics. Application caches and memory caches are both popular for their ability to speed up certain responses.
By storing relatively static data in the cache and serving it from the cache when requested, the application saves the time that would be required to generate the data from scratch every time. Caching can occur at different levels and places it in an application.
On the server-side, at the lower level, the cache may be used to store basic data, such as a list of most recent article information fetched from the database; and at the higher level, the cache may be used to store fragments or whole information, such as the rendering result of the most recent articles. On the client-side, HTTP caching may be used to keep the most recently visited page content in the browser cache.
How Does Caching Work?
Caching is an act of keeping data in temporary storage to allow retrieval without having to request the data repeatedly from the original data source, reducing the trips to the original data source and in turn, improving the response time. The word “caching” spans in a lot of different dimensions, but we’re discussing it in the context of a request from the API to an application (e.g. Database, Salesforce, Rest API) hosted on a server. Let’s refer to a “database” as an original data source going forward. Caching is a buffering technique that stores frequently-queried data in a temporary memory. It makes data easier to be accessed and reduces workloads for databases.
For example, you need to retrieve a user’s profile from the database and you need to go from server to server. After the first time, the user profile is stored next (or much nearer) to you. Therefore, it greatly reduces the time to read the profile when you need it again. The cache can be set up at different levels or on its own, depending on the use case. There are several benefits to using a cache.
Benefits
Effective caching aids both content consumers and content providers. Some of the benefits that caching brings to content delivery are:
- Decreased network costs: Content can be cached at various points in the network path between the content consumer and content origin. When the content is cached closer to the consumer, requests will not cause much additional network activity beyond the cache.
- Improved responsiveness: Caching enables content to be retrieved faster because an entire network round trip is not necessary. Caches maintained close to the user, like the browser cache, can make this retrieval nearly instantaneous.
- Increased performance on the same hardware: For the server where the content originated, more performance can be squeezed from the same hardware by allowing aggressive caching. The content owner can leverage the powerful servers along the delivery path to take the brunt of certain content loads.
- Availability of content during network interruptions: With certain policies, caching can be used to serve content to end users even when it may be unavailable for short periods of time from the origin servers.
To Cache or Not to Cache
Caching is one of the most effective design strategies for improving the latency and performance of an API. An API taking a longer time to respond may result in cascaded delays and timeouts in the consuming applications. Further, a longer processing time of an API could result in consuming and blocking more and more server resources during high volume API calls and may end up in a server crash or deadlocks. Hence low latency is one of the most desired features in API implementations, and it's imperative that while building an effective API, the right design strategy should be adopted to improve the API response time as much as possible.
Caching can be a very effective technique to improve API response time, however, care must be taken to use caching for appropriate scenarios only in order to avoid functional errors resulting from stale data. In this article, I will be discussing some of the guidelines and scenarios where caching could be effectively used while developing APIs in Mule.
Typically, in APIs, the caching approach can be effectively used for data such as,
Static data, which rarely changes over time (e.g. static lookup data)
Data that changes only during a known interval of time. (e.g. data from a back-end data source system which allows only daily data updates – only daily/nightly batch updates)
Fixed time data (e.g. access tokens that expire after fixed time interval)
Though the caching mechanism is effective, it is also important to note that caching implementation has to be accompanied by a suitable cache-invalidation approach in order to avoid the APIs returning stale data to its consumers. Functional errors in a production environment due to stale data are very difficult to catch and debug, as they leave no trace in the form of errors in the application logs.
Caching in Mule 4
There are multiple approaches that can be used in Mule to implement caching for APIs, based on what data you decide to cache.
The two main approaches are:
Caching the whole API response using “HTTP Caching” policy in API Manager
Caching a specific back-end response within the API code using “Cache Scope” or “Object Store” Connector
Here, we are going to discuss the second approach. When it is not feasible to cache the whole API response, there can still be possibilities to improve the overall API response time by applying caching within the processing flows at appropriate places.
Cache scope internally uses Object Store to store the data. Cache scope and object store have their specific use cases where they can be used effectively.
Cache Scope in Mule
Some of the most obvious scenarios for caching are file operations and external system interactions (database, web services, etc). However, sometimes it is also beneficial to apply caching on other code elements that involve complex internal processing. You can use a cache scope to reduce the processing load on the Mule instance and to increase the speed of message processing within a flow.
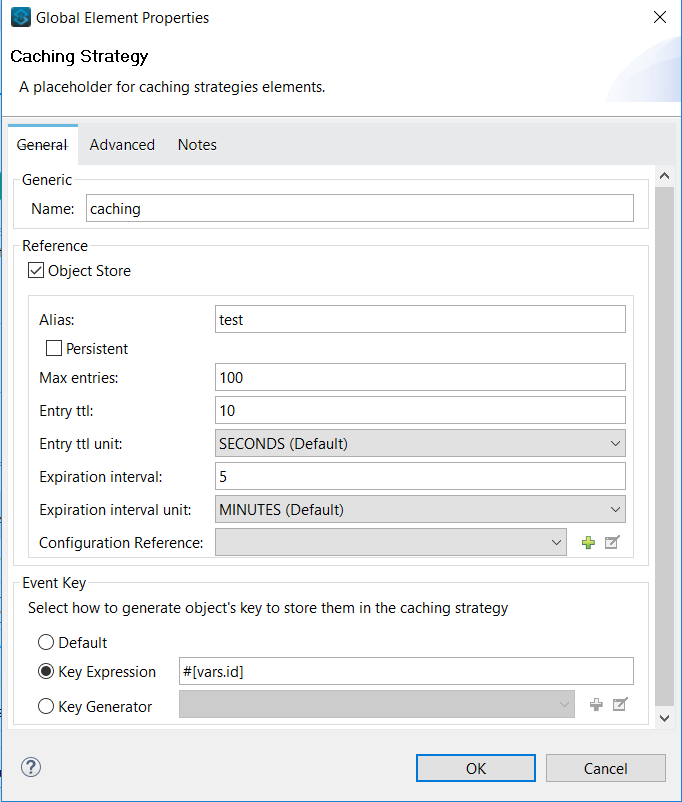
Cache scope, by default, is using in memory caching strategy. This has such drawback that when mule starts caching large payloads it may reach memory limit and throw java heap exception. As a consequence, this defaults strategy should be replaced. This can be done by creating object store caching strategy.
How Cache Scope Works
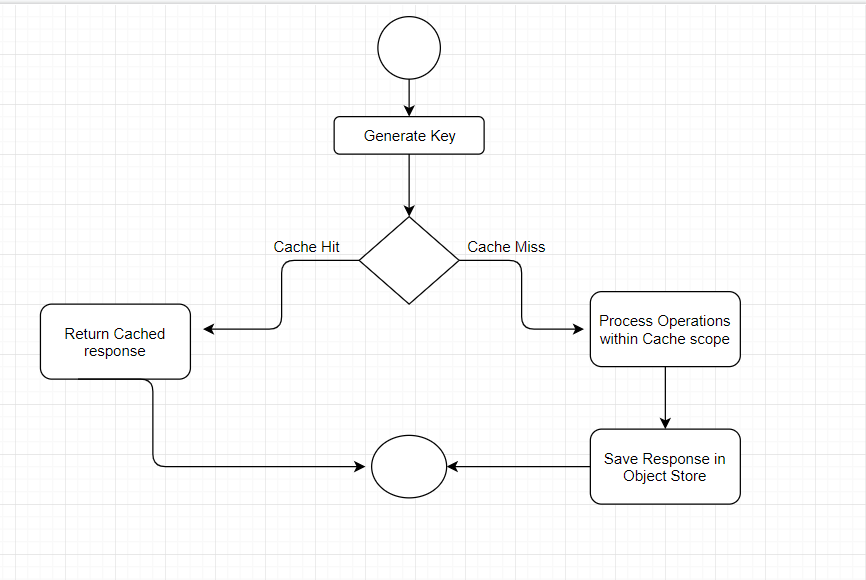
Implementing Caching in Mule 4
Enough with theory; let’s try it with an example application. I have generated a simple flow with current time value and cached time value so that it will be easy to check the current time and cached time and validate both values.
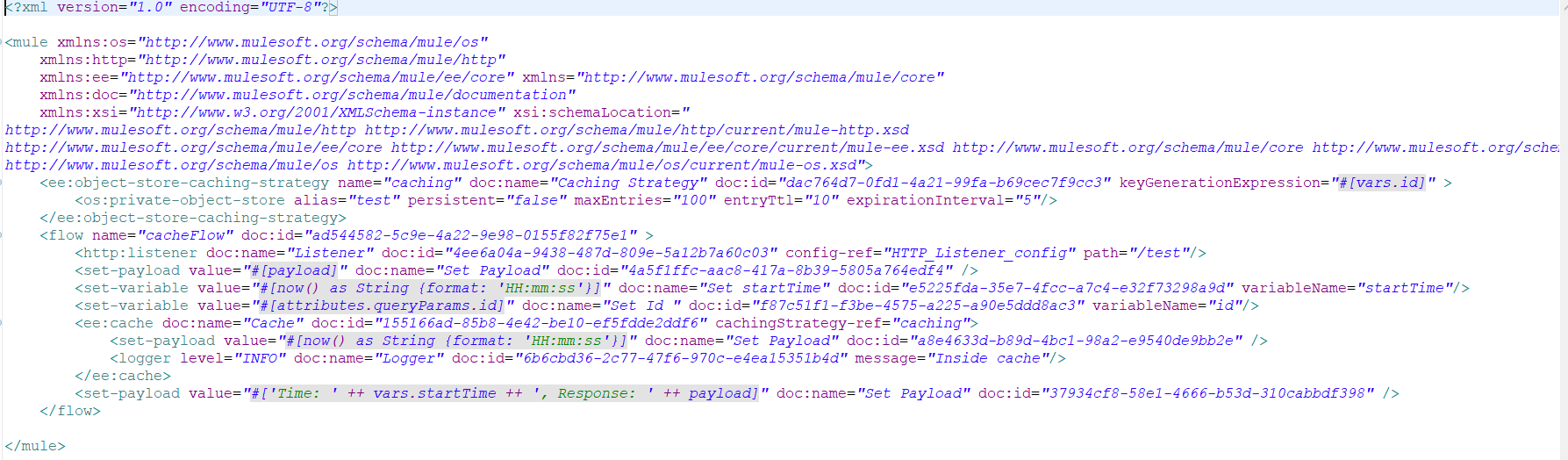
Here is a configuration XML for flow
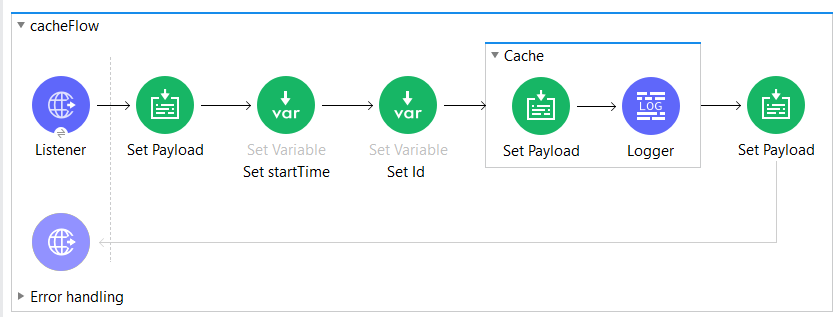
Application flow
Cache Configuration Details
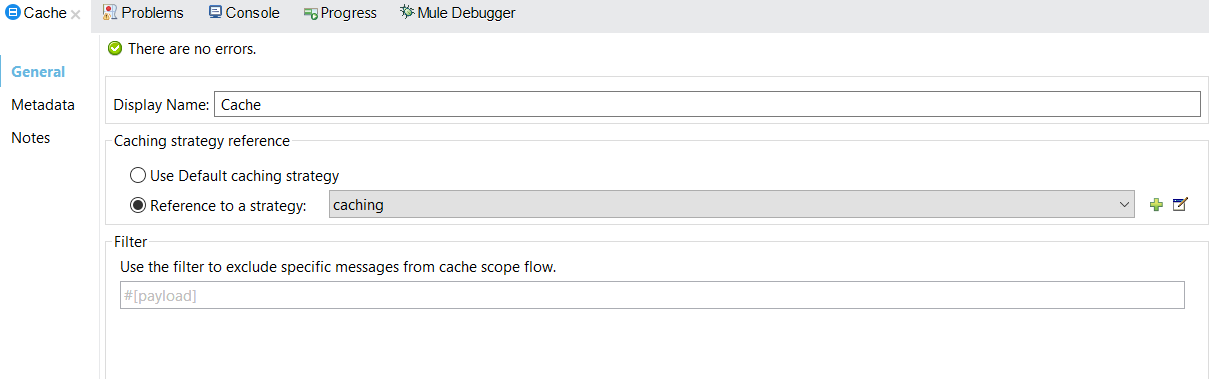
Caching Strategy Details
Deploying the caching application
Now we can test our application.
Request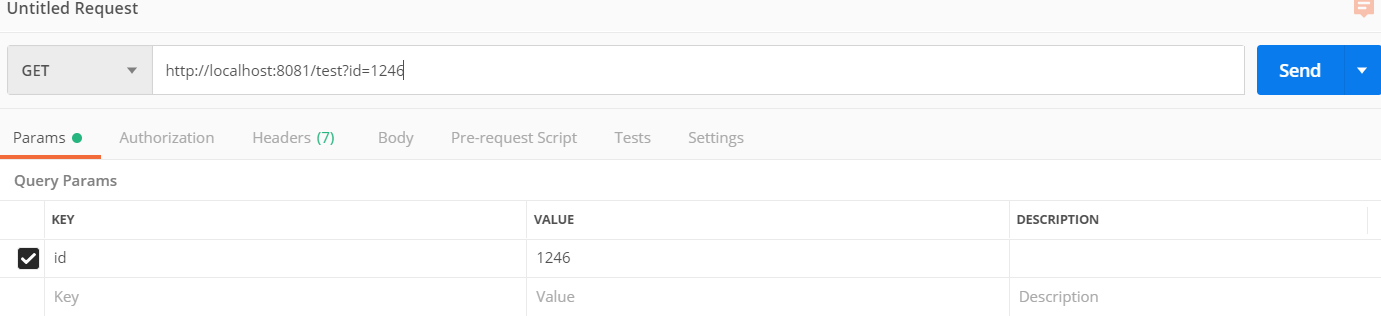
Response
First hit
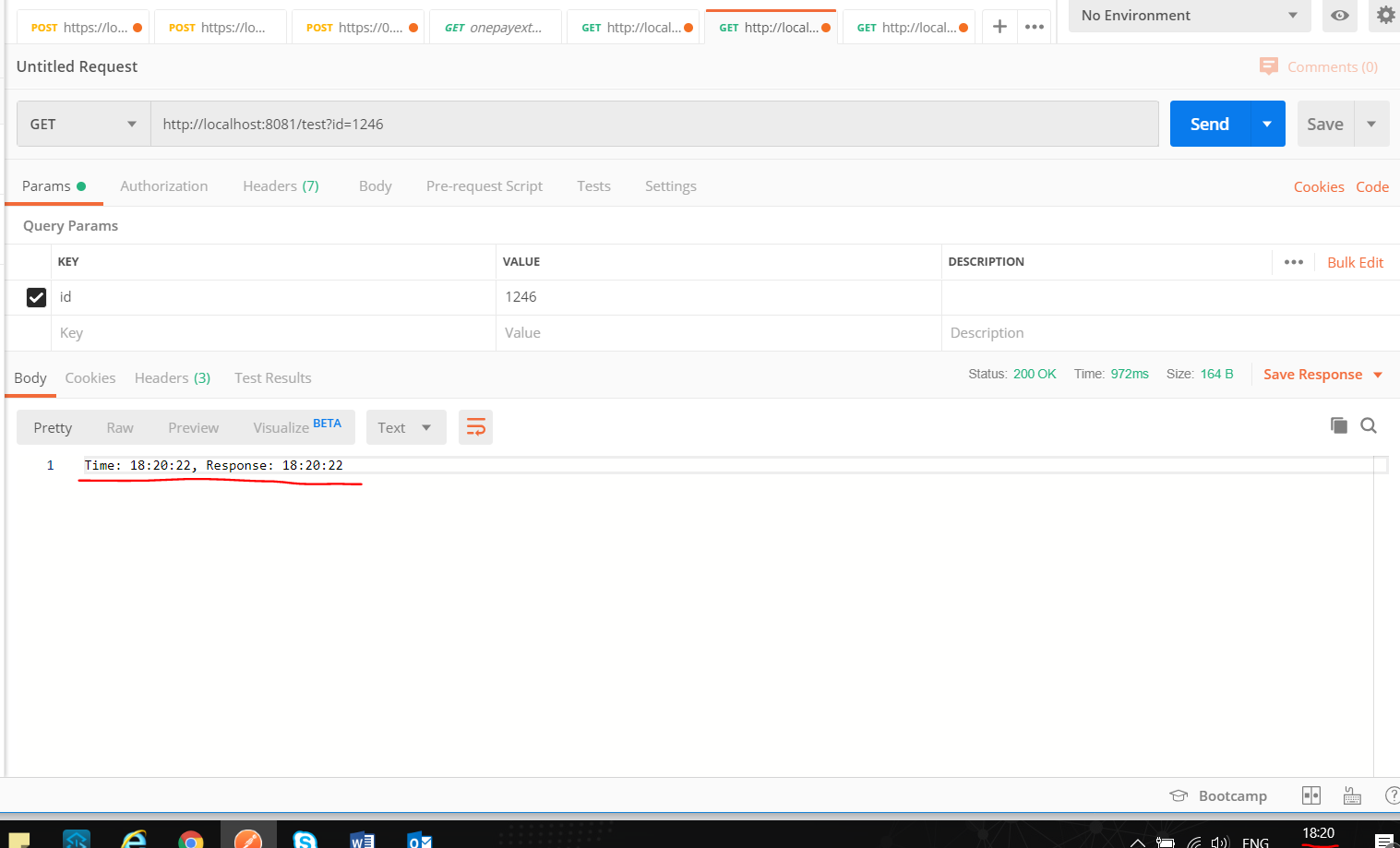
Second Hit after 2 mins and we can see the current time and response from the cache.

Conclusion
Caching is a powerful tool. By implementing it, we can improve our application’s performance by limiting the number of external HTTP requests. We cut out the latency from the actual HTTP request itself. When used correctly, it will not only result in significantly faster load times but also decrease the load on your server.
In many cases, we are not just making a request. We have to process the request as well, which could involve hitting a database, performing some sort of filtering, etc. Thus, caching can cut the latency from the processing of the request as well.
It is also important to note that caching implementation must be accompanied by a suitable cache-invalidation approach to avoid the APIs returning stale data to its consumers.
Opinions expressed by DZone contributors are their own.
Comments