Change Data Capture With Debezium: A Simple How-To, Part 1
This is a simple how-to on how to build out a change data capture solution using Debezium within an OpenShift environment.
Join the DZone community and get the full member experience.
Join For FreeOne question always comes up as organizations moving towards being cloud-native, twelve-factor, and stateless: How do you get an organization’s data to these new applications? There are many different patterns out there, but one pattern we will look at today is change data capture. This post is a simple how-to on how to build out a change data capture solution using Debezium within an OpenShift environment. Future posts will also add to this and add additional capabilities.
What Is Change Data Capture?
Another Red Hatter, Sadhana Nandakumar, sums it up well in one of her posts around change data capture:
"Change data capture (CDC) is a pattern that enables database changes to be monitored and propagated to downstream systems. It is an effective way of enabling reliable microservices integration and solving typical challenges, such as gradually extracting microservices from existing monoliths."
This pattern lets data become distributed amongst teams, where each team can self-manage their own data while still keeping up-to-date with the original source of data. There are also other patterns, such as Command Query Responsibility Segregation (CQRS), which build on this idea.
What Is Debezium?
Debezium is an open source technology, supported by Red Hat as part of Red Hat Integration, which allows database row-level changes to be captured as events and published to Apache Kafka topics. Debezium connectors are based on the popular Apache Kafka Connect API and can be deployed within Red Hat AMQ Streams Kafka clusters.
Application Overview
The application we will use as our "monolith" is a Spring Boot application that uses a MySQL database as its back end. The application itself has adopted the Event Sourcing and Outbox patterns. This means that the application maintains a separate table within the database consisting of domain events. It is this table that we need to monitor for changes to publish into our Kafka topics. In this example, there is a table called outbox_events that looks like this:
xxxxxxxxxx
+-----------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+---------+----------------+
| event_id | bigint(20) | NO | PRI | NULL | auto_increment |
| aggregate_id | varchar(255) | NO | | NULL | |
| aggregate_type | varchar(255) | NO | | NULL | |
| event_timestamp | datetime(6) | NO | | NULL | |
| event_type | varchar(255) | NO | | NULL | |
| payload | json | YES | | NULL | |
+-----------------+--------------+------+-----+---------+----------------+
Setting up the Database
The Debezium documentation has a section on how to set up the Debezium connector to work with a MySQL database. We need to follow that documentation but in a container-native way since we will run everything on Red Hat OpenShift. There are many different ways to accomplish this task, but I will describe the way I decided to do it.
Create an OpenShift Project
The first thing we need to do is log into our OpenShift cluster. In my example, I use OpenShift 4.3. The database setup does not require cluster admin privileges, so any normal user will work fine:
$ oc login <CLUSTER_API_URL>
Next, let’s create a project to host our work:
xxxxxxxxxx
$ oc new-project debezium-demo
Create the MySQL Configuration
From , the first thing we need to do is enable the binlog, GTIDs, and query log events. This is typically done in the MySQL configuration file, usually located in /etc/my.cnf. In our case, we will use Red Hat’s MySQL 8.0 container image. This image is already deployed in most OpenShift installations in the openshift namespace under the mysql:8.0 tag. The source of this image comes from registry.redhat.io/rhscl/mysql-80-rhel7:latest.
According to the container image documentation, the default configuration file is at /etc/my.cnf, but there is an environment variable, MYSQL_DEFAULTS_FILE, that can be used to override its location. MySQL configuration also lets one configuration file include other configuration files, so we will create a new configuration file that first includes the default configuration and then overrides some of that configuration to enable the required Debezium configuration.
We’ll do this by first creating a configuration file containing our configuration. We’ll call this file my-debezium.cnf:
xxxxxxxxxx
!include /etc/my.cnf
[mysqld]
server-id = 223344
server_id = 223344
log_bin = ON
binlog_format = ROW
binlog_row_image = full
binlog_rows_query_log_events = ON
expire_logs_days = 10
gtid_mode = ON
enforce_gtid_consistency = ON
Now that our MySQL configuration file is created, let's create it as a ConfigMap within our OpenShift project:
xxxxxxxxxx
$ oc create configmap db-config --from-file=my-debezium.cnf
Create a MySQL User
The next part of the Debezium MySQL configuration is to create a MySQL user for the connector. We will follow the same pattern that we did for the configuration by creating a file containing the needed SQL. This initdb.sql file will create a user with the ID debezium and password debezium:
xxxxxxxxxx
CREATE USER IF NOT EXISTS 'debezium''%' IDENTIFIED WITH mysql_native_password BY 'debezium';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium''%';
FLUSH PRIVILEGES;
Note: In a real production environment, we want to choose usernames and passwords more carefully, as well as only allowing the debezium user access to the tables it will monitor.
Now create a ConfigMap within our OpenShift project:
xxxxxxxxxx
$ oc create configmap db-init --from-file=initdb.sql
The last piece of the configuration is to create an OpenShift Secret to hold onto our database credentials. This Secret will be used by our database as well as the application that connects to the database. For simplicity, we will use music as our database name, username, password, and admin password:
xxxxxxxxxx
$ oc create secret generic db-creds --from-literal=database-name=music --from-literal=database-password=music --from-literal=database-user=music --from-literal=database-admin-password=music
Note (again): In a real production environment, we want to choose usernames and passwords more carefully.
Deploy MySQL
The last part is to create the database and point it to our two configurations. OpenShift allows us to take the ConfigMaps we created and mount them as files within the container filesystem. We can then use environment variables to change the behavior of the MySQL container image. Let’s create a descriptor YAML file, mysql.yml, for our database DeploymentConfig and Service:
xxxxxxxxxx
kind: DeploymentConfig
apiVersion: apps.openshift.io/v1
metadata:
name: spring-music-db
labels:
application: spring-music
app: spring-music
app.kubernetes.io/part-of: spring-music
app.openshift.io/runtime: mysql-database
spec:
replicas: 1
strategy:
type: Recreate
recreateParams:
post:
failurePolicy: Abort
execNewPod:
command:
- /bin/sh
- '-c'
- sleep 10 && MYSQL_PWD="$MYSQL_ROOT_PASSWORD" $MYSQL_PREFIX/bin/mysql -h $SPRING_MUSIC_DB_SERVICE_HOST -u root < /config/initdb.d/initdb.sql
containerName: spring-music-db
volumes:
- db-init
selector:
name: spring-music-db
template:
metadata:
name: spring-music-db
labels:
name: spring-music-db
spec:
volumes:
- name: db-data
emptyDir: {}
- name: db-init
configMap:
name: db-init
- name: db-config
configMap:
name: db-config
containers:
- env:
- name: MYSQL_DEFAULTS_FILE
value: /config/configdb.d/my-debezium.cnf
- name: MYSQL_USER
valueFrom:
secretKeyRef:
name: db-creds
key: database-user
- name: MYSQL_PASSWORD
valueFrom:
secretKeyRef:
name: db-creds
key: database-password
- name: MYSQL_DATABASE
valueFrom:
secretKeyRef:
name: db-creds
key: database-name
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: db-creds
key: database-admin-password
name: spring-music-db
image: ' '
imagePullPolicy: IfNotPresent
volumeMounts:
- name: db-data
mountPath: /var/lib/mysql/data
- name: db-init
mountPath: /config/initdb.d
- name: db-config
mountPath: /config/configdb.d
ports:
- containerPort: 3306
protocol: TCP
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 3306
timeoutSeconds: 1
readinessProbe:
exec:
command:
- /bin/sh
- -i
- -c
- MYSQL_PWD="$MYSQL_PASSWORD" mysql -h 127.0.0.1 -u $MYSQL_USER -D $MYSQL_DATABASE -e 'SELECT 1'
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
memory: 512Mi
securityContext:
privileged: false
triggers:
- type: ConfigChange
- type: ImageChange
imageChangeParams:
automatic: true
containerNames:
- spring-music-db
from:
kind: ImageStreamTag
name: mysql:8.0
namespace: openshift
---
kind: Service
apiVersion: v1
metadata:
name: spring-music-db
labels:
application: spring-music
app: spring-music
annotations:
template.openshift.io/expose-uri: mysql://{.spec.clusterIP}:{.spec.ports[?(.name=="mysql")].port}
spec:
ports:
- name: mysql
port: 3306
protocol: TCP
targetPort: 3306
selector:
name: spring-music-db
From this DeploymentConfig, you can see that we mount our db-init and db-config ConfigMaps as volumes on the container filesystem inside the /config directory on lines 72-75:
xxxxxxxxxx
volumeMounts:
- name: db-data
mountPath: /var/lib/mysql/data
- name: db-init
mountPath: /config/initdb.d
- name: db-config
mountPath: /config/configdb.d
The /config/configdb.d/my-debezium.cnf file is also set as the value for the MYSQL_DEFAULTS_FILE environment variable on lines 44-45:
xxxxxxxxxx
- env:
- name: MYSQL_DEFAULTS_FILE
value: /config/configdb.d/my-debezium.cnf
The database initialization script from the db-init ConfigMap is executed as a post lifecycle hook on lines 15-24:
xxxxxxxxxx
post:
failurePolicy: Abort
execNewPod:
command:
- /bin/sh
- '-c'
- sleep 10 && MYSQL_PWD="$MYSQL_ROOT_PASSWORD" $MYSQL_PREFIX/bin/mysql -h $SPRING_MUSIC_DB_SERVICE_HOST -u root < /config/initdb.d/initdb.sql
containerName: spring-music-db
volumes:
- db-init
Our MySQL instance here is ephemeral, so whenever a new container instance is created the script will execute in a sidecar container within the pod.
Now create the resources and wait for the database pod to start:
xxxxxxxxxx
$ oc create -f mysql.yml
Starting the Application
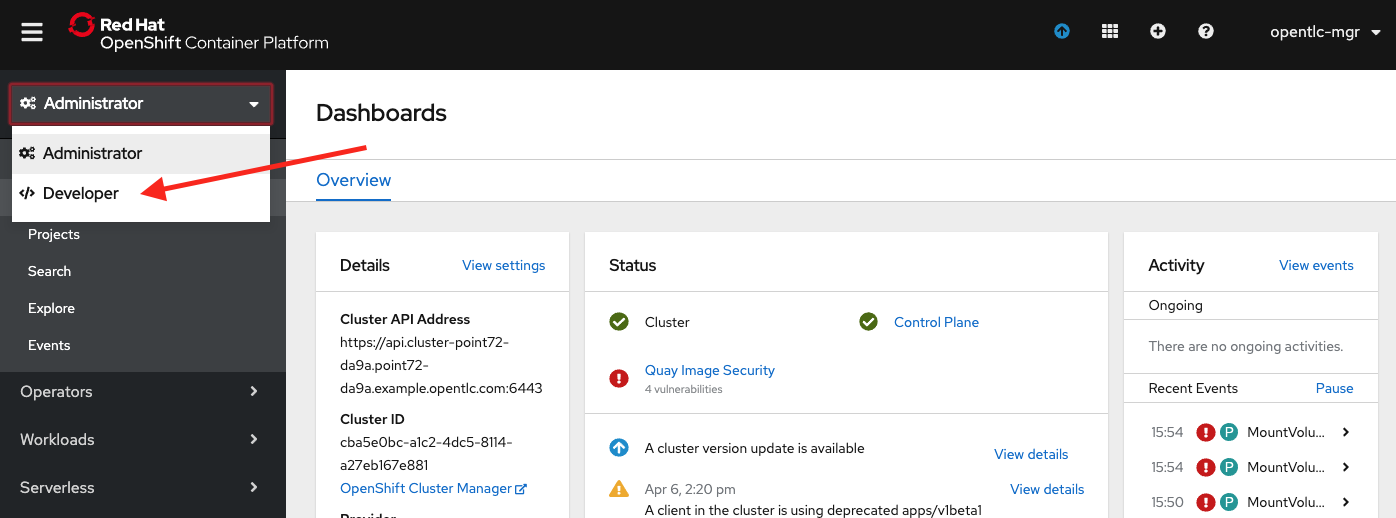
Now that our database is up and running we can start the application. Let's go to the OpenShift web console and then to the Developer perspective's Topology view, as shown in Figure 1.
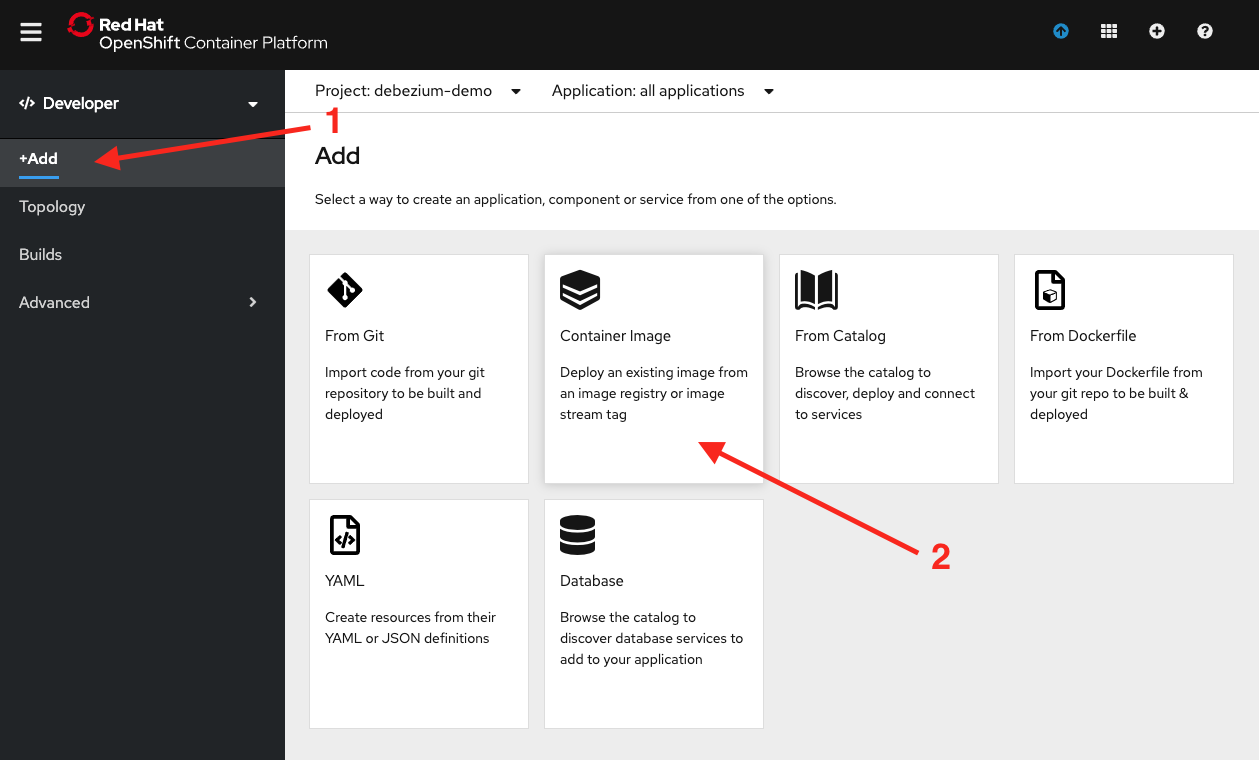
Then click the +Add button, followed by the Container Image tile, as shown in Figure 2.
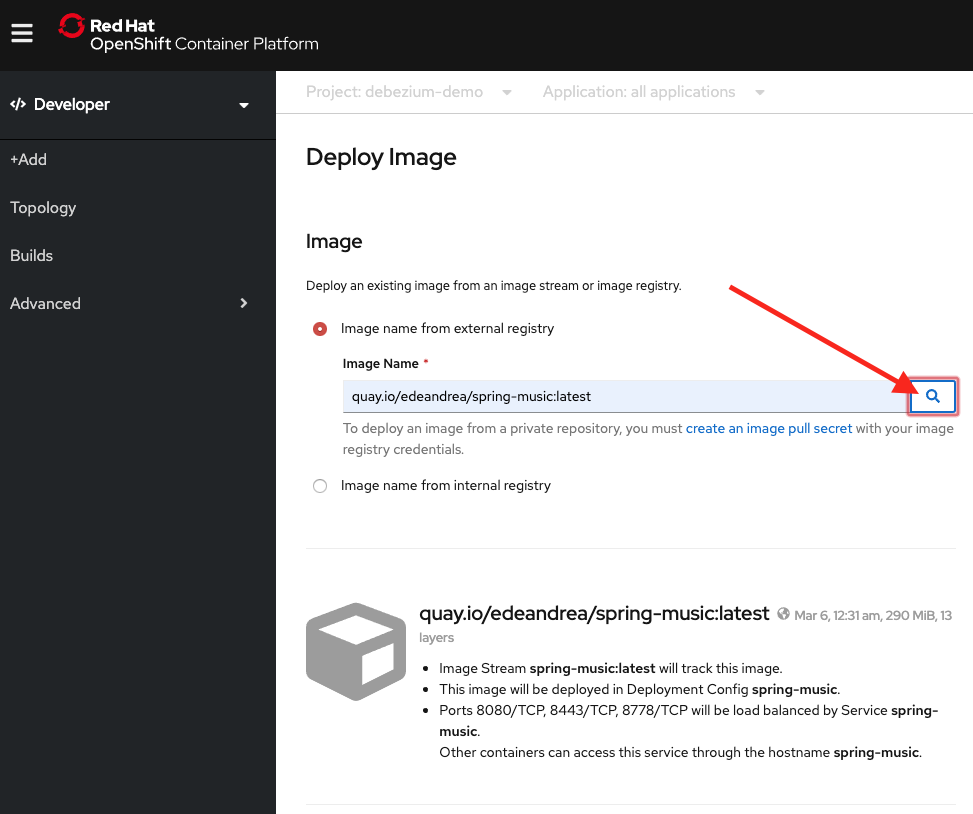
Fill in the image name with quay.io/edeandrea/spring-music:latest and then click the search button, as shown in Figure 3.
Then fill out the rest of the information from Figures 4 and 5 below, making sure to add the correct labels and environment variables by clicking the links at the bottom with the sentence "Click on the names to access advanced options for Routing, Deployment, Scaling, Resource Limits, and Labels."
The fields and values should be filled out as follows:
- Application: spring-music
- Name: spring-music
- Deployment Config: selected
- Create a route to the application: checked
- Labels
- app.openshift.io/runtime=spring
- Deployment
- Auto deploy when new image is available: checked
- Auto deploy when deployment configuration changes: checked
- Environment Variables
- Add from Config Map or Secret
- NAME: SPRING_DATASOURCE_USERNAME
- VALUE: From Secret db-creds field database-user
- Add from Config Map or Secret
- NAME: SPRING_DATASOURCE_PASSWORD
- VALUE: from Secret db-creds field database-password
- Add Value
- NAME: SPRING_DATASOURCE_URL
- VALUE: jdbc:mysql://spring-music-db/music
- Add from Config Map or Secret

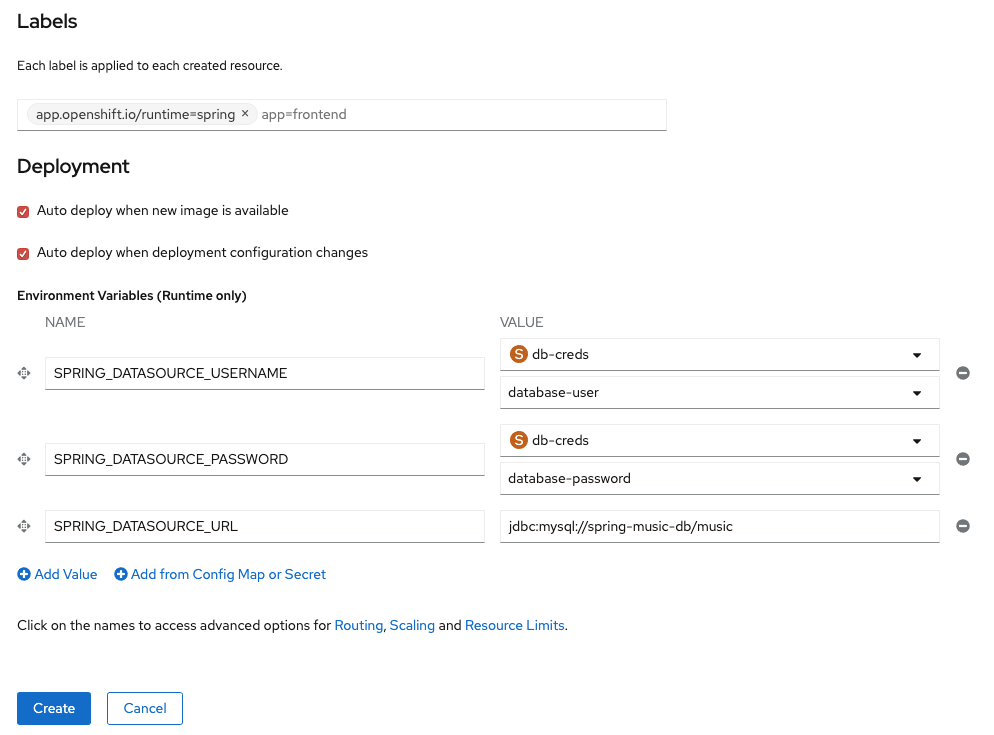
Once done, click the Create button.
Back in the Topology view, you should see the application spin up. Once it is surrounded by the blue ring, click the route button on the top-right corner of the application icon, as shown in Figure 6.

This will launch the application. Feel free to play around with it if you'd like. Try deleting an album.
Deploy AMQ Streams
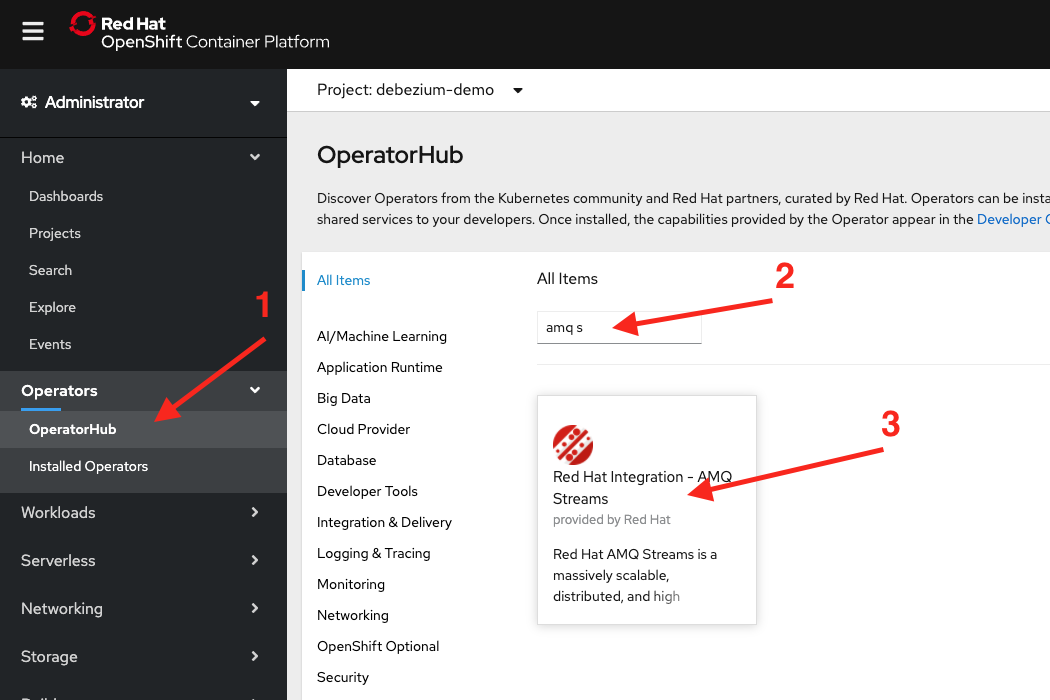
Now that our database and application are up and running let’s deploy our AMQ Streams cluster. First, we need to install the AMQ Streams Operator into the cluster from the OperatorHub. To do this you need cluster admin privileges for your OpenShift cluster. Log in to the web console as a cluster admin, then on the left expand OperatorHub, search for AMQ Streams, and select Red Hat Integration - AMQ Streams, as shown in Figure 7.
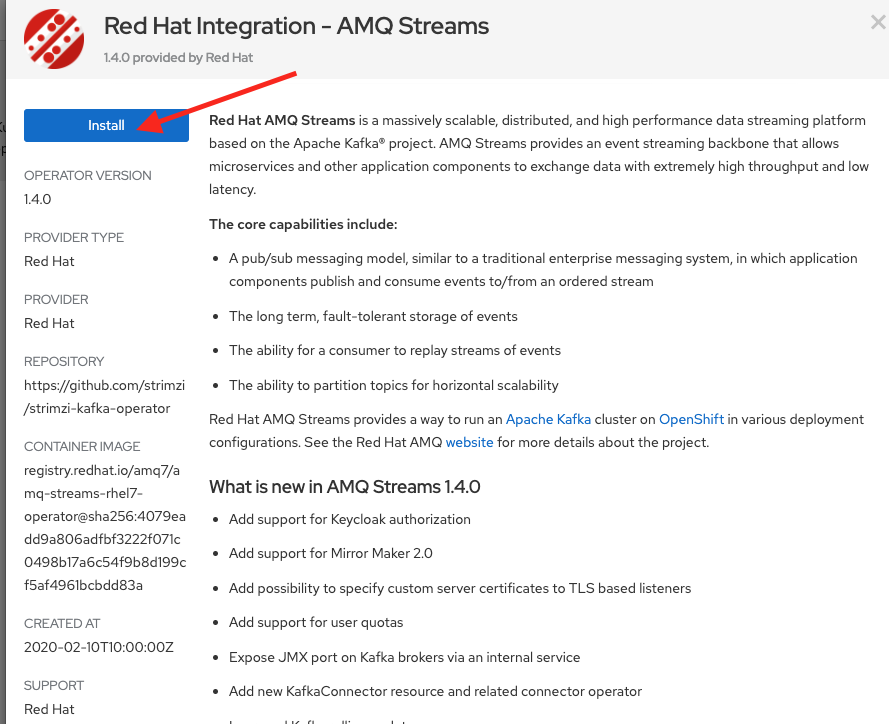
On the installation screen, click the Install button, as shown in Figure 8.
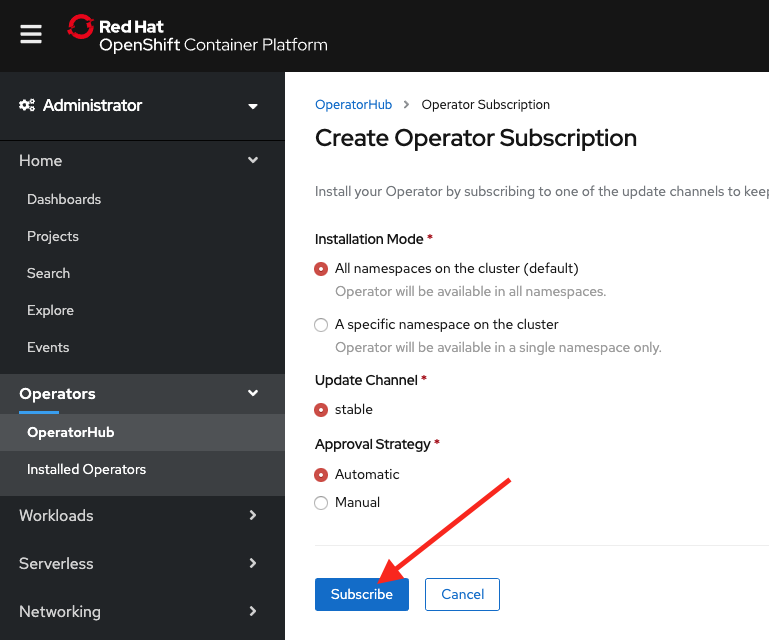
On the Create Operator Subscription page, leave the defaults and click Subscribe, as shown in Figure 9. This action will install the Operator for all of the projects in the cluster.
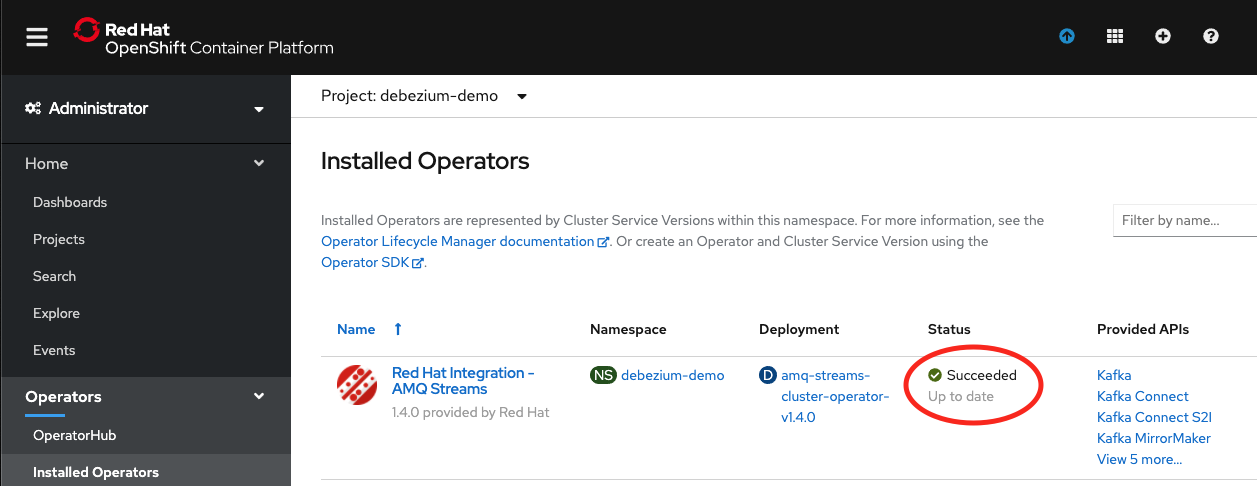
You'll then be brought to the Installed Operators screen. Sit tight and wait for the Red Hat Integration - AMQ Streams Operator to show up with Succeeded status, as shown in Figure 10. It shouldn't take more than a minute or two.
Now let's create our Kafka cluster. Click on the Red Hat Integration - AMQ Streams label to get to the main AMQ Streams Operator page. Then under Provided APIs, click the Create Instance label in the Kafka section, as shown in Figure 11.
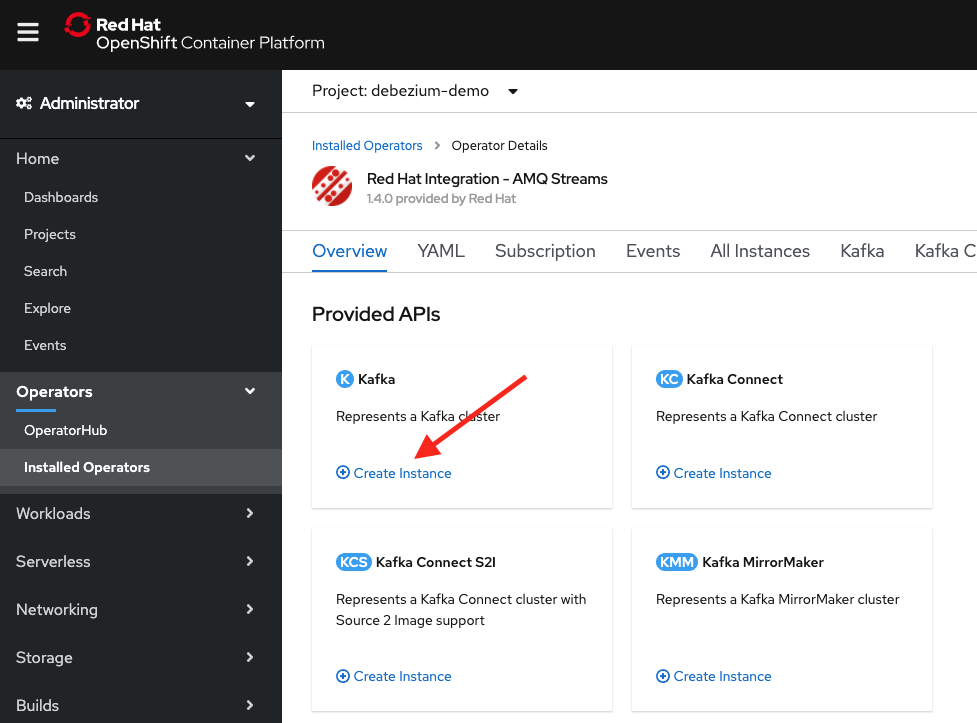
The Create Kafka YAML editor will then come up. Remove everything that's there, paste in the following, and click the Create button at the bottom of the screen:
xxxxxxxxxx
kind: Kafka
apiVersion: kafka.strimzi.io/v1beta1
metadata:
name: db-events
namespace: debezium-demo
labels:
app: spring-music-cdc
template: spring-music-cdc
app.kubernetes.io/part-of: spring-music-cdc
spec:
kafka:
replicas: 3
listeners:
plain: {}
jvmOptions:
gcLoggingEnabled: false
config:
auto.create.topics.enable: "true"
num.partitions: 1
offsets.topic.replication.factor: 3
default.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
storage:
type: persistent-claim
size: 100Gi
deleteClaim: true
template:
statefulset:
metadata:
labels:
app.kubernetes.io/part-of: spring-music-cdc
app: spring-music-cdc
template: spring-music-cdc
annotations:
app.openshift.io/connects-to: db-events-zookeeper
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
deleteClaim: true
template:
statefulset:
metadata:
labels:
app.kubernetes.io/part-of: spring-music-cdc
app: spring-music-cdc
template: spring-music-cdc
entityOperator:
topicOperator: {}
userOperator: {}
This action will deploy a three-node Kafka cluster along with a three-node Zookeeper cluster. It will also turn down the JVM's garbage collection logging so that if we need to look at the logs in any of the Kafka broker pods they won’t be polluted with tons of garbage collection debug logs. Both the Kafka and Zookeeper brokers are backed by persistent storage, so the data will survive a broker and cluster restart.
Wait a few minutes for OpenShift to spin everything up. You can switch to the OpenShift Developer perspective’s Topology view by clicking what is shown in Figure 12.
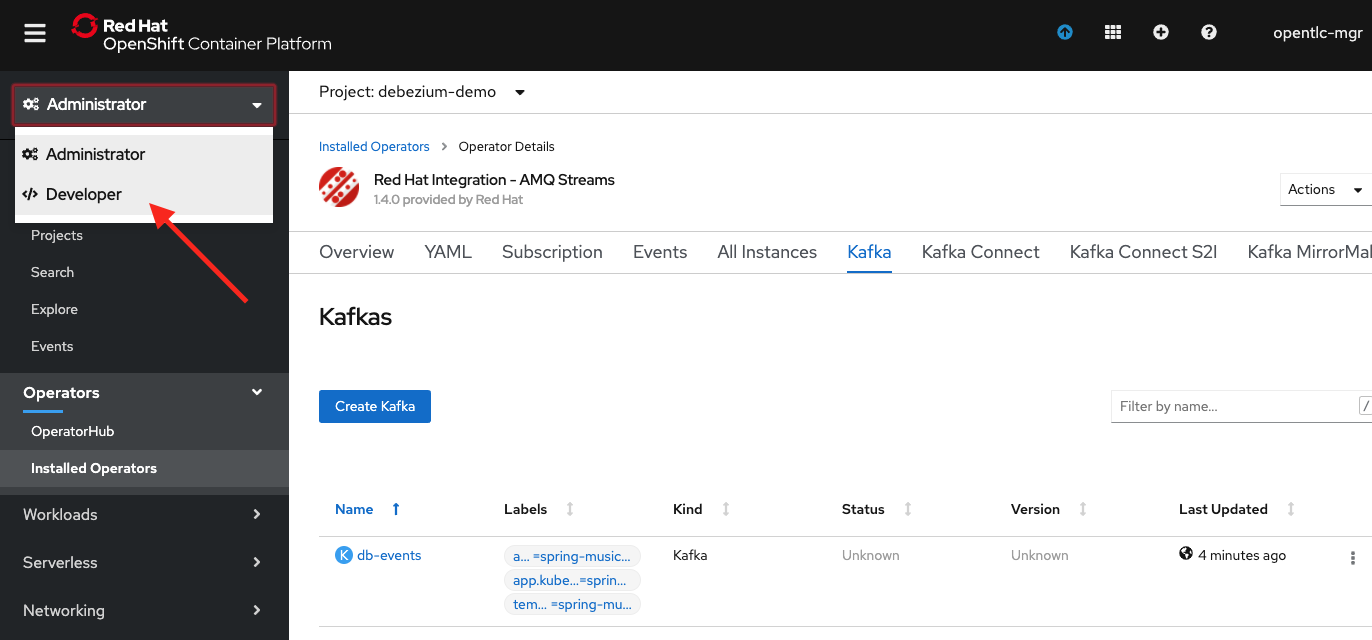
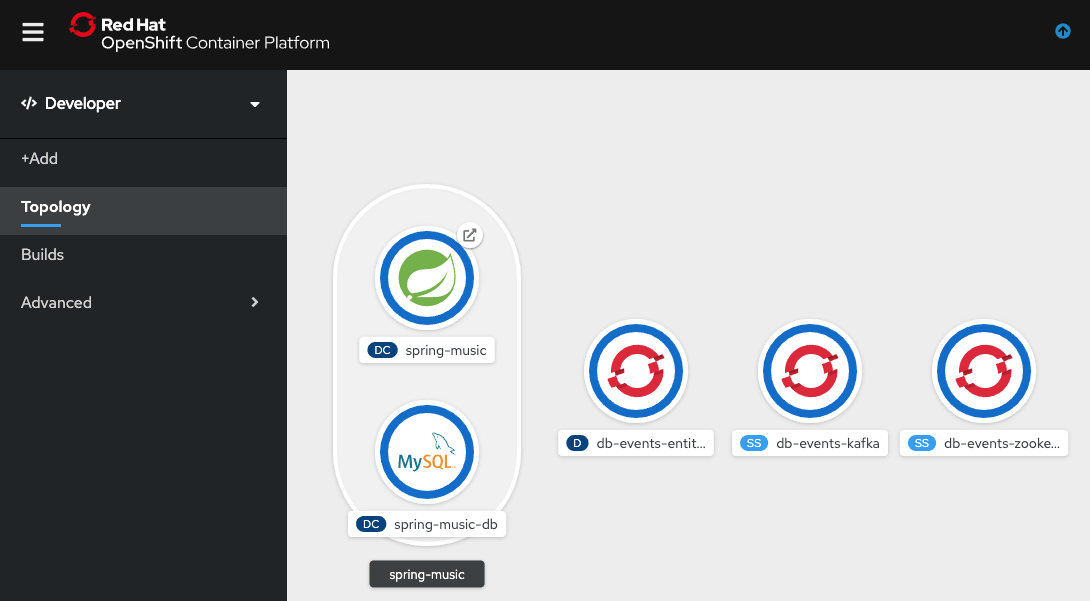
Once the db-events-entity-operator, db-events-kafka, and db-events-zookeeper items all show up with a blue ring around them, as shown in Figure 13, you are done.
Deploy Kafka Connect
Debezium runs inside a Kafka Connect cluster, so that means we need a container image with both Kafka Connect and the Debezium libraries together. The easiest way to do this is to create your own container image from the Kafka Connect base image. What follows are the steps needed to do this. I also already created an image you can use, so feel free to skip this sub-section if you would like and use the image at quay.io/edeandrea/kafka-connect-debezium-mysql:amq-streams-1.4.0-dbz-1.1.0.Final instead.
Building Your Own Kafka Connect Image
To build your own Kafka Connect image:
- Create a directory on your local computer (i.e.,
debezium-connect-image) and thencdinto that directory. - Create a directory inside called
plugins. - Download the Debezium MySQL connector from the Debezium Releases page.
Note: This post was written using the 1.1.0.Final version of the MySQL connector, but whatever the latest version listed should do fine.
- Unpackage the downloaded file into the
pluginsdirectory. - Create a
Dockerfileat the root (i.e.,debezium-connect-image) directory with the following contents (you'll need an account onregistry.redhat.ioand to log into the registry on your machine in order to pull the AMQ Streams image):Java
xxxxxxxxxx1
1FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.02USER root:root3COPY ./plugins/ /opt/kafka/plugins4USER jboss:jboss
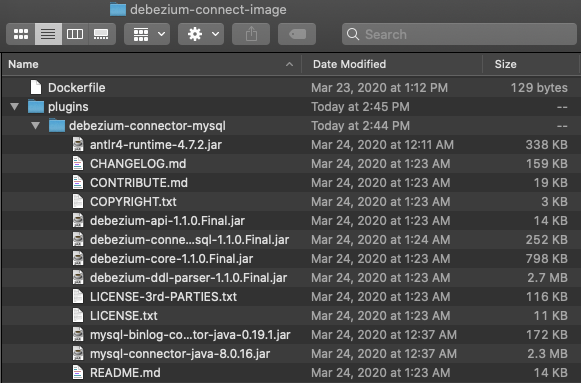
- Your directory tree should now look like what's shown in Figure 14.
![Contents of Kafka Connect image]()
Figure 14: Contents of Kafka Connect image - Build or tag the image using your favorite tool (i.e., Docker/Buildah/etc.) and push it to your registry of choice.
Create Kafka Connect Credentials
Before we create the KafkaConnect cluster there is one small thing we need to take care of. The Debezium connector requires a connection to the database. Rather than hard-coding the credentials into the configuration, let’s instead create an OpenShift Secret that contains credentials that can then be mounted into the KafkaConnect pods.
On your local filesystem, create a file called connector.properties. The contents of this file should be:
xxxxxxxxxx
dbUsername=debezium
dbPassword=debezium
Now let’s create the OpenShift Secret:
xxxxxxxxxx
$ oc create secret generic db-connector-creds --from-file=connector.properties
Deploy the Kafka Connect image
Back in the OpenShift console go back to the Administrator perspective and go into Installed Operators, then click on the Red Hat Integration - AMQ Streams operator, as shown in Figure 15.
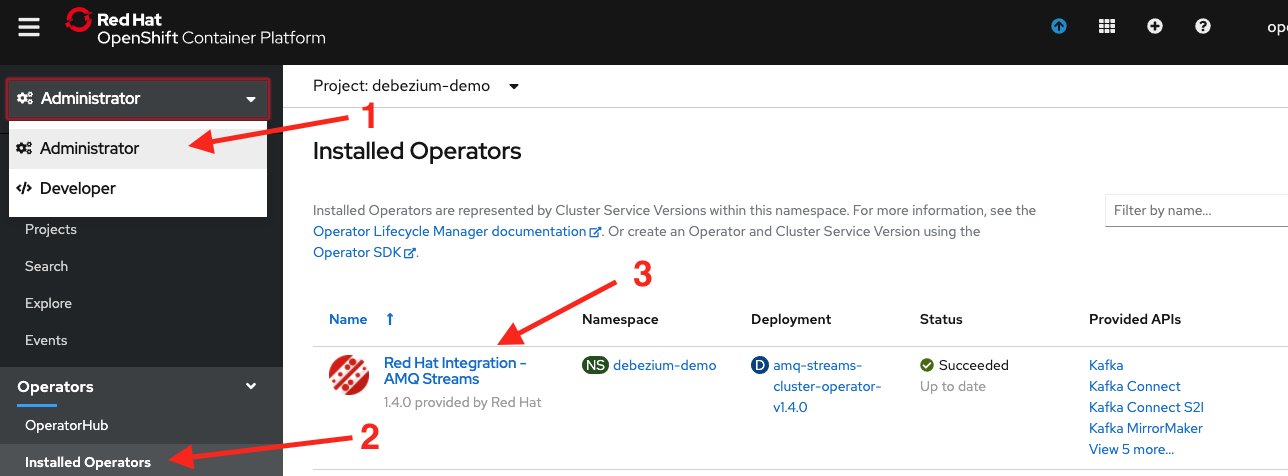
Then under Provided APIs, click the Create Instance label in the Kafka Connect section, as shown in Figure 16.
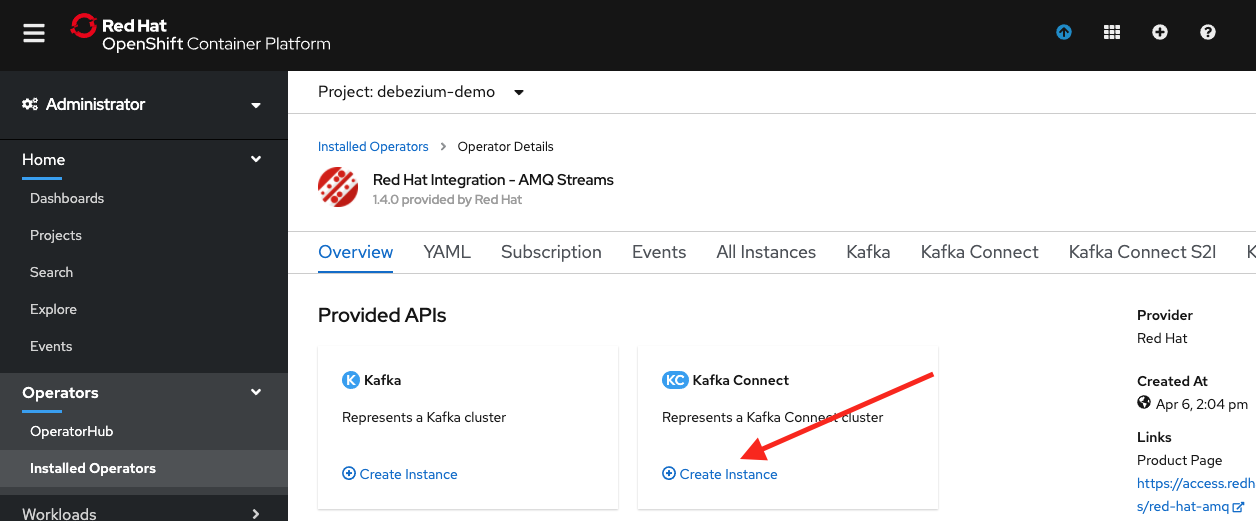
The Create KafkaConnect YAML editor will then come up. Remove everything that's there, paste in the following, and click the Create button at the bottom of the screen:
xxxxxxxxxx
kind: KafkaConnect
apiVersion: kafka.strimzi.io/v1beta1
metadata:
name: db-events
namespace: debezium-demo
labels:
app: spring-music-cdc
template: spring-music-cdc
annotations:
strimzi.io/use-connector-resources: "true"
spec:
replicas: 1
image: "quay.io/edeandrea/kafka-connect-debezium-mysql:amq-streams-1.4.0-dbz-1.1.0.Final"
bootstrapServers: "db-events-kafka-bootstrap:9092"
jvmOptions:
gcLoggingEnabled: false
config:
group.id: spring-music-db
offset.storage.topic: spring-music-db-offsets
config.storage.topic: spring-music-db-configs
status.storage.topic: spring-music-db-status
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
config.providers: file
config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider
externalConfiguration:
volumes:
- name: connector-config
secret:
secretName: db-connector-creds
template:
deployment:
metadata:
labels:
app: spring-music-cdc
app.kubernetes.io/part-of: spring-music-cdc
template: spring-music-cdc
annotations:
app.openshift.io/connects-to: db-events-kafka,spring-music-db
This action will deploy a one-node KafkaConnect cluster. It will also turn down the JVM's garbage collection logging so that if we need to look at the logs in any of the KafkaConnect pods, they won’t be polluted with tons of garbage collection debug logs.
As you can see from this configuration, we use the quay.io/edeandrea/kafka-connect-debezium-mysql:amq-streams-1.4.0-dbz-1.1.0.Final image on line 13:
xxxxxxxxxx
image: "quay.io/edeandrea/kafka-connect-debezium-mysql:amq-streams-1.4.0-dbz-1.1.0.Final"
Then we tell the KafkaConnect cluster to connect to the db-events-kafka-bootstrap:9092 bootstrap server on line 14:
xxxxxxxxxx
bootstrapServers: "db-events-kafka-bootstrap:9092"
We’ve also added some externalConfiguration, which tells the KafkaConnect container to mount the secret named db-connector-creds into the directory /opt/kafka/external-configuration/connector-config within the running container (lines 27-31):
xxxxxxxxxx
externalConfiguration:
volumes:
- name: connector-config
secret:
secretName: db-connector-creds
If you go back to the OpenShift Developer perspective’s Topology view, you should now see the db-events-connect deployment with one replica available, as shown in Figure 17. It might take a few minutes for it to become available.
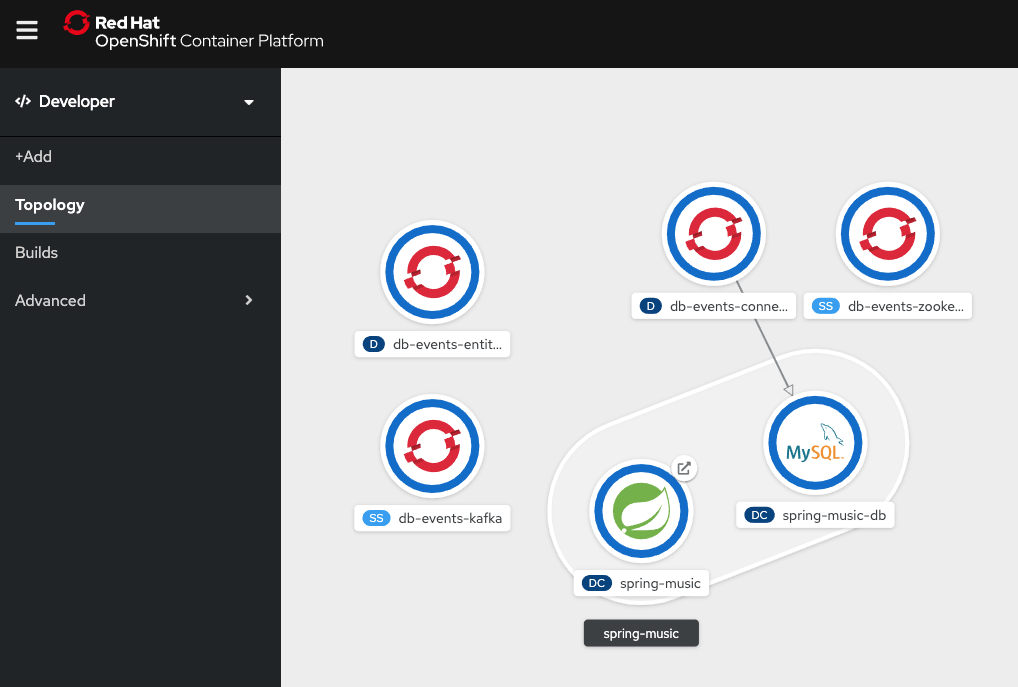
Deploy the Debezium Connector
Now that our Kafka Connect cluster is up and running we can deploy our Debezium connector configuration into it. Back in the OpenShift console, go back to the Administrator perspective, then Installed Operators, and then click the Red Hat Integration - AMQ Streams operator, as shown in Figure 18.
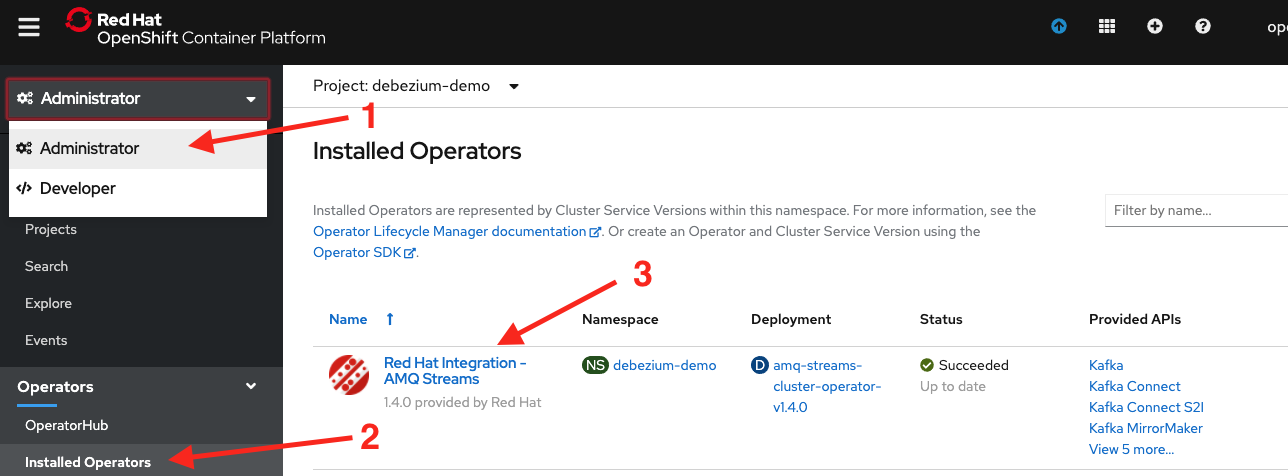
Then under Provided APIs, click the Create Instance label in the Kafka Connector section, as shown in Figure 19.
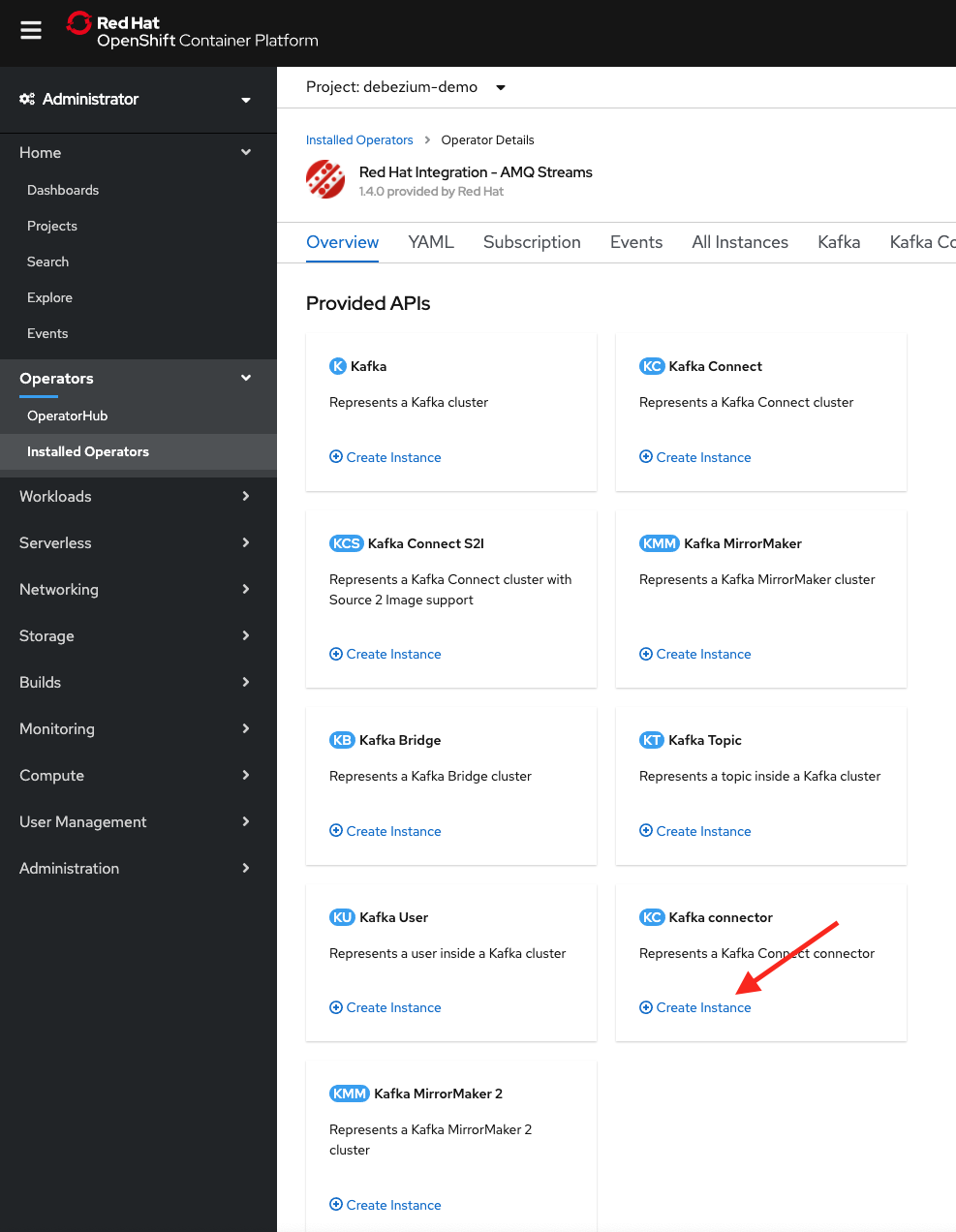
The Create KafkaConnector YAML editor will then come up. Remove everything that's there, paste in the following, and click the Create button at the bottom of the screen. This action will deploy the connector configuration into the Kafka Connect cluster and start the connector:
xxxxxxxxxx
kind: KafkaConnector
apiVersion: kafka.strimzi.io/v1alpha1
metadata:
name: db-events
namespace: debezium-demo
labels:
app: spring-music-cdc
strimzi.io/cluster: db-events
spec:
class: io.debezium.connector.mysql.MySqlConnector
tasksMax: 1
config:
database.hostname: spring-music-db
database.port: 3306
database.user: "${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbUsername}"
database.password: "${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbPassword}"
database.dbname: music
database.server.name: spring-music
database.server.id: 223344
database.whitelist: music
database.allowPublicKeyRetrieval: true
database.history.kafka.bootstrap.servers: db-events-kafka-bootstrap:9092
database.history.kafka.topic: dbhistory.music
table.whitelist: music.outbox_events
tombstones.on.delete : false
transforms: outbox
transforms.outbox.type: io.debezium.transforms.outbox.EventRouter
transforms.outbox.route.topic.replacement: "outbox.${routedByValue}.events"
transforms.outbox.table.field.event.id: event_id
transforms.outbox.table.field.event.key: aggregate_id
transforms.outbox.table.field.event.timestamp: event_timestamp
transforms.outbox.table.field.event.type: event_type
transforms.outbox.table.field.event.payload.id: aggregate_id
transforms.outbox.route.by.field: aggregate_type
transforms.outbox.table.fields.additional.placement: "event_id:envelope:eventId,event_timestamp:envelope:eventTimestamp,aggregate_id:envelope:aggregateId,aggregate_type:envelope:aggregateType"
This configuration provides lots of information. You’ll notice that the database username and password are injected into the configuration via the connector.properties file stored in our OpenShift Secret on lines 15-16:
xxxxxxxxxx
database.user: "${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbUsername}"
database.password: "${file:/opt/kafka/external-configuration/connector-config/connector.properties:dbPassword}"
The configuration also instructs Debezium as to which topic to place events on (line 28):
xxxxxxxxxx
transforms.outbox.route.topic.replacement: "outbox.${routedByValue}.events"
Debezium supports placing all events on a single topic or using a derived routing key to decide the topic. In our case, our application only deals with a single type of domain for its events. For our application, all of the events are stored in the outbox.Album.events topic.
Note: If our application worked with more than one kind of domain event that might be unrelated to another, it might make sense to place each domain’s events into different topics.
Debezium provides a single message transformation to provide out-of-the-box support for applications implementing the Outbox pattern. More documentation on the specifics of Debezium’s Outbox Event Router and it’s configuration can be found in the Debezium documentation. Since the connector has this capability built-in, we just need to tell Debezium how to map between the fields it expects in the payload and the fields in our actual database table (lines 29-35):
xxxxxxxxxx
transforms.outbox.table.field.event.id: event_id
transforms.outbox.table.field.event.key: aggregate_id
transforms.outbox.table.field.event.timestamp: event_timestamp
transforms.outbox.table.field.event.type: event_type
transforms.outbox.table.field.event.payload.id: aggregate_id
transforms.outbox.route.by.field: aggregate_type
transforms.outbox.table.fields.additional.placement: "event_id:envelope:eventId,event_timestamp:envelope:eventTimestamp,aggregate_id:envelope:aggregateId,aggregate_type:envelope:aggregateType"
We could have named the fields in our table exactly as the Debezium EventRouter transformation was looking for it, but that would then have tightly-coupled our database schema to Debezium. As a best practice, we want our components to be loosely-coupled and updateable via external configuration.
Now, how do we know this all worked? We can go directly to one of the Kafka broker pods and run the kafka-console-consumer utility to see the data in the topic.
Look at Resulting Events
Go back to the OpenShift web console and the Topology view. Click the db-events-kafka resource. When the sidebar appears on the right, click any of the three db-events-kafka pods that show up (i.e., the list in Figure 20). It doesn’t matter which one.
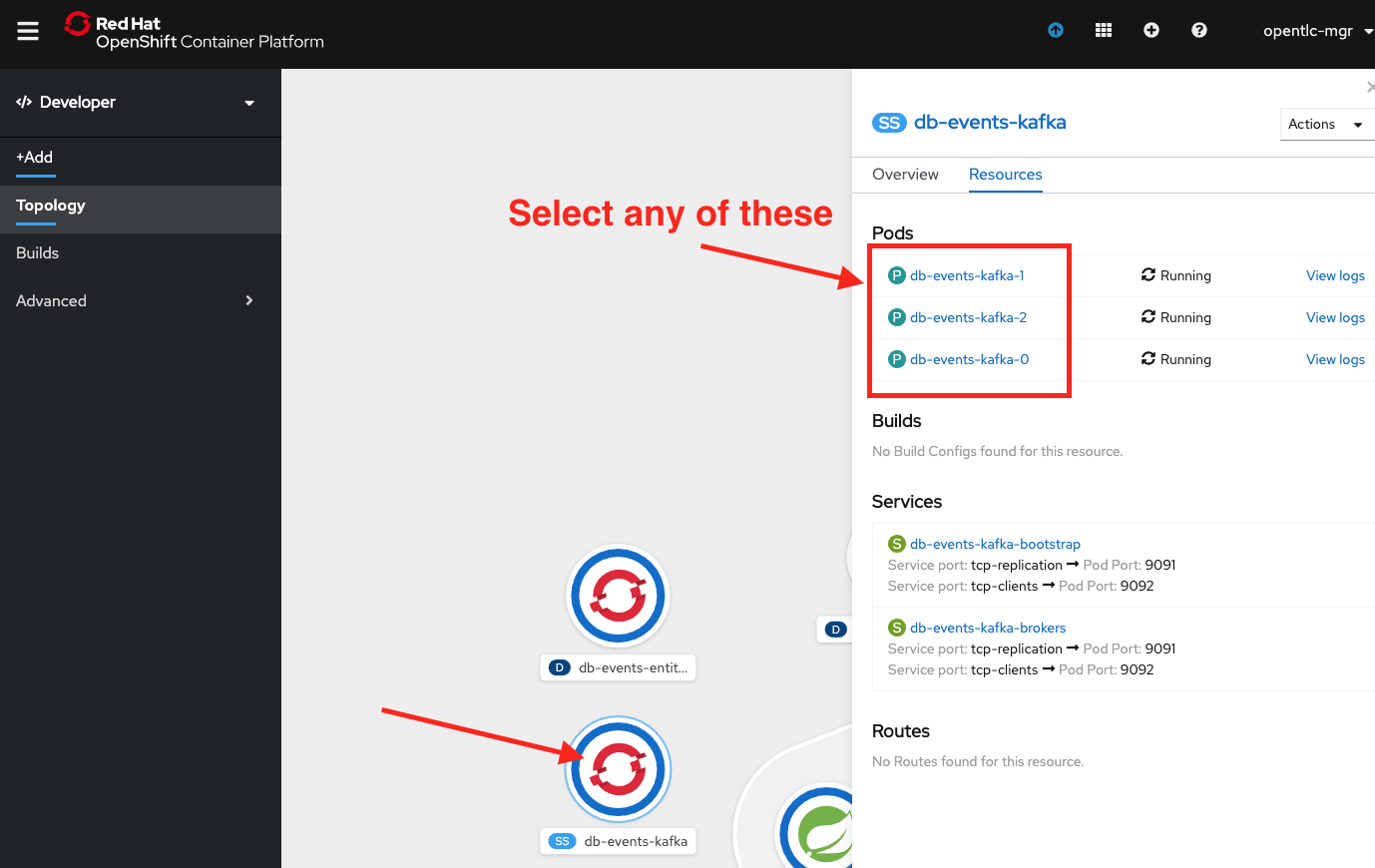
From there, click the Terminal tab to bring you to the terminal. Once at the terminal, run:
xxxxxxxxxx
$ bin/kafka-console-consumer.sh --bootstrap-server db-events-kafka-bootstrap:9092 --topic outbox.Album.events --from-beginning
It will output a bunch of JSON, as shown in Figure 21.
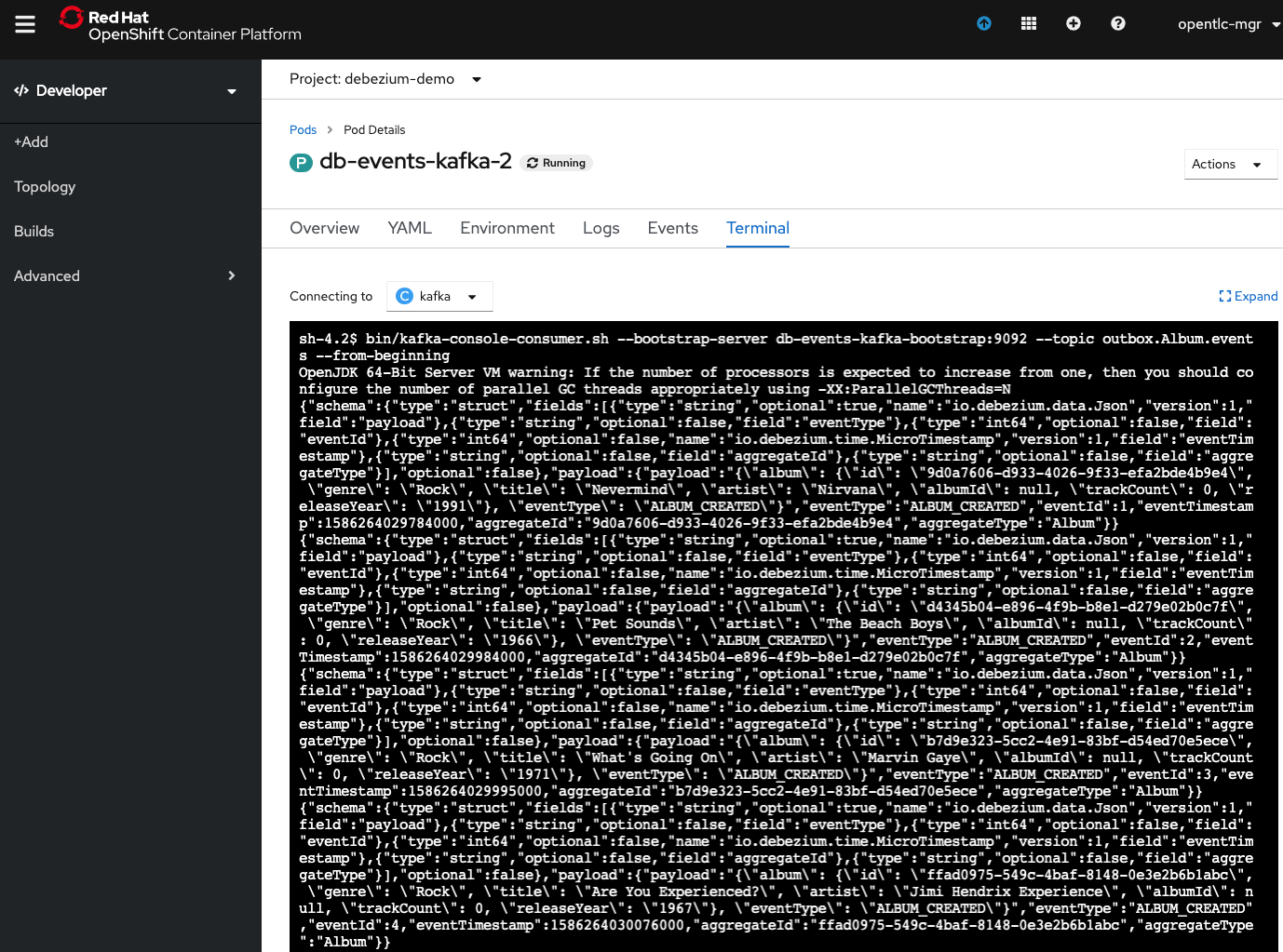
You can now examine the raw output. It should look something like this:
xxxxxxxxxx
{"schema":{"type":"struct","fields":[{"type":"string","optional":true,"name":"io.debezium.data.Json","version":1,"field":"payload"},{"type":"string","optional":false,"field":"eventType"},{"type":"int64","optional":false,"field":"eventId"},{"type":"int64","optional":false,"name":"io.debezium.time.MicroTimestamp","version":1,"field":"eventTimestamp"},{"type":"string","optional":false,"field":"aggregateId"},{"type":"string","optional":false,"field":"aggregateType"}],"optional":false},"payload":{"payload":"{\"album\": {\"id\": \"9d0a7606-d933-4026-9f33-efa2bde4b9e4\", \"genre\": \"Rock\", \"title\": \"Nevermind\", \"artist\": \"Nirvana\", \"albumId\": null, \"trackCount\": 0, \"releaseYear\": \"1991\"}, \"eventType\": \"ALBUM_CREATED\"}","eventType":"ALBUM_CREATED","eventId":1,"eventTimestamp":1586264029784000,"aggregateId":"9d0a7606-d933-4026-9f33-efa2bde4b9e4","aggregateType":"Album"}}
The output might not look too legible, but if you pretty-print it (Google json pretty print in your browser and find a free utility) you’ll see that the payload format looks like this:
xxxxxxxxxx
{
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Json",
"version": 1,
"field": "payload"
},
{
"type": "string",
"optional": false,
"field": "eventType"
},
{
"type": "int64",
"optional": false,
"field": "eventId"
},
{
"type": "int64",
"optional": false,
"name": "io.debezium.time.MicroTimestamp",
"version": 1,
"field": "eventTimestamp"
},
{
"type": "string",
"optional": false,
"field": "aggregateId"
},
{
"type": "string",
"optional": false,
"field": "aggregateType"
}
],
"optional": false
},
"payload": {
"payload": "{\"album\": {\"id\": \"9d0a7606-d933-4026-9f33-efa2bde4b9e4\", \"genre\": \"Rock\", \"title\": \"Nevermind\", \"artist\": \"Nirvana\", \"albumId\": null, \"trackCount\": 0, \"releaseYear\": \"1991\"}, \"eventType\": \"ALBUM_CREATED\"}",
"eventType": "ALBUM_CREATED",
"eventId": 1,
"eventTimestamp": 1586264029784000,
"aggregateId": "9d0a7606-d933-4026-9f33-efa2bde4b9e4",
"aggregateType": "Album"
}
}
This payload defines its own structure in the schema element on lines 2-41:
xxxxxxxxxx
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Json",
"version": 1,
"field": "payload"
},
{
"type": "string",
"optional": false,
"field": "eventType"
},
{
"type": "int64",
"optional": false,
"field": "eventId"
}, { "type": "int64", "optional": false, "name": "io.debezium.time.MicroTimestamp", "version": 1, "field": "eventTimestamp" }, { "type": "string", "optional": false, "field": "aggregateId" }, { "type": "string", "optional": false, "field": "aggregateType" } ], "optional": false }
We could eliminate this section by standing up our own schema registry and configuring our cluster to use Avro serialization/deserialization. The payload element on lines 42-49 contains metadata about the event, as well as the actual payload of the event:
xxxxxxxxxx
"payload": {
"payload": "{\"album\": {\"id\": \"9d0a7606-d933-4026-9f33-efa2bde4b9e4\", \"genre\": \"Rock\", \"title\": \"Nevermind\", \"artist\": \"Nirvana\", \"albumId\": null, \"trackCount\": 0, \"releaseYear\": \"1991\"}, \"eventType\": \"ALBUM_CREATED\"}",
"eventType": "ALBUM_CREATED",
"eventId": 1,
"eventTimestamp": 1586264029784000,
"aggregateId": "9d0a7606-d933-4026-9f33-efa2bde4b9e4",
"aggregateType": "Album"
}
The payload sub-element within the main payload element (line 43) is itself a JSON string representing the contents of the domain object making up the event:
xxxxxxxxxx
"payload": "{\"album\": {\"id\": \"9d0a7606-d933-4026-9f33-efa2bde4b9e4\", \"genre\": \"Rock\", \"title\": \"Nevermind\", \"artist\": \"Nirvana\", \"albumId\": null, \"trackCount\": 0, \"releaseYear\": \"1991\"}, \"eventType\": \"ALBUM_CREATED\"}"
If you keep this terminal window open and open up a new browser window back to the application itself, you should see new events stream in as you update/delete albums from the application’s user interface.
Next Steps
Hopefully, you found this post helpful! If so, please watch for a few other posts in this series once they become available:
- Adding Prometheus metrics and Grafana Dashboard monitoring
- Securing Kafka and KafkaConnect with OAuth authentication
- Adding access control to Kafka and KafkaConnect with OAuth authorization
Also, if you are like me and want to automate the provisioning of everything, feel free to take a look at an Ansible Playbook that is capable of doing this.
References
This post was originally published on Red Hat Developer. To read the original post, visit https://developers.redhat.com/blog/2020/05/08/change-data-capture-with-debezium-a-simple-how-to-part-1/.
Published at DZone with permission of Eric Deandrea. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments