Capacity and Compliance in Hybrid Cloud, Multi-Tenant Big Data Platforms
We cover capacity governance, technical risk management, security compliance, and site reliability engineering in big data platforms.
Join the DZone community and get the full member experience.
Join For FreeAs organizations are realizing how Data-Driven insights can empower their strategic decisions and increase their ROI, the focus is on building Data Lakes and Data Warehouses where all the Big Data can be safely archived. Big data can then be used to empower various data engineering, data science, business analytics, and operational analytics initiatives to benefit the business by improving operational efficiency, reducing operating costs, and making better strategic business decisions. However, the exponential growth in the data that we humans consume and generate day to day makes it necessary to have a well-structured approach toward capacity governance in the Big Data Platform.
Introduction:
Capacity governance and scalability engineering are inter-related disciplines, as this requires a comprehensive understanding of our compute and storage capacity demands, infrastructure supply, and their inter-dynamics to develop an appropriate strategy for scalability in the big data platform. In addition to this, technical risk resolution and security compliance are equally important aspects of capacity governance.
Similar to any other software application, big data applications operate upon personally identifiable information (PII) data of the customers and impact the critical business functions and strategic decisions of the company. Likewise, big data applications must follow the latest data security and service reliability standards at all times. All the IT Hardware and software components must be regularly updated or patched with the latest security patches or bug fixes. Regardless of which infrastructure it is deployed, each component of the big data platform must be continuously scanned to quickly identify and resolve any potential technical or security risk.
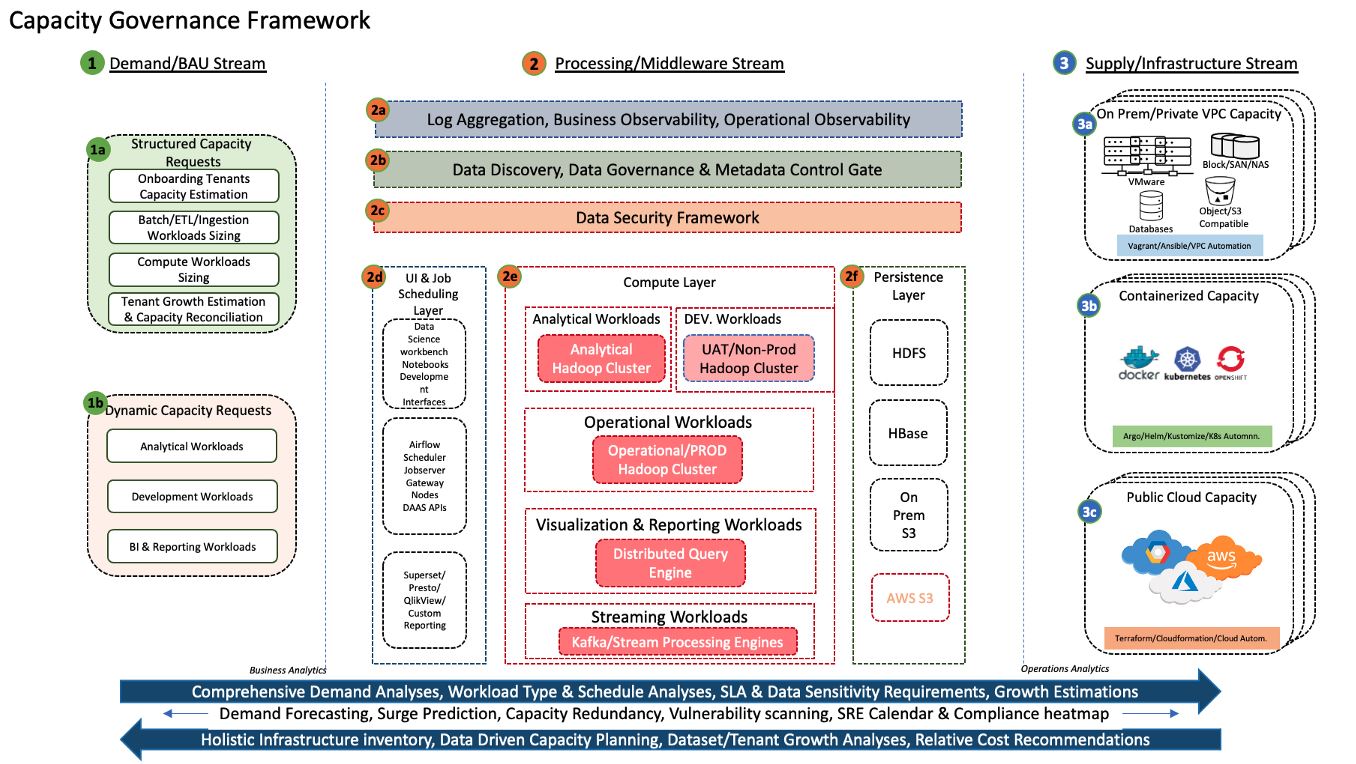
The diagram above is the functional architecture of the Capacity Governance framework for a Big Data platform. The rightmost section in the diagram represents the infrastructure or supply stream which is closer to the technical users. The leftmost section of the diagram is the demand stream or business-as-usual stream which is closer to business users who would be more interested in solving business use cases rather than getting into technical details of the solution. The center section represents the Big Data framework where we manage the supply against the demands using an appropriate set of tools and technologies.
To keep the article brief we will keep the technical architecture out of the scope as a bunch of microservices and jobs were utilized to curate the insights from a diverse set of tools appropriate for specific problem domains. At the start we asked the obvious question — is it worth putting effort to build a solution around this problem? Or we can identify one or few tools in the market to solve the whole capacity and compliance problem. But over the time working with a bunch of monitoring, APM, and analytics tools we understood that we will need to weave through the information coming out from a diverse set of tools that are efficiently solving the diverse set of domain-specific problems, to build the bigger picture at platform level. While we should not try to re-invent what existing tools already offer, we should also not try to answer all of the functional problems through one tool or singular approach.
For example, the tools suitable for monitoring, log analysis, and application performance management for spark applications running on YARN are completely different from the tools used for the same purpose for microservices deployed to containers in Kubernetes. Likewise, it will be irrelevant to retrofit a tool appropriate for monitoring, APM, and autoscaling in on-premise VMware to Virtual machines provisioned in the public cloud. Each public cloud offers a bunch of native monitoring tools and autoscaling API(s) for the same purpose.
A major portion of data science or AI Industrialization project is not necessarily MapReduce/spark/big data, there is a considerable portion of the project that interfaces with external systems or are normally deployed as conventional software or microservice. This just requires a diligent selection of DevOps tools and underlying deployment platforms.
For financial organizations, it is extremely important to ensure continuous compliance and high availability of the Big Data Platform. This requires a comprehensive understanding of available compute and storage infrastructure (supply), the 4 Vs (Volume, Velocity, Variety, Veracity) and nature of the workload (processing), SLA, and Data Sensitivity requirements (Demand/BAU) to build a suitable and scalable solution for a particular business use case while ensuring high availability and capacity redundancy in the Big Data Platform.
Delivery Approach:
Our approach was to follow the maturity matrix, initially from data collection and exploration, to identifying trends and performing analytics, and then to leverage the analytics to empower intelligent operations. We targeted to achieve this in 7 phases:
1. Comprehensive Inventory
The first phase of the project was to build a comprehensive cross-platform inventory. Virtual Machines Infrastructure level inventory was readily available from On-Prem monitoring tools, however, the API(s) and pattern of monitoring in the containerized platform and different public clouds were different. Besides this, only VM Level inventory was not sufficient. The platform used multiple In-House, Vendor Supported, and Open Source middleware which consist of distinct components involved in requisite functions. We had to implement the publishers, observers, and subscribers to perform the role tagging for middleware components deployed to Virtual Machine, Containerized (Kubernetes/Openshift), or Public cloud infrastructure platforms.
2. Infrastructure Utilizations, Consumption Trends, and Analytics
Once we have a clear understanding of the roles deployed across the hybrid cloud infrastructure, we needed to overlay the infrastructure utilization trends and classify the data into more fine-grained component-level metrics.
Also, the monitoring data must solve both the problems:
- The Point of Time incident management requires quick identification, notification, and resolution of CPU, RAM, and network capacity issues. Sampling frequency for incident management dashboards is expected to be near real-time.
- The Time Series data which is an aggregation of curated Capacity matrices with clear tagging of individual middleware components sampled at 5 minutes and rolled up to Hourly, Daily, Weekly, and Monthly sampling frequency — facilitated long term Capacity Utilization and service health analytics.
- All this data was still technical/Infrastructure utilization data. We then needed to overlay our multi-tenancy Occupancy data on the top of Infrastructure Utilization to come up with accrued bifurcation of tenant-wise occupancy for each Dataset, Job, Project/Initiative, and Business Unit.
3. Demand Analysis and Forecasting
Once we managed to obtain the tenant-wise occupancy data from infrastructure utilization, we were then in a position to identify the growth trends at storage, compute and project size levels. Based on the relative growth of individual datasets/tenants we had to identify the top occupants, the fastest-growing datasets/tenants, the top (compute) wasters, and non-critical noisy neighbors.
4. Performance Optimization
The next natural step was to identify the top wasters and work together with Business Unit partners to optimize them and reduce wastage, ensure redundancy and increase service reliability. At each point in time, there are thousands of job runs scheduled by the job scheduler onto the cluster, and each queue contains hundreds of jobs submitted serving daily, weekly, monthly or ad-hoc schedules. It was thus decided to identify and tune the biggest CPU, and RAM wasters and to reschedule the non-critical jobs to non-critical or off-peak time slots.
5. High Availability, Capacity Redundancy, and Scalability
Identifying the business-critical workloads and ensuring sufficient capacity redundancy for them, re-aligning non-critical noisy neighbors to off-peak hours is one of the critical key performance indicators for the site reliability engineering team. Besides this ensuring high availability at each middleware component level, identifying site reliability issues, and making sure each platform component is individually and collectively scalable to handle peak hour surges could only be achieved when we monitor and observe the operational performance data over the time.
For each middleware component, high availability (preferably active-active) at both the worker and the master level is an essential requirement, particularly for business-critical category 1 applications. For In-House applications, thorough and consistent code analyses, unit-integration-performance testing, dependency license, and vulnerability scanning data need to be gathered at each component level. For managed services, in the public cloud, the service level agreement needs to be established with the respective cloud infrastructure providers. The same software support, patching, and incident management support SLA needs to be ensured by external software providers.
6. Autoscaling, Self-Healing, Cost Optimizations
In the final phase of maturity, the capacity governance framework will become more intrusive, where our decision engines not only produce schedules, weekly-monthly roosters for SRE Teams but also can auto-heal or clean up some of the services without human intervention (depending upon the criticality of the environment, service level agreement and the impact radius of the change). All the data and analytics captured above, in the end, must be curated to identify the most performant and cost-effective infrastructure suitable for each middleware component.
The data is also used to create autoscaling policies, self-healing automation (specifically for non HA components), performance and cost optimization reports, and recommendation models.
7. Technical Risk and Continuous Compliance
Procuring and setting up a performant and security-compliant system at once is not enough, it is necessary to ensure that every component remains compliant and free from ongoing threats and vulnerabilities regardless of which infrastructure platform and topology it is deployed.
Tech risk and compliance are one of the extremely important aspects of service delivery in the financial industry as service disruption may lead to monetary losses and regulatory penalties, particularly for Cat1 applications. Once a project is delivered to the production environment the buck does not stop there.
- End-of-life hardware must be replaced. End of support software needs to be updated. Ending support licenses should be renewed on a timely basis.
- The various components deployed to different platforms expose various TCP and other ports which must be consistently scanned for requisite network zone isolation, in transit (SSL), and at rest (encryption) standards.
- Each middleware sub-component / micro-service must be scanned punctually for critical vulnerabilities (like the recent log4j vulnerability). Servers need to be patched timely with the latest operating system and security patches.
- Servers need to be rebooted regularly to corroborate disaster recovery at the middleware layer, high availability, to detect and eliminate single points of failures, and to apply patches that require a reboot.
- In terms of cloud EC2 instances, AMI(s) need to be refreshed, credentials and encryption keys, and SSL Certificates need to be rotated.
- Capacity redundancy needs to be scanned and ensured for monthly tenant growth for structure demands and peak hour utilization for dynamic demands.
1. The Demand/BAU Stream
A business requirement undergoes reckonings from various perspectives to culminate into a technical architecture that combines the appropriate set of big data tools and deployment infrastructure to solve the use case most appropriately.
The most appropriate type of tools and capacity required for a particular use case can only be decided based on the nature of data from the source system and the ingestion, computing, and reporting requirements. For example, streaming jobs will require a continuous stream of smaller memory allocation (and appropriate compute and network bandwidth to process the streaming workload). On the other hand, Batch/ETL ingestion of historical data would require a sudden burst of lots of RAM and Network, and eventually, it would become small in off-peak hours. Analytical and Reporting workloads on the other hand may require a sudden burst of CPU and RAM depending upon the size of the dataset and complexity of the query.
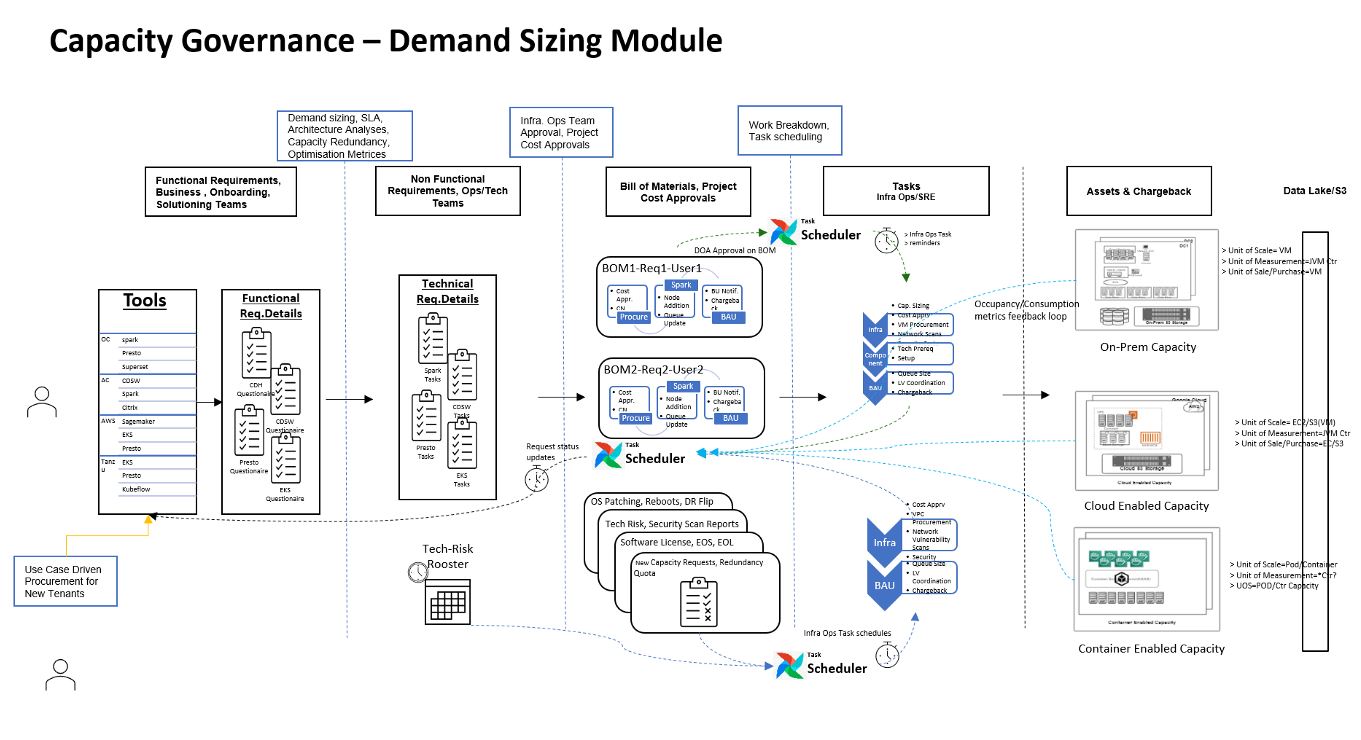
The Demand Sizing Module:
One of the important modules of the Capacity Governance framework is the Demand Sizing module. This module streamlines the predictable and unpredictable capacity workload demands to the existing supply /availability of infrastructure capacity. The module also catalyzes the feedback loop from the actual growth in capacity back to the stakeholders responsible for managing the demand.
Business Requirements, Technical Requirements vs. Operational Scalability:
For a business user, the functional requirement could be simple streaming or batch ingestion of some dataset into the data lake for future data engineering or providing a strategic report comprehending patterns in some big data dataset, or training a recommendation model on certain datasets in the data warehouse.
In a broader sense, we classified the demands into two types — 1. Structured, 2. Dynamic. Let us look at these.
1a. Structured Capacity Requests:
Structured capacity requests are the ones where we were able to predict the capacity sizing requirements and job schedules so that we can provision requisite minimum guaranteed capacity or maintain appropriate redundancy to handle these workloads during peak hour surges. These workloads also include streaming jobs where the streaming load from the source systems can be reasonably predicted. Similarly, the capacity can also be provisioned beforehand for the Model API(s) once they are finally deployed.
1b. Dynamic Capacity Requests:
Dynamic capacity requests consist of jobs that were still in an experimental or exploratory phase where capacity sizing cannot be predicted upfront and there can be no fixed schedules for when these jobs will be executed. This includes the non-production developer environments where Data Engineers build their ingestion or compute jobs and experimentation environments where Data Scientists directly train their models before releasing them for production. A major portion of these workloads are active during office hours and an appropriate capacity redundancy needs to be maintained to handle these surges during peak hours and to reclaim the capacity during off-peak hours(if it saves cost or can be re-allocated to other critical environments).
Unit of Measure vs. Unit of Scale:
While considering the scalability of the platform as a whole there are three important factors we will need to consider:
While considering the scalability of the platform as a whole there are three important factors we will need to consider:
Unit of Scale: for example, in Openshift we can define the scalability at a container, in VPC it will be VMWare, in Aws, it will be either your EKS cluster or your ec2 instances, and s3 buckets.
Unit of Measurement: It is imperative that if the unit of scale is closest to the unit of measurement. For example in the EMR the unit of scale will be ec2 instance but since this is a multi-tenancy cluster the unit of measurement still would be CPU hours or memory hours used by a spark job
Unit of Sale/Purchase: This is the entity at which we can put a price tag. Since the Big Data platform itself is a resource manager, this is going to be a mix. If we build individual clusters for teams we can scale the whole cluster still it needs to be answered which job consumed how much resources.
The Demand Analyses Loop (Forward Capacity Planning):
It is essential to build each data science/ data engineering project with a proper understanding of the use case, appropriate choice of tools, and proper capacity planning. Despite a good understanding of the four V(s) of the source system, the actual footprint of the destination dataset can only be estimated. Besides this, with continuous ingestion and compute jobs running as per schedule or on an ad-hoc basis on the cluster — the capacity required to accommodate the growing T1, T2, and T3 datasets needs to be predicted based on the combined trend in the growth of each category of ingestion vs compute datasets.
2. The Processing/Middleware Stream
At the center of the diagram is the middleware stream where we have various Big Data tools. This stream is closest to our big data subject matter experts and SRE Leads. The diagram broadly classifies the platform components based on operational functionality.
The biggest chunk of capacity is the distributed compute layer where we use various Hadoop/spark frameworks (like Cloudera CDH/CDP, Databricks, Spark on Kubernetes, etc.) the query engine (like Presto/Impala), and streaming engine (Kafka).
2a. 2b. 2c. Essential Services (Monitoring and Log Aggregation, Data Governance, Data Security):
There are some tools that provide the cross-environment, cross-cluster essential services for all types of workloads in the platform. This includes the tools involved in the function of Log Aggregation, Data Discovery/Data governance, and Data Security. These tools require a cross-environment coherence and ubiquitous presence to ensure the sustainable, secure, and reliable functioning of the big data platform as a whole.
2e. Analytical/Data Science Workloads:
The Data Science workloads usually have a very different usage pattern and capacity requirements than the scheduled ingestion or compute jobs in the operational cluster. The Data Scientists may need to leverage a specific set of huge datasets into the memory of distributed processing engine to train the model. This might persist until the model is trained but that is the only time it is required. The model training need not follow any specific schedule and the load on the cluster may be high during the normal office hours while the cluster is practically free over off-peak hours.
Also, the data security and access control features required in the Analytical cluster are much higher as this allows direct access to Data Scientists on the Production data which might container customer data. Strict tokenization, data storage, retrieval, and data leakage prevention mechanisms must be in place to avoid any data breach or personal identifiable information (PII) data theft.
2f. Developer/Non-Prod Workloads:
For every ingestion, and compute job promoted to the Operational environments. The data here is either synthetic or sterilized data. Usually, developer environments are shared tenancy and are smaller compared to production environments. The support SLA is also lesser intensive. Essentially big data solutions are dependent on the four Vs of actual production data so the actual footprint and performance of a job can only be validated in the production zone. Normally a separate QA environment is provisioned for performance tuning of jobs in a real production network zone. This environment is used to validate the jobs from business logic, data governance, data security, and integration testing of view.
2g. Operational/ETL/Batch Processing Workloads:
Operational workloads here refer to the ingestion or compute jobs that require a guaranteed service level agreement (SLA) to be fulfilled. Any break in these services might impact the company’s business as usual (BAU) operations or strategic business decisions. This requires a careful understanding of the overall compute, storage, data security, and time-sensitivity of these jobs and to ensure sufficient guaranteed capacity and appropriate redundancy to prevent any impact on their SLA.
2h. Distributed Query Processing/Visualization Layer Workloads
A lot of business reporting does not require any modifications to underlying datasets but simply requires the large(/big data) dataset to be processed in memory. There are several Distributed query processing engines for big data (like Trino/Apache Presto, Apache Impala, Apache Drill or even SparkSQL) which can be used to provide SQL interface to reporting or visualization tools like superset, tableau, Qlikview, or custom dashboards built on readily available visualization/charting libraries.
A note on Storage Virtualization:
A lot of organizations want to leverage object (/s3 compatible) storage for cheaper archival of data. However, in terms of the CAP theorem, S3 compromises consistency to ensure the other two. Meanwhile, thinking of public cloud s3 — putting an entire load of churning big data compute directly on to network channel might make the reliability of the system inconsistent. Various tools offer storage virtualization which provides an arbitration layer to mitigate this for the parallel processing compute layer. (e.g., Trino Hive connector for s3 https://trino.io/docs/current/connector/hive-s3.html, with storage caching https://trino.io/docs/current/connector/hive-caching.html )
Since this layer provides a direct interface to end users to perform queries, it is difficult to establish patterns except the utilization is higher during office hours (barring scheduled queries which can be segregated and allocated guaranteed capacity). Capacity requirements are handled through project-level isolation and respective capacity redundancy.
2i. Streaming Workloads Processing Workloads
One of the common requirements for greenfield projects is to ingest the operational and business big data directly into the data warehouse through streaming ingestion. Apache Kafka, Apache Storm, Spark Streaming, and AWS Kinesis are some of the tools often used for this purpose. The Kafka platform comes with its own set of high availability, multi-tenancy and capacity governance capabilities. Depending upon the network and nature of source systems, mostly there is a very little surge in CPU/RAM occupancy of streaming jobs as replication and resilience is efficiently handled by the Streaming engine.
2j. Persistence Layer, Storage Traversal, and Occupancy
The eventual size of a dataset (persisted to storage layer) may depend upon the nature and size of the source system, type of compression, replication requirements, tokenization and encryption, and nature of ingestion/compute job. Thus it becomes essential to traverse the persistence layer to identify the actual size of the dataset and connect it back to the respective compute job, its tenant, and source system.
Thus we have written the storage traversal module to traverse through the datasets, connect their sizes through metadata and multi-tenancy structure and then come up with the trends in the growth of the dataset. Eventually, it should be able to predict the nature and size of growth per dataset and thus allow us to ensure storage layer redundancy according to requirements.
Capacity Governance on YARN (or Future Spark-on-Kubernetes) Scheduler:
Essentially the capacity management for compute workloads in the big data framework utilize the YARN capacity scheduler. Spark community is working on bringing the same features to Spark on Kubernetes. Basically for a particular queue, we have a minimum guaranteed capacity which will be ensured for the queue even if the cluster is on heavy load, other jobs will be pre-empted to provide this to the queue. Max capacity on the other hand is the limit beyond which you may not be allocated the resources even in normal load on the cluster (exceptions can be set up).
The difference between the minimum guaranteed capacity and the max limit is what comes from the common pool (or redundancy quota in our discussion). During peak hours, if the non-critical jobs have a high Max Limit value, those can interfere with the critical jobs which have reasonable min and max set up. e.g., Apache Hadoop 2.4.1 — Hadoop Map Reduce Next Generation-2.4.1 — Capacity Scheduler.
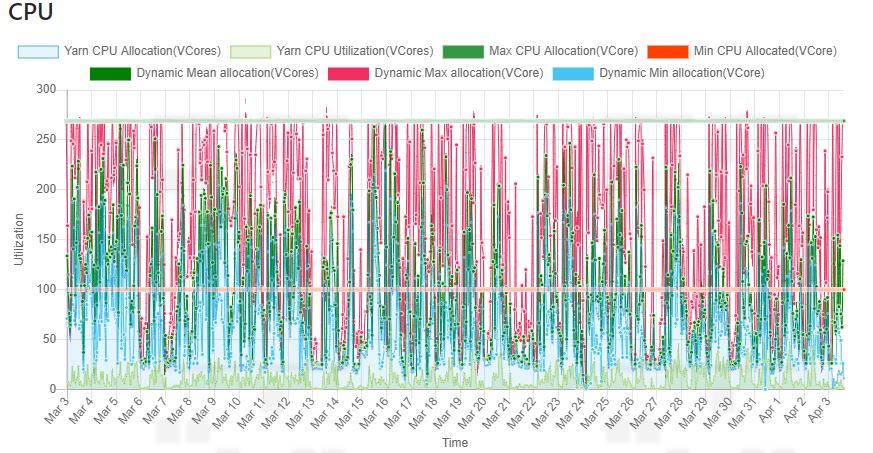
For example, above is one of the YARN queues in an operational cluster. The red line indicates the minimum guaranteed capacity being 100 vCores. While the maximum is clipped at something around 270 vCores. The difference between the minimum guaranteed capacity and the max limit comes from the common pool and the jobs in this zone can be preempted if the yarn is on load. Now, the queue might contain thousands of job runs over the day, how we identified the biggest wasters and approached the optimization is described in the separate article here.
Basically what we want to do is we want to bring the VM Infrastructure cost nearer to the queue allocation. Once the CPU or RAM is allocated to a job, from the YARN point of view it is considered to be occupied/utilized.
This is how our multi-tenancy structure roughly looks at high-level. Discussed in more detail in the other article.
Our goal is to procure nearer to what is utilized/allocated in the queues, with reasonable redundancy to handle a sudden surge in workloads. But while we utilize we also gauge continuously to bring the utilization nearer to allocation. In this process, we avoid both under-allocation (to avoid unpredicted surge onto the cluster), and overallocation (to avoid wastage). In addition, we want to avoid scheduling non-critical jobs during peak hours to avoid impact on time-critical jobs with higher SLA(s). For both capacity and schedule optimizations, we have different strategies.
The SRE Calendar and Compliance Daily, Weekly, Monthly Roster
Every production change request requires our L1 support and Site Reliability Engineering team to be on the toes for the new changes being deployed by our development and DevOps team. SRE team must have a clear understanding of the downtime or service interruption notified to BAU teams, particularly in the production environment.
Compliance heatmap on the other hand provides a consolidated view of critical tech risk deliverables.
SRE calendar provides a place to schedule the Tech Risk action items mentioned above for SRE Teams. It also allows developer teams to book and coordinate BAU downtimes with L1 support and SRE Teams during software releases, upgrades, and patches.
3. The Supply/Infrastructure Stream
The classification is inspired by DevOps for the Modern Enterprise by Mirco Hering. The Infrastructure supply is primarily classified into three streams based on the way DevOps interact with the respective platform. The three infrastructure domains will differ in the way we implement High Availability, Provisioning/Deployment Automations, and Auto-scaling. The mode of implementing infrastructure operations and managing technology risk and compliance are also different. I will quickly discuss the relevant topics as a lot has been explored in infrastructure monitoring and log aggregation in all the three infrastructure platforms beyond this article.
3a. On-Premise Infrastructure
While several organizations want to offload the Infrastructure maintenance to Public Cloud Providers who are eager to do the same job at competitive prices. But as the IT infrastructure available in the market is getting cheaper while energy efficiency is increasing; the snowballing cost of migration, storage, and retrieval of customer data into the public cloud and the risk of breach of the company’s customer data or PII data theft — many organizations are more comfortable building cost-effective capabilities in the virtual private cloud itself.
3b. Containerized(/Cloud Native) Infrastructure
According to this study from Gartner — 98% of world infrastructure will be deployed to containers by 2021. Deploying our applications to containers with the use of container orchestrators like Kubernetes/Openshift offers advanced features for deeper operating system level isolation, efficient configuration management, autoscaling, high availability, maintainability, and self-healing capabilities.
Even the Spark community is working to bring Spark on Kubernetes. Although Dynamic Resource Allocation and Queue Management is still a work in progress, some organizations have managed to use this in production.
3c. Public Cloud (IAAS / PAAS / SAAS)
The public cloud is easy to provision or scale, and equally easy to waste. If we do not use the most appropriate solution for a use case we may easily end up wasting money very fast. For each public cloud, it is preferred to use managed services. For example, although we can set up Argo pipelines for spinning up vanilla Kubernetes clusters, EKS is preferred for much better integration. Likewise, Sagemaker + EMR will be the preferred combination compared to self-baked Jupyterhub and Hadoop + Spark deployment. Regardless, we are leveraging the public cloud for IAAS or PAAS only, or we are re-engineering our business workloads to managed services provided natively by public cloud offerings — it becomes necessary to develop a comprehensive inventory of assets and overlay the consumption data on top of it. The multi-tenancy can also be designed in project-wise isolation mode but still, role-based access federated to the company’s identity provider along with strong data encryption, tokenization, and access control will be the requirement for big data projects.
The Infrastructure Supply Feedback Loop
With increasing compute and ingestion jobs onboarding and growing into the cluster, the feedback from the capacity must be used to ensure capacity redundancy. As well as the occupancy and growth analytics should be bifurcated and communicated to the Business users. This interplay of demand and supply and corresponding analytics were uncovered through various forward and backward feedback jobs depicted in the Demand Sizing Module diagram above.
Conclusion:
While building the capacity governance framework while keeping the site reliability, high availability, and compliance in firm view — we decided to merge our experience of implementing DevOps and site reliability engineering (SRE) principles across the various infrastructure offerings in the virtual private cloud (VPC), containerized and public cloud platforms together with working on Big Data products and use cases. We ensured that there is a strong consideration of the Business user’s point of view, the platform’s multi-tenancy structure and business-as-usual (BAU) service level agreements (SLA)s, data security, and uptime requirements. The Capacity Governance framework built over time now delivers insights, empowers SRE Teams, and is able to save millions of dollars in infrastructure costs through capacity optimizations. I hope this article will provide some useful pointers to the wider community working in a similar problem domain.
Opinions expressed by DZone contributors are their own.
Comments