Chain-of-Thought Prompting: A Comprehensive Analysis of Reasoning Techniques in Large Language Models
Chain-of-thought (CoT) prompting enables LLMs to improve their reasoning capabilities. This paper explores various CoT techniques and their practical limitations.
Join the DZone community and get the full member experience.
Join For FreeChain-of-thought (CoT) prompting has emerged as a transformative technique in artificial intelligence, enabling large language models (LLMs) to break down complex problems into logical, sequential steps. First introduced by Wei et al. in 2022, this approach mirrors human cognitive processes and has demonstrated remarkable improvements in tasks requiring multi-step reasoning[1].
CoT: Explanation and Definition
What Is CoT?
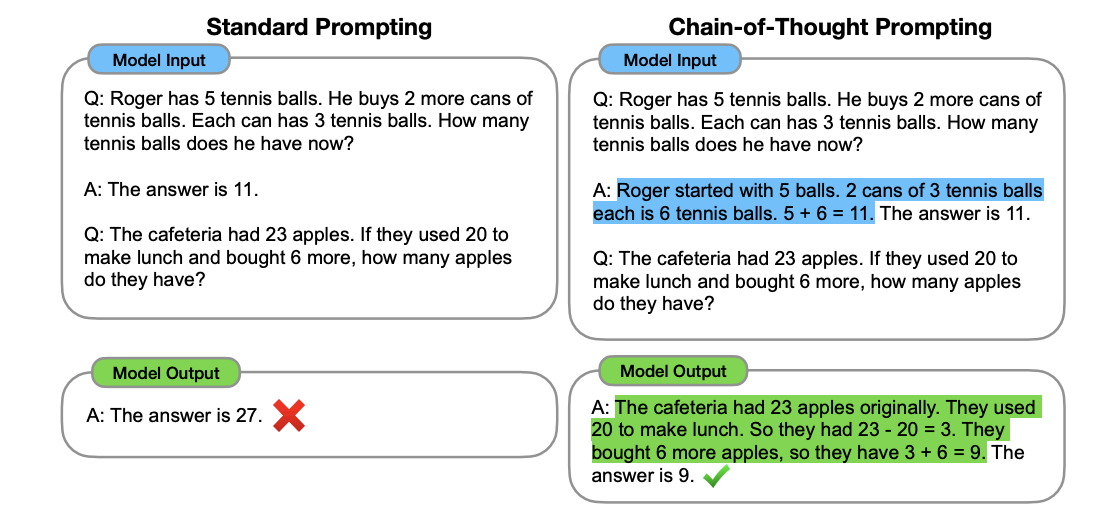
Chain-of-thought prompting is a technique that guides LLMs through structured reasoning processes by breaking down complex tasks into smaller, manageable steps. Unlike traditional prompting, which seeks direct answers, CoT encourages models to articulate intermediate reasoning steps before reaching a conclusion, significantly improving their ability to perform complex reasoning tasks [1].
Types of CoT
Let's break down the different types of chain-of-thought (CoT) approaches in detail:
Zero-Shot CoT
This simplest form of CoT requires no examples and uses basic prompts like "Let's think step by step" or "Let's solve this problem step by step." It relies on the model's inherent ability to break down problems without demonstrations [1].
As demonstrated in Kojima et al.'s seminal work (2022), Large Language Models are inherently capable of zero-shot reasoning when prompted appropriately. Their research, illustrated in Figure 1 of their paper, shows how LLMs can generate coherent reasoning chains simply by including phrases like "Let's solve this step by step" without requiring any demonstrations or examples. This ability emerges naturally in sufficiently large language models, though it's important to note that this capability is primarily observed in models with more than 100B parameters [2].

Figure 2: Kojima et al.'s seminal (2022), Large Language Models are inherently capable of zero-shot reasoning
Key characteristics:
- No examples needed
- Uses simple universal prompts
- Lower performance than other CoT variants
- Works mainly with larger models (>100B parameters)
Few-Shot CoT
Few-shot CoT builds upon zero-shot CoT by incorporating demonstrations with explicit reasoning steps. Unlike zero-shot, which relies solely on simple prompts, few-shot CoT provides carefully crafted examples that guide the model's reasoning process. Wei et al. (2022) demonstrated that providing eight exemplars with chains of thought significantly improves performance across various reasoning tasks [1].
Key to successful few-shot CoT implementation is selecting appropriate exemplars that align with the target reasoning task. The examples should demonstrate the complete thought process, from initial problem understanding to final solution, allowing the model to learn both the reasoning structure and the expected output format [1][2].
Key characteristics:
- Uses 2-8 examples typically
- Each example includes: input question, step-by-step reasoning, final answer
- More reliable than zero-shot
- Requires manual creation of demonstrations
Auto-CoT
Auto-CoT is an automated approach to generating chain-of-thought demonstrations through clustering and pattern recognition, as introduced by Fu et al. (2023). Unlike few-shot CoT which requires manual examples, auto-CoT automatically generates its own reasoning chains.
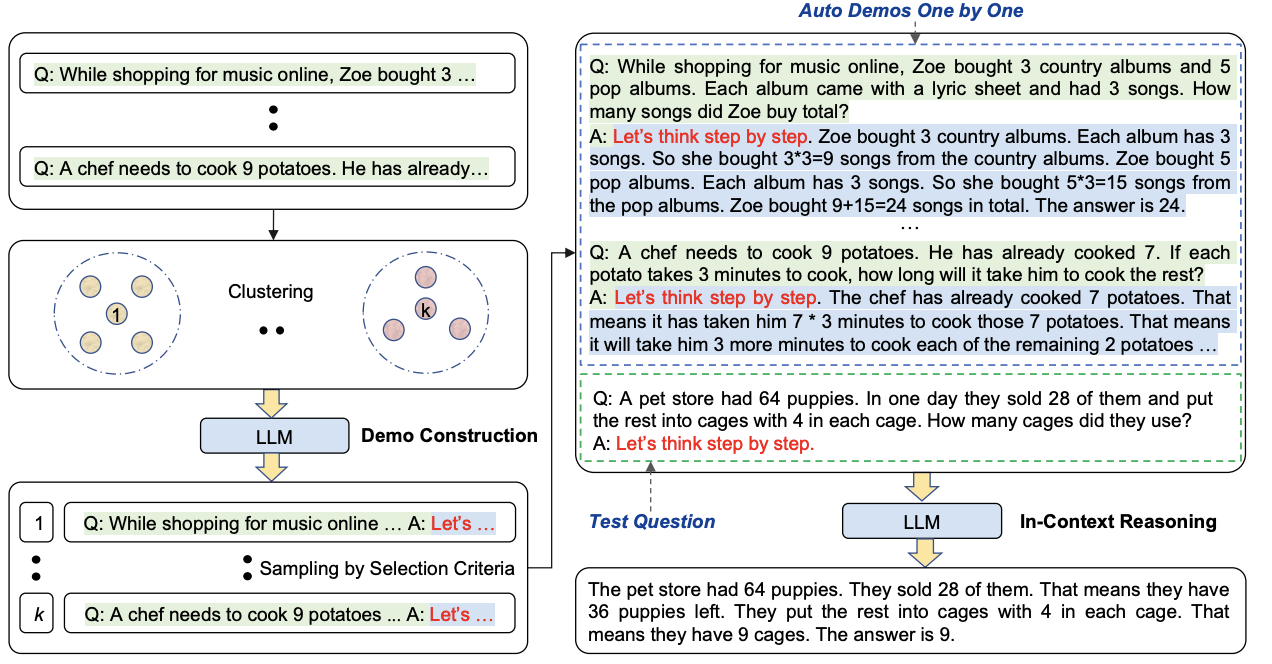
Figure 3: Zhang, Z et al., Automatic Chain of Thought Prompting in Large Language Models
Key characteristics:
- Automatically clusters similar questions from the dataset
- Generates reasoning chains for representative examples from each cluster
- Reduces the need for manual annotation while maintaining effectiveness
- Done during the setup phase, not at inference time
Active-Prompt CoT
Active-prompt CoT represents an advanced approach to chain-of-thought prompting that uses uncertainty estimation to identify challenging questions and strategically selects examples for human annotation. Fu et al. (2023) demonstrated that this method achieves substantial improvements over traditional CoT approaches [5].
Key to successful active-prompt CoT implementation is the strategic selection of examples based on model uncertainty, focusing annotation efforts on the most uncertain cases. This targeted approach reduces the need for exhaustive dataset annotation while maintaining or improving performance compared to standard CoT methods [5].
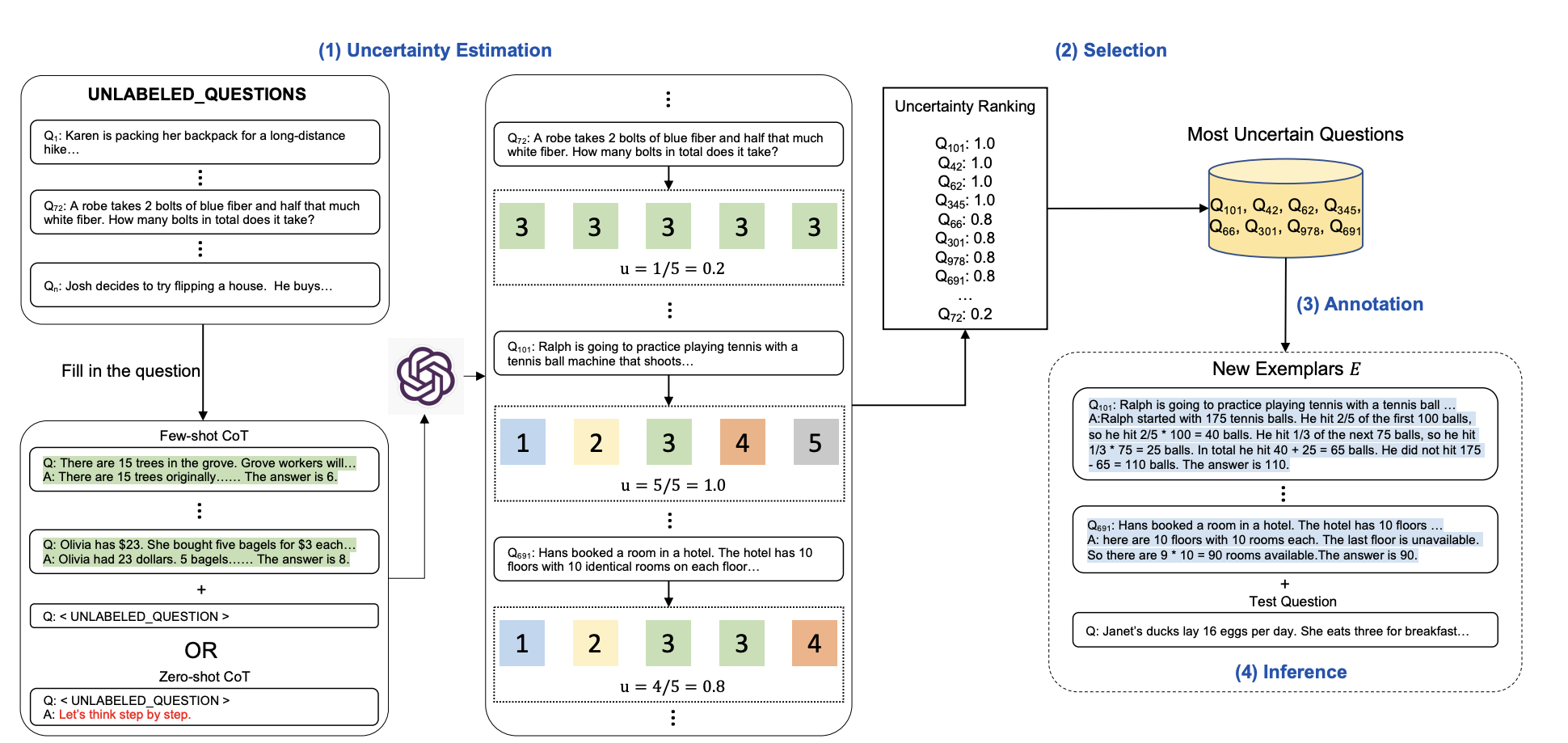
Figure 4: Diao, S et al. (2023). Active Prompting with Chain-of-Thought for Large Language Models
Key characteristics:
- Uses uncertainty estimation to identify challenging questions
- Dynamically adapts to different tasks with task-specific prompts
- Focuses annotation efforts on uncertain cases
- More efficient than manual annotation of entire datasets
- Achieves better performance than standard CoT and Auto-CoT
Self-Consistency CoT
Self-consistency CoT enhances the standard CoT approach by sampling multiple reasoning paths and selecting the most consistent answer. Introduced by Wang et al. (2022), this method significantly improves reasoning performance compared to greedy decoding [6].
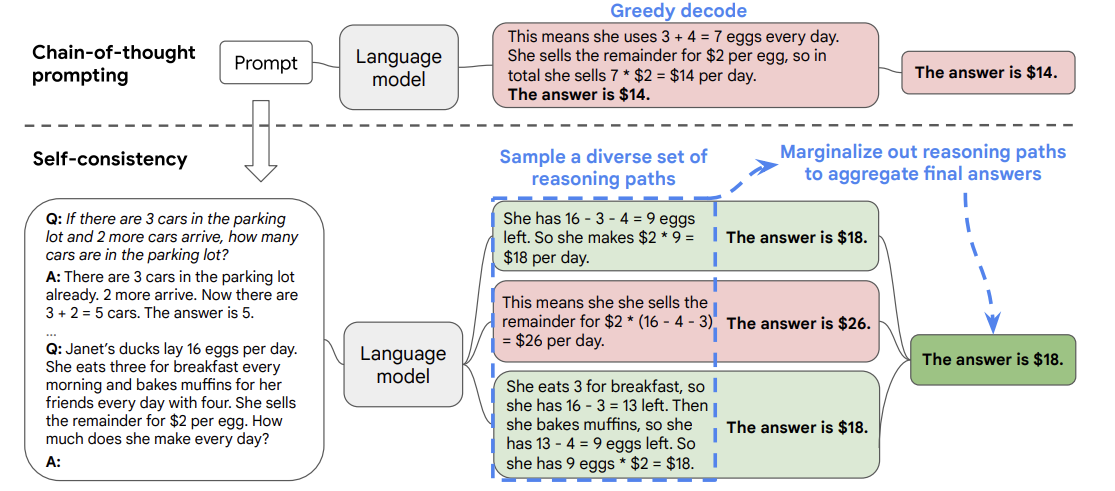
Figure 5: Wang, X. et al. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models
Key characteristics:
- Samples multiple reasoning chains (typically 40-50) instead of using greedy decoding
- Takes majority vote among generated answers
- More robust than single-path reasoning
- Better handles complex problems with multiple possible approaches
Comparison
Here is a comparison table that resumes previously detailed based on some key factors:
| Method |
Complexity |
Human Effort |
Accuracy |
Key Advantage |
Main Limitation |
|---|---|---|---|---|---|
|
Zero-shot CoT |
Low |
None |
Lowest |
Simple implementation |
Limited performance |
|
Few-shot CoT |
Medium |
High |
High |
Reliable results |
Manual example creation |
|
Auto-CoT |
Medium |
Low |
Medium+ |
Automated examples |
Clustering overhead |
|
Active-Prompt |
High |
Medium |
High |
Targeted optimization |
Complex implementation |
|
Self-Consistency |
Highest |
Medium |
Highest |
Most reliable |
Highest computation cost |
When to Use It
Chain-of-thought (CoT) prompting is particularly effective for complex tasks requiring multi-step reasoning. Understanding when to apply CoT is crucial for optimal results.
Benefits
CoT prompting offers several key advantages when implemented correctly [1].
First, it significantly enhances accuracy in complex problem-solving tasks requiring multiple steps, showing improvements of up to +18% on arithmetic tasks. This improvement is particularly notable in mathematical reasoning and symbolic manipulation tasks where step-by-step problem decomposition is essential [1][7].
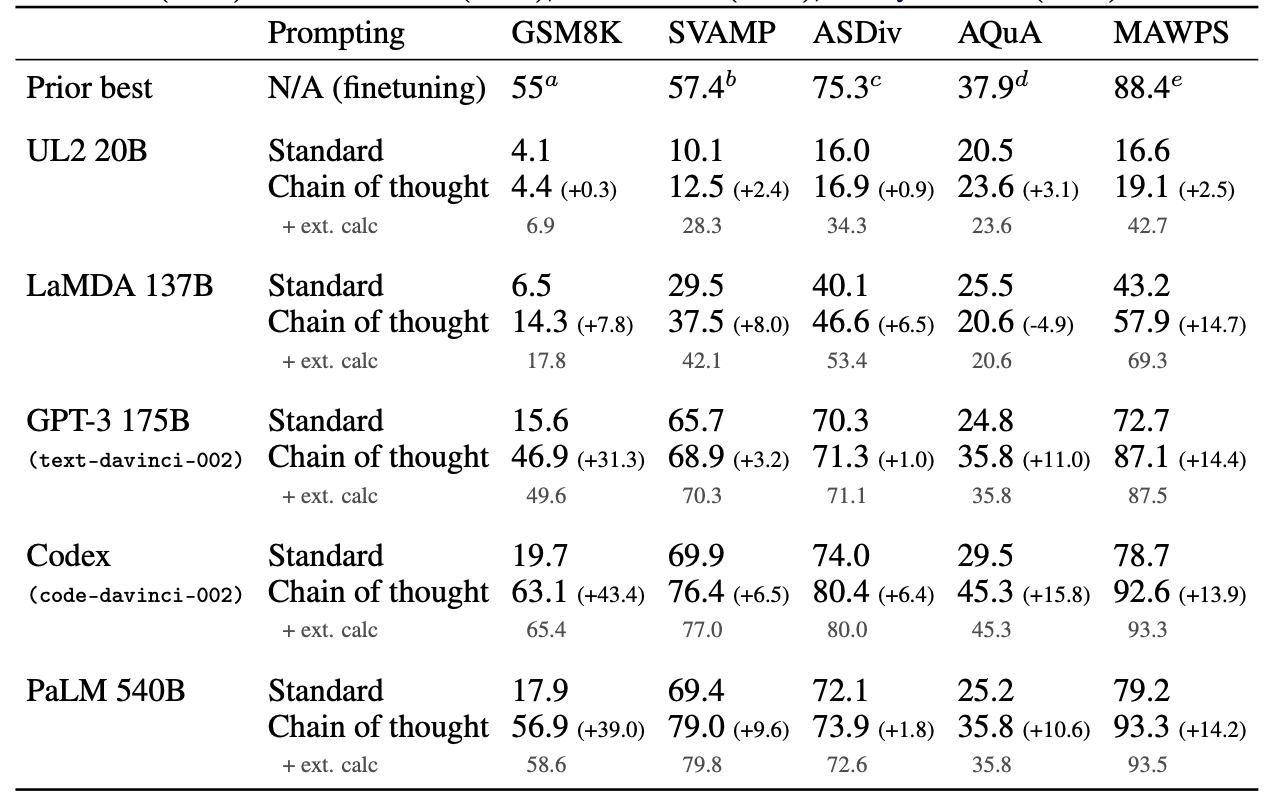
Figure 6: Wei et al. (2022) "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"
Second, CoT provides unprecedented transparency into the model's reasoning process. By making intermediate steps explicit and verifiable, it enables a better understanding of how the model arrives at its conclusions [2]. This transparency is crucial for both validation and debugging of model outputs [1][6][7].
Third, CoT excels at handling complex tasks requiring sequential reasoning. It shows particular effectiveness in mathematical word problems, temporal reasoning, and multi-step logical deductions12. The ability to break down complex problems into manageable steps makes it especially valuable for tasks that would be difficult to solve in a single step [1][3][7].
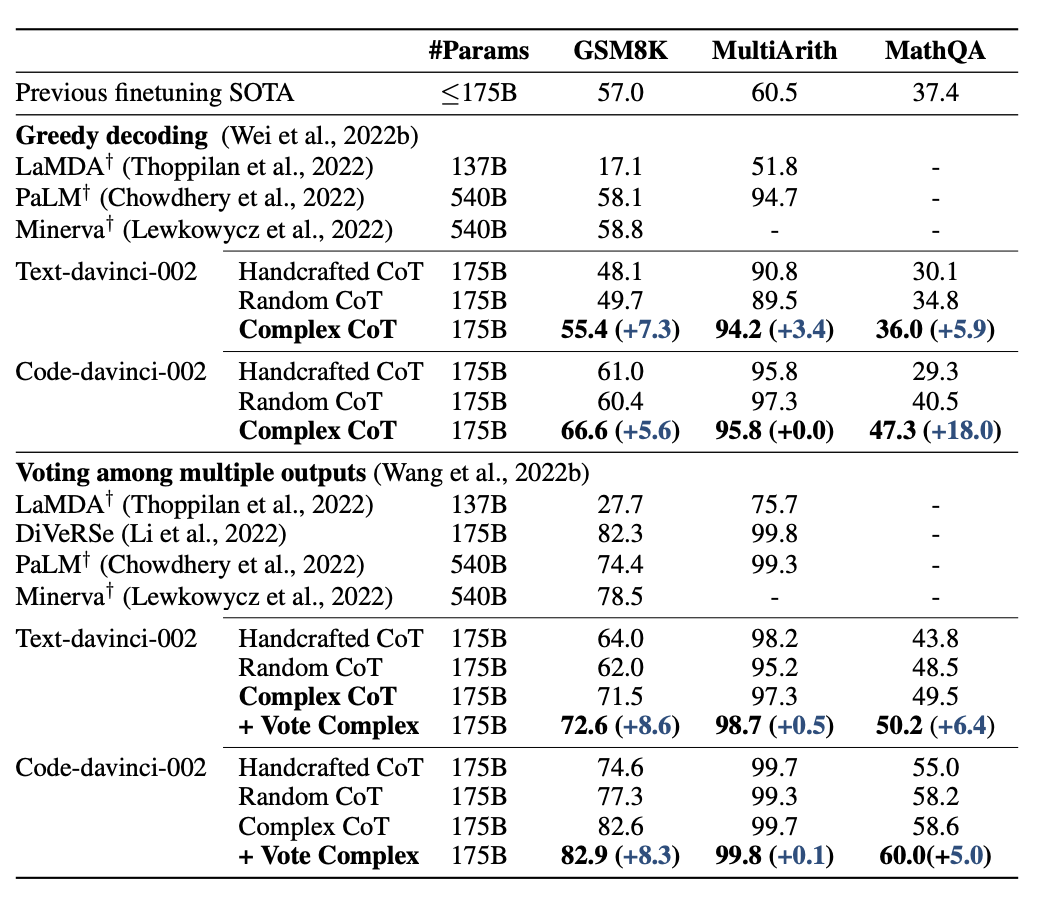
Trade-Offs
While chain-of-thought (CoT) prompting demonstrates impressive capabilities, it comes with several significant considerations that must be carefully weighed.
First, computational costs represent a major trade-off. Generating detailed reasoning chains demands substantially more computational resources and processing time compared to direct prompting, as models need to generate longer sequences that include intermediate reasoning steps, directly impacting operational costs when using commercial API services.
Second, implementation requirements pose considerable challenges. CoT demands careful prompt engineering and typically requires larger models exceeding 100B parameters for optimal performance. Ma et al. (2023) demonstrated that while smaller models can be enhanced through knowledge distillation, they still struggle to match the reasoning capabilities of larger models in complex tasks.
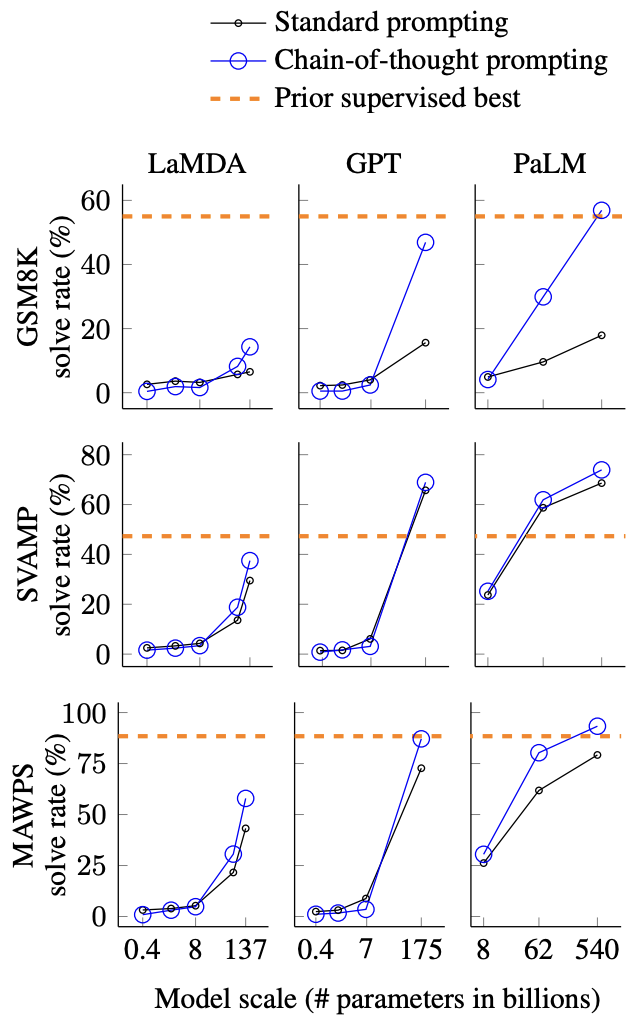
Figure 8: Wei et al. (2022) "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"
Third, reliability concerns have emerged in recent research. Wang et al. (2022) found that CoT can sometimes produce convincing but incorrect reasoning chains, particularly in domains requiring specialized knowledge. This "false confidence" problem becomes especially critical in applications where reasoning verification is essential.
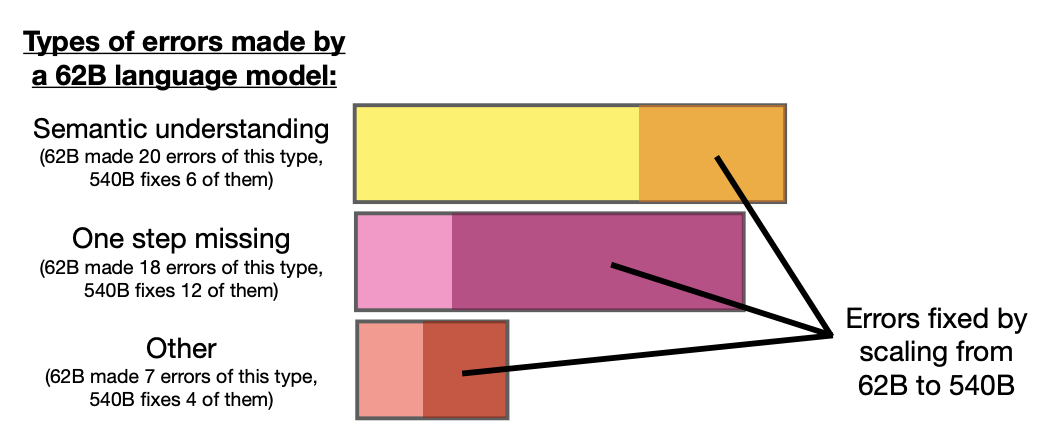
Figure 9: Wei et al. (2022) "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"
Fourth, domain adaptation remains challenging. Recent work by Fu et al. (2023) highlights that CoT performance varies significantly across different domains and task types. The effectiveness of CoT prompting depends heavily on the alignment between the task domain and the model's training data, making consistent cross-domain application difficult.
Conclusion
Chain-of-thought (CoT) prompting represents a significant advancement in enhancing Large Language Models' reasoning capabilities. Through its various implementations — from simple zero-shot approaches to sophisticated methods like active-prompt and self-consistency — CoT has demonstrated remarkable improvements in complex problem-solving tasks, particularly in areas requiring multi-step reasoning.
The evolution of CoT techniques reflects the field's rapid progress. While zero-shot and few-shot CoT provided initial breakthroughs in reasoning capabilities, newer approaches like auto-CoT and active-prompt CoT have addressed scalability and efficiency challenges. Self-consistency CoT further enhanced reliability by leveraging multiple reasoning paths, marking a significant step toward more robust AI reasoning systems.
However, important challenges remain. The requirement for large models (>100B parameters) limits accessibility, while computational costs and prompt engineering complexity pose implementation challenges. These limitations suggest future research directions, including:
- Developing more efficient CoT techniques for smaller models
- Reducing computational overhead while maintaining performance
- Improving prompt engineering automation
- Enhancing reliability for critical applications
As AI continues to evolve, CoT prompting stands as a crucial technique for enabling transparent and verifiable reasoning in language models. Its ability to break down complex problems into interpretable steps not only improves performance but also provides valuable insights into AI decision-making processes, making it an essential tool for the future of artificial intelligence.
References
[1] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903.
[2] Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022). Large Language Models are Zero-Shot Reasoners. arXiv preprint arXiv:2205.11916.
[3] Fu, Y., Peng, H., Sabharwal, A., Clark, P., & Khot, T. (2023). Complexity-Based Prompting for Multi-step Reasoning. arXiv preprint arXiv:2210.00720.
[4] Zhang, Z., Zhang, A., Li, M., & Smola, A. (2022). Automatic Chain of Thought Prompting in Large Language Models. arXiv:2210.03493
[5] Diao, S., Wang, P., Lin, Y., Pan, R., Liu, X., & Zhang, T. (2023). Active Prompting with Chain-of-Thought for Large Language Models.
[6] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E. H., Narang, S., Chowdhery, A., & Zhou, D. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171.
[7] Hao, H., Zhang, K., & Xiong, M. (2023). Dynamic Models of Neural Population Dynamics. Society of Artificial Intelligence Research and University of Texas, School of Public Health.
[8] Chu, Z., Chen, J., Chen, Q., Yu, W., He, T., Wang, H., Peng, W., Liu, M., Qin, B., & Liu, T. (2023). Navigate through Enigmatic Labyrinth: A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future. arXiv preprint arXiv:2309.15402.
[9] Ma, Y., Jiang, H., & Fan, C. (2023). Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA. arXiv preprint arXiv:2308.04679.
Opinions expressed by DZone contributors are their own.
Comments